10 jul 2025·8 min
Patrones sencillos de cola de trabajos en segundo plano para correos y webhooks
Aprende patrones simples de cola de jobs en segundo plano para enviar correos, ejecutar reportes y entregar webhooks con reintentos, backoff y manejo dead-letter, sin herramientas pesadas.
Por qué necesitas jobs en segundo plano (y por qué se complica rápido)
Cualquier trabajo que pueda durar más de uno o dos segundos no debería ejecutarse dentro de una petición de usuario. Enviar correos, generar reportes y entregar webhooks dependen de redes, servicios terceros o consultas lentas. A veces se retrasan, fallan o simplemente tardan más de lo esperado.
Si haces ese trabajo mientras el usuario espera, la gente lo nota de inmediato. Las páginas se quedan pegadas, los botones de "Guardar" giran y las peticiones hacen timeout. Los reintentos también pueden ocurrir en el lugar equivocado. Un usuario refresca, tu balanceador reintenta, o el frontend vuelve a enviar, y acabas con correos duplicados, llamadas webhook duplicadas o dos ejecuciones de reporte compitiendo entre sí.
Los jobs en segundo plano arreglan esto manteniendo las peticiones pequeñas y predecibles: acepta la acción, registra un job para más tarde y responde rápido. El job corre fuera de la petición, con reglas que tú controlas.
La parte difícil es la fiabilidad. Una vez que el trabajo sale del camino de la petición, todavía tienes que responder preguntas como:
- ¿Qué pasa si el proveedor de email cae 3 minutos?
- ¿Qué pasa si el endpoint webhook devuelve 500 o hace timeout?
- ¿Qué pasa si el job se ejecuta dos veces?
- ¿Cómo detectas jobs atascados antes de que los usuarios se quejen?
Muchos equipos responden añadiendo "infraestructura pesada": un broker, flotas separadas de workers, dashboards, alertas y playbooks. Esas herramientas son útiles cuando realmente las necesitas, pero también añaden nuevas piezas móviles y nuevos modos de fallo.
Un objetivo de inicio mejor es más simple: jobs fiables usando las partes que ya tienes. Para la mayoría de productos eso significa una cola respaldada por base de datos y un pequeño proceso worker. Añade una estrategia clara de reintentos y backoff, y un patrón dead-letter para jobs que siguen fallando. Obtienes comportamiento predecible sin comprometerte con una plataforma compleja desde el día uno.
Incluso si construyes rápido con una herramienta de chat como Koder.ai, esta separación sigue siendo importante. Los usuarios deben recibir una respuesta rápida ahora, y tu sistema debe terminar el trabajo lento y propenso a fallos de forma segura en segundo plano.
Qué es una cola en términos sencillos
Una cola es una fila de espera para trabajo. En vez de hacer tareas lentas o poco fiables durante una petición de usuario (enviar un correo, construir un reporte, llamar a un webhook), pones un registro pequeño en una cola y respondes rápido. Más tarde, un proceso separado recoge ese registro y hace el trabajo.
Unas cuantas palabras que verás a menudo:
- Job: una unidad de trabajo, como "enviar correo de bienvenida al usuario 123".
- Worker: el código que saca jobs y los ejecuta.
- Intento: un intento de ejecutar un job.
- Programación (Schedule): cuándo debe ejecutarse el job (ahora o después).
- Cola (Queue): donde los jobs esperan hasta que un worker los toma.
El flujo más simple se ve así:
-
Enqueue: tu app guarda un registro de job (tipo, payload, tiempo de ejecución).
-
Claim: un worker encuentra el siguiente job disponible y lo "bloquea" para que solo un worker lo ejecute.
-
Run: el worker realiza la tarea (enviar, generar, entregar).
-
Finish: lo marca como hecho, o registra un fallo y programa el siguiente intento.
Si tu volumen de jobs es modesto y ya tienes una base de datos, una cola respaldada por base de datos suele ser suficiente. Es fácil de entender, fácil de depurar y cubre necesidades comunes como procesamiento de correos y confiabilidad en entrega de webhooks.
Las plataformas de streaming empiezan a tener sentido cuando necesitas un throughput muy alto, muchos consumidores independientes o la capacidad de reproducir grandes historiales de eventos entre muchos sistemas. Si ejecutas docenas de servicios con millones de eventos por hora, herramientas como Kafka pueden ayudar. Hasta entonces, una tabla de base de datos más un bucle worker cubren muchas colas del mundo real.
Los datos mínimos que deberías rastrear para cada job
Una cola en base de datos solo se mantiene sana si cada registro de job responde tres preguntas rápidamente: qué hacer, cuándo intentar de nuevo y qué pasó la última vez. Haz eso bien y las operaciones se vuelven aburridas (que es la meta).
Qué almacenar en el payload (y qué no)
Almacena la entrada más pequeña necesaria para hacer el trabajo, no todo el output ya renderizado. Buenas cargas son IDs y unos pocos parámetros, como { "user_id": 42, "template": "welcome" }.
Evita almacenar blobs grandes (HTML completo de correos, datos de reportes pesados, cuerpos enormes de webhooks). Hace que tu base de datos crezca más rápido y complica la depuración. Si el job necesita un documento grande, almacena una referencia en su lugar: report_id, export_id o una key de archivo. El worker puede recuperar los datos completos cuando se ejecute.
Los campos que se pagan solos
Como mínimo, deja espacio para:
- job_type + payload:
job_typeselecciona el handler (send_email,generate_report,deliver_webhook).payloadcontiene entradas pequeñas como IDs y opciones. - status: mantenlo explícito (por ejemplo:
queued,running,succeeded,failed,dead). - seguimiento de intentos:
attempt_countymax_attemptspara dejar de reintentar cuando claramente no va a funcionar. - campos de tiempo:
created_atynext_run_at(cuando se vuelve elegible). Añadestarted_atyfinished_atsi quieres mejor visibilidad de jobs lentos. - idempotencia + último error: una
idempotency_keypara prevenir efectos dobles, ylast_errorpara ver por qué falló sin hurgar en montones de logs.
La idempotencia suena elegante, pero la idea es simple: si el mismo job se ejecuta dos veces, la segunda ejecución debe detectar eso y no hacer nada peligroso. Por ejemplo, un job de entrega webhook puede usar una clave de idempotencia como webhook:order:123:event:paid para no entregar el mismo evento dos veces si un reintento se solapa con un timeout.
También captura algunos números básicos desde el principio. No necesitas un gran dashboard para empezar, solo consultas que te digan: cuántos jobs están encolados, cuántos están fallando y la antigüedad del job más antiguo en cola.
Paso a paso: una cola simple en base de datos que puedes construir hoy
Si ya tienes una base de datos, puedes empezar una cola en segundo plano sin añadir nueva infraestructura. Los jobs son filas, y un worker es un proceso que sigue recogiendo filas vencidas y haciendo el trabajo.
1) Crea una tabla jobs
Mantén la tabla pequeña y aburrida. Quieres suficientes campos para ejecutar, reintentar y depurar jobs después.
CREATE TABLE jobs (
id bigserial PRIMARY KEY,
job_type text NOT NULL,
payload jsonb NOT NULL,
status text NOT NULL DEFAULT 'queued', -- queued, running, done, failed
attempts int NOT NULL DEFAULT 0,
next_run_at timestamptz NOT NULL DEFAULT now(),
locked_at timestamptz,
locked_by text,
last_error text,
created_at timestamptz NOT NULL DEFAULT now(),
updated_at timestamptz NOT NULL DEFAULT now()
);
CREATE INDEX jobs_due_idx ON jobs (status, next_run_at);
Si construyes sobre Postgres (común en backends en Go), jsonb es una forma práctica de almacenar datos de job como { "user_id":123,"template":"welcome" }.
2) Enqueue de forma segura (especialmente para acciones de usuario)
Cuando una acción de usuario debe disparar un job (enviar un correo, disparar un webhook), escribe la fila del job en la misma transacción de base de datos que el cambio principal cuando sea posible. Eso evita "usuario creado pero job faltante" si ocurre un crash justo después de la escritura principal.
Ejemplo: cuando un usuario se registra, inserta la fila del usuario y un job send_welcome_email en una sola transacción.
3) Ejecuta un bucle worker que pueda escalar
Un worker repite el mismo ciclo: encuentra un job vencido, lo reclama para que nadie más lo tome, lo procesa y luego lo marca como hecho o programa un reintento.
En la práctica, eso significa:
- Elegir un job donde
status='queued'ynext_run_at <= now(). - Reclamarlo atómicamente (en Postgres,
SELECT ... FOR UPDATE SKIP LOCKEDes un enfoque común). - Poner
status='running',locked_at=now(),locked_by='worker-1'. - Procesar el job.
- Marcarlo como terminado (por ejemplo
done/succeeded), o registrarlast_errory agendar el siguiente intento.
Varios workers pueden ejecutarse a la vez. El paso de claim es lo que evita que se tomen dos veces el mismo job.
4) Manejar el apagado sin romper jobs
En el apagado, deja de tomar nuevos jobs, termina el actual y luego sal. Si un proceso muere a mitad de job, usa una regla simple: trata jobs en running que llevan demasiado tiempo como elegibles para reencolar por una tarea periódica llamada "reaper".
Si construyes en Koder.ai, este patrón de cola en base de datos es un valor predeterminado sólido para emails, reportes y webhooks antes de añadir servicios de cola especializados.
Reintentos y backoff que no causan caos
Experimenta sin miedo
Captura un snapshot antes de cambios para poder volver atrás si un release dispara fallos.
Los reintentos son cómo una cola se mantiene tranquila cuando el mundo real es ruidoso. Sin reglas claras, los reintentos se vuelven un bucle ruidoso que spamea usuarios, golpea APIs y oculta el bug real.
Empieza decidiendo qué debe reintentarse y qué debe fallar rápido.
Reintenta problemas temporales: timeouts de red, errores 502/503, límites de tasa o una breve pérdida de conexión a la base de datos.
Falla rápido cuando el job no va a tener éxito: falta de dirección de correo, un 400 de webhook porque el payload es inválido o un pedido de reporte para una cuenta eliminada.
El backoff es la pausa entre intentos. El backoff lineal (5s, 10s, 15s) es simple, pero aún puede crear oleadas de tráfico. El backoff exponencial (5s, 10s, 20s, 40s) distribuye mejor la carga y suele ser más seguro para webhooks y proveedores terceros. Añade jitter (un pequeño retraso aleatorio) para que mil jobs no reintenten exactamente al mismo segundo después de una caída.
Reglas que tienden a comportarse bien en producción:
- Reintenta solo en errores claramente temporales (timeouts, 429, 5xx).
- Usa backoff exponencial con jitter.
- Limita los intentos y luego deja de intentarlo, marcando el job como fallido.
- Pon un timeout por intento para que los workers no se queden colgados.
- Haz cada job idempotente para que los reintentos no creen duplicados.
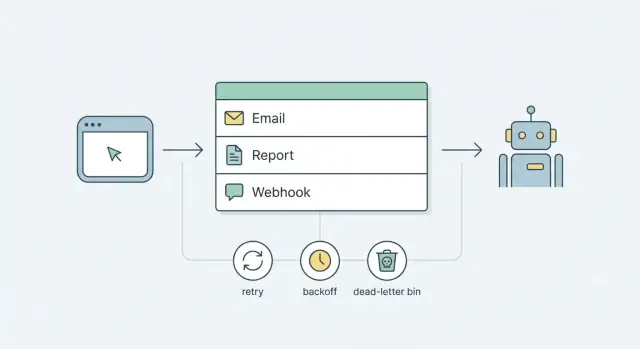
Max attempts trata de limitar el daño. Para muchos equipos, 5 a 8 intentos son suficientes. Después de eso, deja de reintentar y aparca el job para revisión (un flujo dead-letter) en vez de ciclar eternamente.
Los timeouts evitan jobs "zombies". Los emails pueden tener timeout de 10 a 20 segundos por intento. Los webhooks a menudo necesitan un límite más corto, como 5 a 10 segundos, porque el receptor puede estar caído y quieres seguir adelante. La generación de reportes puede permitir minutos, pero aun así debe tener un corte estricto.
Si construyes esto en Koder.ai, trata should_retry, next_run_at y una clave de idempotencia como campos de primera clase. Esos pequeños detalles mantienen el sistema tranquilo cuando algo falla.
Manejo dead-letter y operaciones simples
Un estado dead-letter es donde van los jobs cuando los reintentos ya no son seguros o útiles. Convierte fallos silenciosos en algo que puedes ver, buscar y actuar sobre.
Qué guardar en un job dead-letter
Guarda suficiente información para entender qué pasó y reproducir el job sin adivinar, pero ten cuidado con los secretos.
Conserva:
- Las entradas del job (payload) exactamente como se usaron, además del tipo y la versión del job
- El último mensaje de error y una traza corta (o un código de error si no tienes stacktraces)
- Contador de intentos, hora del primer intento, hora del último intento y next run time (si estaba programado)
- Identidad del worker (nombre del servicio, host) y un correlation ID para logs
- Un motivo dead-letter (timeout, error de validación, 4xx de un proveedor, etc.)
Si el payload incluye tokens o datos personales, redacta o cifra antes de almacenar.
Un flujo de triage simple
Cuando un job llega a dead-letter, toma una decisión rápida: reintentar, arreglar o ignorar.
Reintentar es para outages externos y timeouts. Arreglar es para datos malos (email faltante, URL webhook errónea) o un bug en tu código. Ignorar debería ser raro, pero puede ser válido cuando el job ya no es relevante (por ejemplo, el cliente eliminó su cuenta). Si ignoras, registra una razón para que no parezca que el job desapareció.
Reencolar manualmente es más seguro cuando crea un job nuevo y mantiene el antiguo inmutable. Marca el job dead-letter con quién lo reencoló, cuándo y por qué, y luego encola una copia nueva con un ID nuevo.
Para alertas, vigila señales que suelen significar problemas reales: conteo de dead-letter subiendo rápido, el mismo error repitiéndose en muchos jobs y jobs antiguos en cola que no están siendo reclamados.
Si usas Koder.ai, snapshots y rollback ayudan cuando un mal release dispara fallos, porque puedes revertir rápidamente mientras investigas.
Finalmente, añade válvulas de seguridad para outages de proveedores. Limita el ritmo de envíos por proveedor y usa un circuit breaker: si un endpoint webhook está fallando fuerte, pausa nuevos intentos por una ventana corta para no inundar sus servidores (y los tuyos).
Patrones para correos, reportes y webhooks
Asume tu implementación de la cola
Obtén el código fuente completo de tu cola y worker para que tu equipo lo extienda.
Una cola funciona mejor cuando cada tipo de job tiene reglas claras: qué cuenta como éxito, qué debe reintentarse y qué nunca debe pasar dos veces.
Correos. La mayoría de fallos de correo son temporales: timeouts del proveedor, límites de tasa o outages breves. Trátalos como reintentables, con backoff. El riesgo mayor son los envíos duplicados, así que haz los jobs de correo idempotentes. Guarda una clave de deduplicación estable como user_id + template + event_id y rehúsa enviar si esa clave ya está marcada como enviada.
También vale la pena guardar el nombre y la versión de la plantilla (o un hash del asunto/cuerpo renderizado). Si alguna vez necesitas re-ejecutar jobs, puedes elegir si reenviar exactamente el mismo contenido o regenerarlo desde la plantilla más reciente. Si el proveedor devuelve un message ID, guárdalo para que soporte pueda rastrear lo ocurrido.
Reportes. Los reportes fallan de forma diferente. Pueden ejecutarse durante minutos, chocar con límites de paginación o quedarse sin memoria si lo haces todo de una vez. Divide el trabajo en piezas más pequeñas. Un patrón común es: un job "request de reporte" crea muchos jobs de "página" (o "chunk"), cada uno procesando una porción de datos.
Guarda resultados para descarga posterior en vez de mantener al usuario esperando. Puede ser una tabla en la base de datos con report_run_id, o una referencia a archivo más metadatos (status, conteo de filas, created_at). Añade campos de progreso para que la UI muestre "procesando" vs "listo" sin adivinar.
Webhooks. Los webhooks tratan de confiabilidad en la entrega, no de rapidez. Firma cada petición (por ejemplo HMAC con un secreto compartido) e incluye un timestamp para prevenir replays. Reintenta solo cuando el receptor pueda tener éxito después.
Un conjunto de reglas sencillo:
- Reintenta en timeouts y respuestas 5xx, usando backoff y un máximo de intentos.
- Trata la mayoría de 4xx como fallos permanentes y deja de reintentar.
- Registra el último código de estado y un cuerpo de respuesta corto para depuración.
- Usa una clave de idempotencia para que los receptores puedan ignorar duplicados con seguridad.
- Limita el tamaño del payload y registra lo que en realidad enviaste.
Orden y prioridad. La mayoría de jobs no necesitan orden estricto. Cuando el orden importa, suele importar por key (por usuario, por factura, por endpoint webhook). Añade un group_key y ejecuta solo uno en vuelo por key.
Para prioridad, separa trabajo urgente del trabajo lento. Un gran backlog de reportes no debe retrasar correos de restablecimiento de contraseña.
Ejemplo: tras una compra, encolas (1) un correo de confirmación de pedido, (2) un webhook a un partner y (3) una actualización de reporte. El correo puede reintentarse rápido, el webhook reintenta más tiempo con backoff, y el reporte corre después con baja prioridad.
Un ejemplo realista: flujo de registro, webhook y reporte nocturno
Un usuario se registra en tu app. Tres cosas deben ocurrir, pero ninguna debe ralentizar la página de registro: enviar un correo de bienvenida, notificar a tu CRM con un webhook e incluir al usuario en un reporte nocturno de actividad.
Qué se encola en el registro
Justo después de crear la fila del usuario, escribe tres filas de job en tu cola de base de datos. Cada fila tiene un tipo, un payload (como user_id), un status, un contador de intentos y un timestamp next_run_at.
Un ciclo de vida típico se ve así:
queued: creado y esperando por un workerrunning: un worker lo reclamósucceeded: hecho, no más trabajofailed: falló, programado para más tarde o sin más reintentosdead: falló demasiadas veces y necesita revisión humana
El job de bienvenida incluye una clave de idempotencia como welcome_email:user:123. Antes de enviar, el worker revisa una tabla de claves de idempotencia completadas (o aplica una restricción única). Si el job se ejecuta dos veces por un crash, la segunda ejecución ve la clave y omite el envío. No hay correos de bienvenida dobles.
Una falla y cómo se recupera
Ahora el endpoint del CRM está caído. El job webhook falla con un timeout. Tu worker programa un reintento usando backoff (por ejemplo: 1 minuto, 5 minutos, 30 minutos, 2 horas) más un poco de jitter para que muchos jobs no reintenten al mismo segundo.
Tras superar los intentos máximos, el job pasa a dead. El usuario igual se registró, recibió el correo de bienvenida y el job de reporte nocturno puede ejecutarse normalmente. Solo la notificación al CRM está atascada y es visible.
A la mañana siguiente, soporte (o quien esté de guardia) puede manejarlo sin hurgar horas en logs:
- Filtrar jobs dead por tipo (por ejemplo
webhook.crm). - Leer el último mensaje de error y confirmar que el payload se ve correcto.
- Verificar que el CRM volvió.
- Reencolar el job (dead -> queued, resetear attempts) o deshabilitar temporalmente ese destino.
Si construyes apps en una plataforma como Koder.ai, el mismo patrón aplica: mantén el flujo de usuario rápido, empuja los efectos secundarios a jobs y haz que los fallos sean fáciles de inspeccionar y re-ejecutar.
Errores comunes que hacen las colas poco fiables
Genera un bucle worker en Go
Pide a Koder.ai que genere un worker en Go con claim seguro de jobs y timeouts.
La forma más rápida de romper una cola es tratarla como opcional. Los equipos suelen empezar con "esta vez envío el correo en la petición porque parece más simple". Luego se propaga: restablecimientos de contraseña, recibos, webhooks, exportes de reporte. Pronto la app se siente lenta, los timeouts suben y cualquier contratiempo de terceros se vuelve tu outage.
Otra trampa común es saltarse la idempotencia. Si un job puede ejecutarse dos veces, no debe crear dos resultados. Sin idempotencia, los reintentos se vuelven correos duplicados, eventos webhook repetidos o peor.
Un tercer problema es la visibilidad. Si solo te enteras de fallos por tickets de soporte, la cola ya está perjudicando a los usuarios. Incluso una vista interna básica que muestre conteos de jobs por estado más last_error buscable ahorra mucho tiempo.
Asesinos de fiabilidad a vigilar
Unos cuantos problemas aparecen pronto, incluso en colas simples:
- Reintentar inmediatamente al fallo. Si un proveedor está caído, reintentos rápidos crean tu propia ola de tráfico.
- Mezclar jobs lentos con urgentes. Un reporte de 10 minutos puede bloquear un "verifica tu email".
- Tratar errores como temporales para siempre. Jobs que nunca van a tener éxito siguen ciclando y ocultan problemas reales.
- Sin ownership de versiones de payload. Si cambias la forma del job, los jobs antiguos pueden empezar a fallar.
- Ignorar límites de tasa. Las colas pueden inundar proveedores que te limitan.
El backoff evita outages autoinducidos. Incluso una programación básica como 1 minuto, 5 minutos, 30 minutos, 2 horas hace que los fallos sean más seguros. También pon un límite de intentos para que un job roto pare y se haga visible.
Si construyes sobre una plataforma como Koder.ai, ayuda implementar estas bases junto con la función misma, no semanas después como proyecto de limpieza.
Lista rápida de comprobación y siguientes pasos
Antes de añadir más herramientas, asegúrate de que lo básico está sólido. Una cola respaldada por base de datos funciona bien cuando cada job es fácil de reclamar, reintentar e inspeccionar.
Una lista de comprobación rápida de fiabilidad:
- Cada job tiene: id, tipo, payload, status, attempts, max_attempts, run_at/next_run_at y last_error.
- Los workers reclaman jobs de forma segura (un worker obtiene un job) y se recuperan tras crashes (timeout de bloqueo + reaper).
- Cada job tiene un timeout claro para que el trabajo atascado sea reintentable en vez de quedarse colgado.
- Los reintentos están limitados y el retraso entre ellos crece (backoff) para evitar multitudes sincronizadas.
- Existe un estado dead-letter (o tabla) y una forma clara de re-ejecutar o descartar jobs.
Luego, elige tus tres primeros tipos de job y anota sus reglas. Por ejemplo: correo de restablecimiento de contraseña (reintentos rápidos, max corto), reporte nocturno (pocos reintentos, timeouts más largos), entrega webhook (más reintentos, backoff largo, parar en 4xx permanentes).
Si no estás seguro de cuándo una cola en base de datos deja de ser suficiente, vigila señales como contención a nivel de fila por muchos workers, necesidades de orden estricto entre muchos tipos de job, fan-out grande (un evento dispara miles de jobs) o consumo entre servicios donde distintos equipos poseen distintos workers.
Si quieres un prototipo rápido, puedes esbozar el flujo en Koder.ai (koder.ai) usando Planning Mode, generar la tabla jobs y el bucle worker, e iterar con snapshots y rollback antes de desplegar.
Preguntas frecuentes
¿Cuándo debo mover trabajo a un job en segundo plano en vez de hacerlo en la petición?
Si una tarea puede tardar más de uno o dos segundos, o depende de una llamada de red (proveedor de correo, endpoint webhook, consulta lenta), muévela a un job en segundo plano.
Mantén la solicitud del usuario enfocada en validar la entrada, escribir el cambio principal en la base de datos, encolar un job y devolver una respuesta rápida.
¿Realmente basta una cola en la base de datos, o necesito un message broker?
Empieza con una cola respaldada por base de datos cuando:
- Ya usas PostgreSQL y tu volumen es moderado
- Quieres lo más sencillo y fácil de depurar
- Un mismo servicio se encarga de encolar y procesar
Añade un broker/plataforma de streaming más adelante cuando necesites muy alto throughput, muchos consumidores independientes o la posibilidad de reproducir eventos entre servicios.
¿Qué campos debería tener cada registro de job?
Registra lo básico que responda: qué hacer, cuándo intentar de nuevo y qué pasó la última vez.
Un mínimo práctico:
¿Qué debo poner en el payload del job (y qué debo evitar)?
Almacena entradas, no grandes salidas.
Buenos payloads:
- IDs y opciones pequeñas (por ejemplo
user_id,template,report_id)
Evita:
¿Cómo evitan los múltiples workers hacerse con el mismo job?
La clave es un paso de “claim” atómico para que dos workers no tomen el mismo job.
En Postgres es común:
- Seleccionar filas elegibles con bloqueo (por ejemplo
FOR UPDATE SKIP LOCKED) - Marcar inmediatamente el job como
runningy ponerlocked_at/locked_by
Así los workers escalan horizontalmente sin procesar la misma fila dos veces.
¿Cómo prevengo correos duplicados o entregas duplicadas de webhooks?
Asume que los jobs se ejecutarán al menos dos veces a veces (crashes, timeouts, reintentos). Haz que el efecto lateral sea seguro.
Patrones simples:
- Añade una
idempotency_keycomowelcome_email:user:123 - Aplica unicidad (índice único o tabla separada de claves completadas)
- Si llega de nuevo, detecta la clave y omite el envío/entrega
Esto es especialmente importante para correos y webhooks para evitar duplicados.
¿Qué estrategia de reintentos y backoff debería usar para empezar?
Usa una política por defecto clara y manténla simple:
- Reintenta solo fallos temporales (timeouts, 429, 5xx)
- Backoff exponencial con jitter (pequeño retraso aleatorio)
- Limita los intentos (a menudo 5–8)
- Pon un timeout por intento para que los workers no queden colgados
Falla rápido en errores permanentes (dirección de correo faltante, payload inválido, la mayoría de 4xx en webhooks).
¿Qué es un job dead-letter y cuándo debo usarlo?
Dead-letter significa “dejar de reintentar y hacerlo visible.” Úsalo cuando:
- Se superaron
max_attempts - El error es claramente permanente
- Reintentar causaría daño (spam, webhooks repetidos)
Guarda contexto suficiente para actuar:
¿Cómo trato jobs que quedan en running tras un crash?
Maneja jobs “atascados en running” con dos reglas:
- Cada intento tiene un timeout (para que el trabajo no pueda ejecutarse indefinidamente)
- Un reaper periódico detecta jobs
runningmás antiguos que un umbral y los reencola (o los marca como fallados)
Así el sistema se recupera de crashes de workers sin intervención manual.
¿Cómo manejo prioridad y orden (para que los reportes no retrasen emails críticos)?
Separa para que trabajo lento no bloquee lo urgente:
- Pon jobs urgentes (restablecer contraseña, verificación de email) en una cola de alta prioridad
- Pon jobs pesados (reportes grandes) en una cola de baja prioridad
Si el orden importa, normalmente es “por key” (por usuario, por endpoint webhook). Añade un group_key y asegura que solo haya un job en vuelo por key para preservar orden local sin forzar orden global.