21 sept 2025·8 min
Pensamiento CAP de Eric Brewer: por qué los sistemas distribuidos hacen concesiones
Aprende el teorema CAP de Eric Brewer como un modelo mental práctico: cómo consistencia, disponibilidad y particiones influyen en las decisiones de sistemas distribuidos.
Por qué CAP se convirtió en el modelo mental de referencia
Cuando almacenas los mismos datos en más de una máquina, ganas velocidad y tolerancia a fallos—pero también heredas un problema nuevo: desacuerdo. Dos servidores pueden recibir actualizaciones distintas, los mensajes pueden llegar tarde o no llegar, y los usuarios pueden leer respuestas diferentes según qué réplica atiendan. CAP se hizo popular porque da a los ingenieros una forma clara de hablar sobre esa realidad desordenada sin ambigüedades.
Eric Brewer, científico informático y cofundador de Inktomi, presentó la idea central en 2000 como una afirmación práctica sobre sistemas replicados bajo fallo. Se difundió rápido porque encajaba con lo que los equipos ya veían en producción: los sistemas distribuidos no solo fallan apagándose; fallan dividiéndose.
CAP es una lente para fallos, no una lista de características
CAP es más útil cuando las cosas van mal—especialmente cuando la red no se comporta. En un día sano, muchos sistemas pueden parecer suficientemente consistentes y disponibles. La prueba de fuego es cuando las máquinas no pueden comunicarse de forma fiable y debes decidir qué hacer con lecturas y escrituras mientras el sistema está dividido.
Esa perspectiva es la razón por la que CAP se convirtió en modelo de referencia: no discute sobre mejores prácticas; obliga a una pregunta concreta—¿qué sacrificaremos durante una partición?
Qué sabrás decidir al final
Al terminar este artículo deberías poder:
- Reconocer cuándo estás ante un verdadero escenario CAP (replicación + posibilidad de cortes de comunicación).
- Elegir, de forma intencionada, si tu sistema debe favorecer consistencia (todos ven la misma verdad) o disponibilidad (el sistema sigue respondiendo) cuando las réplicas no pueden ponerse de acuerdo.
- Conectar esa elección con el impacto en el producto: qué experimentan los usuarios, qué errores muestras y qué arreglos necesitarás cuando la partición sane.
CAP perdura porque convierte el vago “lo distribuido es difícil” en una decisión que puedes tomar—y defender.
El planteamiento: replicación y el problema del desacuerdo
Un sistema distribuido es, en términos simples, muchos ordenadores intentando actuar como uno solo. Puedes tener varios servidores en distintos racks, regiones o zonas de nube, pero para el usuario es “la app” o “la base de datos”.
Por qué replicamos datos
Para que ese sistema compartido funcione a escala real, normalmente replicamos: mantenemos varias copias de los mismos datos en máquinas distintas.
La replicación es popular por tres razones prácticas:
- Escala: más máquinas pueden atender más tráfico.
- Rendimiento: los usuarios pueden servirse desde una copia cercana, reduciendo la latencia.
- Fiabilidad: si una máquina muere, otra copia puede mantener el servicio en pie.
Hasta aquí, la replicación parece un triunfo claro. El inconveniente es que la replicación crea una nueva tarea: mantener todas las copias de acuerdo.
La tensión central: las copias pueden discrepar
Si cada réplica pudiera siempre hablar con las demás instantáneamente, podrían coordinar actualizaciones y mantenerse alineadas. Pero las redes reales no son perfectas. Los mensajes pueden retrasarse, perderse o enrutarse sorteando fallos.
Cuando la comunicación está sana, las réplicas suelen intercambiar actualizaciones y converger en el mismo estado. Pero cuando la comunicación se rompe (incluso temporalmente), puedes acabar con dos versiones válidas de “la verdad”.
Por ejemplo, un usuario cambia su dirección de envío. La réplica A recibe la actualización, la réplica B no. Ahora el sistema tiene que responder a una pregunta aparentemente simple: ¿cuál es la dirección actual?
Operación normal vs operación bajo fallo
Esta es la diferencia entre:
- Operación normal: las réplicas pueden coordinarse; el desacuerdo es mayormente una cuestión de tiempo.
- Operación en fallo: algunas réplicas no pueden comunicarse; el desacuerdo se vuelve inevitable.
El pensamiento CAP empieza exactamente aquí: una vez que existe replicación, el desacuerdo bajo fallo de comunicación no es un caso borde—es el problema central de diseño.
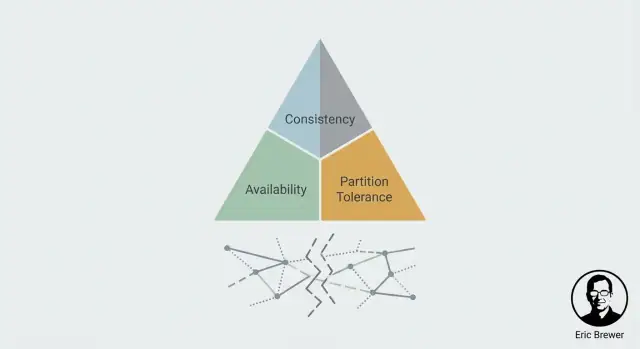
CAP en lenguaje llano: C, A y P
CAP es un modelo mental de lo que los usuarios realmente sienten cuando un sistema está distribuido en varias máquinas (a menudo en varias ubicaciones). No describe “buenos” o “malos” sistemas—solo la tensión que debes gestionar.
Consistencia (C): ¿veo la escritura más reciente?
La consistencia trata sobre el acuerdo. Si actualizas algo, ¿reflejará la siguiente lectura (desde cualquier lugar) esa actualización?
Desde el punto de vista del usuario, es la diferencia entre “acabo de cambiarlo y todos ven el nuevo valor” frente a “algunas personas todavía ven el valor antiguo por un rato”.
Disponibilidad (A): ¿obtengo una respuesta en absoluto?
Disponibilidad significa que el sistema responde a peticiones—lecturas y escrituras—con un resultado de éxito. No “el más rápido posible”, sino “no te rechaza”.
Durante problemas (un servidor caído, un fallo de red), un sistema disponible sigue aceptando peticiones, incluso si debe responder con datos algo desactualizados.
Tolerancia a particiones (P): ¿qué pasa cuando los nodos no pueden hablar?
Una partición es cuando la red se divide: las máquinas funcionan, pero los mensajes entre algunas de ellas no pueden pasar (o llegan demasiado tarde para ser útiles). En sistemas distribuidos, no puedes tratar esto como imposible—debes definir el comportamiento cuando ocurra.
Una historia simple: dos tiendas, un inventario
Imagina dos tiendas que venden el mismo producto y comparten “1 unidad de inventario”. Un cliente compra el último artículo en la Tienda A, así que A escribe inventario = 0. Al mismo tiempo, una partición de red impide que la Tienda B lo sepa.
Si B permanece disponible, puede vender un artículo que ya no tiene (aceptando la venta mientras está particionada). Si B aplica consistencia, puede rechazar la venta hasta confirmar el inventario más reciente (negando servicio durante la partición).
Qué son realmente las particiones (y por qué no puedes ignorarlas)
Una “partición” no es solo “Internet está caído”. Es cualquier situación donde partes de tu sistema no pueden comunicarse de forma fiable—aunque cada parte siga ejecutándose correctamente.
En un sistema replicado, los nodos intercambian constantemente mensajes: escrituras, acuses, latidos, elecciones de líder, lecturas. Una partición es lo que ocurre cuando esos mensajes dejan de llegar (o llegan demasiado tarde), creando desacuerdo sobre la realidad: “¿Se aplicó esa escritura?” “¿Quién es el líder?” “¿Está vivo el nodo B?”
Las particiones son fallos de comunicación
La comunicación puede fallar de formas desordenadas y parciales:
- Pérdida de paquetes que dispara reintentos y timeouts
- Problemas de enrutamiento donde el tráfico toma un desvío largo o desaparece
- Enlaces saturados (o NICs saturadas) causando grandes retrasos
- Cortafuegos o grupos de seguridad mal configurados que bloquean solo ciertos puertos o direcciones
- Problemas de DNS o descubrimiento de servicios que impiden que los nodos se encuentren
El punto importante: las particiones suelen ser degradación, no una caída limpia. Para la aplicación, “lo bastante lento” puede ser indistinguible de “caído”.
Por qué las particiones son inevitables a escala
Al añadir más máquinas, más redes, más regiones y más piezas móviles, hay simplemente más oportunidades de que la comunicación se rompa temporalmente. Incluso si los componentes individuales son fiables, el sistema global experimenta fallos porque tiene más dependencias y más coordinación entre nodos.
No necesitas asumir una tasa de fallos exacta para aceptar la realidad: si tu sistema funciona lo bastante tiempo y abarca suficiente infraestructura, ocurrirán particiones.
Qué significa en la práctica “tolerar particiones”
Tolerancia a particiones significa que tu sistema está diseñado para seguir operando durante una división—incluso cuando los nodos no pueden ponerse de acuerdo o confirmar lo que el otro lado ha visto. Eso fuerza una elección: seguir atendiendo peticiones (arriesgando inconsistencia) o detener/rechazar algunas peticiones (preservando consistencia).
El momento clave: elegir consistencia o disponibilidad durante una partición
Una vez que tienes replicación, una partición es simplemente una ruptura de comunicación: dos partes de tu sistema no pueden hablarse con fiabilidad durante un tiempo. Las réplicas siguen en marcha, los usuarios siguen haciendo clic, y tu servicio sigue recibiendo peticiones—pero las réplicas no pueden acordar la verdad más reciente.
Esa es la tensión CAP en una frase: durante una partición, debes elegir priorizar Consistencia (C) o Disponibilidad (A). No obtienes ambas al mismo tiempo.
Si eliges Consistencia (C)
Estás diciendo: “prefiero estar correcto a ser rápido”. Cuando el sistema no puede confirmar que una petición mantendrá todas las réplicas en sincronía, debe fallar o esperar.
Efecto práctico: algunos usuarios verán errores, timeouts o mensajes de “inténtalo de nuevo”—especialmente para operaciones que cambian datos. Esto es común cuando prefieres rechazar un pago antes que cobrar dos veces, o bloquear una reserva de asiento antes que vender de más.
Si eliges Disponibilidad (A)
Estás diciendo: “prefiero responder a bloquearme”. Cada lado de la partición seguirá aceptando peticiones, incluso si no puede coordinarse.
Efecto práctico: los usuarios obtienen respuestas exitosas, pero los datos que leen pueden estar obsoletos, y las actualizaciones concurrentes pueden conflictar. Luego dependes de la reconciliación posterior (reglas de merge, last-write-wins, revisión manual, etc.).
La elección puede variar por operación
Esto no es siempre un ajuste global. Muchos productos mezclan estrategias:
- Lecturas vs. escrituras: mantener lecturas disponibles, pero hacer las escrituras más estrictas.
- Acciones críticas vs. no críticas: hacer consistencia para dinero, identidad e inventario; permitir disponibilidad para feeds, analítica, “me gusta” o perfiles en caché.
El momento clave es decidir—por operación—qué es peor: bloquear a un usuario ahora o arreglar una verdad en conflicto después.
Conceptos erróneos comunes: más allá del lema “elige dos”
Planifica la consistencia por endpoint
Bosqueja endpoints, tipos de datos y necesidades de consistencia con el Modo de Planificación antes de codificar.
El lema “elige dos” es memorable, pero a menudo induce a error al hacer creer que CAP es un menú de tres características donde solo puedes quedarte con dos para siempre. CAP trata de lo que ocurre cuando la red deja de cooperar: durante una partición (o cualquier cosa que parezca una), un sistema distribuido debe elegir entre devolver respuestas consistentes y mantenerse disponible para cada petición.
Falso 1: “Simplemente elegiré C y A y evitaré particiones”
En sistemas reales distribuidos, las particiones no son una opción que puedas desactivar. Si tu sistema abarca máquinas, racks, zonas o regiones, los mensajes pueden retrasarse, perderse, reordenarse o enrutarse de forma extraña. Eso es una partición desde la perspectiva del software: los nodos no pueden acordar qué está ocurriendo.
Incluso si la red física está bien, fallos en otras partes crean el mismo efecto—nodos sobrecargados, pausas de GC, vecinos ruidosos, problemas de DNS, balanceadores inestables. El resultado es el mismo: algunas partes del sistema no pueden hablar con otras lo suficiente para coordinarse.
Falso 2: “Las particiones son casos raros”
Las aplicaciones no experimentan la “partición” como un evento binario y ordenado. Experimentan picos de latencia y timeouts. Si una petición agota el tiempo tras 200 ms, no importa si el paquete llegó en 201 ms o nunca llegó: la app debe decidir qué hacer a continuación. Desde la app, la comunicación lenta suele ser indistinguible de la comunicación rota.
Falso 3: “Los sistemas son o CP o AP”
Muchos sistemas reales son mayormente consistentes o mayormente disponibles, según configuración y condiciones de operación. Timeouts, políticas de reintento, tamaños de quórum y opciones de “leer tus propias escrituras” pueden desplazar el comportamiento.
En condiciones normales, una base de datos puede parecer fuertemente consistente; bajo estrés o fallos cross-región, puede empezar a fallar peticiones (favoreciendo consistencia) o devolver datos antiguos (favoreciendo disponibilidad).
CAP trata menos de etiquetar productos y más de entender el intercambio que haces cuando aparece el desacuerdo—especialmente cuando ese desacuerdo es causado por la simple lentitud.
Opciones de consistencia que realmente puedes elegir
Las discusiones CAP suelen hacer que la consistencia parezca binaria: o “perfecta” o “vale todo”. Los sistemas reales ofrecen un menú de garantías, cada una con una experiencia de usuario distinta cuando las réplicas discrepan o se rompe un enlace de red.
Consistencia fuerte (y su coste durante fallos)
Consistencia fuerte (a menudo “linearizable”) significa que una vez que una escritura es reconocida, toda lectura posterior—no importa qué réplica—debe devolver esa escritura.
Su coste: durante una partición o cuando una minoría de réplicas no está accesible, el sistema puede retrasar o rechazar lecturas/escrituras para evitar mostrar estados en conflicto. Los usuarios notan esto como timeouts, “inténtalo más tarde” o comportamiento temporal de solo lectura.
Consistencia eventual (y lo que los usuarios pueden notar)
Consistencia eventual promete que si no ocurren nuevas actualizaciones, todas las réplicas convergerán. No promete que dos usuarios que leen ahora vean lo mismo.
Lo que los usuarios pueden notar: una foto de perfil recién actualizada que “revierta”, contadores que van retrasados, o un mensaje enviado que no aparece en otro dispositivo por un tiempo corto.
Garantías intermedias útiles
A menudo puedes obtener mejor experiencia sin exigir consistencia fuerte total:
- Leer tus propias escrituras: después de actualizar algo, no leerás una versión anterior de tus datos.
- Lecturas monotónicas: una vez que has visto la versión N, no volverás a ver la versión N-1.
- Consistencia causal: si el evento B depende de A (responder después de leer un mensaje), todos ven A antes que B.
Estas garantías encajan bien con cómo la gente piensa (“no me muestres mis cambios desapareciendo”) y pueden ser más fáciles de mantener durante fallos parciales.
Elegir nivel de consistencia según expectativas
Empieza con promesas al usuario, no con jerga:
- Si lecturas incorrectas crean daño irreversible (movimientos de dinero, reservas de inventario, cambios de permisos), inclínate hacia consistencia más fuerte y acepta indisponibilidad temporal.
- Si la función tolera discrepancia breve (likes, contadores, ranking de feeds), la consistencia eventual o causal suele encajar.
- Si el dolor central es la confusión personal (“lo guardé—¿por qué no lo veo?”), prioriza leer tus propias escrituras y lecturas monotónicas.
La consistencia es una decisión de producto: define qué significa “estar mal” para un usuario y elige la garantía más débil que impida ese mal.
La disponibilidad como decisión de producto, no solo un número de uptime
Empieza pequeño, escala después
Comienza en el plan gratuito y súbete solo cuando tu prototipo necesite más capacidad.
La disponibilidad en CAP no es una métrica para alardear (“cinco nueves”)—es una promesa que haces a los usuarios sobre lo que ocurre cuando el sistema no puede estar seguro.
Éxito rápido vs. éxito exacto
Cuando las réplicas no pueden ponerse de acuerdo, a menudo eliges entre:
- Éxito rápido: devolver algo pronto (incluso si puede estar desactualizado).
- Éxito exacto: devolver solo cuando puedas demostrar que la respuesta está actualizada.
Los usuarios sienten esto como “la app funciona” frente a “la app es correcta”. Ninguno es universalmente mejor; la elección correcta depende de lo que signifique “estar equivocado” en tu producto. Un feed social ligeramente desactualizado es molesto. Un saldo bancario desactualizado puede ser daño.
“Fallar cerrando” vs. “fallar abriendo”
Dos comportamientos comunes durante la incertidumbre:
- Fallar cerrando: rechazar la petición (errores, timeouts, modo solo lectura). Proteges la corrección, pero los usuarios pueden quedar bloqueados.
- Fallar abriendo: servir una respuesta de esfuerzo razonable (datos en caché, réplica local, escritura en cola). Proteges el flujo, pero puedes mostrar resultados inconsistentes.
Esto no es una elección puramente técnica; es una política. El producto debe definir qué es aceptable mostrar y qué nunca debe ser conjeturado.
La disponibilidad parcial sigue siendo disponibilidad
La disponibilidad raramente es todo o nada. Durante una división, puedes ver disponibilidad parcial: algunas regiones, redes o grupos de usuarios tienen éxito mientras otros fallan. Esto puede ser un diseño deliberado (seguir atendiendo donde la réplica local está sana) o accidental (desequilibrios de enrutamiento, alcance desigual de quórum).
Modo degradado: mantener lo esencial, limitar el riesgo
Un punto medio práctico es el modo degradado: seguir atendiendo acciones seguras mientras limitas las riesgosas. Por ejemplo, permitir navegación y búsqueda, pero desactivar temporalmente “transferir fondos”, “cambiar contraseña” u otras operaciones donde la corrección y unicidad son críticas.
Ejemplos concretos: casar elecciones CAP con casos de uso
CAP resulta abstracto hasta que lo mapeas a lo que tus usuarios viven durante una partición: ¿prefieres que el sistema siga respondiendo o que pare para evitar devolver/aceptar datos en conflicto?
Inventario y pedidos: riesgo de sobreventa vs. caídas en el checkout
Imagina dos centros de datos que aceptan pedidos mientras no pueden hablar entre sí.
Si mantienes el flujo de checkout disponible, cada lado puede vender el “último artículo” y sobrevenderás. Eso puede ser aceptable para bienes de poco valor (haciendo backorder o disculpándote), pero doloroso para drops de inventario limitados.
Si eliges consistencia primero, podrías bloquear pedidos nuevos cuando no puedas confirmar stock globalmente. Los usuarios verán “inténtalo más tarde”, pero evitarás vender algo que no puedes cumplir.
Pagos y saldos: patrones orientados a la corrección (y por qué)
El dinero es el dominio clásico donde equivocarse es caro. Si dos réplicas aceptan retiradas independientemente durante una partición, una cuenta puede quedar en negativo.
Los sistemas suelen preferir consistencia en escrituras críticas: rechazar o retrasar acciones si no pueden confirmar el saldo más reciente. Cambiarás algo de disponibilidad (fallos temporales en pagos) por corrección, auditabilidad y confianza.
Chat, feeds, analítica: disponible con datos ligeramente obsoletos está bien
En chat y feeds sociales, los usuarios toleran pequeñas inconsistencias: un mensaje llega unos segundos tarde, un contador de likes está desfasado, una métrica aparece más tarde.
Aquí, diseñar para disponibilidad suele ser buena elección de producto, siempre que dejes claro qué elementos son “eventualmente correctos” y puedas fusionar actualizaciones limpiamente.
El punto: tu compromiso es una decisión de negocio
La elección CAP correcta depende del coste de estar equivocado: reembolsos, exposición legal, pérdida de confianza del usuario u caos operacional. Decide dónde puedes aceptar estaleza temporal—y dónde debes fallar cerrado.
Patrones de diseño que implementan tu elección
Una vez que hayas decidido qué harás durante una partición, necesitas mecanismos que hagan real esa decisión. Estos patrones aparecen en bases de datos, sistemas de mensajería y APIs—aunque el producto nunca nombre “CAP”.
Quórums: acuerdo por mayoría
Un quórum es simplemente “la mayoría de las réplicas están de acuerdo”. Si tienes 5 copias, la mayoría es 3.
Al exigir que lecturas y/o escrituras contacten con una mayoría, reduces la probabilidad de devolver datos obsoletos o conflictivos. Por ejemplo, si una escritura debe ser reconocida por 3 réplicas, es más difícil que dos grupos aislados acepten verdades distintas.
El intercambio es velocidad y alcance: si no alcanzas una mayoría (por partición o fallos), el sistema puede rechazar la operación—eligiendo consistencia sobre disponibilidad.
Timeouts, reintentos y backoff moldean la disponibilidad percibida
Muchos problemas de “disponibilidad” no son fallos absolutos sino respuestas lentas. Poner un timeout corto puede hacer que el sistema se sienta ágil, pero también aumenta la probabilidad de tratar éxitos lentos como fallos.
Los reintentos pueden recuperarse de fallos transitorios, pero reintentos agresivos pueden sobrecargar un servicio ya estresado. El backoff (esperar un poco más entre reintentos) y el jitter (aleatoriedad) ayudan a que los reintentos no se conviertan en picos de tráfico.
La clave es alinear estos ajustes con tu promesa: “siempre responder” suele implicar más reintentos y fallback; “nunca mentir” suele implicar límites más estrictos y errores claros.
Manejo de conflictos cuando permites divergencia
Si eliges mantener disponibilidad durante particiones, las réplicas pueden aceptar actualizaciones distintas y debes reconciliar después. Enfoques comunes incluyen:
- Last-write-wins (LWW): elegir la actualización con la marca temporal más reciente. Sencillo, pero puede perder cambios válidos si los relojes no concuerdan.
- Vectores de versión (a alto nivel): adjuntar un pequeño “historial” que ayuda a detectar si las actualizaciones son concurrentes o una supera a la otra.
- Reglas de merge: definir cómo combinar cambios (p. ej., unión de artículos de carrito; contadores que suman; perfiles que prefieren campos no vacíos). Esto funciona mejor cuando se diseña en el modelo de datos.
Idempotencia: hacer seguros los reintentos
Los reintentos pueden crear duplicados: cobrar una tarjeta dos veces o enviar el mismo pedido repetido. La idempotencia lo evita.
Un patrón común es una clave de idempotencia (ID de petición) enviada con cada petición. El servidor almacena el primer resultado y devuelve el mismo resultado para repeticiones—así los reintentos mejoran disponibilidad sin corromper datos.
Cómo validar supuestos CAP en la vida real
Prototipa compensaciones CAP rápidamente
Convierte tus decisiones CAP en un prototipo funcional en Go y Postgres en una sola conversación.
La mayoría de equipos “eligen” una postura CAP en una pizarra—y luego descubren en producción que el sistema se comporta distinto bajo estrés. Validar significa crear intencionadamente las condiciones donde las compensaciones CAP se hacen visibles, y comprobar que tu sistema reacciona como diseñaste.
Probar particiones a propósito (de forma segura)
No necesitas un corte de cable real para aprender algo. Usa inyección de fallos controlada en staging (y con cuidado en producción) para simular particiones:
- Agujerea tráfico entre servicios o nodos específicos (descartar paquetes sin cerrar conexiones) para imitar una división silenciosa.
- Rompe enlaces bloqueando puertos o reglas de grupos de seguridad entre réplicas/regiones.
- Añade latencia extrema y pérdida de paquetes para que los timeouts y reintentos se comporten como en una partición.
- Aísla líderes forzando (p. ej., aislar el primario de un quórum) para ver si fallas hacia “consistente” o “disponible”.
El objetivo es responder preguntas concretas: ¿se rechazan o aceptan las escrituras? ¿las lecturas devuelven datos obsoletos? ¿se recupera el sistema automáticamente y cuánto tarda la reconciliación?
Si quieres validar estos comportamientos pronto (antes de invertir semanas en conectar servicios), puede ayudar montar un prototipo realista rápido. Por ejemplo, equipos que usan Koder.ai suelen empezar generando un servicio pequeño (comúnmente un backend Go con PostgreSQL y una UI React) y luego iteran en comportamientos como reintentos, claves de idempotencia y flujos de “modo degradado” en un entorno sandbox.
Señales de monitorización que revelan dolor CAP
Los chequeos tradicionales de uptime no detectarán “disponible pero equivocado”. Supervisa:
- Tasas de error por tipo de operación (lectura vs escritura vs actualización condicional).
- Indicadores de lecturas obsoletas (violaciones de read-your-writes, desajustes de versiones/ETag, métricas de retraso).
- Divergencia de réplicas (lag de replicación, cuentas de aplicados fallidos, tasas de conflicto).
- Timeouts/reintentos (a menudo la primera señal de una partición emergente).
Runbooks y comunicación al usuario
Los operadores necesitan acciones predefinidas cuando ocurre una partición: cuándo congelar escrituras, cuándo hacer failover, cuándo degradar funciones, y cómo validar la seguridad de la re-fusión.
También planifica el comportamiento visible al usuario. Si eliges consistencia, el mensaje podría ser “No podemos confirmar tu actualización ahora—por favor reintenta.” Si eliges disponibilidad, sé explícito: “Tu actualización puede tardar unos minutos en aparecer en todos los dispositivos.” Un wording claro reduce la carga de soporte y preserva la confianza.
Lista práctica CAP para decisiones diarias de sistema
Cuando tomes una decisión de sistema, CAP es más útil como una auditoría rápida de “¿qué se rompe durante una partición?”—no como un debate teórico. Usa esta checklist antes de elegir una característica de base de datos, estrategia de cache o modo de replicación.
1) Una checklist corta CAP
Pregúntate en este orden:
- ¿Qué debe ser correcto? (p. ej., “un saldo bancario nunca puede ser negativo”, “no podemos sobrevender inventario”, “los permisos deben ser exactos”)
- ¿Qué debe seguir funcionando? (p. ej., endpoint de checkout, login, catálogo en solo lectura)
- ¿Qué puede degradarse temporalmente? (p. ej., analítica, recomendaciones, avatares, “última vez visto”)
Si ocurre una partición, estás decidiendo qué de esto protegerás primero.
2) Decide por tipo de dato y por endpoint
Evita un ajuste global como “somos un sistema AP”. En su lugar decide por:
- Tipo de dato: dinero vs likes vs logs
- Endpoint: “realizar pedido” vs “ver pedido” vs “rastrear envío”
Ejemplo: durante una partición, puedes bloquear escrituras a payments (favorecer consistencia) pero mantener lecturas de product_catalog disponibles con datos en caché.
3) Define “inconsistencia aceptable” en términos concretos
Anota qué toleras, con ejemplos:
- Límite temporal: “los contadores pueden ir con 5–10 minutos de retraso”
- Magnitud: “el inventario puede desviarse ±1 en artículos de baja demanda”
- A nivel de campo: “ETA de envío puede estar obsoleta; el total del pedido no”
- Texto visible al usuario: “muestra ‘pendiente’ en lugar de un estado definitivo”
Si no puedes describir la inconsistencia en ejemplos claros, te costará probarla y explicar incidentes.
4) Conclusiones + qué leer después
- Las particiones convierten garantías “agradables de tener” en elecciones obligadas.
- Haz explícitas esas elecciones por endpoint y documenta la inconsistencia aceptable.
Temas siguientes que encajan bien con esta checklist: consenso (/blog/consensus-vs-cap), modelos de consistencia (/blog/consistency-models-explained), y SLOs/presupuestos de error (/blog/sre-slos-error-budgets).
Preguntas frecuentes
¿Qué problema ayuda a razonar CAP a los ingenieros?
CAP es un modelo mental para sistemas replicados bajo fallos de comunicación. Es más útil cuando la red es lenta, pierde paquetes o se divide, porque es entonces cuando los réplicas no pueden acordar de forma fiable y te ves obligado a elegir entre:
- Consistencia: todos ven el mismo valor más reciente
- Disponibilidad: el sistema sigue devolviendo respuestas exitosas
Te ayuda a convertir el típico “lo distribuido es difícil” en una decisión concreta de producto e ingeniería.
¿Cuándo estoy realmente en una situación CAP?
Un verdadero escenario CAP requiere ambas cosas:
- Replicación (más de un nodo puede servir/aceptar operaciones sobre los mismos datos)
- Una probabilidad realista de fallo de comunicación (particiones, timeouts, latencias largas)
Si tu sistema es de un único nodo, o no replicas estado, las compensaciones CAP no son el problema central.
¿Qué cuenta como una partición de red en sistemas reales?
Una partición es cualquier situación en la que partes de tu sistema no pueden comunicarse de forma fiable o dentro de los límites de tiempo requeridos—incluso si todas las máquinas siguen ejecutándose.
En la práctica, “partición” suele manifestarse como:
- picos de latencia que disparan timeouts
- paquetes perdidos o en un agujero negro
- cortafuegos o rutas mal configuradas
- nodos sobrecargados que dejan de responder a tiempo
Desde la perspectiva de la aplicación, “demasiado lento” puede ser lo mismo que “caído”.
¿Cuál es la diferencia entre consistencia y disponibilidad en términos de usuario?
Consistencia (C) significa que las lecturas reflejan la última escritura reconocida desde cualquier lugar. Los usuarios lo experimentan como “lo cambié y todo el mundo lo ve”.
Disponibilidad (A) significa que cada petición recibe una respuesta exitosa (no necesariamente la más reciente). Los usuarios lo experimentan como “la app sigue funcionando”, quizá con datos obsoletos.
Durante una partición, normalmente no puedes garantizar ambas cosas simultáneamente para todas las operaciones.
¿Por qué no puedo simplemente elegir consistencia y disponibilidad e ignorar las particiones?
Porque las particiones no son opcionales en sistemas distribuidos que abarcan máquinas, racks, zonas o regiones. Si replicas, debes definir comportamiento para cuando los nodos no puedan coordinarse.
“Tolerar particiones” suele significar: cuando la comunicación falla, el sistema aún tiene una forma definida de operar—o bien rechazando/pausando algunas acciones (favoreciendo consistencia) o bien sirviendo resultados aproximados (favoreciendo disponibilidad).
¿Cómo se ve una elección orientada a la consistencia (CP) durante una partición?
Si favoreces consistencia, normalmente:
- rechazas o retrasas operaciones cuando no puedes confirmar el acuerdo
- requieres mayorías/quórums para lecturas/escrituras
- muestras errores como timeouts, “inténtalo de nuevo” o modos de solo lectura
Esto es habitual en movimientos de dinero, reservas de inventario y cambios de permisos—lugares donde equivocarse es peor que estar temporalmente inaccesible.
¿Cómo se ve una elección orientada a la disponibilidad (AP) durante una partición?
Si favoreces disponibilidad, normalmente:
- sigues aceptando lecturas/escrituras en cada lado de la partición
- permites que las réplicas diverjan temporalmente
- reconcilias después (reglas de merge, resolución de conflictos, revisión manual)
Los usuarios ven menos errores duros, pero pueden ver datos obsoletos, efectos duplicados sin idempotencia, o conflictos que necesitan limpieza.
¿Puedo mezclar las elecciones de consistencia y disponibilidad por operación?
Puedes elegir distinto por endpoint/tipo de dato. Estrategias mixtas comunes incluyen:
- Lecturas disponibles, escrituras más estrictas (la navegación funciona; las actualizaciones arriesgadas pueden fallar)
- Acciones críticas fallan cerradas (pagos, inventario, autenticación) mientras funciones de bajo impacto fallan abiertas (feeds, analítica)
- Modo degradado: mantener operaciones seguras activas y deshabilitar temporalmente las riesgosas
Esto evita una etiqueta global “somos AP/CP” que rara vez se ajusta a las necesidades reales del producto.
¿Qué garantías de consistencia puedo elegir además de “fuerte” vs “eventual”?
Opciones útiles incluyen:
¿Cómo pruebo y monitorizo el comportamiento CAP de mi sistema en la práctica?
Valida creando condiciones donde la discrepancia sea visible:
- Simula particiones/latencia en staging (y con cuidado en producción): agujerea tráfico, bloquea puertos, añade retraso/pérdida
- Verifica el comportamiento: ¿las escrituras se rechazan o se aceptan? ¿las lecturas se quedan obsoletas? ¿cómo funciona la recuperación/reconciliación?
- Supervisa señales más allá del tiempo de actividad:
- tasas de error por operación (lectura vs escritura)
- lag/divergencia/conflictos en réplicas