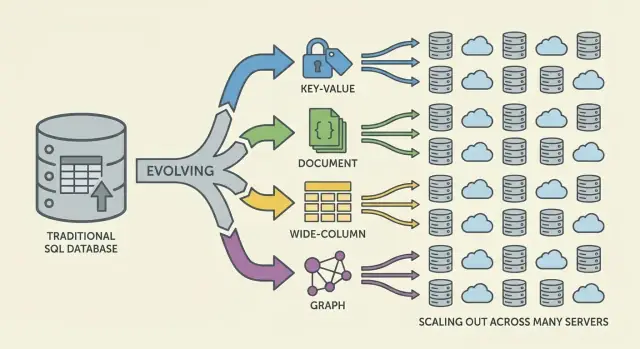
¿Qué problema intentaba resolver NoSQL?
NoSQL surgió cuando muchos equipos se encontraron con una discordancia entre lo que sus aplicaciones necesitaban y para qué estaban optimizadas las bases de datos relacionales tradicionales (bases SQL). SQL no “falló”, pero a escala web algunos equipos empezaron a priorizar objetivos distintos.
Las dos presiones: escala y cambio
Primero, escala. Las aplicaciones de consumo populares comenzaron a ver picos de tráfico, escrituras constantes y volúmenes masivos de datos generados por usuarios. Para estas cargas, “comprar un servidor más grande” resultó caro, lento de implementar y, en última instancia, limitado por la máquina más grande que podrías operar razonablemente.
Segundo, cambio. Las características de producto evolucionaban rápido y los datos detrás de ellas no siempre encajaban bien en un conjunto fijo de tablas. Añadir nuevos atributos a perfiles de usuario, almacenar múltiples tipos de eventos o ingerir JSON semiestructurado desde distintas fuentes a menudo implicaba migraciones repetidas de esquema y coordinación entre equipos.
Por qué las bases relacionales tropezaron en ciertos casos
Las bases relacionales son excelentes para imponer estructura y habilitar consultas complejas sobre tablas normalizadas. Pero algunas cargas de alto volumen hicieron que esas fortalezas fuesen más difíciles de aprovechar:
- Muchas escrituras concurrentes en múltiples tablas pueden crear contención.
- Consultas pesadas basadas en joins pueden volverse costosas a medida que los datos crecen rápidamente.
- Escalar horizontalmente en muchas máquinas es posible, pero operarlo manteniendo consistencia estricta en todas partes puede ser complicado.
El resultado: algunos equipos buscaron sistemas que intercambiasen ciertas garantías por un escalado más simple y una iteración más rápida.
NoSQL: una familia de enfoques, no una sola cosa
NoSQL no es una única base de datos o diseño. Es un término paraguas para sistemas que enfatizan una mezcla de:
- Escalado horizontal (añadir más máquinas)
- Modelos de datos flexibles
- Patrones de acceso ajustados a necesidades específicas de la aplicación
Un reajuste de expectativas
NoSQL nunca estuvo pensado para ser un reemplazo universal de SQL. Es un conjunto de compensaciones: puedes ganar escalabilidad o flexibilidad de esquema, pero quizá aceptes garantías de consistencia más débiles, menos opciones de consulta ad-hoc o más responsabilidad en el modelado de datos a nivel de aplicación.
Por qué el escalado tradicional empezó a fallar
Durante años, la respuesta estándar a una base de datos lenta fue sencilla: compra un servidor más grande. Añade más CPU, más RAM, discos más rápidos y conserva el mismo esquema y modelo operativo. Este enfoque de “escalar verticalmente” funcionó—hasta que dejó de ser práctico.
El escalado vertical chocó con límites duros
Las máquinas de gama alta se encarecen rápidamente y la curva precio/rendimiento acaba siendo desfavorable. Las actualizaciones suelen requerir aprobaciones presupuestarias grandes e infrecuentes y ventanas de mantenimiento para mover datos y hacer el corte. Incluso si puedes permitirte hardware más grande, un único servidor tiene un techo: un bus de memoria, un subsistema de almacenamiento y un nodo primario que absorbe la carga de escritura.
A medida que los productos crecían, las bases de datos afrontaban presión constante de lectura/escritura en lugar de picos ocasionales. El tráfico se volvió verdaderamente 24/7 y ciertas características generaron patrones de acceso desiguales. Un pequeño número de filas o particiones muy accedidas podía dominar el tráfico, produciendo tablas calientes (o claves calientes) que lastraban todo lo demás.
Los cuellos de botella operativos se hicieron comunes:
- Inflado de índices conforme nuevas características requerían más índices secundarios
- Contención por muchas escrituras concurrentes que golpean las mismas tablas
- Esperas de bloqueo que hacen la latencia impredecible bajo carga
- Retrasos en la replicación y conmutaciones por error más lentas a medida que los conjuntos de datos crecían
Los servidores más grandes no resolvían la disponibilidad global
Muchas aplicaciones también necesitaban estar disponibles en varias regiones, no solo rápidas en un centro de datos. Una única base de datos “principal” en un lugar aumenta la latencia para usuarios lejanos y hace que las caídas sean más catastróficas. La pregunta cambió de “¿Cómo compramos una caja más grande?” a “¿Cómo ejecutamos la base de datos en muchas máquinas y ubicaciones?”
La necesidad de modelos de datos flexibles
Las bases relacionales brillan cuando la forma de tus datos es estable. Pero muchos productos modernos no se quedan quietos. Un esquema de tabla es deliberadamente estricto: cada fila sigue el mismo conjunto de columnas, tipos y restricciones. Esa previsibilidad es valiosa—hasta que estás iterando rápido.
Esquemas rígidos y el coste real del cambio
En la práctica, los cambios frecuentes de esquema pueden ser caros. Una actualización aparentemente pequeña puede requerir migraciones, backfills, actualizaciones de índices, planificación de despliegues coordinados y compatibilidad para que rutas de código antiguo no fallen. En tablas grandes, incluso añadir una columna o cambiar un tipo puede convertirse en una operación que consume tiempo y con riesgo operativo real.
Esa fricción empuja a los equipos a retrasar cambios, acumular soluciones provisionales o almacenar blobs desordenados en campos de texto—ninguna de las cuales es ideal para iterar rápido.
Datos semiestructurados encajan con cómo evolucionan los productos
Muchos datos de aplicación son naturalmente semiestructurados: objetos anidados, campos opcionales y atributos que evolucionan con el tiempo.
Por ejemplo, un “perfil de usuario” puede comenzar con nombre y correo, luego crecer para incluir preferencias, cuentas vinculadas, direcciones de envío, ajustes de notificación y flags de experimentos. No todos los usuarios tienen todos los campos y los campos nuevos llegan gradualmente. Los modelos estilo documento pueden almacenar formas anidadas y desiguales directamente sin forzar a cada registro a un mismo template rígido.
Iteración más rápida, menos joins incómodos
La flexibilidad también reduce la necesidad de joins complejos para ciertas formas de datos. Cuando una pantalla necesita un objeto compuesto (un pedido con ítems, info de envío e historial de estado), los diseños relacionales pueden requerir múltiples tablas y joins—además de capas ORM que intentan ocultar esa complejidad pero a menudo añaden fricción.
Las opciones NoSQL facilitaron modelar datos más cercanos a cómo la aplicación los lee y escribe, ayudando a los equipos a lanzar cambios más rápido.
El cambio a escala web que modificó los requisitos de las bases de datos
Las aplicaciones web no solo se hicieron más grandes: cambiaron de forma. En lugar de servir a un número predecible de usuarios internos durante horas laborales, los productos empezaron a servir a millones de usuarios globales a cualquier hora, con picos repentinos impulsados por lanzamientos, noticias o compartidos sociales.
La expectativa de estar siempre disponibles subió el listón: el tiempo de inactividad pasó a ser noticia, no una molestia. Al mismo tiempo, se pedía a los equipos que lanzaran características más rápido—a menudo antes de saber cuál sería el modelo de datos “final”.
Distribuido se convirtió en la vía por defecto para crecer
Para mantener el ritmo, escalar un único servidor dejó de ser suficiente. Cuanto más tráfico manejabas, más querías capacidad que pudieras añadir incrementalmente: añadir otro nodo, repartir carga, aislar fallos.
Esto empujó la arquitectura hacia flotas de máquinas en lugar de una única "caja principal" y cambió lo que los equipos esperaban de las bases de datos: no solo corrección, sino rendimiento predecible bajo alta concurrencia y comportamiento elegante cuando partes del sistema están enfermas.
Patrones que los equipos adoptaron antes de que las bases de datos se pusieran al día
Antes de que “NoSQL” fuese una categoría mainstream, muchos equipos ya estaban adaptando sistemas a realidades web-scale:
- Capas de caché (a menudo en memoria) para reducir lecturas repetidas
- Desnormalización para evitar joins costosos y reducir viajes de ida y vuelta
- Vistas precomputadas y rollups materializados para feeds, timelines y dashboards
Estas técnicas funcionaban, pero trasladaban la complejidad al código de aplicación: invalidación de caché, mantener datos duplicados consistentes y construir pipelines para registros “listos para servir”.
Cómo esto forzó la evolución de las bases de datos
A medida que estos patrones se convirtieron en estándar, las bases de datos tuvieron que soportar distribuir datos entre máquinas, tolerar fallos parciales, manejar altos volúmenes de escritura y representar datos que evolucionan de forma limpia. Los sistemas NoSQL emergieron en parte para convertir estrategias comunes de web-scale en capacidades de primera clase en lugar de atajos constantes.
Compromisos distribuidos y el teorema CAP
Prototipa tu estrategia de datos
Prototipa rápidamente un enfoque SQL vs NoSQL con una aplicación full-stack generada desde el chat.
Cuando los datos viven en una máquina, las reglas parecen simples: hay una única fuente de verdad y cada lectura o escritura puede comprobarse de inmediato. Cuando repartes datos entre servidores (a menudo entre regiones), aparece una nueva realidad: los mensajes pueden retrasarse, los nodos pueden fallar y partes del sistema pueden dejar de comunicarse temporalmente.
El compromiso central en lenguaje claro
Una base de datos distribuida debe decidir qué hacer cuando no puede coordinarse con seguridad. ¿Debe seguir atendiendo peticiones para que la app permanezca “arriba”, aun cuando los resultados puedan estar un poco desactualizados? ¿O debe rechazar operaciones hasta confirmar que las réplicas concuerdan, lo que puede parecer tiempo de inactividad para los usuarios?
Estas situaciones ocurren durante fallos de routers, redes sobrecargadas, despliegues progresivos, malas configuraciones de firewall y retardos en replicación entre regiones.
CAP en un cuadro: C, A y P
El teorema CAP es un atajo para tres propiedades que uno querría al mismo tiempo:
- Consistencia (C): cada lectura devuelve la última escritura (o un error). En la práctica, “todos ven la misma respuesta ahora mismo.”
- Disponibilidad (A): cada petición obtiene una respuesta (no necesariamente los datos más recientes).
- Tolerancia a particiones (P): el sistema sigue operando aunque la red se divida en grupos aislados.
El punto clave no es “elige dos para siempre.” Es: cuando ocurre una partición de red, debes elegir entre consistencia y disponibilidad. En sistemas web-scale, las particiones se tratan como inevitables—especialmente en configuraciones multinodo y multirregión.
Las particiones conectan directamente con fallos reales
Imagina que tu app corre en dos regiones para resiliencia. Un corte de fibra o un problema de ruteo impide la sincronización.
- Si priorizas disponibilidad, ambas regiones siguen aceptando escrituras y los datos pueden divergir temporalmente.
- Si priorizas consistencia, una región puede rechazar escrituras (o lecturas) hasta confirmar el acuerdo.
Distintos sistemas NoSQL (e incluso distintas configuraciones del mismo sistema) hacen diferentes compromisos según lo que importe más: experiencia de usuario durante fallos, garantías de corrección, simplicidad operativa o comportamiento de recuperación.
Escalar horizontalmente: sharding y replicación como ideas centrales
Escalar horizontalmente significa aumentar capacidad añadiendo más máquinas (nodos) en lugar de comprar un servidor más grande. Para muchos equipos, esto fue un cambio financiero y operativo: nodos commodity se pueden añadir incrementalmente, se esperan fallos y el crecimiento no exige migraciones riesgosas a “big box”.
Sharding (particionado): repartir el trabajo
Para hacer útiles a muchos nodos, los sistemas NoSQL se apoyaron en sharding (también llamado particionado). En lugar de que una base de datos maneje cada petición, los datos se dividen en particiones y se distribuyen entre nodos.
Un ejemplo simple es particionar por una clave (como user_id):
- Nodo A almacena usuarios 1–1,000,000
- Nodo B almacena usuarios 1,000,001–2,000,000
Las lecturas y escrituras se reparten, reduciendo hotspots y permitiendo que el rendimiento crezca al añadir nodos. La clave de partición se convierte en una decisión de diseño: elige una clave alineada con los patrones de consulta o podrías canalizar demasiado tráfico en un solo shard.
Replicación: disponibilidad y escalado de lecturas
La replicación consiste en mantener múltiples copias de los mismos datos en distintos nodos. Esto mejora:
- Disponibilidad: si un nodo falla, otra réplica puede servir peticiones.
- Capacidad de lectura: las lecturas pueden servirse desde múltiples réplicas.
La replicación también permite dispersar datos por racks o regiones para sobrevivir a fallos localizados.
El coste oculto: reequilibrar y operar
Sharding y replicación introducen trabajo operativo continuo. A medida que los datos crecen o los nodos cambian, el sistema debe reequilibrar—mover particiones mientras permanece en línea. Si se maneja mal, el reequilibrio puede causar picos de latencia, cargas desiguales o faltas temporales de capacidad.
Este es un compromiso central: escalado más barato vía más nodos a cambio de mayor complejidad en distribución, monitorización y manejo de fallos.
Modelos de consistencia: de lo estricto a lo eventual
Una vez que los datos están distribuidos, la base debe definir qué significa “correcto” cuando las actualizaciones ocurren concurrentemente, las redes se retrasan o los nodos no pueden comunicarse.
Consistencia estricta
Con consistencia fuerte, una vez que una escritura se reconoce, todo lector debería verla de inmediato. Esto coincide con la experiencia de “fuente única de verdad” que mucha gente asocia con bases relacionales.
El reto es la coordinación: las garantías estrictas entre nodos requieren múltiples mensajes, esperar suficientes respuestas y manejar fallos a mitad de vuelo. Cuanto más separados estén los nodos (o más ocupados), más latencia puedes introducir—a veces en cada escritura.
Consistencia eventual
La consistencia eventual relaja esa garantía: después de una escritura, distintos nodos pueden devolver respuestas diferentes temporalmente, pero el sistema converge con el tiempo.
Ejemplos:
- Un contador de “me gusta” puede mostrar 101 en una réplica mientras otra sigue mostrando 100 por unos segundos.
- Una publicación nueva puede aparecer en el feed de algunos usuarios antes que en el de otros, especialmente entre regiones.
Para muchas experiencias de usuario, esa discordancia temporal es aceptable si el sistema sigue siendo rápido y disponible.
Conflictos y cómo se resuelven
Si dos réplicas aceptan actualizaciones casi al mismo tiempo, la base necesita una regla de fusión.
Enfoques comunes incluyen:
- Marcas temporales (last-write-wins): conservar la actualización con la marca más reciente. Sencillo, pero puede perder datos si los relojes se desincronizan o si “lo más nuevo” no es semánticamente correcto.
- Vectores de versión (conceptualmente): rastrear qué réplicas han visto qué actualizaciones, detectar escrituras concurrentes y fusionar o exponer conflictos.
Dónde sigue importando la consistencia fuerte
La consistencia fuerte suele valer el coste en transferencias de dinero, límites de inventario, nombres de usuario únicos, permisos y cualquier flujo donde “dos verdades por un momento” pueda causar daño real.
Las principales familias de bases NoSQL (y para qué optimizaban)
Planifica antes de elegir
Usa el Modo de Planificación para mapear consultas, estructuras de datos y compensaciones antes de comprometerte.
NoSQL es un conjunto de modelos que hacen distintos compromisos en torno a escala, latencia y forma de los datos. Entender la “familia” ayuda a predecir qué será rápido, qué será doloroso y por qué.
Key-value: velocidad por simplicidad
Las bases clave-valor almacenan un valor bajo una clave única, como un enorme hashmap distribuido. Dado que el patrón de acceso suele ser “get por clave” / “set por clave”, pueden ser extremadamente rápidas y escalables horizontalmente.
Son fantásticas cuando ya conoces la clave de búsqueda (sessions, caché, feature flags), pero limitadas para consultas ad-hoc: filtrar por múltiples campos no es el objetivo del sistema.
Las bases documentales almacenan documentos tipo JSON (a menudo agrupados en colecciones). Cada documento puede tener una estructura ligeramente distinta, lo que soporta flexibilidad de esquema conforme los productos evolucionan.
Se optimizan para leer y escribir documentos completos y para consultar por campos dentro de ellos—sin forzar tablas rígidas. La compensación: modelar relaciones puede complicarse y los joins (si existen) suelen ser más limitados que en sistemas relacionales.
Wide-column: alto throughput de escritura a enorme escala
Las bases wide-column (inspiradas en Bigtable) organizan datos por claves de fila, con muchas columnas que pueden variar por fila. Brillan en tasas masivas de escritura y almacenamiento distribuido, siendo idóneas para series temporales, eventos y logs.
Suelen recompensar el diseño cuidadoso alrededor de patrones de acceso: consultas eficientes por clave primaria y reglas de clustering, no por filtros arbitrarios.
Grafos: consultas centradas en relaciones
Las bases de datos de grafos tratan las relaciones como dato de primera clase. En lugar de hacer joins repetidamente, recorren aristas entre nodos, haciendo naturales y rápidas las consultas del tipo “¿cómo están conectadas estas cosas?” (análisis de fraude, recomendaciones, dependencias).
Guía rápida: cuándo encaja mejor cada modelo
- Key-value: búsquedas más rápidas por ID; caché, sesiones, contadores
- Documental: datos de producto que evolucionan; perfiles, catálogos, contenido
- Wide-column: ingesta masiva a escala; telemetría, logs, series temporales
- Grafo: consultas profundas de relaciones; grafos sociales, enrutamiento, análisis de fraude
Cambios en el modelado de datos: menos joins, diseño más intencional
Las bases relacionales fomentan la normalización: dividir datos en muchas tablas y recomponerlos con joins en tiempo de consulta. Muchos sistemas NoSQL te empujan a diseñar alrededor de los patrones de acceso más importantes—a veces a costa de duplicación—para mantener la latencia predecible entre nodos.
Por qué la desnormalización es tan común
En bases distribuidas, un join puede requerir traer datos de múltiples particiones o máquinas. Eso añade saltos de red, coordinación y latencia impredecible. La desnormalización (almacenar datos relacionados juntos) reduce viajes y mantiene una lectura “local” tan a menudo como sea posible.
Una consecuencia práctica: podrías almacenar el mismo nombre de cliente en un registro orders aunque también exista en customers, porque “mostrar las últimas 20 órdenes” es una consulta principal.
Restricciones de consulta: menos joins, más modelado en la app
Muchas bases NoSQL soportan joins limitados (o ninguno), así que la aplicación asume más responsabilidad:
- Obtener un documento/fila por clave y renderizar directamente
- Leer dos conjuntos de datos por separado y combinarlos en código
- Precomputar datos de vista (cuentas, resúmenes) para evitar escaneos costosos
Por eso el modelado NoSQL suele empezar con: “¿Qué pantallas necesitamos cargar?” y “¿Cuáles son las consultas principales que deben ser rápidas?”.
Índices secundarios—y sus costes ocultos
Los índices secundarios pueden habilitar nuevas consultas ("buscar usuarios por email"), pero no son gratuitos. En sistemas distribuidos, cada escritura puede actualizar múltiples estructuras de índice, lo que conduce a:
- Amplificación de escritura: una escritura lógica se convierte en varias físicas
- Almacenamiento extra: las entradas de índice pueden rivalizar con el tamaño de los datos
- Complejidad operativa: los índices pueden retrasarse o requerir afinamiento cuidadoso
Ejemplos de decisiones de modelado que mejoran el rendimiento
- Embed en lugar de referenciar: almacenar ítems de un pedido dentro del documento del pedido para leerlo en una sola petición
- Agrupar datos de series temporales: mantener eventos por dispositivo por día para evitar particiones ilimitadas
- Materializar modelos de lectura: mantener un registro
user_profile_summary para servir la página de perfil sin escanear posts, likes y follows
Beneficios y compromisos que aceptaron los equipos
Comparte una demo ejecutable
Lanza una demo interna con hosting y compártela para recibir comentarios.
NoSQL no se adoptó porque fuera “mejor” en todo. Se adoptó porque los equipos estaban dispuestos a intercambiar ciertas comodidades de las bases relacionales por velocidad, escala y flexibilidad bajo la presión web-scale.
Lo que ganaron los equipos
Escalar horizontalmente por diseño. Muchos sistemas NoSQL hicieron práctico añadir máquinas en lugar de actualizar continuamente un único servidor. Sharding y replicación fueron capacidades clave, no complementos.
Esquemas flexibles. Sistemas documentales y clave-valor permitieron evolucionar la aplicación sin pasar cada cambio de campo por la definición estricta de una tabla, reduciendo la fricción cuando los requisitos cambiaban semanalmente.
Patrones de alta disponibilidad. La replicación entre nodos y regiones facilitó mantener servicios activos durante fallos de hardware o mantenimiento.
Lo que pagaron los equipos
Duplicación de datos y desnormalización. Evitar joins suele significar duplicar datos. Eso mejora lecturas pero incrementa almacenamiento e introduce la complejidad de “actualizar en todos lados”.
Sorpresas de consistencia. La consistencia eventual puede ser aceptable—hasta que no lo es. Los usuarios pueden ver datos obsoletos o casos límite confusos a menos que la aplicación esté diseñada para tolerar o resolver conflictos.
Analítica más difícil (a veces). Algunos almacenes NoSQL son excelentes para lecturas/escrituras operacionales, pero hacen las consultas ad-hoc, reporting o agregaciones complejas más engorrosas que los sistemas orientados a SQL.
Por qué la operación y las herramientas importaron
La adopción temprana de NoSQL a menudo trasladó el esfuerzo de características de la base de datos a disciplina de ingeniería: monitorizar replicación, gestionar particiones, ejecutar compactación, planificar backups/restores y hacer pruebas de carga con escenarios de fallo. Los equipos con madurez operativa fuerte fueron los que más se beneficiaron.
Cómo evaluar los compromisos
Elige en función de realidades de la carga: latencia esperada, picos máximos, patrones de consulta dominantes, tolerancia a lecturas desactualizadas y requisitos de recuperación (RPO/RTO). La elección “correcta” suele ser la que coincide con cómo tu aplicación falla, escala y necesita ser consultada—no la que tiene la lista de características más impresionante.
Cómo decidir si NoSQL es adecuado hoy
Elegir NoSQL no debería empezar por marcas o hype: debe empezar por lo que tu aplicación necesita hacer, cómo crecerá y qué significa “correcto” para tus usuarios.
Empieza con requisitos y patrones de acceso
Antes de escoger un datastore, escribe:
- Las 5–10 consultas/operaciones principales que debes soportar (lecturas, escrituras, búsqueda, agregaciones)
- Tráfico esperado ahora vs. en 12–24 meses
- Tu tolerancia a lecturas desactualizadas (milisegundos, segundos, nunca)
- Expectativas de fallo (¿qué pasa si un nodo o región cae?)
Si no puedes describir claramente tus patrones de acceso, cualquier elección será conjetural—especialmente con NoSQL, donde el modelado a menudo se moldea por cómo lees y escribes.
Checklist simple de decisión (SQL vs NoSQL vs híbrido)
Usa esto como filtro rápido:
- Elige SQL si necesitas consistencia fuerte por defecto, consultas ad-hoc complejas y muchas relaciones que se benefician de joins.
- Elige NoSQL si necesitas escalado horizontal fácil para patrones de acceso específicos, puedes diseñar los datos alrededor de esos patrones y aceptas consistencia relajada para algunos flujos.
- Elige un híbrido si distintas partes de la app tienen necesidades diferentes (común en productos reales).
Una señal práctica: si tu “verdad central” (pedidos, pagos, inventario) debe ser correcta siempre, conserva eso en SQL u otro almacén fuertemente consistente. Si atiendes contenido de alto volumen, sesiones, caché, feeds de actividad o datos generados por usuarios con estructura flexible, NoSQL puede encajar bien.
Considera persistencia poliglota (intencionada)
Muchos equipos triunfan con múltiples almacenes: por ejemplo, SQL para transacciones, una base documental para perfiles/contenido y un almacén clave-valor para sesiones. La meta no es complejidad por sí misma, sino alinear cada carga con la herramienta adecuada.
Aquí también importa el flujo de trabajo del desarrollador. Si iteras la arquitectura (SQL vs NoSQL vs híbrido), poder montar un prototipo funcional rápido—API, modelo de datos y UI—puede reducir riesgos. Plataformas como Koder.ai ayudan a generar apps full-stack desde chat, típicamente con frontend en React y backend en Go + PostgreSQL, y permiten exportar el código fuente. Incluso si luego introduces una tienda NoSQL para cargas específicas, tener un fuerte SQL “sistema de registro” más prototipado rápido, snapshots y rollback puede hacer los experimentos más seguros y veloces.
Valida con pruebas, no con opiniones
Sea lo que sea que elijas, pruébalo:
- Ejecuta pruebas de carga con consultas y tamaños de datos realistas.
- Haz ensayos de fallo (matar nodos, simular particiones, probar restauraciones).
- Crea un plan de evolución de esquema: cómo añadirás campos, migrarás registros y mantenerás versiones antiguas/nuevas funcionando durante el despliegue.
Si no puedes probar estos escenarios, tu decisión de base de datos seguirá siendo teórica—y producción hará las pruebas por ti.