Por qué Patterson y RISC siguen importando
David Patterson suele presentarse como “un pionero de RISC”, pero su influencia perdura más allá de cualquier diseño de CPU concreto. Popularizó una forma práctica de pensar sobre las computadoras: tratar el rendimiento como algo que se puede medir, simplificar y mejorar de extremo a extremo —desde las instrucciones que entiende un chip hasta las herramientas de software que generan esas instrucciones.
“Pensamiento RISC” en términos sencillos
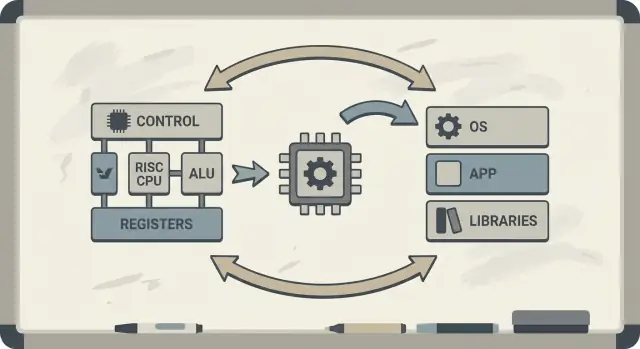
RISC (Reduced Instruction Set Computing) es la idea de que un procesador puede funcionar más rápido y de forma más predecible si se centra en un conjunto más pequeño de instrucciones simples. En lugar de poner en hardware un gran catálogo de operaciones complejas, haces que las operaciones comunes sean rápidas, regulares y fáciles de canalizar. La ganancia no es “menos capacidad”: son bloques simples que, ejecutados eficientemente, suelen ganar en cargas de trabajo reales.
Codiseño: chips y código mejorándose mutuamente
Patterson también defendió el codiseño hardware–software: un bucle de retroalimentación donde arquitectos de chips, autores de compiladores y diseñadores de sistemas iteran juntos.
Si un procesador está diseñado para ejecutar bien patrones simples, los compiladores pueden producir esos patrones de forma fiable. Si los compiladores muestran que los programas reales pasan tiempo en ciertas operaciones (como accesos a memoria), el hardware puede ajustarse para manejar mejor esos casos. Por eso las discusiones sobre la ISA se conectan naturalmente con optimizaciones del compilador, cachés y canalización.
Qué obtendrás de este artículo
Aprenderás por qué las ideas RISC se conectan con el rendimiento por vatio (no solo con la velocidad bruta), cómo la “predictibilidad” hace que las CPU modernas y los chips móviles sean más eficientes y cómo estos principios aparecen en los dispositivos de hoy —desde portátiles hasta servidores en la nube.
Si quieres un mapa de los conceptos clave antes de profundizar, salta a /blog/key-takeaways-and-next-steps.
El problema al que respondía RISC
Los primeros microprocesadores se construyeron bajo fuertes restricciones: el silicio tenía espacio limitado para lógica, la memoria costaba y el almacenamiento era lento. Los diseñadores intentaban vender equipos asequibles y “lo suficientemente rápidos”, a menudo con cachés pequeñas (o ninguna), velocidades de reloj modestas y memoria principal muy limitada respecto a lo que el software demandaba.
La apuesta antigua: instrucciones complejas = programas más rápidos
Una idea popular entonces era que si la CPU ofrecía instrucciones de alto nivel más potentes —capaces de hacer varios pasos a la vez—, los programas correrían más rápido y serían más fáciles de escribir. Si una instrucción podía “hacer el trabajo de varias”, el razonamiento decía que harías falta menos instrucciones, ahorrando tiempo y memoria.
Esa es la intuición tras muchos diseños CISC (complex instruction set computing): dar a programadores y compiladores una gran caja de herramientas con operaciones sofisticadas.
La descoincidencia: lo que la CPU ofrecía vs lo que se usaba
El problema era que los programas reales (y los compiladores que los traducen) no aprovechaban esa complejidad de forma consistente. Muchas de las instrucciones más elaboradas se usaban raramente, mientras que un pequeño conjunto de operaciones simples —cargar datos, almacenar datos, sumar, comparar, saltar— aparecían una y otra vez.
Mientras tanto, soportar un gran catálogo de instrucciones complejas hacía las CPUs más difíciles de construir y más lentas de optimizar. La complejidad consumía área de chip y esfuerzo de diseño que podría haberse dedicado a hacer que las operaciones comunes funcionaran de forma rápida y predecible.
RISC respondió a esa brecha: centra la CPU en lo que el software hace la mayor parte del tiempo y acelera esos caminos, dejando que los compiladores hagan más del trabajo de “orquestación” de forma sistemática.
RISC vs CISC: la idea en lenguaje llano
Una forma sencilla de pensar en CISC vs RISC es comparar talleres.
CISC (Complex Instruction Set Computing) es como un taller lleno de herramientas especializadas y elaboradas: cada una puede hacer mucho de una vez. Una sola “instrucción” podría cargar datos de memoria, hacer un cálculo y almacenar el resultado, todo en un paquete.
RISC (Reduced Instruction Set Computing) es como llevar un conjunto más pequeño de herramientas fiables que usas a menudo —martillo, destornillador, cinta métrica— y construir todo mediante pasos repetibles. Cada instrucción tiende a hacer una tarea pequeña y clara.
Por qué “más simple” puede ser más rápido
Cuando las instrucciones son más simples y uniformes, la CPU puede ejecutarlas con una línea de montaje más limpia (una canalización). Esa línea es más fácil de diseñar, de llevar a frecuencias de reloj más altas y de mantener ocupada.
Con instrucciones estilo CISC “que hacen mucho”, la CPU a menudo tiene que decodificar y descomponer la instrucción compleja en pasos internos de todos modos. Eso añade complejidad y hace más difícil mantener la canalización fluyendo sin interrupciones.
La predictibilidad importa
RISC busca tiempos de instrucción predecibles —muchas instrucciones tardan aproximadamente lo mismo. La predictibilidad ayuda a la CPU a programar el trabajo eficientemente y ayuda a los compiladores a generar código que mantenga la canalización llena en lugar de estancarse.
Los trade‑offs (y por qué suelen compensar)
RISC normalmente necesita más instrucciones para hacer la misma tarea. Eso puede significar:
- Tamaño de programa ligeramente mayor (más bytes de código)
- Más búsquedas de instrucciones en memoria
Pero puede seguir siendo una buena operación si cada instrucción es rápida, la canalización se mantiene fluida y el diseño global es más simple.
En la práctica, compiladores bien optimizados y buen caching pueden compensar la desventaja de “más instrucciones” —y la CPU puede pasar más tiempo haciendo trabajo útil y menos tiempo desenredando instrucciones complicadas.
Berkeley RISC y la mentalidad de “medir y luego diseñar”
Berkeley RISC no fue solo una nueva ISA. Fue una actitud de investigación: no empieces por lo que parece elegante en papel —empieza por lo que los programas realmente hacen y después adapta la CPU a esa realidad.
Núcleo pequeño y rápido + compilador inteligente
A nivel conceptual, el equipo de Berkeley buscó un núcleo de CPU lo suficientemente simple como para correr muy rápido y de forma predecible. En lugar de llenar el hardware con trucos de instrucciones complejas, confiaron en el compilador para hacer más trabajo: elegir instrucciones sencillas, agendarlas bien y mantener los datos en registros tanto como sea posible.
Esa división del trabajo importó. Un núcleo más pequeño y limpio es más fácil de canalizar eficazmente, más sencillo de razonar y a menudo más rápido por transistor. El compilador, que ve el programa completo, puede planificar con antelación de formas que el hardware no puede hacer fácilmente en tiempo de ejecución.
Medir cargas reales, no suposiciones
David Patterson enfatizó la medición porque el diseño de computadores está lleno de mitos tentadores —características que suenan útiles pero raramente aparecen en código real. Berkeley RISC impulsó el uso de benchmarks y trazas de carga de trabajo para encontrar los caminos calientes: los bucles, llamadas a funciones y accesos a memoria que dominan el tiempo de ejecución.
Esto se conecta directamente con la regla de oro: “hacer rápido el caso común”. Si la mayoría de las instrucciones son operaciones simples y cargas/almacenamientos, optimizar esos casos frecuentes rinde más que acelerar instrucciones complejas y raras.
La lección duradera es que RISC fue tanto una arquitectura como una mentalidad: simplificar lo frecuente, validar con datos y tratar al hardware y al software como un único sistema que puede afinarse conjuntamente.
Qué significa codiseñar hardware y software
Codiseñar hardware y software es la idea de que no diseñas una CPU en aislamiento. Diseñas el chip y el compilador (y a veces el sistema operativo) con el uno pensado para el otro, de modo que los programas reales funcionen rápido y de forma eficiente —no solo secuencias sintéticas “mejor caso” de instrucciones.
Un bucle de retroalimentación sencillo
El codiseño funciona como un bucle de ingeniería:
-
Decisiones de ISA: la arquitectura de conjunto de instrucciones (ISA) decide qué puede expresar fácilmente la CPU (por ejemplo, acceso memoria “load/store”, muchos registros, modos de direccionamiento simples).
-
Estrategias del compilador: el compilador se adapta —manteniendo variables calientes en registros, reordenando instrucciones para evitar stalls y eligiendo convenciones de llamada que reduzcan la sobrecarga.
-
Resultados de la carga de trabajo: mides programas reales (compiladores, bases de datos, gráficos, código de SO) y ves dónde se va el tiempo y la energía.
-
Siguiente diseño: ajustas la ISA y la microarquitectura (profundidad de pipeline, número de registros, tamaños de caché) según esas mediciones.
Aquí hay un pequeño bucle (C) que destaca la relación:
for (int i = 0; i < n; i++)
sum += a[i];
En una ISA de estilo RISC, el compilador típicamente mantiene sum e i en registros, usa instrucciones simples de load para a[i] y realiza scheduler de instrucciones para que la CPU se mantenga ocupada mientras una carga está en vuelo.
Por qué ignorar al compilador desperdicia silicio y energía
Si un chip añade instrucciones complejas o hardware especial que los compiladores usan raramente, esa área sigue consumiendo energía y esfuerzo de diseño. Mientras tanto, las cosas “aburridas” que los compiladores sí usan —suficientes registros, pipelines predecibles, convenciones de llamada eficientes— pueden quedar subfinanciadas.
El pensamiento RISC de Patterson enfatizaba gastar silicio donde el software real pueda beneficiarse realmente.
Canalizaciones, predictibilidad y ayuda del compilador
Lleva el pensamiento RISC al móvil
Crea una app móvil con Flutter desde el chat e itera en velocidad, batería y UX.
Una idea clave de RISC fue facilitar que la “línea de montaje” de la CPU se mantuviera ocupada. Esa línea es la canalización: en lugar de completar una instrucción completamente antes de empezar la siguiente, el procesador divide el trabajo en etapas (fetch, decode, execute, write-back) y las solapa. Cuando todo fluye, completas cerca de una instrucción por ciclo —como coches moviéndose por una fábrica de varias estaciones.
Por qué las instrucciones más simples mantienen la línea en movimiento
Las canalizaciones funcionan mejor cuando cada ítem en la línea es similar. Las instrucciones RISC fueron diseñadas para ser uniformes y predecibles (a menudo de longitud fija, con direccionamiento simple). Eso reduce los “casos especiales” donde una instrucción necesita tiempo extra o recursos inusuales.
Cuando la canalización tiene que pausar: hazards y stalls
Los programas reales no son perfectamente suaves. A veces una instrucción depende del resultado de la anterior (no puedes usar un valor antes de que esté calculado). Otras veces, la CPU debe esperar datos de memoria, o aún no sabe qué camino tomará un branch.
Estas situaciones causan stalls —pausas breves donde parte de la canalización está inactiva. La intuición es simple: los stalls ocurren cuando la siguiente etapa no puede hacer trabajo útil porque algo que necesita no ha llegado.
El compilador como controlador de tráfico
Aquí se ve claramente el codiseño. Si el hardware es predecible, el compilador puede ayudar reordenando instrucciones (sin cambiar el significado del programa) para llenar “huecos”. Por ejemplo, mientras se espera que se produzca un valor, el compilador podría programar una instrucción independiente que no dependa de ese valor.
La recompensa es una responsabilidad compartida: la CPU se mantiene más simple y rápida en el caso común, mientras el compilador hace más planificación. Juntos reducen stalls y aumentan el rendimiento—mejorando el rendimiento real sin necesitar una ISA más compleja.
Cachés y la pared de memoria: donde el codiseño da frutos
Una CPU puede ejecutar operaciones simples en pocas ciclos, pero traer datos desde la memoria principal (DRAM) puede llevar cientos de ciclos. Esa brecha existe porque la DRAM está físicamente más lejos, optimizada para capacidad y coste, y limitada por latencia (cuánto tarda una petición) y ancho de banda (cuántos bytes por segundo se pueden mover).
A medida que las CPU se hicieron más rápidas, la memoria no siguió al mismo ritmo —esa desproporción es a menudo llamada la pared de memoria.
Cachés y localidad
Las cachés son memorias pequeñas y rápidas colocadas cerca de la CPU para evitar pagar la penalización de DRAM en cada acceso. Funcionan porque los programas reales muestran localidad:
- Localidad temporal: si usaste un valor o instrucción recientemente, es probable que lo vuelvas a usar pronto.
- Localidad espacial: si accediste una dirección, es probable que accedas direcciones cercanas a continuación.
Los chips modernos apilan cachés (L1, L2, L3), intentando mantener el “conjunto de trabajo” de código y datos cerca del núcleo.
Dónde la ISA y los compiladores influyen en el comportamiento de caché
Aquí es donde el codiseño hardware–software paga dividendos. La ISA y el compilador juntos moldean cuánta presión generan en la caché los programas.
- Tamaño del código importa. Binaries más grandes y secuencias de instrucciones pesadas pueden desbordar la caché de instrucciones y causar stalls. Elecciones de ISA que mejoran la densidad de código (por ejemplo, instrucciones comprimidas opcionales) pueden aumentar las tasas de acierto en la caché de instrucciones.
- Patrones de acceso importan. El diseño load/store al estilo RISC hace los accesos a memoria explícitos. Los compiladores pueden programar cargas antes, mantener valores calientes en registros y reducir tráfico de memoria innecesario.
- Ordenación y bloqueado. Optimizations del compilador como loop tiling (blocking), reordenación de estructuras de datos y hints de prefetch buscan convertir “viajes aleatorios a DRAM” en aciertos previsibles en caché.
La pared de memoria en el rendimiento real
En términos cotidianos, la pared de memoria explica por qué una CPU con alta frecuencia puede seguir sintiéndose lenta: abrir una app grande, ejecutar una consulta de base de datos, desplazarse por un feed o procesar un gran conjunto de datos a menudo se bloquea por fallos de caché y ancho de banda de memoria —no por la velocidad aritmética bruta.
Eficiencia: rendimiento por vatio, no solo velocidad bruta
Acelera los ciclos de iteración
Acorta el ciclo construir-medir con iteraciones más rápidas y mayor capacidad en Koder.ai.
Durante mucho tiempo, las discusiones sobre CPU parecían una carrera: el chip que terminara una tarea más rápido “ganaba”. Pero las computadoras reales viven dentro de límites físicos —capacidad de batería, calor, ruido del ventilador y facturas de electricidad.
Por eso rendimiento por vatio se volvió una métrica central: cuánta obra útil obtienes por la energía que gastas.
Qué significa realmente “rendimiento por vatio”
Piensa en eficiencia, no en fuerza máxima. Dos procesadores podrían sentirse igual de rápidos en uso diario, pero uno podría hacerlo consumiendo menos energía, manteniéndose más fresco y durando más con la misma batería.
En portátiles y móviles, esto impacta directamente la autonomía y la comodidad. En centros de datos, afecta el coste para alimentar y enfriar miles de máquinas, además de cuánta densidad de servidores puedes meter sin sobrecalentamiento.
Por qué los núcleos más simples suelen gastar menos energía
El pensamiento RISC impulsó el diseño de CPU hacia hacer menos en hardware y hacerlo de forma más predecible. Un núcleo más simple puede reducir el consumo energético de varias maneras:
- Lógica de control menos complicada significa menos “partes móviles” internas que cambian estado cada ciclo.
- Ejecución más predecible facilita mantener la canalización ocupada sin costosas recuperaciones.
- Diseños amigables para compiladores permiten al software programar el trabajo eficientemente, evitando que el hardware haga conjeturas caras.
No se trata de que “lo simple siempre sea mejor”. Se trata de que la complejidad tiene un coste energético, y una ISA y microarquitectura bien escogidas pueden sacrificar algo de ingenio por mucha eficiencia.
Convergencia móvil y servidores
Los teléfonos priorizan batería y calor; los servidores priorizan suministro de energía y refrigeración. Diferentes entornos, misma lección: el chip más rápido no siempre es la mejor computadora. Los ganadores suelen ser diseños que ofrecen rendimiento sostenido manteniendo el consumo bajo control.
Lo que RISC acertó — y lo que fue más complicado
RISC a menudo se resume como “las instrucciones más simples ganan”, pero la lección más duradera es más sutil: la ISA importa, pero muchas ganancias reales vinieron de cómo se construyeron los chips, no solo de cómo se veía la ISA sobre el papel.
El debate de “la ISA importa”
Los primeros argumentos RISC implicaban que una ISA más limpia y pequeña haría automáticamente las máquinas más rápidas. En la práctica, las mayores mejoras de velocidad vinieron con frecuencia de elecciones de implementación que RISC facilitó: decodificación más simple, canalizaciones más profundas, relojes más altos y compiladores que podían programar el trabajo de forma predecible.
Por eso dos CPUs con ISAs distintas pueden quedar sorprendentemente parecidas en rendimiento si difieren en microarquitectura, tamaños de caché, predicción de saltos y proceso de fabricación. La ISA marca las reglas; la microarquitectura juega la partida.
Medir vence a las listas de características
Un cambio clave de la era Patterson fue diseñar a partir de datos, no de suposiciones. En lugar de añadir instrucciones porque “parecían” útiles, los equipos midieron lo que los programas realmente hacían y optimizaron el caso común.
Esa mentalidad frecuentemente superó el diseño guiado por características, donde la complejidad crece más rápido que los beneficios. También aclara las compensaciones: una instrucción que ahorra unas pocas líneas de código puede costar ciclos extra, energía o área de chip —y esos costes se notan en todas partes.
No es una historia de ganador absoluto
El pensamiento RISC no solo moldeó “chips RISC”. Con el tiempo, muchas CPU CISC adoptaron técnicas internas tipo RISC (por ejemplo, descomponer instrucciones complejas en operaciones internas más simples) manteniendo su compatibilidad de ISA.
Así que el resultado no fue “RISC venció a CISC”. Fue una evolución hacia diseños que valoran la medición, la predictibilidad y la coordinación ajustada hardware–software —independientemente del logo de la ISA.
De MIPS a RISC‑V: un hilo continuo
RISC no se quedó en el laboratorio. Una de las líneas más claras desde la investigación temprana hasta la práctica moderna va de MIPS a RISC‑V —dos ISAs que convirtieron la simplicidad y la claridad en una ventaja, no en una limitación.
MIPS: la ISA limpia que la gente podía construir (y aprender)
MIPS se recuerda a menudo como una ISA didáctica, y con razón: sus reglas son fáciles de explicar, los formatos de instrucción son consistentes y el modelo básico load/store no se interpone en el camino del compilador.
Esa limpieza no fue solo académica. Procesadores MIPS se comercializaron en productos reales durante años (desde estaciones de trabajo hasta sistemas embebidos), en parte porque una ISA directa facilita construir canalizaciones rápidas, compiladores previsibles y cadenas de herramientas eficientes. Cuando el comportamiento del hardware es regular, el software puede planificar alrededor de ello.
RISC‑V: abierto, práctico y amigo del codiseño
RISC‑V renovó el interés en el pensamiento RISC dando un paso clave que MIPS no dio: es una ISA abierta. Eso cambia los incentivos. Universidades, startups y grandes empresas pueden experimentar, fabricar silicio y compartir herramientas sin negociar acceso a la ISA.
Para el codiseño, esa apertura importa porque el lado del “software” (compiladores, SOs, runtimes) puede evolucionar públicamente junto al lado “hardware”, con menos barreras artificiales.
Extensiones modulares: añadir lo que necesitas—solo cuando lo necesitas
Otra razón por la que RISC‑V encaja tan bien con el codiseño es su enfoque modular. Empiezas con una ISA base pequeña y añades extensiones para necesidades específicas —como cómputo vectorial, restricciones embebidas o características de seguridad.
Eso fomenta un trade‑off más sano: en lugar de meter todas las posibles características en un diseño monolítico, los equipos pueden alinear las funciones de hardware con el software que realmente ejecutan.
Si quieres una introducción más profunda, mira /blog/what-is-risc-v.
Cómo se manifiesta el codiseño en la computación moderna
Prototipa el ciclo de codiseño
Convierte ideas de codiseño en un prototipo funcional construyendo tu app por chat en Koder.ai.
El codiseño no es una nota histórica del periodo RISC —es la forma en que la computación moderna sigue mejorando en velocidad y eficiencia. La idea clave sigue siendo al estilo Patterson: no “ganas” solo con hardware ni solo con software. Ganas cuando ambos encajan con sus fortalezas y limitaciones.
Pensamiento RISC en los dispositivos que usas cada día
Los smartphones y muchos dispositivos embebidos se apoyan fuertemente en principios RISC (a menudo basados en ARM): instrucciones más simples, ejecución predecible y fuerte énfasis en el consumo energético.
Esa predictibilidad ayuda a los compiladores a generar código eficiente y permite a los diseñadores crear núcleos que consumen poco al desplazarte por la pantalla, pero que pueden estallar en rendimiento para cámaras o juegos.
Portátiles y servidores persiguen metas similares —especialmente rendimiento por vatio. Incluso cuando la ISA no es tradicionalmente “RISC”, muchas elecciones internas buscan eficiencia tipo RISC: canalizaciones profundas, ejecución amplia y gestión de energía agresiva afinada para el comportamiento real del software.
Aceleradores: el codiseño en acción
GPUs, aceleradores de IA (TPUs/NPUs) y motores multimedia son una forma práctica de codiseño: en lugar de forzar todo el trabajo por una CPU de propósito general, la plataforma ofrece hardware que coincide con patrones de cómputo comunes.
Lo que convierte esto en codiseño (no solo “hardware extra”) es la pila de software que lo rodea:
- Las GPUs obtienen su velocidad de modelos de programación como CUDA y APIs como Vulkan/Metal.
- Los aceleradores de IA dependen de compiladores y optimizadores de grafos que transforman un modelo en las operaciones preferidas por el chip.
- Los codificadores/decodificadores de vídeo rinden porque los SO, navegadores y apps están escritos para usarlos.
Si el software no apunta al acelerador, la velocidad teórica permanece teórica.
Las pilas de software son parte del rendimiento
Dos plataformas con especificaciones similares pueden sentirse muy distintas porque el “producto real” incluye compiladores, librerías y frameworks. Una librería matemática bien optimizada (BLAS), un buen JIT o un compilador más inteligente pueden producir grandes mejoras sin cambiar el chip.
Por eso el diseño de CPUs moderno suele guiarse por benchmarks: los equipos de hardware analizan lo que compilan y ejecutan las cargas, y ajustan características (cachés, predicción de saltos, instrucciones vectoriales, prefetching) para acelerar el caso común.
Lista rápida: qué vigilar
Cuando evalúes una plataforma (teléfono, portátil, servidor o placa embebida), busca señales de codiseño:
- Coincidencia de carga: ¿tus apps son CPU‑bound, GPU‑bound, memory‑bound o aptas para aceleradores?
- Disponibilidad de aceleradores: ¿hay NPU/GPU/motor multimedia —y tus herramientas realmente los usan?
- Madurez del compilador/cadena de herramientas: ¿hay builds optimizados, buenas herramientas de profiling y soporte activo?
- Ecosistema de librerías: ¿las librerías núcleo (math, visión, cripto) están afinadas para ese hardware?
- Comportamiento energético: ¿obtienes rendimiento sostenido dentro de tus límites térmicos/eléctricos?
El progreso en la computación moderna trata menos de una única “CPU más rápida” y más de todo un sistema hardware‑más‑software que se ha formado —medido y luego diseñado— alrededor de cargas de trabajo reales.
Conclusiones clave y siguientes pasos prácticos
El pensamiento RISC y el mensaje más amplio de Patterson pueden resumirse en unas pocas lecciones duraderas: simplifica lo que debe ser rápido, mide lo que realmente ocurre y trata hardware y software como un solo sistema —porque los usuarios experimentan el todo, no los componentes.
Lecciones que vale la pena conservar
Primero, la simplicidad es una estrategia, no una estética. Una ISA limpia y una ejecución predecible facilitan que los compiladores generen buen código y que las CPU lo ejecuten eficientemente.
Segundo, medir vence a la intuición. Haz benchmarks con cargas representativas, recoge datos de perfilado y deja que los cuellos de botella reales guíen las decisiones de diseño —ya sea afinando optimizaciones del compilador, escogiendo una SKU de CPU o rediseñando un camino crítico.
Tercero, el codiseño apila las mejoras. Código amigable para pipeline, estructuras de datos conscientes de caché y objetivos realistas de rendimiento por vatio a menudo entregan más velocidad práctica que perseguir rendimiento teórico pico.
Pasos prácticos siguientes para equipos de producto
Si estás seleccionando una plataforma (sistemas basados en x86, ARM o RISC‑V), evalúala como lo harán tus usuarios:
- Haz benchmarks de escenarios de extremo a extremo (tiempo de arranque, rendimiento en régimen estable, latencias tail), no solo microbenchmarks.
- Mide métricas de eficiencia (vatios, térmicas, impacto en batería) junto al rendimiento.
- Itera: perfila → cambia una cosa → vuelve a medir. Pasos pequeños y validados se acumulan.
Si parte de tu trabajo es convertir esas mediciones en software desplegado, puede ayudar acortar el bucle construir–medir. Por ejemplo, equipos usan Koder.ai para prototipar y evolucionar aplicaciones reales mediante un flujo de trabajo guiado por chat (web, backend y móvil), y vuelven a ejecutar los mismos benchmarks de extremo a extremo tras cada cambio. Funciones como modo planificación, snapshots y rollback soportan la disciplina de “medir y luego diseñar” que promovió Patterson —aplicada al desarrollo de producto moderno.
Para una introducción más profunda sobre eficiencia, ve a /blog/performance-per-watt-basics. Si comparas entornos y necesitas una forma sencilla de estimar trade‑offs coste/rendimiento, /pricing puede ayudar.
La lección perdurable: las ideas —simplicidad, medición y codiseño— siguen dando réditos, incluso cuando las implementaciones evolucionan desde pipelines de la era MIPS a núcleos heterogéneos modernos y nuevas ISAs como RISC‑V.