Por qué las apps en tiempo real se sienten lentas aun cuando el código es rápido
La velocidad tiene dos caras: throughput y latencia. El throughput es cuánto trabajo terminas por segundo (peticiones, mensajes, frames). La latencia es cuánto tarda una sola unidad de trabajo de principio a fin.
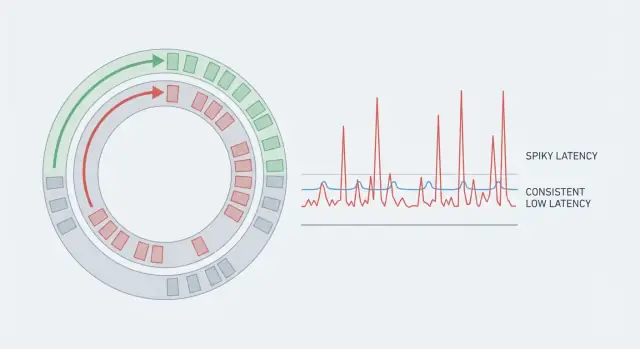
Un sistema puede tener gran throughput y aun así sentirse lento si algunas peticiones tardan mucho más que otras. Por eso las medias engañan. Si 99 acciones toman 5 ms y una toma 80 ms, la media parece bien, pero quien experimenta el caso de 80 ms nota el tartamudeo. En sistemas en tiempo real, esos picos raros son la historia completa porque rompen el ritmo.
Latencia predecible significa que no solo buscas una media baja. Buscas consistencia, de modo que la mayoría de las operaciones terminen dentro de un rango estrecho. Por eso los equipos miran la cola alta (p95, p99). Ahí es donde se esconden las pausas.
Un pico de 50 ms puede importar en lugares como voz y video (glitches de audio), juegos multijugador (rubber-banding), trading en tiempo real (precios perdidos), monitorización industrial (alarmas tarde) y dashboards en vivo (números que saltan, alertas poco fiables).
Un ejemplo simple: una app de chat puede entregar mensajes rápido la mayor parte del tiempo. Pero si una pausa de fondo hace que un mensaje llegue 60 ms tarde, los indicadores de escritura parpadean y la conversación se siente con lag aunque el servidor parezca “rápido” en promedio.
Si quieres que lo «en tiempo real» se sienta real, necesitas menos sorpresas, no solo código más rápido.
Conceptos básicos de latencia: a dónde va realmente el tiempo
La mayoría de los sistemas en tiempo real no son lentos porque la CPU esté saturada. Se sienten lentos porque el trabajo pasa la mayor parte de su vida esperando: esperando a que lo programen, esperando en una cola, esperando la red o esperando el almacenamiento.
La latencia de extremo a extremo es el tiempo completo desde “algo ocurrió” hasta “el usuario ve el resultado”. Aunque tu manejador corra en 2 ms, la petición aún puede tardar 80 ms si se pausa en cinco lugares diferentes.
Una forma útil de descomponer el camino es:
- Tiempo de red (cliente a borde, servicio a servicio, reintentos)
- Tiempo de planificación (tu hilo espera para ejecutarse)
- Tiempo en cola (el trabajo está detrás de otro trabajo)
- Tiempo de almacenamiento (disco, locks de base de datos, cache misses)
- Tiempo de serialización (codificar y decodificar datos)
Esas esperas se apilan. Unos pocos milisegundos aquí y allá convierten una ruta “rápida” en una experiencia lenta.
La latencia de cola es donde los usuarios empiezan a quejarse. La latencia media puede parecer bien, pero p95 o p99 significan el 5% o 1% más lento de las peticiones. Los outliers suelen venir de pausas raras: un ciclo de GC, un vecino ruidoso en el host, contención breve de locks, un refill de caché o una ráfaga que crea una cola.
Ejemplo concreto: una actualización de precio llega por la red en 5 ms, espera 10 ms por un worker ocupado, pasa 15 ms detrás de otros eventos y luego sufre una parada en la base de datos de 30 ms. Tu código aún corrió en 2 ms, pero el usuario esperó 62 ms. La meta es hacer cada paso predecible, no solo la computación rápida.
Las fuentes habituales de jitter más allá de la velocidad del código
Un algoritmo rápido aún puede sentirse lento si el tiempo por petición oscila. Los usuarios notan los picos, no las medias. Esa oscilación es jitter, y a menudo viene de cosas que tu código no controla del todo.
Las cachés de CPU y el comportamiento de la memoria son costes ocultos. Si los datos calientes no caben en caché, la CPU se queda esperando la RAM. Estructuras con muchos objetos, memoria dispersa y “una búsqueda más” pueden traducirse en fallos repetidos de caché.
La asignación de memoria añade su propia aleatoriedad. Crear muchos objetos de corta vida incrementa la presión sobre el heap, que luego aparece como pausas (recolección de basura) o contención del asignador. Incluso sin GC, asignaciones frecuentes pueden fragmentar la memoria y perjudicar la localidad.
La planificación de hilos es otra fuente común. Cuando un hilo es desplanificado, pagas overhead de cambio de contexto y pierdes la «calidez» de caché. En una máquina ocupada, tu hilo «en tiempo real» puede esperar detrás de trabajo no relacionado.
La contención de locks es donde los sistemas predecibles suelen romperse. Un lock que “usualmente está libre” puede convertirse en un convoy: hilos despiertan, compiten por el lock y se vuelven a dormir. El trabajo se hace, pero la latencia en cola se estira.
Las esperas de I/O pueden eclipsar todo lo demás. Una sola syscall, un buffer de red lleno, un handshake TLS, un flush de disco o una resolución DNS lenta pueden crear un pico agudo que ninguna micro-optimización arreglará.
Si buscas jitter, empieza por revisar fallos de caché (a menudo causados por estructuras basadas en punteros y acceso aleatorio), asignaciones frecuentes, cambios de contexto por demasiados hilos o vecinos ruidosos, contención de locks y cualquier I/O bloqueante (red, disco, logging, llamadas síncronas).
Ejemplo: un servicio de ticker de precios puede calcular actualizaciones en microsegundos, pero una llamada de logger sincronizada o un lock contendido de métricas puede añadir intermitentemente decenas de milisegundos.
Martin Thompson y qué es el patrón Disruptor
Martin Thompson es conocido en ingeniería de baja latencia por enfocar cómo los sistemas se comportan bajo presión: no solo velocidad media, sino velocidad predecible. Junto con el equipo de LMAX, ayudó a popularizar el patrón Disruptor, un enfoque de referencia para mover eventos por un sistema con retrasos pequeños y consistentes.
El enfoque Disruptor responde a lo que hace impredecibles a muchas apps “rápidas”: contención y coordinación. Las colas típicas suelen depender de locks o atomics pesados, despiertan hilos arriba y abajo, y crean ráfagas de espera cuando productores y consumidores compiten por estructuras compartidas.
En lugar de una cola, Disruptor usa un ring buffer: un array circular de tamaño fijo que guarda eventos en ranuras. Los productores reclaman la siguiente ranura, escriben los datos y publican un número de secuencia. Los consumidores leen en orden siguiendo esa secuencia. Como el buffer está preasignado, evitas asignaciones frecuentes y reduces la presión sobre el recolector de basura.
Una idea clave es el principio de escritor único: mantener una sola componente responsable de un trozo de estado compartido (por ejemplo, el cursor que avanza por el anillo). Menos escritores significan menos momentos de “quién va ahora?”.
El backpressure es explícito. Cuando los consumidores se quedan atrás, los productores finalmente alcanzan una ranura que sigue en uso. En ese punto el sistema debe esperar, descartar o ralentizarse, pero lo hace de forma controlada y visible en lugar de ocultar el problema dentro de una cola que crece sin control.
Ideas de diseño centrales que mantienen la latencia consistente
Lo que hace rápidos a los diseños estilo Disruptor no es una micro-optimización ingeniosa. Es eliminar las pausas impredecibles que ocurren cuando un sistema combate sus propias piezas móviles: asignaciones, fallos de caché, contención de locks y trabajo lento mezclado en la ruta caliente.
Un modelo mental útil es una línea de montaje. Los eventos se mueven por una ruta fija con entregas claras. Eso reduce el estado compartido y hace cada paso más fácil de mantener simple y medible.
Mantén la memoria y los datos predecibles
Los sistemas rápidos evitan asignaciones sorpresa. Si preasignas buffers y reutilizas objetos de mensaje, reduces los picos “a veces” causados por la recolección de basura, el crecimiento del heap y locks del asignador.
También ayuda mantener los mensajes pequeños y estables. Cuando los datos que tocas por evento caben en caché de CPU, pasas menos tiempo esperando la memoria.
En la práctica, los hábitos que importan más suelen ser: reutilizar objetos en lugar de crear nuevos por evento, mantener los datos de evento compactos, preferir un escritor único para estado compartido y agrupar (batch) con cuidado para pagar menos los costes de coordinación con menos frecuencia.
Haz obvias las rutas lentas
Las apps en tiempo real suelen necesitar extras como logging, métricas, reintentos o escrituras a base de datos. La mentalidad Disruptor es aislar eso del bucle central para que no pueda bloquearlo.
En un feed de precios en vivo, la ruta caliente podría solo validar un tick y publicar la siguiente snapshot de precio. Todo lo que pueda atascarse (disco, llamadas de red, serialización pesada) se mueve a un consumidor separado o a un canal lateral, para que la ruta predecible siga siendo predecible.
Elecciones arquitectónicas para latencia predecible
La latencia predecible es, en su mayor parte, un problema de arquitectura. Puedes tener código rápido y aun así obtener picos si demasiados hilos pelean por los mismos datos, o si los mensajes rebotan por la red sin razón.
Empieza decidiendo cuántos escritores y lectores tocan la misma cola o buffer. Un solo productor es más fácil de mantener suave porque evita coordinación. Configuraciones multi-productor pueden aumentar el throughput, pero a menudo añaden contención y hacen el peor caso menos predecible. Si necesitas múltiples productores, reduce escrituras compartidas particionando eventos por clave (por ejemplo, por userId o instrumentId) para que cada shard tenga su propio camino caliente.
En el lado del consumidor, un consumidor único da el timing más estable cuando el orden importa, porque el estado permanece local a un hilo. Los worker pools ayudan cuando las tareas son realmente independientes, pero añaden retrasos de planificación y pueden reordenar trabajo a menos que seas cuidadoso.
El batching es otro trade-off. Lotes pequeños reducen overhead (menos wakeups, menos fallos de caché), pero el batching también puede añadir espera si retienes eventos para llenar un lote. Si agrupas en un sistema en tiempo real, limita el tiempo de espera (por ejemplo, “hasta 16 eventos o 200 microsegundos, lo que ocurra primero”).
Los límites de servicio también importan. Mensajería in-process suele ser lo mejor cuando necesitas latencia ajustada. Saltos de red pueden valer la pena para escalar, pero cada salto añade colas, reintentos y demora variable. Si necesitas un salto, mantén el protocolo simple y evita fan-out en la ruta caliente.
Una regla práctica: mantén un camino de escritor único por shard cuando puedas, escala por sharding de claves en lugar de compartir una cola caliente, agrupa solo con un tope estricto de tiempo, añade worker pools solo para trabajo paralelo e independiente, y trata cada salto de red como una fuente potencial de jitter hasta que lo midas.
Paso a paso: diseñando una canalización de baja variabilidad
Empieza con un presupuesto de latencia escrito antes de tocar código. Elige un objetivo (cómo se siente “bueno”) y un p99 (qué debes cumplir). Divide ese número entre etapas como entrada, validación, emparejamiento, persistencia y actualizaciones salientes. Si una etapa no tiene presupuesto, no tiene límite.
Luego dibuja el flujo completo de datos y marca cada entrega: límites de hilo, colas, saltos de red y llamadas a almacenamiento. Cada entrega es un lugar donde se esconde el jitter. Cuando los ves, puedes reducirlos.
Un flujo de trabajo que mantiene el diseño honesto:
- Escribe un presupuesto por etapa (objetivo y p99), más un pequeño buffer para imprevistos.
- Mapea la canalización y etiqueta colas, locks, asignaciones y llamadas bloqueantes.
- Elige un modelo de concurrencia razonable (escritor único, particionado por clave, o un hilo I/O dedicado).
- Define la forma del mensaje temprano: esquemas estables, cargas compactas y copias mínimas.
- Decide las reglas de backpressure desde el principio: descartar, retrasar, degradar o shed load. Hazlo visible y medible.
Luego decide qué puede ser asíncrono sin romper la experiencia del usuario. Una regla simple: cualquier cosa que cambie lo que el usuario ve “ahora” queda en el camino crítico. Todo lo demás se mueve hacia fuera.
Analítica, logs de auditoría e indexación secundaria suelen ser seguros para sacar del camino caliente. Validación, orden y pasos necesarios para producir el siguiente estado normalmente no.
Elecciones de runtime y SO que afectan la cola alta
El código rápido aún puede sentirse lento cuando el runtime o el SO pausa tu trabajo en el momento equivocado. La meta no es solo alto throughput. Es menos sorpresas en el 1% más lento de peticiones.
Los runtimes con recolección de basura (JVM, Go, .NET) pueden ser excelentes para productividad, pero pueden introducir pausas cuando la memoria necesita limpieza. Los recolectores modernos son mejores que antes, aun así la latencia de cola puede saltar si creas muchos objetos de corta vida bajo carga. Los lenguajes sin GC (Rust, C, C++) evitan pausas de GC, pero trasladan el coste a disciplina manual de ownership y asignación. De cualquier forma, el comportamiento de la memoria importa tanto como la velocidad de CPU.
El hábito práctico es sencillo: encuentra dónde ocurren las asignaciones y hazlas aburridas. Reutiliza objetos, precalibra buffers y evita convertir datos del camino caliente en strings o mapas temporales.
Las elecciones de threading también aparecen como jitter. Cada cola extra, salto asíncrono o handoff de pool de hilos añade espera e incrementa la varianza. Prefiere un número pequeño de hilos de larga vida, mantén claros los límites productor-consumidor y evita llamadas bloqueantes en la ruta caliente.
Algunas configuraciones de SO y contenedores deciden si tu cola es limpia o con picos. Estrangulamiento de CPU por límites estrictos, vecinos ruidosos en hosts compartidos y logging mal situado pueden crear lentitud súbita. Si solo vas a cambiar una cosa, empieza midiendo la tasa de asignaciones y cambios de contexto durante picos de latencia.
Datos, almacenamiento y límites de servicio sin pausas sorpresa
Muchos picos de latencia no son “código lento”. Son esperas que no planeaste: un lock de base de datos, una tormenta de reintentos, una llamada entre servicios que se queda, o un cache miss que se convierte en un viaje completo.
Mantén el camino crítico corto. Cada hop extra añade planificación, serialización, colas de red y más lugares para bloquearse. Si puedes responder desde un proceso y una tienda de datos, hazlo primero. Divide en más servicios solo cuando cada llamada sea opcional o estrictamente acotada.
La espera acotada es la diferencia entre medias rápidas y latencia predecible. Pon timeouts duros en llamadas remotas y falla rápido cuando una dependencia está degradada. Los circuit breakers no son solo para salvar servidores; limitan cuánto puede quedarse atascado un usuario.
Cuando el acceso a datos bloquea, separa caminos. Las lecturas suelen querer formas indexadas, desnormalizadas y amigables con caché. Las escrituras buscan durabilidad y orden. Separarlas puede eliminar contención y reducir tiempo de locks. Si tu consistencia lo permite, registros append-only (un event log) suelen comportarse más predeciblemente que actualizaciones in-place que provocan bloqueos de filas calientes o mantenimiento en segundo plano.
Una regla simple para apps en tiempo real: la persistencia no debería estar en el camino crítico a menos que realmente la necesites para corrección. A menudo la forma mejor es: actualizar en memoria, responder y luego persistir de forma asíncrona con un mecanismo de replay (como outbox o write-ahead log).
En muchas canalizaciones con ring buffer esto acaba siendo: publicar en un buffer en memoria, actualizar estado, responder y luego dejar que un consumidor separado agrupe escrituras a PostgreSQL.
Un ejemplo realista: actualizaciones en tiempo real con latencia predecible
Imagina una app de colaboración en vivo (o un pequeño juego multijugador) que empuja actualizaciones cada 16 ms (unas 60 veces por segundo). La meta no es “rápido en promedio”. Es “usualmente por debajo de 16 ms”, incluso cuando la conexión de un usuario es mala.
Un flujo estilo Disruptor simple se ve así: la entrada del usuario se convierte en un evento pequeño, se publica en un ring buffer preasignado, luego es procesado por un conjunto fijo de handlers en orden (validar -> aplicar -> preparar mensajes salientes) y finalmente se retransmite a los clientes.
El batching ayuda en los bordes. Por ejemplo, agrupa escrituras salientes por cliente una vez por tick para llamar menos veces a la capa de red. Pero no agrupes dentro del camino caliente de forma que esperes “un poco más” por más eventos. Esperar es cómo fallas el tick.
Cuando algo se pone lento, trátalo como un problema de contención. Si un handler se ralentiza, aíslalo detrás de su propio buffer y publica un ítem de trabajo ligero en vez de bloquear el loop principal. Si un cliente es lento, no dejes que llene el broadcaster; da a cada cliente una pequeña cola de envío y descarta o coalesce actualizaciones antiguas para mantener el estado más reciente. Si la profundidad del buffer crece, aplica backpressure en el borde (deja de aceptar entradas extra para ese tick o degrada características).
Sabes que funciona cuando los números se mantienen aburridos: la profundidad de backlog ronda cero, los eventos descartados/coalescidos son raros y explicables, y p99 se mantiene por debajo de tu presupuesto de tick bajo carga realista.
Errores comunes que crean picos de latencia
La mayoría de los picos de latencia son autoinfligidos. El código puede ser rápido, pero el sistema aún se pausa cuando espera a otros hilos, al SO o a cualquier cosa fuera de la caché de CPU.
Unos cuantos errores que reaparecen:
- Usar locks compartidos en todas partes porque parece simple. Un lock contendido puede detener muchas peticiones.
- Mezclar I/O lento en el camino caliente, como logging síncrono, escrituras a BD o llamadas remotas.
- Mantener colas sin límites. Ocultan la sobrecarga hasta que tienes segundos de backlog.
- Vigilar medias en lugar de p95 y p99.
- Sobreajustar demasiado pronto. Anclar hilos no ayuda si los retrasos vienen de GC, contención o espera en un socket.
Una forma rápida de reducir picos es hacer las esperas visibles y acotadas. Pon el trabajo lento en un camino separado, limita colas y decide qué pasa cuando estás lleno (descartar, shed load o degradar funciones).
Checklist rápido para latencia predecible
Trata la latencia predecible como una característica de producto, no como un accidente. Antes de afinar código, asegúrate de que el sistema tenga metas claras y guardrails.
- Establece un objetivo p99 explícito (y p99.9 si importa), luego escribe un presupuesto de latencia por etapa.
- Mantén el camino caliente libre de I/O bloqueante. Si I/O debe ocurrir, muévelo a un camino lateral y decide qué haces cuando va lento.
- Usa colas acotadas y define comportamiento ante sobrecarga (descartar, shed load, coalescer o backpressure).
- Mide continuamente: profundidad de backlog, tiempo por etapa y latencia en la cola.
- Minimiza asignaciones en el bucle caliente y haz que sea fácil detectarlas en perfiles.
Una prueba simple: simula una ráfaga (10x tráfico normal durante 30 segundos). Si p99 explota, pregunta dónde ocurre la espera: colas crecientes, un consumidor lento, una pausa de GC o un recurso compartido.
Próximos pasos: cómo aplicar esto en tu propia app
Trata el patrón Disruptor como un flujo de trabajo, no como una librería obligatoria. Prueba la latencia predecible con un slice fino antes de añadir funciones.
Elige una acción de usuario que deba sentirse instantánea (por ejemplo, “llega un nuevo precio, la UI se actualiza”). Escribe el presupuesto extremo a extremo, luego mide p50, p95 y p99 desde el día uno.
Una secuencia que suele funcionar:
- Construye una canalización delgada con una entrada, un loop central y una salida. Valida p99 bajo carga pronto.
- Haz explícitas las responsabilidades (quién posee el estado, quién publica, quién consume) y mantén el estado compartido pequeño.
- Añade concurrencia y buffering en pasos pequeños y mantén los cambios reversibles.
- Despliega cerca de los usuarios cuando el presupuesto sea ajustado, luego vuelve a medir bajo carga realista (mismos tamaños de payload y mismos patrones de ráfaga).
Si construyes sobre Koder.ai (koder.ai), puede ayudar mapear primero el flujo de eventos en Planning Mode para que colas, locks y límites de servicio no aparezcan por accidente. Las snapshots y la posibilidad de rollback también facilitan ejecutar experimentos de latencia repetidos y revertir cambios que mejoran throughput pero empeoran p99.
Mantén las mediciones honestas. Usa un script de prueba fijo, calienta el sistema y registra tanto throughput como latencia. Cuando p99 sube con la carga, no empieces por “optimizar el código”. Busca pausas por GC, vecinos ruidosos, ráfagas de logging, planificación de hilos o llamadas bloqueantes ocultas.