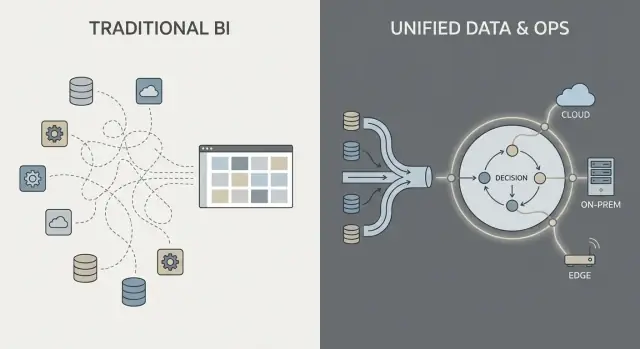
Qué significan aquí “Palantir” y “software empresarial tradicional"
La gente suele usar “Palantir” como atajo para unos pocos productos relacionados y una forma general de construir operaciones basadas en datos. Para que esta comparación sea clara, ayuda nombrar qué se está discutiendo realmente —y qué no.
A qué se refiere “Palantir” en este artículo
Cuando alguien dice “Palantir” en un contexto empresarial, normalmente se refiere a uno (o más) de estos:
- Foundry: la plataforma comercial de Palantir, centrada en integrar datos, modelarlos y habilitar la toma de decisiones operativas.
- Gotham: a menudo asociada a casos de defensa y sector público, con temas similares pero diferente historia y posicionamiento.
- Apollo: un sistema de despliegue y entrega usado para enviar y gestionar software en muchos entornos (incluidos los restringidos).
Este artículo usa “estilo Palantir” para describir la combinación de (1) fuerte integración de datos, (2) una capa semántica/ontológica que alinea a los equipos sobre el significado, y (3) patrones de despliegue que pueden abarcar cloud, on‑prem y entornos desconectados.
Qué significa “software empresarial tradicional” aquí
“Software empresarial tradicional” no es un producto único: es la pila típica que muchas organizaciones ensamblan con el tiempo, como por ejemplo:
- Sistemas ERP y CRM (sistemas de registro para finanzas, cadena de suministro, ventas)
- Un almacén o lago de datos más dashboards BI (sistemas para reporting y análisis)
- Middleware de integración (herramientas ETL/ELT, iPaaS, colas de mensajes, APIs)
En este enfoque, integración, analítica y operaciones con frecuencia las manejan herramientas y equipos separados, conectados mediante proyectos y procesos de gobierno.
Qué es (y qué no es) esta comparación
Se trata de una comparación de enfoques, no de una recomendación de proveedor. Muchas organizaciones tienen éxito con pilas convencionales; otras se benefician de un modelo de plataforma más unificado.
La pregunta práctica es: ¿qué concesiones haces en velocidad, control y en cuán directamente la analítica se conecta con el trabajo diario?
Para mantener el resto del artículo con los pies en la tierra, nos centraremos en tres áreas:
- Integración de datos: cómo se conectan, mantienen y asignan responsabilidades por los datos
- Analítica operativa: cómo el análisis va más allá de los dashboards hacia las decisiones
- Modelos de despliegue: cloud, on‑prem y realidades desconectadas
Integración de datos: pipelines y responsabilidades
La mayor parte del trabajo de datos en “software empresarial tradicional” sigue una cadena familiar: extraer datos de sistemas (ERP, CRM, logs), transformarlos, cargarlos en un almacén o lago, y luego construir dashboards BI más algunas aplicaciones downstream.
Ese patrón puede funcionar bien, pero con frecuencia convierte la integración en una serie de traspasos frágiles: un equipo posee los scripts de extracción, otro los modelos del almacén, un tercero las definiciones de dashboard, y los equipos de negocio mantienen hojas de cálculo que silenciosamente redefinen “el número real”.
El patrón tradicional: ETL/ELT como una carrera de relevos
Con ETL/ELT, los cambios tienden a propagarse. Un campo nuevo en el sistema fuente puede romper una pipeline. Un “arreglo rápido” crea una segunda pipeline. Pronto tienes métricas duplicadas (“ingresos” en tres lugares), y no está claro quién es responsable cuando los números no coinciden.
El procesamiento por lotes es común: los datos aterrizan por la noche y los dashboards se actualizan por la mañana. El casi‑tiempo‑real es posible, pero a menudo se convierte en una pila de streaming separada con sus propias herramientas y responsables.
El patrón estilo Palantir: integrar, estandarizar el significado y reutilizar en todas partes
Un enfoque tipo Palantir busca unificar fuentes y aplicar semántica consistente (definiciones, relaciones y reglas) más temprano, y luego exponer los mismos datos curados a la analítica y a los flujos operativos.
En términos sencillos: en lugar de que cada dashboard o app “averigüe” qué es un cliente, un activo, un caso o un envío, ese significado se define una vez y se reutiliza. Esto puede reducir la lógica duplicada y aclarar la responsabilidad—porque cuando una definición cambia, sabes dónde vive y quién la aprueba.
Puntos de dolor comunes a vigilar
La integración suele fallar por responsabilidades, no por conectores:
- Pipelines frágiles que se rompen con pequeños cambios en la fuente
- Métricas duplicadas definidas de forma distinta entre equipos
- Propiedad poco clara de la calidad de datos, definiciones y arreglos
La pregunta clave no es solo “¿Podemos conectar con el sistema X?” sino “¿Quién posee la pipeline, las definiciones de métricas y el significado del negocio a lo largo del tiempo?”
Capa semántica y ontología: un centro de gravedad distinto
El software empresarial tradicional a menudo trata el “significado” como una idea secundaria: los datos se almacenan en muchos esquemas específicos de aplicaciones, las definiciones de métricas viven dentro de dashboards individuales y los equipos mantienen en silencio sus propias versiones de “qué es un pedido” o “cuándo se considera resuelto un caso.” El resultado es conocido: números diferentes en distintos sitios, reuniones lentas de conciliación y responsabilidad poco clara cuando algo falla.
Ontología, explicada en términos sencillos
En un enfoque tipo Palantir, la capa semántica no es solo una comodidad de reporting. Una ontología actúa como un modelo de negocio compartido que define:
- Entidades (cosas que le importan al negocio): Pedido, Cliente, Activo, Envío, Caso
- Relaciones (cómo se conectan esas cosas): un Pedido pertenece a un Cliente; un Envío cumple un Pedido; un Activo está instalado en un Sitio
- Acciones (qué hacen las personas con ellas): aprobar, despachar, escalar, retirar, reembolsar
Esto se convierte en el “centro de gravedad” para analítica y operaciones: pueden seguir existiendo múltiples fuentes de datos, pero se mapean a un conjunto común de objetos de negocio con definiciones coherentes.
Por qué la semántica importa más de lo que se espera
Un modelo compartido reduce los números desajustados porque los equipos no reinventan definiciones en cada informe o aplicación. También mejora la responsabilidad: si “Entrega a tiempo” se define contra eventos de Envío en la ontología, queda más claro quién posee los datos subyacentes y la lógica de negocio.
Ejemplos prácticos que puedes imaginar
- Pedidos: Ventas, finanzas y soporte ven el mismo objeto Pedido, incluyendo estado, valor, aprobaciones y excepciones—sin tablas de “pedido” separadas por departamento.
- Activos: Mantenimiento, operaciones y cumplimiento comparten un único registro de Activo con ubicación, historial de inspecciones y banderas de riesgo.
- Casos: Los casos de soporte se conectan a clientes, pedidos y envíos, de modo que las reglas de escalado y métricas de servicio no divergen por equipo.
Bien hecha, una ontología no solo limpia dashboards—acelera y reduce conflictos en decisiones del día a día.
Analítica operativa vs dashboards BI
Los dashboards BI y el reporting tradicional se centran principalmente en la retrospectiva y el monitoreo. Responden preguntas como “¿Qué pasó la semana pasada?” o “¿Vamos en línea con los KPI?” Un dashboard de ventas, un reporte de cierre financiero o un cuadro de mando ejecutivo son valiosos, pero a menudo se quedan en visibilidad.
La analítica operativa es distinta: es analítica incrustada en decisiones y ejecución diarias. En lugar de un “destino de analítica” separado, el análisis aparece dentro del flujo de trabajo donde se realiza el trabajo y empuja hacia un siguiente paso específico.
BI: observar y explicar
El BI/reporting típicamente se enfoca en:
- Métricas estandarizadas y definiciones de KPI
- Actualizaciones programadas y revisiones semanales/mensuales
- Vistas agregadas (equipos, regiones, periodos)
- Exploración de causa raíz después de que se conocen los resultados
Eso es excelente para gobierno, gestión del desempeño y responsabilidad.
Analítica operativa: decidir y hacer
La analítica operativa se centra en:
- Señales en tiempo real o casi real
- Soporte de decisiones en el momento de la acción
- Recomendaciones, priorización y manejo de excepciones
- Bucles de feedback (¿la acción funcionó y qué cambió?)
Los ejemplos concretos parecen menos un “gráfico” y más una cola de trabajo con contexto:
- Despacho: elegir qué trabajo enviar a qué equipo dado ubicación, habilidad, SLA y disponibilidad de piezas
- Asignación de inventario: decidir dónde enviar stock limitado para reducir faltantes y entregas perdidas
- Triage de fraude: priorizar casos por riesgo y enrutarlos a investigadores con la evidencia adecuada
- Planificación de mantenimiento: predecir fallos y programar paradas alrededor de restricciones de producción
El cambio clave: de “ver” a “actuar”
El cambio más importante es que el análisis está ligado a un paso específico del flujo de trabajo. Un dashboard BI puede mostrar “las entregas tardías han aumentado.” La analítica operativa convierte eso en “aquí están los 37 envíos en riesgo hoy, las causas probables y las intervenciones recomendadas,” con la capacidad de ejecutar o asignar la siguiente acción de inmediato.
De los insights a las acciones: diseño centrado en workflows
La analítica empresarial tradicional suele acabar en una vista de dashboard: alguien detecta un problema, exporta a CSV, envía un email y un equipo separado “hace algo” más tarde. Un enfoque tipo Palantir está diseñado para acortar esa brecha incrustando la analítica directamente en el flujo de trabajo donde se toman las decisiones.
Decisiones con humano en el circuito (no piloto automático)
Los sistemas centrados en workflows suelen generar recomendaciones (por ejemplo, “prioriza estos 12 envíos”, “marca estos 3 proveedores”, “programa mantenimiento en 72 horas”) pero aún requieren aprobaciones explícitas. Ese paso de aprobación importa porque crea:
- Responsabilidad en la decisión: quién aprobó, cuándo y con qué datos
- Rastros de auditoría: una cadena registrada desde datos de entrada → lógica/modelo → recomendación → acción
- Excepciones controladas: los operadores pueden anular con una razón, en lugar de trabajar fuera de la herramienta
Esto es especialmente útil en entornos regulados o de alto riesgo donde “porque el modelo lo dijo” no es una justificación aceptable.
En lugar de tratar la analítica como un destino separado, la interfaz puede dirigir insights a tareas: asignar a una cola, solicitar firma, enviar una notificación, abrir un caso o crear una orden de trabajo. El cambio importante es que los resultados se rastrean dentro del mismo sistema—por lo que puedes medir si las acciones realmente redujeron riesgo, costo o retrasos.
Experiencias por rol y derechos de decisión
El diseño centrado en workflows suele separar las experiencias por rol:
- Operadores de primera línea: colas rápidas, siguiente mejor acción clara, contexto mínimo necesario
- Analistas: mayor capacidad de profundizar, pruebas de escenario y monitoreo de calidad de datos/modelos
- Ejecutivos: KPI ligados al throughput operativo y a los cuellos de botella, no solo a gráficos
El factor común de éxito es alinear el producto con los derechos de decisión y procedimientos operativos: quién puede actuar, qué aprobaciones se requieren y qué significa “hecho” operativamente.
Gobernanza, seguridad y confianza en los datos
Unifica el significado
Modela Orders, Assets y Cases como objetos compartidos que tus equipos pueden reutilizar.
La gobernanza es donde muchos programas de analítica triunfan o se estancan. No es solo “ajustes de seguridad”: es el conjunto práctico de reglas y evidencia que permite a las personas confiar en los números, compartirlos de forma segura y usarlos para tomar decisiones reales.
Qué debe cubrir la gobernanza (más allá del acceso)
La mayoría de las empresas necesitan los mismos controles básicos, independientemente del proveedor:
- Controles de acceso: quién puede ver, editar o aprobar datos, modelos y salidas operativas
- Trazabilidad de datos: de dónde vino una métrica, qué fuentes la alimentaron y qué transformaciones sufrió
- Registros de auditoría: un registro demás para defender quién cambió qué y cuándo
- Aprobaciones y control de cambios: especialmente para métricas “oficiales”, conjuntos de datos compartidos y workflows en producción
No es burocracia por sí misma. Es cómo evitas el problema de “dos versiones de la verdad” y reduces el riesgo cuando la analítica se acerca a las operaciones.
“Seguridad en el dashboard” vs seguridad en toda la cadena
Las implementaciones BI tradicionales a menudo colocan la seguridad principalmente en la capa de informes: los usuarios pueden ver ciertos dashboards y los administradores gestionan permisos allí. Eso puede funcionar cuando la analítica es mayormente descriptiva.
Un enfoque tipo Palantir empuja la seguridad y el gobierno a través de toda la cadena: desde la ingestión de datos crudos, a la capa semántica (objetos, relaciones, definiciones), a los modelos e incluso a las acciones desencadenadas por los insights. La meta es que una decisión operativa (como despachar un equipo, liberar inventario o priorizar casos) herede los mismos controles que los datos que la respaldan.
Principio de menor privilegio y segregación de funciones (en términos sencillos)
Dos principios importan para seguridad y responsabilidad:
- Menor privilegio: las personas obtienen solo el acceso que necesitan para hacer su trabajo
- Segregación de funciones: quien construye o cambia la lógica no es la misma persona que la aprueba para producción
Por ejemplo, un analista puede proponer una definición de métrica, un responsable de datos la aprueba y operaciones la usa—con un rastro de auditoría claro.
Por qué la gobernanza impulsa la adopción
Una buena gobernanza no es solo para equipos de cumplimiento. Cuando los usuarios de negocio pueden inspeccionar la trazabilidad, ver definiciones y confiar en permisos consistentes, dejan de discutir sobre la hoja de cálculo y comienzan a actuar sobre el insight. Esa confianza es lo que convierte la analítica de “informes interesantes” en comportamiento operativo.
Modelos de despliegue: cloud, on‑prem y entornos desconectados
Dónde corre el software empresarial ya no es un detalle de IT: moldea lo que puedes hacer con los datos, qué tan rápido puedes cambiar y qué riesgos puedes aceptar. Los compradores suelen evaluar cuatro patrones de despliegue.
Nube pública
La nube pública (AWS/Azure/GCP) optimiza la velocidad: el aprovisionamiento es rápido, los servicios gestionados reducen trabajo de infra y escalar es sencillo. Las preguntas principales del comprador son residencia de datos (qué región, backups, acceso de soporte), integración con sistemas on‑prem y si tu modelo de seguridad tolera conectividad de red a la nube.
Nube privada
Una nube privada (single‑tenant o Kubernetes/VMs gestionadas por el cliente) se elige cuando necesitas automatización tipo cloud pero con fronteras de red y requisitos de auditoría más estrictos. Puede reducir fricciones de cumplimiento, pero aún necesita disciplina operativa fuerte alrededor de parches, monitorización y revisiones de acceso.
On‑prem
Los despliegues on‑prem siguen siendo comunes en manufactura, energía y sectores muy regulados donde sistemas y datos centrales no pueden salir de la instalación. La contrapartida es la sobrecarga operativa: ciclo de vida del hardware, planificación de capacidad y mayor esfuerzo para mantener entornos consistentes entre dev/test/prod. Si tu organización tiene dificultades para operar plataformas de manera fiable, on‑prem puede ralentizar el time‑to‑value.
Desconectado / air‑gapped
Los entornos desconectados son un caso especial: defensa, infraestructura crítica o sitios con conectividad limitada. Aquí, el modelo de despliegue debe soportar controles estrictos de actualización—artefactos firmados, promoción controlada de releases e instalaciones repetibles en redes aisladas.
Las restricciones de red también afectan el movimiento de datos: en lugar de sincronización continua, puedes depender de transferencias por etapas y flujos de “exportar/importar”.
Las compensaciones clave
En la práctica, es un triángulo: flexibilidad (cloud), control (on‑prem/air‑gapped) y rapidez de cambio (automatización + actualizaciones). La elección correcta depende de reglas de residencia, realidades de red y cuánto trabajo de operaciones de plataforma esté dispuesto a asumir tu equipo.
Poner en marcha actualizaciones: qué cambia una entrega tipo Apollo
Demuestra la ruta de datos
Levanta servicios de Go y PostgreSQL para validar integraciones y reglas de datos.
La “entrega tipo Apollo” es básicamente entrega continua para entornos de alto riesgo: puedes enviar mejoras frecuentemente (semanal, diario, incluso varias veces al día) mientras mantienes las operaciones estables.
El objetivo no es “moverse rápido y romper cosas”. Es “moverse a menudo y no romper nada.”
Entrega continua en términos sencillos
En lugar de agrupar cambios en un gran release trimestral, los equipos entregan actualizaciones pequeñas y reversibles. Cada actualización es más fácil de probar, explicar y revertir si algo falla.
Para la analítica operativa, eso importa porque tu “software” no es solo una UI: son pipelines de datos, lógica de negocio y los workflows de los que depende la gente. Un proceso de actualización más seguro pasa a ser parte de la operación diaria.
Cómo difiere de los ciclos tradicionales empresariales
Las actualizaciones tradicionales suelen parecer proyectos: ventanas largas de planificación, coordinación de downtime, preocupaciones de compatibilidad, reentrenamiento y una fecha de corte. Incluso cuando los proveedores ofrecen parches, muchas organizaciones retrasan actualizaciones porque el riesgo y el esfuerzo son impredecibles.
Las herramientas tipo Apollo buscan que actualizar sea rutinario en lugar de excepcional—más parecido a mantener infraestructura que a ejecutar una migración mayor.
Separar “construir” de “entregar”
Las herramientas modernas de despliegue permiten que los equipos desarrollen y prueben en entornos aislados, y luego “promuevan” la misma build a través de etapas (dev → test → staging → producción) con controles consistentes. Esa separación reduce sorpresas de último minuto causadas por diferencias entre entornos.
Preguntas que hacer al proveedor
- ¿Cómo manejan el rollback—un clic, rollback parcial o pasos complejos de recuperación?
- ¿Qué versionado existe para pipelines, modelos y cambios de ontología (no solo la UI)?
- ¿Cómo funciona la promoción de entornos y quién puede aprobarla?
- ¿Pueden ejecutar canary releases (un subconjunto primero) o feature flags?
- ¿Qué rastro de auditoría muestra quién lanzó qué, cuándo y por qué?
- ¿Cuál es el downtime esperado—idealmente ninguno—para actualizaciones típicas?
Implementación y time‑to‑value: qué requiere realmente esfuerzo
El time‑to‑value es menos sobre qué tan rápido puedes “instalar” algo y más sobre qué tan rápido los equipos pueden ponerse de acuerdo en definiciones, conectar datos desordenados y convertir insights en decisiones diarias.
Estilos de implementación: configurar, ensamblar o construir
El software empresarial tradicional a menudo enfatiza la configuración: adoptas un modelo de datos y workflows predefinidos y mapeas tu negocio a ellos.
Las plataformas tipo Palantir tienden a mezclar tres modos:
- Configuración para controles de acceso, conexiones de datos y componentes estándar
- Bloques reutilizables (plantillas, componentes, patrones) que pueden ensamblarse en nuevos casos de uso
- Desarrollo de aplicaciones a medida cuando el flujo es único (por ejemplo, aprobaciones, manejo de excepciones, traspasos operativos)
La promesa es flexibilidad—pero también significa que necesitas claridad sobre qué estás construyendo frente a qué estás estandarizando.
Una opción práctica durante el descubrimiento temprano es prototipar apps de workflow rápidamente—antes de comprometerse con un despliegue amplio de plataforma. Por ejemplo, los equipos a veces usan Koder.ai (una plataforma de vibe‑coding) para transformar la descripción de un workflow en una app web funcional vía chat, luego iterar con stakeholders usando planning mode, snapshots y rollback. Como Koder.ai soporta exportación de código fuente y stacks de producción típicos (React en web; Go + PostgreSQL en backend; Flutter en móvil), puede ser una forma de baja fricción para validar la UX de “insight → tarea → rastro de auditoría” durante una prueba de valor.
Dónde realmente gastan tiempo los equipos
La mayor parte del esfuerzo suele concentrarse en cuatro áreas:
- Onboarding de datos: lograr que los propietarios de fuente den acceso, documentar campos, manejar brechas de calidad y fijar expectativas de refresco
- Modelado y semántica: ponerse de acuerdo en definiciones de negocio (qué cuenta como “activo”, “tarde”, “disponible”) y mantenerlas consistentes
- Diseño de workflows: decidir quién actúa sobre alertas, qué decisiones están permitidas y qué significa “hecho”
- Formación y adopción: convertir la herramienta en hábito—especialmente para usuarios de primera línea que no tolerarán complejidad
Señales de alerta que retrasan o matan el valor
Vigila la propiedad poco clara (sin owner de datos/producto), demasiadas definiciones a medida (cada equipo inventa sus métricas) y sin camino de piloto a escala (una demo que no puede operacionalizarse, soportarse o gobernarse).
Estructurar un piloto que pueda escalar
Un buen piloto es deliberadamente estrecho: elige un workflow, define usuarios específicos y comprométete con un resultado medible (p. ej., reducir el tiempo de respuesta en 15%, cortar el backlog de excepciones en 30%). Diseña el piloto para que los mismos datos, semántica y controles puedan extenderse al siguiente caso de uso—en lugar de empezar de cero.
Las conversaciones sobre coste pueden ser confusas porque una “plataforma” agrupa capacidades que a menudo se compran como herramientas separadas. La clave es mapear el precio a los resultados que necesitas (integración + modelado + gobernanza + apps operativas), no solo a una línea llamada “software”.
La mayoría de los acuerdos de plataforma se modelan por unas pocas variables:
- Número de usuarios y roles: constructores (ingenieros, modeladores) vs consumidores (operadores, analistas)
- Cómputo y almacenamiento: cargas más pesadas (datos en tiempo real, simulación, joins grandes) elevan costes de infraestructura
- Número de entornos: dev/test/prod, más entornos regulados o desconectados, cada uno añade sobrecarga
- Requisitos de soporte y SLA: soporte 24/7, SLAs de incidente y equipos dedicados de éxito cambian el precio
- Servicios profesionales: onboarding inicial de datos, diseño de ontología y construcción de workflows suelen ser el verdadero coste inicial
Qué ocultan los costes de la pila tradicional
Un enfoque de soluciones puntuales puede parecer más barato al principio, pero el coste total suele repartirse en:
- Múltiples licencias (ETL/ELT, BI, catálogo, gobernanza, workflow, feature store, etc.)
- Trabajo de integración entre herramientas (conectores, identidad, sincronización de metadatos)
- Mantenimiento continuo (upgrades, pipelines rotas, definiciones métricas duplicadas)
Las plataformas suelen reducir la proliferación de herramientas, pero a cambio firmas un contrato más grande y estratégico.
Con una plataforma, la compra debería tratarla como infraestructura compartida: define alcance empresarial, dominios de datos, requisitos de seguridad y hitos de entrega. Pide separación clara entre licencia, cloud/infraestructura y servicios, para poder comparar manzanas con manzanas.
Lista de comprobación simple para presupuestar
- ¿Qué equipos van a construir activamente vs solo ver?
- ¿Qué workflows deben ejecutarse en producción (no solo dashboards)?
- ¿Cuántos entornos y regiones se requieren?
- ¿Hay sitios air‑gapped u offline?
- ¿Crecimiento esperado en volumen de datos/frecuencia de refresco?
- ¿Servicios necesarios para los primeros 90 días?
Si quieres una forma rápida de estructurar supuestos, ve a /pricing.
Cuándo encaja un enfoque tipo Palantir (y cuándo no)
Mantén el control total
Toma el código fuente generado y continúa en tu propia canalización.
Las plataformas tipo Palantir suelen brillar cuando el problema es operativo (la gente necesita tomar decisiones y actuar a través de sistemas), no solo analítico (la gente necesita un informe). La contra es que adoptas un enfoque más “de plataforma”—potente, pero que exige más a tu organización que un despliegue BI simple.
Escenarios con buen encaje
Un enfoque tipo Palantir suele encajar bien cuando el trabajo abarca múltiples sistemas y equipos y no puedes permitirte traspasos frágiles. Ejemplos comunes: coordinación de cadena de suministro, operaciones de fraude y riesgo, planificación de misión, gestión de casos o flotas y mantenimiento—donde los mismos datos deben interpretarse de forma coherente por roles distintos.
También encaja bien cuando los permisos son complejos (acceso a nivel de fila/columna, datos multi‑tenant, reglas need‑to‑know) y cuando necesitas un rastro claro de auditoría de cómo se usaron los datos. Finalmente, funciona bien en entornos regulados o con constraints de despliegue: requisitos on‑prem, despliegues air‑gapped o acreditaciones de seguridad estrictas donde el modelo de despliegue es un requisito de primera clase.
Escenarios con peor encaje
Si el objetivo es principalmente reporting sencillo—KPIs semanales, unos pocos dashboards, cierres financieros básicos—el BI tradicional sobre un almacén bien gestionado puede ser más rápido y barato.
También puede ser excesivo para conjuntos de datos pequeños, esquemas estables o analítica de un solo departamento donde un equipo controla las fuentes y definiciones, y la acción principal ocurre fuera de la herramienta.
Criterios de decisión (ajuste al problema)
Haz tres preguntas prácticas:
- Urgencia: ¿Los equipos necesitan workflows funcionando en semanas, o es un programa de modernización largo?
- Complejidad de datos: ¿Decisiones clave quedan bloqueadas por definiciones inconsistentes y sistemas fragmentados?
- Capacidad de cambio: ¿Tienes ownership de producto, SMEs y banda ancha de gobernanza para adoptar una plataforma y mantenerla?
Los mejores resultados vienen de tratar esto como “ajuste al problema”, no “una herramienta lo reemplaza todo”. Muchas organizaciones mantienen BI existente para reporting amplio mientras usan un enfoque tipo Palantir para los dominios operativos de mayor riesgo.
Lista de verificación para compradores y siguientes pasos
Comprar una plataforma tipo Palantir vs software tradicional es menos acerca de casillas de características y más sobre dónde caerá el trabajo real: integración, significado compartido (semántica) y uso operativo diario. Usa la siguiente checklist para forzar claridad temprano, antes de quedar atrapado en una implementación larga o en una herramienta puntual estrecha.
Checklist práctica de comparación de proveedores
Pide a cada proveedor que sea específico sobre quién hace qué, cómo se mantiene consistente y cómo se usa en operaciones reales.
- Esfuerzo de integración: ¿Qué fuentes de datos son típicas (ERP, logs, hojas de cálculo, feeds de socios)? ¿Qué viene preconstruido vs personalizado? ¿Quién mantiene las pipelines después del go‑live—IT, ingeniería de datos o el proveedor?
- Consistencia semántica: ¿Cómo evitan que cinco equipos definan “cliente”, “activo” o “listo‑para‑misión” de forma distinta? ¿Pueden mostrar una capa de negocio gobernada (ontología/modelo semántico) y cómo se propagan los cambios?
- Soporte de workflows: ¿Pueden los equipos de primera línea completar una tarea (triage, aprobar, despachar, investigar) dentro del producto, o es “analiza aquí, actúa en otro sitio”? ¿Cómo manejan las excepciones?
- Gobernanza y seguridad: Controles de acceso granulares, registros de auditoría y gestión de políticas—¿pueden los propietarios de datos controlar quién ve qué, a qué granularidad y por qué?
- Restricciones de despliegue: ¿Puede correr en tu entorno requerido (cloud, on‑prem, air‑gapped/desconectado)? ¿Qué se rompe cuando la conectividad es limitada? ¿Cuál es la ruta de actualización?
Preguntas de prueba para demos (no aceptes diapositivas)
- Mostrar trazabilidad: Elige un KPI crítico y traza su camino desde la fuente hasta la métrica final. ¿Dónde puede fallar y cómo lo detectarías?
- Demostrar un workflow de extremo a extremo: Desde datos crudos, luego alerta → decisión → acción → rastro de auditoría. Incluye aprobaciones y “quién cambió qué”.
- Simular una caída/rollback: ¿Qué pasa si una pipeline falla o un release causa una regresión? ¿Pueden revertir limpiamente y con qué rapidez?
Quién debe estar en la sala
Incluye stakeholders que vivirán con las compensaciones:
- IT y dueños de plataforma (propiedad de integración, fiabilidad, coste)
- Seguridad y cumplimiento (controles, auditoría, aprobaciones de despliegue)
- Propietarios/steweards de datos (definiciones, reglas de acceso, responsabilidad)
- Líderes de operaciones (impacto en procesos, adopción)
- Usuarios de primera línea (¿realmente les ayuda a hacer el trabajo más rápido?)
Siguientes pasos
Ejecuta una prueba de valor con tiempo limitado centrada en un workflow operativo de alto riesgo (no un dashboard genérico). Define criterios de éxito por adelantado: tiempo a la decisión, reducción de errores, auditabilidad y propiedad continua del trabajo de datos.
Si quieres más orientación sobre patrones de evaluación, ve a /blog. Para ayuda en acotar una prueba de valor o en la preselección de proveedores, contáctanos en /contact.