Qué es una página de estado SaaS (y por qué importa)
Una página de estado SaaS es un sitio público (o solo para clientes) que muestra si tu producto está funcionando ahora mismo —y qué estáis haciendo si no lo está. Se convierte en la fuente única de verdad durante incidentes, separada de redes sociales, tickets de soporte y rumores.
Ayuda a más personas de las que podrías imaginar:
- Clientes pueden confirmar rápidamente “¿Me pasa solo a mí?” y decidir si esperar, reintentar o usar una solución temporal.
- Equipos de soporte pueden enlazar a una única actualización canónica en vez de repetir explicaciones en docenas de tickets.
- Ventas y Customer Success pueden gestionar renovaciones y cuentas clave con información precisa y con marca temporal.
Estado en tiempo real vs. historial de incidentes vs. postmortems
Un buen sitio de estado suele contener tres capas relacionadas (pero diferentes):
- Estado en tiempo real: qué está arriba, abajo o degradado ahora mismo en tus componentes (API, panel, facturación, etc.).
- Página de historial de incidentes: una línea temporal de incidentes y mantenimientos pasados, para que los clientes entiendan patrones y vean que los problemas se resolvieron.
- Revisiones post‑incidente (postmortems): análisis más profundos que explican causa raíz, correcciones y pasos de prevención. Pueden ser públicos o compartidos de forma privada con los clientes afectados.
El objetivo es la claridad: el estado en tiempo real responde “¿Puedo usar el producto?” mientras el historial responde “¿Con qué frecuencia pasa esto?” y los postmortems responden “¿Por qué pasó y qué cambió?”.
Fijar expectativas: transparencia, rapidez y claridad
Una página de estado funciona cuando las actualizaciones son rápidas, en lenguaje llano y honestas respecto al impacto. No necesitas un diagnóstico perfecto para comunicar. Sí necesitas marcas temporales, alcance (quiénes están afectados) y la hora de la próxima actualización.
Momentos comunes en los que la usarás
La usarás durante caídas, rendimiento degradado (inicios de sesión lentos, webhooks retrasados) y mantenimientos programados que puedan causar interrupciones breves o riesgo.
Si tratas la página de estado como una superficie de producto (no como una página de operaciones puntual), el resto de la configuración se vuelve mucho más fácil: puedes definir responsables, crear plantillas y conectar monitorización sin reinventar el proceso en cada incidente.
Establece objetivos, audiencia y responsables
Antes de elegir una herramienta o diseñar un layout, decide qué debe hacer tu página de estado. Un objetivo claro y un responsable claro mantienen las páginas de estado útiles durante un incidente —cuando todos están ocupados y la información es confusa.
Define el objetivo (qué significa “éxito”)
La mayoría de equipos SaaS crean una página de estado para tres resultados prácticos:
- Reducir tickets de soporte respondiendo “¿está caído?” en un lugar público
- Generar confianza compartiendo actualizaciones oportunas y en lenguaje llano
- Acelerar la comunicación entre Soporte, Ingeniería, Ventas y Customer Success
Apunta 2–3 señales medibles que puedas seguir tras el lanzamiento: menos tickets duplicados durante caídas, tiempo hasta la primera actualización más rápido o más clientes usando suscripciones.
Identifica la audiencia y el nivel de lectura
Tu lector principal suele ser un cliente no técnico que quiere saber:
- ¿Funciona el producto ahora?
- ¿Qué está afectado (login, API, facturación, etc.)?
- ¿Qué debo hacer ahora?
- ¿Cuándo se arreglará?
Eso significa minimizar la jerga. Prefiere “Algunos clientes no pueden iniciar sesión” antes que “Aumento de tasas 5xx en auth”. Si necesitas detalle técnico, mantenlo como una oración secundaria corta.
Elige tono, reglas y responsabilidad
Escoge un tono que puedas mantener bajo presión: calmado, factual y transparente. Decide por adelantado:
- Quién puede publicar actualizaciones (un rol único o una rotación on‑call)
- Quién aprueba actualizaciones (si aplica) y cuánto puede tardar la aprobación
- Frecuencia mínima de actualizaciones durante un incidente activo (por ejemplo, cada 30 minutos)
Haz explícita la propiedad: la página de estado no debería ser “trabajo de todos”, porque entonces no será de nadie.
Decide dónde reside
Tienes dos opciones comunes:
- Sitio independiente (por ejemplo, status.tuempresa.com): separación más clara y a menudo más resistente a caídas
- Subruta (por ejemplo, /status): branding y analítica más simples
Si tu app principal puede caer, un sitio independiente suele ser más seguro. Aun así, puedes enlazarlo prominentemente desde tu app y centro de ayuda (por ejemplo, /help).
Mapea tus servicios y el modelo de estado de componentes
Una página de estado solo es útil como lo es el “mapa” detrás de ella. Antes de elegir colores o escribir copy, decide sobre qué vas a informar. El objetivo es reflejar cómo los clientes experimentan tu producto —no cómo está organizada tu org chart.
Empieza con un inventario de componentes
Lista las piezas que un cliente podría describir cuando dice “está roto”. Para muchos productos SaaS, un conjunto práctico inicial es:
- API
- Web app
- Dashboard / admin
- Autenticación (login, SSO)
- Facturación
- Integraciones (Slack, Salesforce, webhooks, etc.)
Si ofreces múltiples regiones o planes, inclúyelo también (por ejemplo, “API – US” y “API – EU”). Usa nombres entendibles para clientes: “Login” es más claro que “IdP Gateway”.
Decide cómo agrupar componentes
Elige una agrupación que coincida con cómo piensan los clientes sobre tu servicio:
- Por producto: mejor si tienes ofertas distintas (Producto A vs. Producto B)
- Por región: mejor si la disponibilidad varía por geografía
- Por función/flujo: mejor si los clientes dependen de trabajos específicos (Reporting, Imports, Notifications)
Evita listas interminables. Si tienes docenas de integraciones, considera un componente padre (“Integraciones”) más algunos hijos de alto impacto (p. ej., “Salesforce”, “Webhooks”).
Define tus niveles de estado (y qué significan)
Un modelo simple y coherente evita confusión durante incidentes. Niveles comunes incluyen:
- Operational: funcionando como se espera
- Degraded Performance: más lento de lo normal o errores intermitentes
- Partial Outage: un subconjunto significativo de usuarios/funciones no está disponible
- Major Outage: el servicio está ampliamente indisponible
Escribe criterios internos para cada nivel (aunque no los publiques). Por ejemplo, “Partial Outage = una región caída” o “Degraded = latencia p95 por encima de X durante Y minutos.” La consistencia genera confianza.
Captura dependencias — y decide qué mostrar
La mayoría de las caídas implican terceros: hosting en la nube, entrega de email, procesadores de pago o proveedores de identidad. Documenta estas dependencias para que tus actualizaciones sean precisas.
Si mostrarlas públicamente depende de tu audiencia. Si los clientes pueden verse afectados directamente (p. ej., pagos), mostrar una dependencia puede ser útil. Si añade ruido o provoca culpar a terceros, mantiene las dependencias internas pero refiérete a ellas en las actualizaciones cuando sea relevante (por ejemplo, “Investigamos errores elevados en nuestro proveedor de pagos”).
Con este modelo de componentes, el resto de la configuración de la página de estado se vuelve mucho más sencillo: cada incidente tiene un “dónde” (componente) y “qué tan grave” (estado) desde el inicio.
Diseña una página de estado simple y amigable para el cliente
Una página de estado es más útil cuando responde las preguntas del cliente en segundos. La gente suele llegar estresada y quiere claridad, no mucha navegación.
Empieza con lo que los clientes necesitan primero
Prioriza lo esencial en la parte superior:
- Estado actual: ¿está todo operativo, degradado o caído?
- Impacto: qué está afectado (quién/regiones/funciones) y qué podrían experimentar los usuarios
- ETA (si la tienes): ten cuidado — comparte solo estimaciones que puedas defender
- Próxima actualización: una promesa específica como “Próxima actualización antes de 14:30 UTC” reduce tickets repetidos
Escribe en lenguaje llano. “Tasas de error elevadas en solicitudes API” es más claro que “Partial outage in upstream dependency.” Si debes usar términos técnicos, añade una breve traducción (“Algunas solicitudes pueden fallar o agotar tiempo”).
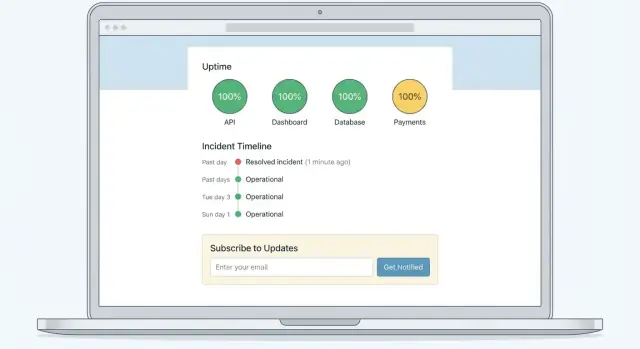
Usa un diseño simple y fácil de escanear
Un patrón fiable es:
- Banner superior para el estado global (All Systems Operational / Degraded Performance / Major Outage)
- Lista de componentes con estados claros (Web App, API, Billing, Integrations, etc.)
- Incidentes activos y mantenimientos programados justo debajo, ordenados por la actualización más reciente
Para la lista de componentes, usa etiquetas orientadas al cliente. Si tu servicio interno se llama “k8s-cluster-2”, los clientes probablemente necesitan “API” o “Background Jobs”.
Accesibilidad y fundamentos móviles
Haz la página legible bajo presión:
- Alto contraste de color y etiquetas de texto (no te bases solo en el color)
- Iconos claros con significado consistente (p. ej., verde = operativo, amarillo = degradado, rojo = caída)
- Espaciado y objetivos táctiles amigables para móviles; muchos usuarios comprobarán el estado desde su teléfono
Añade enlaces rápidos donde la gente los espera
Coloca un conjunto pequeño de enlaces cerca de la parte superior (en el header o justo bajo el banner):
- Subscribe (para notificaciones por email/SMS/webhook)
- Incident History (para incidentes pasados y líneas temporales)
- Contact Support en /support
El objetivo es confianza: los clientes deben entender de inmediato qué sucede, qué afecta y cuándo volverán a tener noticias.
Crea plantillas de actualizaciones para incidentes y mantenimientos
Cuando ocurre un incidente, tu equipo está entre diagnóstico, mitigación y preguntas de clientes al mismo tiempo. Las plantillas eliminan la incertidumbre para que las actualizaciones sean coherentes, claras y rápidas —especialmente cuando distintas personas pueden publicar.
Define los campos del incidente que siempre publicarás
Una buena actualización parte de los mismos hechos cada vez. Como mínimo, estandariza estos campos para que los clientes entiendan rápidamente qué ocurre:
- Hora de inicio del incidente (con zona horaria)
- Componentes/servicios afectados (mapeados a tu modelo)
- Impacto para el cliente (quién está afectado y cómo)
- Estado actual (Investigating, Identified, Monitoring, Resolved)
- Registro de actualizaciones (entradas con marca temporal)
- Hora de resolución (cuando el servicio volvió a la normalidad)
Si publicas una página de historial, mantener estos campos consistentes facilita escanear y comparar incidentes pasados.
Usa una plantilla simple y repetible para las actualizaciones
Apunta a actualizaciones cortas que respondan las mismas preguntas cada vez. Aquí tienes una plantilla práctica que puedes copiar en tu herramienta de status page:
Title: Resumen breve y específico (p. ej., “Errores en API para la región EU”)
Start time: YYYY-MM-DD HH:MM (TZ)
Affected components: API, Dashboard, Payments
Impact: Qué ven los usuarios (errores, timeouts, rendimiento degradado) y quién está afectado
What we know: Una frase sobre la causa si está confirmada (evita especular)
What we’re doing: Acciones concretas (rollback, escalado, escalado con proveedor)
Next update: Hora en la que publicarás otra vez
Updates:
- HH:MM (TZ) — Investigating: …
- HH:MM (TZ) — Identified: …
- HH:MM (TZ) — Monitoring: …
- HH:MM (TZ) — Resolved: …
Establece reglas claras de cadencia de actualizaciones
Los clientes no solo quieren información: quieren previsibilidad.
- Para incidentes mayores, comprométete a actualizaciones cada 30–60 minutos, incluso si la actualización es “Seguimos investigando; sin ETA; próxima actualización X.”
- Para problemas menores, puedes publicar con menos frecuencia, pero siempre promete una “próxima actualización”.
- Si no puedes mantener la cadencia, publica una nota rápida reconociendo el retraso y reajustando expectativas.
Añade plantillas para anuncios de mantenimiento
El mantenimiento programado debe sentirse tranquilo y estructurado. Estandariza los posts de mantenimiento con:
- Ventana de mantenimiento: hora de inicio/fin (con zona horaria)
- Impacto esperado: none / degraded / intermittent / downtime
- Componentes afectados
- Acciones del cliente (si las hay): “No se requiere acción” o pasos claros
- Actualización recordatoria: un post breve al comenzar y otro al finalizar
Mantén el lenguaje del mantenimiento específico (qué cambia, qué notarán los usuarios) y evita prometer de más —los clientes valoran la precisión sobre el optimismo.
Construye un historial de incidentes fácil de escanear
Un historial de incidentes es más que un log: es una forma para que clientes (y tu equipo) entiendan con rapidez con qué frecuencia ocurren problemas, qué tipos de problemas se repiten y cómo respondéis.
Por qué merece la pena el historial de incidentes
Un historial claro genera confianza mediante la transparencia. También crea visibilidad de tendencias: si ves “latencia API” recurrente cada pocas semanas, es una señal para invertir en rendimiento (y priorizar revisiones post‑incidente). Con el tiempo, el reporte consistente puede reducir tickets porque los clientes se autosirven.
Decide retención: ¿cuánto atrás lo guardas?
Elige una ventana de retención que encaje con las expectativas de tus clientes y la madurez del producto.
- 90 días: común en SaaS en etapa temprana, mantiene la página ligera
- 6–12 meses: mejor para compradores enterprise que evalúan fiabilidad
- Más tiempo: considera exportar registros antiguos a una página de archivo separada si la línea temporal se vuelve ruidosa
Sea lo que sea, indícalo claramente (por ejemplo: “Incident history is retained for 12 months”).
Haz que cada entrada sea entendible de un vistazo
La consistencia facilita el escaneo. Usa un formato predecible como:
YYYY-MM-DD — Resumen corto (p. ej., “2025-10-14 — Entrega de email retrasada”)
Para cada incidente, muestra al menos:
- componentes afectados
- hora de inicio/fin (con zona horaria)
- nivel de impacto (minor/major)
- una nota breve de resolución
Enlaza a contexto más profundo cuando esté disponible
Si publicas postmortems, enlaza desde el detalle del incidente al informe (por ejemplo: “Read the postmortem” enlazando a /blog/postmortems/2025-10-14-email-delays). Esto mantiene la línea temporal limpia y ofrece detalle para clientes que lo deseen.
Añade suscripciones y notificaciones
Una página de estado ayuda cuando los clientes recuerdan consultarla. Las suscripciones lo cambian: los clientes reciben actualizaciones automáticamente, sin actualizar la página o escribir al soporte para confirmar.
Ofrece los canales que ya usan tus clientes
La mayoría de equipos esperan al menos un par de opciones:
- Email (el canal por defecto para muchos clientes)
- SMS (mejor para alertas urgentes y de alta señal)
- Slack o Microsoft Teams (ideal para clientes business y equipos de ops)
- RSS/Atom (aún popular entre usuarios técnicos y para tooling interno)
Si soportas varios canales, mantén el flujo de configuración consistente para que los clientes no sientan que se suscriben de cuatro formas distintas.
Haz que la suscripción y las preferencias sean cristalinas
Las suscripciones deben ser siempre opt‑in. Sé explícito sobre lo que recibirán antes de confirmar—especialmente para SMS.
Da control a los suscriptores sobre:
- Alcance: todos los incidentes vs. solo componentes seleccionados (p. ej., “API” pero no “Marketing site”)
- Tipo: solo incidentes, solo mantenimientos o ambos
- Severidad (opcional): solo “Major outage” vs. “Todas las actualizaciones”
Estas preferencias reducen la fatiga de alertas y mantienen la confianza en las notificaciones. Si no tienes suscripciones por componente todavía, empieza con “All updates” y añade filtrado más tarde.
Evita que las notificaciones fallen en el momento crucial
Durante un incidente, el volumen de mensajes se dispara y los proveedores terceros pueden aplicar throttling. Verifica:
- Entregabilidad: SPF/DKIM/DMARC para email; dominios de envío verificados; direcciones “from” reconocibles
- Límites y throttling: topes de tu proveedor de email/SMS, límites de webhooks de Slack/Teams y comportamiento de reintentos
- Fallbacks: si fallan los posts a Slack, ¿sigues enviando email? Si SMS se retrasa, ¿muestras un banner claro en la página de estado?
Vale la pena ejecutar una prueba programada (incluso trimestral) para asegurar que las suscripciones funcionan como es debido.
Pon “Subscribe to updates” donde nadie pueda perderlo
Añade un llamado claro a la suscripción en la página de estado —por encima del pliegue si es posible— para que los clientes se suscriban antes del próximo incidente. Hazlo visible en móvil e inclúyelo en lugares donde los clientes buscan ayuda (como un enlace desde tu portal de soporte o el /help center).
Elige un método de construcción: herramienta alojada vs. DIY
Elegir cómo construir tu página de estado no es tanto “¿podemos construirla?” sino qué quieres optimizar: rapidez de lanzamiento, fiabilidad durante incidentes y esfuerzo de mantenimiento.
Opción 1: usar una herramienta de status page alojada
Una herramienta alojada suele ser la ruta más rápida. Obtienes una página de estado lista, suscripciones, líneas de tiempo de incidentes y a menudo integraciones con sistemas de monitorización comunes.
Qué buscar en una herramienta alojada:
- Fiabilidad e independencia: la página de estado debe ser accesible incluso si vuestra app principal está caída
- API y automatización: crear incidentes, actualizar componentes y publicar avances vía API o webhooks
- Control de acceso: roles para quién puede publicar vs. quién puede borradores; SSO es un plus
- Branding y dominio personalizado: logo/colores y dominio como status.tuempresa.com
- Analítica: número de suscriptores, vistas de actualizaciones y métricas de entrega de email (útil para mejorar comunicación)
- Necesidades de compliance: logs de auditoría y retención si operas en entornos regulados
Opción 2: construirlo internamente (DIY)
DIY puede ser buena si quieres control total sobre diseño, retención de datos y cómo se presenta el historial de incidentes. El intercambio es que tú eres responsable de la fiabilidad y operación.
Una arquitectura práctica DIY es:
- Sitio estático (rápido y amigable con caché) para la interfaz de estado y páginas de historial
- Fuente de datos con API (o un CMS ligero) que almacene incidentes, componentes y actualizaciones
- Caché agresivo + CDN para que la página de estado aguante picos de tráfico durante una caída
Si te autoalojas, planifica modos de fallo: ¿qué pasa si tu base de datos principal está inaccesible o tu pipeline de deploy no funciona? Muchos equipos mantienen la página de estado en infraestructura separada (o incluso en un proveedor distinto) a la app principal.
Si quieres el control del DIY sin reconstruir todo, una plataforma de estilo “vibe‑coding” como Koder.ai puede ayudarte a levantar un sitio de estado personalizado (UI web más una pequeña API de incidentes) rápidamente desde una especificación guiada por chat. Eso es útil para equipos que quieren modelos de componente a medida, UX de historial personalizada o flujos administrativos internos—y poder exportar código, desplegar e iterar con rapidez.
Planificación de costes
Las herramientas alojadas tienen precios mensuales previsibles; DIY implica tiempo de ingeniería, costes de hosting/CDN y mantenimiento continuo. Si comparas opciones, plantea el gasto mensual esperado y el tiempo interno requerido—luego compáralo con vuestro presupuesto (ver /pricing).
Conecta monitorización y flujo de incidentes
Una página de estado solo es útil si refleja la realidad con rapidez. La forma más sencilla de lograrlo es conectar los sistemas que detectan problemas (monitorización) con los que coordinan la respuesta (workflow de incidentes), para que las actualizaciones sean coherentes y oportunas.
De dónde deben venir las actualizaciones
La mayoría de equipos combinan tres fuentes de datos:
- Alertas de monitorización (health checks, tests sintéticos, tasas de error, latencia, profundidad de colas). Son excelentes para detección, pero no siempre describen el impacto al cliente.
- Actualizaciones manuales del on‑call o del equipo de soporte. Los humanos añaden contexto: quién está afectado, cuál es el workaround, qué cambió.
- Herramientas de gestión de incidentes (PagerDuty, Opsgenie, Jira Service Management, etc.). Proporcionan la línea temporal, roles y notas de resolución que la página de estado puede resumir.
Una regla práctica: la monitorización detecta; el workflow coordina; la página de estado comunica.
Automatización útil (sin prometer de más)
La automatización puede ahorrar minutos cuando importa:
- Crear un incidente desde una alerta cuando un monitor de alta severidad se dispara (p. ej., “tasa de errores API > 5% por 5 minutos”). Prefill título, componentes afectados y severidad inicial.
- Actualizar componentes desde health checks para señales objetivas (p. ej., “Web app: Degraded Performance” cuando se superan umbrales de latencia).
- Sincronizar cambios de estado a tu canal de incidentes (Slack/Teams) para que los respondedores vean lo mismo que los clientes.
Mantén el primer mensaje público conservador. “Investigating elevated errors” es más seguro que “Outage confirmed” cuando aún estás validando.
No automatices todo sin revisión humana
La mensajería totalmente automática puede fallar:
- Una alerta ruidosa puede publicar incidentes falsos.
- Un fallo parcial puede parecer “caído” para un monitor pero ser tolerable para clientes.
- Actualizaciones auto‑resueltas pueden cerrar un incidente mientras los usuarios siguen afectados.
Usa la automatización para crear borradores y sugerencias, pero exige revisión humana para el lenguaje visible al cliente —especialmente en los estados Identified, Mitigated y Resolved.
Mantén una pista de auditoría
Trata la página de estado como una bitácora visible al cliente. Asegura que puedas responder:
- ¿Quién cambió el estado del incidente?
- ¿Qué se cambió (texto, componentes, marcas temporales)?
- ¿Cuándo se cambió?
Esta pista de auditoría ayuda en la revisión post‑incidente, reduce la confusión durante los traspasos y genera confianza cuando los clientes piden aclaraciones.
Hazla fiable: hosting, DNS y protecciones contra caídas
Una página de estado solo ayuda si es accesible cuando tu producto no lo está. El fallo más común es construir la página de estado sobre la misma infraestructura que la app—entonces cuando la app cae, la página de estado desaparece también.
Aísla la página de tu stack principal
Siempre que sea posible, hospeda la página de estado en un proveedor diferente al de la app (o al menos en otra región/cuenta). El objetivo es separación del radio de explosión: una caída en la plataforma de la app no debería tirar también las comunicaciones de incidentes.
Considera también separar el DNS. Si el DNS de tu dominio principal está gestionado en el mismo lugar que el edge/CDN de tu app, un problema de DNS o certificado puede bloquear ambos a la vez. Muchos equipos usan un subdominio dedicado (por ejemplo, status.tuempresa.com) con DNS gestionado de forma independiente.
Haz la página rápida y resiliente
Mantén los assets ligeros: JavaScript mínimo, CSS comprimido y sin dependencias que requieran las APIs de tu app para renderizar. Pon un CDN delante y activa caché para recursos estáticos para que cargue incluso con mucho tráfico.
Una red de seguridad práctica es un modo estático de fallback:
- prerender la última información conocida y el banner de incidente
- servirlo desde object storage o hosting estático
- actualizar dinámicamente cuando los sistemas estén sanos, pero degradar con gracia cuando no lo estén
Pública por defecto, con acceso admin seguro
Los clientes no deberían tener que iniciar sesión para ver la salud del servicio. Mantén la página de estado pública, pero protege las herramientas de administración/edición tras autenticación (SSO si lo tienes), con controles de acceso y logs de auditoría.
Finalmente, prueba escenarios de fallo: bloquea temporalmente tu origen de app en staging y confirma que la página de estado sigue resolviendo, carga rápido y puede actualizarse cuando más la necesitas.
Proceso operativo: quién actualiza y cuándo
Una página de estado solo genera confianza si se actualiza consistentemente durante incidentes reales. Esa consistencia no surge por accidente: necesitas propiedad clara, reglas sencillas y cadencia predecible.
Define los roles (antes de que algo falle)
Mantén el equipo central pequeño y explícito:
- Incident Commander (IC): dirige la respuesta, decide prioridades y confirma cuando estáis estables
- Communications Lead: publica actualizaciones en la página de estado y hace el lenguaje amigable para clientes
- Ingenieros on‑call: investigan, mitigan y pasan hechos confirmados al IC
Si eres un equipo pequeño, una persona puede asumir dos roles—solo decídelo por adelantado. Documenta traspasos de roles y rutas de escalado en tu manual on‑call (ver /docs/on-call).
Una checklist simple de actualización para seguir cada vez
Cuando una alerta se convierte en incidente con impacto al cliente, sigue un flujo repetible:
- Acknowledge: publica una actualización de “Investigating” rápido (aunque los detalles sean limitados)
- Assess impact: confirma qué componentes, regiones o segmentos de clientes están afectados
- Post update: comparte qué notarán los usuarios, workarounds (si los hay) y cuándo actualizarás de nuevo
- Resolve: confirma que el servicio se ha restaurado y qué estás monitorizando
- Recap: añade un resumen corto y enlaza la revisión completa cuando esté disponible
Una regla práctica: publica la primera actualización dentro de 10–15 minutos, luego cada 30–60 minutos mientras dure el impacto —incluso si el mensaje es “Sin cambios, seguimos investigando.”
Tras la resolución: revisar y mejorar
Dentro de 1–3 días hábiles, realiza una revisión post‑incidente ligera:
- Timeline: eventos clave desde la detección hasta la recuperación
- Causa raíz (mejor conocida): explícalo en lenguaje llano
- Acciones: arreglos específicos, responsables y fechas
Luego actualiza la entrada del incidente con el resumen final para que el historial sea útil, no solo un registro de “resuelto”.
Checklist de lanzamiento y mejoras continuas
Una página de estado solo es útil si es fácil de encontrar, confiable y se actualiza consistentemente. Antes de anunciarla, haz un repaso “ready for production” —y luego establece una cadencia ligera para mejorarla con el tiempo.
Checklist de lanzamiento (la versión práctica)
Copy y estructura
- Confirma que los nombres de componentes coinciden con lo que reconocen los clientes (p. ej., “Dashboard” vs. nombres internos).
- Añade una breve introducción “Qué muestra esta página” y un enlace claro al soporte (p. ej., /support) para problemas específicos de cuenta.
- Asegura que las actualizaciones de incidentes expliquen el impacto para el cliente (“pagos fallando”) y den siguientes pasos (“reintentar en 10 minutos”).
Branding y confianza
- Añade logo, favicon y un sistema de colores simple para estados (evita tonos demasiado sutiles).
- Incluye formato de marca temporal claro y zona horaria.
Acceso y permisos
- Verifica quién puede publicar incidentes, programar mantenimientos y editar ajustes de la página.
- Configura un “backup on‑call” para que las actualizaciones no se bloqueen por una sola persona.
Prueba el flujo completo
- Ejecuta un incidente de prueba (márcalo como test y déjalo claramente etiquetado).
- Suscríbete vía email/SMS y confirma que las notificaciones llegan e incluyen enlaces correctos.
Anunciar
- Añade el enlace de la página de estado en el footer de la app, centro de ayuda y respuestas automáticas de soporte.
- Envía un anuncio corto a clientes explicando qué esperar y cómo suscribirse.
Si construyes tu propio sitio de estado, considera ejecutar la misma checklist en staging primero. Herramientas como Koder.ai pueden acelerar este ciclo generando UI web, pantallas admin y endpoints backend desde una sola spec —y permitiéndote exportar el código y desplegar donde necesites.
Mide qué significa “mejor”
Sigue unos pocos resultados simples y revísalos mensualmente:
- Tickets reducidos: compara volumen de tickets relacionados con incidentes antes/después del lanzamiento
- Primera actualización más rápida: mide tiempo desde detección hasta la primera actualización pública
- Crecimiento de suscriptores: rastrea suscriptores por canal y qué componentes siguen
Aprende de patrones de incidentes
Mantén una taxonomía básica para que el historial sea accionable:
- Etiqueta incidentes por categoría (rendimiento, partial outage, tercero, mantenimiento, seguridad)
- Anota componentes recurrentes y repetidores
- Usa esto para priorizar arreglos e informar el proceso de post‑incident review
Básicos de SEO (para que los clientes encuentren la página)
- Usa títulos claros como “Service Status” e “Incident History.”
- Mantén las cabeceras estructuradas (H2/H3) para que las páginas de historial sean fáciles de escanear.
- Prefiere páginas de historial indexables (salvo razones de seguridad/privacidad) y asegúrate de que los enlaces entre la página de estado principal y cada incidente sean rastreables.
Con el tiempo, pequeñas mejoras —redacción más clara, actualizaciones más rápidas, mejor categorización— se acumulan en menos interrupciones, menos tickets y más confianza del cliente.