03 nov 2025·8 min
Patrones SaaS multitenant: aislamiento, escalado y diseño con IA
Aprende patrones comunes de SaaS multi-inquilino, compensaciones sobre el aislamiento de inquilinos y estrategias de escalado. Ve cómo arquitecturas generadas por IA aceleran diseño y revisiones.
Qué significa multi-tenancy (sin jerga)
Multi-tenancy significa que un mismo producto de software sirve a varios clientes (inquilinos) desde el mismo sistema en ejecución. Cada inquilino percibe que tiene “su propia app”, pero tras bastidores comparten partes de la infraestructura —como los mismos servidores web, la misma base de código y, con frecuencia, la misma base de datos.
Un modelo mental útil es un edificio de apartamentos. Cada quien tiene su unidad cerrada (sus datos y configuraciones), pero se comparte el ascensor, la fontanería y el equipo de mantenimiento (el cómputo, almacenamiento y operaciones de la app).
Por qué los equipos eligen multi-tenancy
La mayoría de los equipos no eligen SaaS multi-inquilino porque esté de moda: lo hacen porque es eficiente:
- Menor coste por cliente: la infraestructura compartida suele ser más barata que provisionar una pila completa por cliente.
- Operaciones más simples: una plataforma que monitorizar, parchear y asegurar (en lugar de cientos de despliegues pequeños).
- Entrega más rápida: las mejoras llegan a todos a la vez y se evita la “deriva de versiones” entre clientes.
Dónde puede fallar
Los dos modos clásicos de fallo son seguridad y rendimiento.
En seguridad: si los límites entre inquilinos no se aplican en todas las capas, un bug puede filtrar datos entre clientes. Estas filtraciones rara vez son ataques espectaculares; suelen ser errores ordinarios como un filtro perdido, un control de permisos mal configurado o un job en background que se ejecuta sin contexto de inquilino.
En rendimiento: los recursos compartidos implican que un inquilino muy activo puede degradar a otros. Ese efecto de “vecino ruidoso” puede aparecer como consultas lentas, cargas con picos o un cliente que consume una parte desproporcionada de la capacidad de la API.
Vista rápida de los patrones cubiertos
Este artículo recorre los bloques de construcción que usan los equipos para gestionar esos riesgos: aislamiento de datos (base de datos, esquema o filas), identidad y permisos conscientes del inquilino, controles contra vecinos ruidosos y patrones operativos para escalar y gestionar cambios.
El trade-off central: aislamiento vs eficiencia
Multi-tenancy es una decisión sobre dónde te posicionas en un espectro: cuánto compartes entre inquilinos frente a cuánto dedicas por inquilino. Cada patrón arquitectónico es solo un punto distinto en esa línea.
Recursos compartidos vs dedicados: el espectro central
En un extremo, los inquilinos comparten casi todo: las mismas instancias de la app, las mismas bases de datos, las mismas colas y las mismas caches —separados lógicamente por IDs de inquilino y reglas de acceso. Esto suele ser lo más barato y sencillo de operar porque se agrupa la capacidad.
En el otro extremo, los inquilinos obtienen su propio “slice” del sistema: bases de datos separadas, cómputo separado, a veces incluso despliegues separados. Esto aumenta la seguridad y el control, pero también la sobrecarga operativa y el coste.
Por qué aislamiento y coste tiran en direcciones opuestas
El aislamiento reduce la probabilidad de que un inquilino acceda a los datos de otro, consuma su presupuesto de rendimiento o se vea afectado por patrones de uso inusuales. También facilita cumplir ciertos requisitos de auditoría y cumplimiento.
La eficiencia mejora cuando se amortiza la capacidad ociosa entre muchos inquilinos. La infraestructura compartida permite ejecutar menos servidores, mantener pipelines de despliegue más simples y escalar según la demanda agregada en vez de la demanda máxima por inquilino.
Factores comunes para decidir
Tu punto “correcto” en el espectro raramente es filosófico: lo determinan las restricciones:
- SLA y expectativas del cliente: objetivos estrictos de disponibilidad o latencia te impulsan hacia más aislamiento.
- Cumplimiento y residencia de datos: pueden exigir almacenamiento o entornos dedicados.
- Etapa de crecimiento: los productos iniciales suelen empezar más compartidos para moverse rápido; más tarde puedes ofrecer opciones dedicadas para clientes grandes.
- Madurez operativa: más aislamiento normalmente implica más cosas que monitorizar, parchear y migrar.
Un modelo mental simple para elegir patrones
Hazte dos preguntas:
-
¿Cuál es el radio de impacto si un inquilino se comporta mal o es comprometido?
-
¿Cuál es el coste de reducir ese radio?
Si el radio debe ser mínimo, elige componentes más dedicados. Si lo que importa es coste y velocidad, comparte más —pero invierte en controles de acceso fuertes, límites de tasa y monitorización por inquilino para mantener la seguridad.
Modelos multi-inquilino en resumen
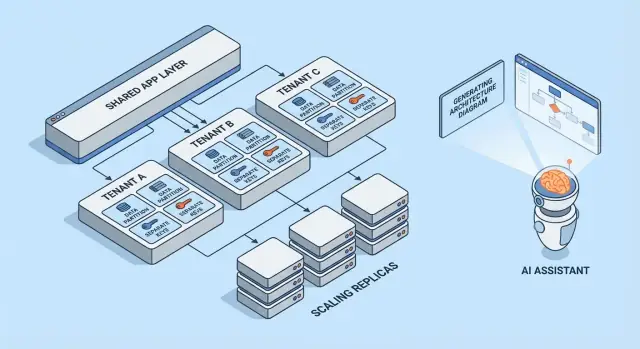
Multi-tenancy no es una única arquitectura: es un conjunto de formas de compartir (o no) la infraestructura entre clientes. El mejor modelo depende de cuánto aislamiento necesitas, cuántos inquilinos esperas y cuánta sobrecarga operativa puede asumir tu equipo.
1) Single-tenant (dedicado) — la base
Cada cliente obtiene su propia pila de la aplicación (o al menos su runtime y base de datos aislados). Es lo más sencillo de razonar respecto a seguridad y rendimiento, pero suele ser lo más caro por inquilino y puede ralentizar la escalada de operaciones.
2) App compartida + DB compartida — coste más bajo, requiere más cuidado
Todos los inquilinos ejecutan la misma aplicación y la misma base de datos. Los costes son típicamente los más bajos porque maximizas la reutilización, pero debes ser meticuloso con el contexto del inquilino en todas partes (consultas, cache, jobs en background, exportaciones analíticas). Un único error puede convertirse en una fuga de datos entre inquilinos.
3) App compartida + DB separada — aislamiento más fuerte, más ops
La aplicación se comparte, pero cada inquilino tiene su propia base de datos (o instancia de BD). Esto mejora el control del radio de impacto ante incidentes, facilita backups/restores a nivel de inquilino y puede simplificar conversaciones de cumplimiento. El intercambio es operativo: más bases de datos que provisionar, monitorizar, migrar y asegurar.
4) Modelos híbridos para “inquilinos grandes”
Muchos productos SaaS mezclan enfoques: la mayoría de clientes vive en infraestructura compartida, mientras que inquilinos grandes o regulados obtienen bases de datos o cómputo dedicado. Lo híbrido suele ser el estado práctico final, pero necesita reglas claras: quién califica, a qué precio y cómo se despliegan las actualizaciones.
Si quieres un análisis más profundo de técnicas de aislamiento dentro de cada modelo, ve a /blog/data-isolation-patterns.
Patrones de aislamiento de datos (BD, esquema, fila)
El aislamiento de datos responde a una pregunta simple: “¿Puede un cliente ver o afectar los datos de otro cliente?” Hay tres patrones comunes, cada uno con implicaciones diferentes en seguridad y operación.
Aislamiento a nivel de fila (tablas compartidas + tenant_id)
Todos los inquilinos comparten las mismas tablas y cada fila incluye una columna tenant_id. Este es el modelo más eficiente para inquilinos pequeños a medianos porque minimiza la infraestructura y mantiene los informes y la analítica sencillos.
El riesgo también es directo: si alguna consulta olvida filtrar por tenant_id, puedes filtrar datos. Incluso un único endpoint “admin” o un job en background puede ser un punto débil. Mitigaciones incluyen:
- Forzar el filtrado por inquilino en una capa compartida de acceso a datos (para que los desarrolladores no implementen filtros manualmente)
- Usar funciones de la base de datos como row-level security (RLS) cuando esté disponible
- Añadir pruebas automatizadas que intenten acceso cruzado entre inquilinos intencionalmente
- Indexar para caminos de acceso comunes (a menudo
(tenant_id, created_at)o(tenant_id, id)) para que las consultas acotadas por inquilino sigan siendo rápidas
Esquema por inquilino (misma BD, esquemas separados)
Cada inquilino obtiene su propio esquema (namespaces como tenant_123.users, tenant_456.users). Esto mejora el aislamiento respecto al compartido por filas y puede facilitar exportes por inquilino o afinación específica por cliente.
El intercambio es la sobrecarga operativa. Las migraciones necesitan ejecutarse en muchos esquemas y las fallas se vuelven más complejas: podrías migrar con éxito 9.900 inquilinos y quedarte atascado con 100. La monitorización y las herramientas importan aquí —tu proceso de migración necesita reintentos claros y reporte.
Base de datos por inquilino (BD separada)
Cada inquilino obtiene una base de datos separada. El aislamiento es fuerte: los límites de acceso son más claros, las consultas ruidosas de un inquilino afectan menos a otros y restaurar un solo inquilino desde backup es mucho más limpio.
Los costes y el escalado son las principales desventajas: más bases de datos que gestionar, más pools de conexión y potencialmente más trabajo de upgrade/migración. Muchos equipos reservan este modelo para inquilinos de alto valor o regulados, mientras los más pequeños permanecen en infraestructura compartida.
Sharding y estrategias de colocación a medida que crecen los inquilinos
Los sistemas reales a menudo mezclan estos patrones. Un camino común es aislamiento a nivel de fila en el crecimiento temprano y luego “graduar” inquilinos grandes a esquemas o bases de datos separadas.
Sharding añade una capa de colocación: decidir en qué cluster de BD vive un inquilino (por región, por tier de tamaño o por hashing). La clave es hacer la colocación explícita y cambiable —para poder mover un inquilino sin reescribir la app y escalar añadiendo shards en vez de rediseñar todo.
Identidad, acceso y contexto de inquilino
El multi-tenancy falla de maneras sorprendentemente ordinarias: un filtro faltante, un objeto cacheado compartido entre inquilinos o una función de admin que “olvida” para quién es la petición. La solución no es una única gran característica de seguridad: es mantener un contexto de inquilino consistente desde el primer byte de la petición hasta la última consulta a la base de datos.
Identificación de inquilino (cómo sabes “quién”)
La mayoría de productos SaaS se decantan por un identificador principal y tratan lo demás como conveniencia:
- Subdominio:
acme.yourapp.comes fácil para usuarios y funciona bien con experiencias de marca por inquilino. - Header: útil para clientes API y servicios internos (pero debe estar autenticado).
- Claim en token: un JWT firmado (o sesión) incluye
tenant_id, lo que dificulta la manipulación.
Elige una fuente de verdad y regístrala en todos lados. Si soportas múltiples señales (subdominio + token), define precedencia y rechaza peticiones ambiguas.
Scoped de la petición (cómo cada consulta permanece dentro del inquilino)
Una buena regla: una vez resuelvas tenant_id, todo lo que venga después debería leerlo de un único lugar (contexto de la petición), no re-derivarlo.
Guardrails comunes incluyen:
- Middleware que adjunta
tenant_idal contexto de la petición - Helpers de acceso a datos que requieren
tenant_idcomo parámetro - Aplicación de la base de datos (como políticas a nivel de fila) para que los errores fallen cerrados
handleRequest(req):
tenantId = resolveTenant(req) // subdomain/header/token
req.context.tenantId = tenantId
return next(req)
Fundamentos de autorización (roles dentro de un inquilino)
Separa autenticación (quién es el usuario) de autorización (qué puede hacer).
Los roles típicos en SaaS son Owner / Admin / Member / Read-only, pero lo clave es el scope: un usuario puede ser Admin en el Inquilino A y Member en el Inquilino B. Almacena permisos por inquilino, no globalmente.
Prevención de filtraciones entre inquilinos (tests y guardrails)
Trata el acceso cruzado como un incidente de primera categoría y prevénlo proactivamente:
- Añade tests automatizados que intenten leer datos del Inquilino B estando autenticado como Inquilino A
- Haz que los bugs por falta de filtros sean más difíciles de mandar a producción (linters, builders de consultas, parámetros obligatorios de inquilino)
- Registra y alerta sobre patrones sospechosos (por ejemplo, discrepancia entre token y subdominio)
Si quieres una lista operativa más detallada, enlaza estas reglas en tus runbooks de ingeniería en /security y mantenlas versionadas junto al código.
Aislamiento más allá de la base de datos
Migraciones más seguras en la práctica
Experimenta con cambios de esquema y revierte rápido si una migración falla.
El aislamiento en la BD es solo la mitad de la historia. Muchos incidentes reales en multi-tenant ocurren en la tubería compartida alrededor de tu app: caches, colas y almacenamiento. Estas capas son rápidas, convenientes y fáciles de convertir accidentalmente en globales.
Caches compartidas: prevenir colisiones de claves y fugas de datos
Si varios inquilinos comparten Redis o Memcached, la regla principal es simple: nunca almacenar claves que sean agnósticas al inquilino.
Un patrón práctico es prefijar cada clave con un identificador estable del inquilino (no un dominio de correo, no un nombre visible). Por ejemplo: t:{tenant_id}:user:{user_id}. Esto hace dos cosas:
- Evita colisiones donde dos inquilinos tienen los mismos IDs internos
- Hace factible la invalidación masiva (borrar por prefijo) durante incidentes de soporte o migraciones
También decide qué está permitido compartir globalmente (por ejemplo, feature flags públicas, metadatos estáticos) y documenta esto —los globals accidentales son una fuente común de exposición cruzada.
Límites de tasa y cuotas conscientes del inquilino
Aunque los datos estén aislados, los inquilinos aún pueden impactarse mutuamente a través del cómputo compartido. Añade límites conscientes del inquilino en los bordes:
- Límites de tasa API por inquilino (y a menudo por usuario dentro de un inquilino)
- Cuotas para operaciones costosas (exportes, generación de informes, llamadas a IA)
Haz el límite visible (encabezados, avisos en UI) para que los clientes entiendan que el throttling es una política y no una inestabilidad.
Jobs en background: particionar colas por inquilino
Una única cola compartida puede permitir que un inquilino muy activo domine el tiempo de los workers.
Arreglos comunes:
- Colas separadas por tier/plan (por ejemplo,
free,pro,enterprise) - Colas particionadas por bucket de inquilinos (hashear tenant_id en N colas)
- Planificación consciente del inquilino para que cada inquilino obtenga una porción justa
Siempre propaga el contexto de inquilino en el payload del job y en los logs para evitar efectos secundarios sobre inquilinos equivocados.
Almacenamiento de archivos/objetos: rutas, políticas y claves separadas
Para almacenamiento tipo S3/GCS, el aislamiento suele ser por rutas y políticas:
- Bucket por inquilino para separación estricta (límites más fuertes, más overhead)
- Bucket compartido con prefijos por inquilino (más simple, requiere IAM y URLs firmadas cuidadosas)
Cualquiera que elijas, valida que uploads/downloads comprueben la propiedad del inquilino en cada petición, no solo en la UI.
Manejo de vecinos ruidosos y uso justo de recursos
Los sistemas multi-inquilino comparten infraestructura, lo que significa que un inquilino puede consumir más de su parte. Este es el problema del vecino ruidoso: una única carga ruidosa degrada el rendimiento del resto.
Cómo se ve un “vecino ruidoso”
Imagina una función de reporting que exporta un año de datos a CSV. El Inquilino A programa 20 exportes a las 9:00 AM. Esos exportes saturan CPU y I/O de BD, así que las pantallas normales del Inquilino B empiezan a hacer timeouts —a pesar de que B no está haciendo nada inusual.
Controles de recursos: límites, cuotas y modelado de carga
Prevenir esto comienza con límites explícitos de recursos:
- Rate limits (requests por segundo) por inquilino y por endpoint, para que APIs costosas no se puedan spamear.
- Cuotas (diarias/mensuales) para cosas como exportes, emails, llamadas a IA o jobs en background.
- Modelado de carga: mete tareas pesadas (exportes, importes, reindexados) en colas con topes de concurrencia por inquilino y reglas de prioridad.
Un patrón práctico es separar tráfico interactivo de trabajo por lotes: mantén las peticiones de cara al usuario en un carril rápido y empuja lo demás a colas controladas.
Disyuntores por inquilino y compartimentos (bulkheads)
Añade válvulas de seguridad que entren en acción cuando un inquilino cruza un umbral:
- Circuit breakers: rechazar o posponer temporalmente operaciones costosas cuando la tasa de errores, latencia o profundidad de cola excede límites para ese inquilino.
- Bulkheads: aislar pools compartidos (conexiones BD, threads de worker, cache) para que un inquilino no agote la capacidad global.
Bien hecho, el Inquilino A puede solo afectar su propia velocidad de exporte sin tumbar al Inquilino B.
Cuándo mover a un inquilino a capacidad dedicada
Mueve a un inquilino a recursos dedicados cuando consistentemente excede las suposiciones compartidas: throughput sostenido alto, picos impredecibles ligados a eventos críticos para su negocio, requisitos de cumplimiento estrictos o cuando su carga requiere afinación personalizada. Una regla simple: si proteger a otros inquilinos exige throttlear permanentemente a un cliente que paga, es hora de ofrecer capacidad dedicada (o un tier superior) en vez de apagar incendios constantemente.
Patrones de escalado que funcionan en SaaS multi-inquilino
Planifica tu modelo multitenant
Diseña un plan para una app multitenant en el chat e itera con seguridad usando el modo de planificación.
Escalar multi-inquilino es menos sobre “más servidores” y más sobre evitar que el crecimiento de un inquilino sorprenda a todos los demás. Los mejores patrones hacen el escalado predecible, medible y reversible.
Escalado horizontal para servicios stateless
Empieza por hacer tu capa web/API stateless: guarda sesiones en una cache compartida (o usa auth basada en tokens), guarda uploads en object storage y manda trabajo largo a jobs en background. Una vez que las peticiones no dependan de memoria o disco local, puedes añadir instancias detrás de un balanceador y escalar hacia fuera rápido.
Un consejo práctico: conserva el contexto de inquilino en el borde (derivado del subdominio o headers) y pásalo a cada manejador. Stateless no significa ignorar al inquilino: significa ser consciente del inquilino sin servidores sticky.
Hotspots por inquilino: identificarlos y suavizarlos
La mayoría de los problemas de escalado son “un inquilino es diferente”. Vigila hotspots como:
- Un inquilino generando tráfico desproporcionado
- Algunos inquilinos con datasets muy grandes
- Uso por lotes (reportes de fin de mes, importes nocturnos)
Tácticas para suavizar incluyen límites por inquilino, ingestión basada en colas, cacheo de paths de lectura específicos por inquilino y shardear inquilinos pesados en pools de workers separados.
Réplicas de lectura, particionado y workloads asíncronos
Usa réplicas de lectura para cargas orientadas a lectura (dashboards, búsqueda, analítica) y mantén escrituras en el primario. El particionado (por inquilino, por tiempo o ambos) ayuda a mantener índices más pequeños y consultas más rápidas. Para tareas costosas —exportes, scoring de ML, webhooks— prefiere jobs asíncronos con idempotencia para que los reintentos no multipliquen la carga.
Señales de planificación de capacidad y umbrales simples
Mantén señales simples y conscientes del inquilino: latencia p95, tasa de errores, profundidad de colas, CPU de BD y tasa de peticiones por inquilino. Define umbrales sencillos (por ejemplo, “profundidad de cola > N por 10 minutos” o “p95 > X ms”) que disparen autoscaling o caps temporales por inquilino —antes de que otros inquilinos lo noten.
Observabilidad y operaciones por inquilino
Los sistemas multi-inquilino no fallan globalmente primero: suelen fallar para un inquilino, un tier o una carga ruidosa. Si tus logs y dashboards no pueden responder “¿qué inquilino está afectado?” en segundos, el on-call se convierte en un juego de adivinanzas.
Logs, métricas y trazas con contexto de inquilino
Empieza con un contexto de inquilino consistente en toda la telemetría:
- Logs: incluye
tenant_id,request_idy unactor_idestable (usuario/servicio) en cada petición y job en background. - Métricas: emite contadores y histogramas de latencia desglosados por tier de inquilino al menos (p. ej.,
tier=basic|premium) y por endpoint de alto nivel (no URLs crudas). - Trazas: propaga el contexto de inquilino como atributos de traza para filtrar una traza lenta a un inquilino específico y ver dónde se consume tiempo (BD, cache, llamadas a terceros).
Controla la cardinalidad: métricas por inquilino para todos los inquilinos pueden ser caras. Un compromiso común es métricas a nivel de tier por defecto y drill-down por inquilino bajo demanda (por ejemplo, muestreo de trazas para “top 20 inquilinos por tráfico” o “inquilinos que actualmente violan SLO”).
Evitar fugas de datos sensibles en la telemetría
La telemetría es un canal de exportación de datos. Trátala como datos de producción.
Prefiere IDs sobre contenido: registra customer_id=123 en lugar de nombres, emails, tokens o payloads de consultas. Añade redacción en el layer de logger/SDK y bloquea secretos comunes (cabeceras Authorization, API keys). Para flujos de soporte, guarda los payloads de depuración en un sistema separado y controlado, no en logs compartidos.
SLOs por tier de inquilino (sin prometer de más)
Define SLOs que coincidan con lo que realmente puedes hacer cumplir. Los inquilinos premium pueden tener presupuestos de latencia/errores más ajustados, pero solo si tienes controles (rate limits, aislamiento de workloads, colas de prioridad). Publica los SLOs por tier como objetivos y monitorízalos por tier y para un conjunto curado de inquilinos de alto valor.
Runbooks de on-call: incidentes comunes en SaaS multi-inquilino
Tus runbooks deben empezar con “identificar inquilino(s) afectados” y luego la acción de aislamiento más rápida:
- Vecino ruidoso: throttlear al inquilino, pausar jobs pesados o moverlos a una cola de baja prioridad.
- Hotspots BD/queries fuera de control: habilitar timeouts de consulta, inspeccionar consultas top por inquilino, aplicar un índice o limitar el endpoint.
- Bugs de contexto de inquilino (mezcla de datos): deshabilitar inmediatamente el feature flag o endpoint y verificar el scope de inquilino en checks de acceso.
- Acumulación de jobs en background: drenar colas por inquilino, capear concurrencia y re-ejecutar con salvaguardas de idempotencia.
Operativamente, la meta es simple: detectar por inquilino, contener por inquilino y recuperar sin impactar a todos los demás.
Despliegues, migraciones y releases por inquilino
Multi-tenancy cambia el ritmo de shipping. No estás desplegando “una app”; estás desplegando runtime y caminos de datos compartidos que muchos clientes usan a la vez. La meta es entregar nuevas funcionalidades sin forzar una actualización sincronizada y masiva para todos los inquilinos.
Despliegues rolling y migraciones de baja latencia
Prefiere patrones de despliegue que toleren versiones mixtas por una ventana corta (blue/green, canary, rolling). Eso solo funciona si los cambios en la base de datos también se planifican por etapas.
Una regla práctica es expand → migrate → contract:
- Expand: añadir columnas/tablas/índices sin romper el código existente.
- Migrate: rellenar datos en batches (a menudo por inquilino) y verificar.
- Contract: eliminar campos viejos solo después de que todas las instancias de la app dejen de depender de ellos.
Para tablas con mucho tráfico, haz backfills incrementalmente (y con throttle), de lo contrario crearás un evento de vecino ruidoso durante la migración.
Feature flags por inquilino para rollouts más seguros
Los feature flags a nivel de inquilino te permiten desplegar código globalmente y activar comportamientos selectivamente.
Esto soporta:
- Programas de acceso temprano para algunos inquilinos
- Rollback rápido desactivando la feature para los inquilinos afectados
- Experimentos A/B sin bifurcar despliegues
Mantén el sistema de flags auditable: quién activó qué, para qué inquilino y cuándo.
Versionado y expectativas de compatibilidad hacia atrás
Asume que algunos inquilinos pueden quedarse atrás en configuración, integraciones o patrones de uso. Diseña APIs y eventos con versionado claro para que nuevos productores no rompan consumidores antiguos.
Expectativas comunes que poner internamente:
- Las nuevas releases deben leer tanto formas antiguas como nuevas durante ventanas de migración.
- Las deprecaciones requieren una línea de tiempo publicada (aunque sea notas internas y una plantilla de email para clientes).
Gestión de configuración específica por inquilino
Trata la configuración de inquilino como superficie del producto: necesita validación, valores por defecto e historial de cambios.
Almacena la configuración separada del código (idealmente separada de secretos en runtime) y soporta un modo seguro de fallback cuando la config es inválida. Una página interna ligera como /settings/tenants puede ahorrar horas durante respuesta a incidentes y despliegues por etapas.
Cómo ayudan las arquitecturas generadas por IA (y sus límites)
Configura el enrutamiento por tenant
Prueba el enrutamiento por subdominio o dominio personalizado para tenants sin reconstruir tu stack.
La IA puede acelerar el pensamiento arquitectónico inicial para un SaaS multi-inquilino, pero no sustituye al juicio de ingeniería, las pruebas o la revisión de seguridad. Trátala como un socio de brainstorming que produce borradores —luego verifica cada asunción.
Qué debería (y no debería) hacer una arquitectura generada por IA
La IA es útil para generar opciones y señalar modos típicos de fallo (como dónde se puede perder el contexto de inquilino o dónde recursos compartidos pueden crear sorpresas). No debería decidir tu modelo, garantizar cumplimiento o validar rendimiento. No puede ver tu tráfico real, las fortalezas de tu equipo ni los casos límite ocultos en integraciones legacy.
Entradas que importan: requisitos, restricciones, riesgos, crecimiento
La calidad del output depende de lo que le des. Entradas útiles incluyen:
- Número de inquilinos hoy vs. en 12–24 meses y volumen de datos esperado por inquilino
- Requisitos de aislamiento (contractuales, regulatorios, expectativas del cliente)
- Presupuesto y capacidad operativa (madurez on-call, soporte SRE, tooling)
- Objetivos de latencia, patrones de pico y burstiness por inquilino
- Tolerancia al riesgo: ¿qué pasa si un inquilino impacta a otro?
Usar IA para proponer opciones de patrón con trade-offs
Pide 2–4 diseños candidatos (por ejemplo: base de datos por inquilino vs. esquema por inquilino vs. aislamiento por filas) y solicita una tabla clara de trade-offs: coste, complejidad operativa, radio de impacto, esfuerzo de migración y límites de escalado. La IA es buena listando gotchas que puedes convertir en preguntas de diseño para tu equipo.
Si quieres pasar de “arquitectura borrador” a un prototipo funcional más rápido, una plataforma vibe-coding como Koder.ai puede ayudarte a convertir esas decisiones en un esqueleto de app real vía chat —a menudo con frontend en React y backend en Go + PostgreSQL— para validar antes la propagación del contexto de inquilino, límites de tasa y flujos de migración. Funciones como modo planificación y snapshots/rollback son especialmente útiles cuando iteras sobre modelos de datos multi-inquilino.
Usar IA para generar modelos de amenaza y listas de verificación
La IA puede redactar un threat model simple: puntos de entrada, fronteras de confianza, propagación del contexto de inquilino y errores comunes (como checks de autorización faltantes en jobs en background). Úsala para generar listas de verificación para PRs y runbooks —pero valida con expertos reales en seguridad y tu historial de incidentes.
Una checklist práctica de selección para tu equipo
Elegir un enfoque multi-inquilino es menos sobre “mejor práctica” y más sobre encajar: la sensibilidad de tus datos, tu ritmo de crecimiento y cuánta complejidad operativa puedes soportar.
Checklist paso a paso (úsalo en un taller de 30 minutos)
-
Datos: ¿Qué datos se comparten entre inquilinos (si los hay)? ¿Qué nunca debe convivir?
-
Identidad: ¿Dónde vive la identidad del inquilino (links de invitación, dominios, claims SSO)? ¿Cómo se establece el contexto del inquilino en cada petición?
-
Aislamiento: Decide tu nivel de aislamiento por defecto (fila/esquema/base de datos) e identifica excepciones (p. ej., clientes enterprise que necesitan separación más fuerte).
-
Escalado: Identifica la primera presión de escalado que esperas (almacenamiento, tráfico de lectura, jobs en background, analítica) y elige el patrón más simple que lo resuelva.
Preguntas para validar con ingenieros y revisores de seguridad
- ¿Cómo prevenimos acceso cruzado si un desarrollador olvida un filtro?
- ¿Cuál es nuestra historia de auditoría por inquilino (quién hizo qué y cuándo)?
- ¿Cómo manejamos la eliminación y retención de datos por inquilino?
- ¿Cuál es el radio de impacto de una migración mala o una query runaway?
- ¿Podemos throttlear, limitar y presupuestar recursos por inquilino?
Señales de alarma que requieren diseño más profundo
- “Añadiremos checks de inquilino más tarde.”
- Herramientas de administración compartidas que pueden ver todo sin controles estrictos.
- Sin plan para backups/restores por inquilino o respuesta a incidentes.
- Una única cola/pool de workers sin fairness por inquilino.
Resumen de “acción recomendada” de ejemplo
Recomendación: Empezar con aislamiento por filas + aplicación estricta de contexto de inquilino, añadir throttles por inquilino y definir un camino de upgrade a esquema/base de datos para inquilinos de alto riesgo.
Próximas acciones (2 semanas): modelar amenazas en los límites de inquilino, prototipar la aplicación de enforcement en un endpoint y ensayar una migración en una copia de staging. Para guía de rollout, ve a /blog/tenant-release-strategies.