17 dic 2025·7 min
Pool de conexiones en PostgreSQL: en la aplicación vs PgBouncer
Pool de conexiones en PostgreSQL: compara pools en la app y PgBouncer para backends Go, métricas para vigilar y malas configuraciones que provocan picos de latencia.
Pool de conexiones en PostgreSQL: compara pools en la app y PgBouncer para backends Go, métricas para vigilar y malas configuraciones que provocan picos de latencia.
Una conexión a la base de datos es como una línea telefónica entre tu app y Postgres. Abrirla cuesta tiempo y recursos en ambos lados: establecimiento TCP/TLS, autenticación, memoria y un proceso backend en Postgres. Un pool de conexiones mantiene un pequeño conjunto de estas “líneas telefónicas” abiertas para que tu app pueda reutilizarlas en lugar de marcar cada vez.
Cuando el pooling está desactivado o mal dimensionado, raramente aparece primero un error claro. Aparece lentitud aleatoria. Solicitudes que normalmente tardan 20–50 ms de repente tardan 500 ms o 5 segundos, y p95 se dispara. Luego aparecen timeouts, seguido de “too many connections”, o una cola dentro de la app mientras espera una conexión libre.
Los límites de conexión importan incluso para apps pequeñas porque el tráfico es esponjoso. Un correo de marketing, un cron o unos endpoints lentos pueden hacer que docenas de solicitudes golpeen la base de datos al mismo tiempo. Si cada solicitud abre una conexión nueva, Postgres puede gastar mucha de su capacidad solo aceptando y gestionando conexiones en lugar de ejecutar consultas. Si ya tienes un pool pero es demasiado grande, puedes sobrecargar Postgres con demasiados backends activos y provocar cambio de contexto y presión de memoria.
Atento a síntomas tempranos como:
El pooling reduce el churn de conexiones y ayuda a Postgres a manejar picos. No arregla SQL lento. Si una consulta hace un full table scan o espera bloqueos, el pooling cambia sobre todo cómo falla el sistema (cola antes, timeouts después), no si es rápido.
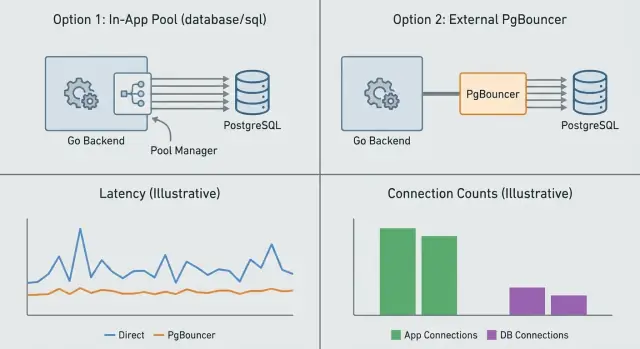
El pooling de conexiones trata de controlar cuántas conexiones existen a la vez y cómo se reutilizan. Puedes hacerlo dentro de la app (pool a nivel de app) o con un servicio separado delante de Postgres (PgBouncer). Resuelven problemas relacionados pero distintos.
El pooling a nivel de app (en Go, normalmente el pool incorporado database/sql) gestiona conexiones por proceso. Decide cuándo abrir una nueva conexión, cuándo reutilizar una y cuándo cerrar las inactivas. Esto evita pagar el coste de setup en cada solicitud. Lo que no puede hacer es coordinarse entre múltiples instancias de la app. Si ejecutas 10 réplicas, en la práctica tienes 10 pools separados.
PgBouncer se sitúa entre tu app y Postgres y hace pooling en nombre de muchos clientes. Es más útil cuando tienes muchas solicitudes de corta duración, muchas instancias de app o tráfico picoso. Limita las conexiones servidor a Postgres incluso si llegan cientos de conexiones cliente a la vez.
División simple de responsabilidades:
Pueden trabajar juntos sin problemas de “double pooling” siempre que cada capa tenga un propósito claro: un database/sql razonable por proceso Go, más PgBouncer para aplicar un presupuesto global de conexiones.
Una confusión común es pensar "más pools = más capacidad". Normalmente significa lo contrario. Si cada servicio, worker y réplica tiene su propio pool grande, el recuento total de conexiones puede explotar y causar colas, cambios de contexto y picos de latencia repentinos.
database/sql en GoEn Go, sql.DB es un gestor de pool de conexiones, no una única conexión. Cuando llamas a db.Query o db.Exec, database/sql intenta reutilizar una conexión inactiva. Si no puede, puede abrir una nueva (hasta tu límite) o hacer que la petición espere.
Esa espera es donde a menudo nace la “latencia misteriosa”. Cuando el pool está saturado, las solicitudes se encolan dentro de la app. Desde fuera parece que Postgres se volvió lento, pero el tiempo se pasa esperando una conexión libre.
La mayor parte del tuning se reduce a cuatro parámetros:
MaxOpenConns: tope duro de conexiones abiertas (idle + en uso). Cuando lo alcanzas, los llamantes se bloquean.MaxIdleConns: cuántas conexiones pueden quedarse listas para reutilizar. Si es muy bajo provoca reconexiones frecuentes.ConnMaxLifetime: fuerza el reciclado periódico de conexiones. Útil para load balancers y timeouts NAT, pero si es muy corto causa churn.ConnMaxIdleTime: cierra conexiones que han estado inactivas demasiado tiempo.La reutilización de conexiones suele bajar la latencia y el CPU de la base de datos porque evitas el setup repetido (TCP/TLS, auth, init de sesión). Pero un pool sobredimensionado puede hacer lo contrario: permite más consultas concurrentes de las que Postgres puede manejar bien, aumentando la contención y la sobrecarga.
Piensa en totales, no por proceso. Si cada instancia Go permite 50 conexiones abiertas y escalas a 20 instancias, efectivamente permitiste 1.000 conexiones. Compara ese número con lo que tu servidor Postgres puede ejecutar con suavidad.
Un punto práctico de partida es ligar MaxOpenConns a la concurrencia esperada por instancia y luego validar con métricas de pool (in-use, idle y wait time) antes de aumentarlo.
PgBouncer es un proxy pequeño entre tu app y PostgreSQL. Tu servicio conecta a PgBouncer, y PgBouncer mantiene un número limitado de conexiones reales al servidor Postgres. Durante un pico, PgBouncer encola trabajo cliente en vez de crear más backends de Postgres inmediatamente. Esa cola puede ser la diferencia entre una desaceleración controlada y una base de datos que se cae.
PgBouncer tiene tres modos de pooling:
Session pooling se comporta más como conexiones directas a Postgres. Es lo menos sorprendente, pero ahorra menos conexiones servidor en cargas picosas.
Para APIs HTTP típicas en Go, transaction pooling suele ser un buen valor por defecto. La mayoría de las solicitudes hacen una pequeña consulta o una transacción corta y terminan. Transaction pooling permite que muchas conexiones cliente compartan un presupuesto menor de conexiones en Postgres.
El intercambio es el estado de sesión. En modo transaction, cualquier cosa que asuma una conexión servidor persistente puede romperse o comportarse de forma extraña, incluyendo:
SET, SET ROLE, search_path)Si tu app depende de ese tipo de estado, session pooling es más seguro. Statement pooling es el más restrictivo y rara vez encaja en aplicaciones web.
Una regla útil: si cada petición puede preparar lo que necesita dentro de una sola transacción, transaction pooling suele mantener la latencia más estable bajo carga. Si necesitas comportamiento de sesión de larga duración, usa session pooling y enfócate en límites más estrictos en la app.
Si ejecutas un servicio Go con database/sql, ya tienes pooling en la app. Para muchos equipos eso es suficiente: pocas instancias, tráfico estable y consultas que no son extremadamente picosas. En ese escenario, la elección más simple y segura es afinar el pool de Go, mantener un límite de conexiones realista y dejarlo así.
PgBouncer ayuda más cuando la base de datos recibe demasiadas conexiones cliente a la vez. Esto aparece con muchas instancias de app (o escalado tipo serverless), tráfico picoso y muchas consultas cortas.
PgBouncer también puede perjudicar si se usa en el modo equivocado. Si tu código depende del estado de sesión (tablas temporales, prepared statements persistentes, advisory locks mantenidos entre llamadas o settings a nivel de sesión), transaction pooling puede causar fallos confusos. Si realmente necesitas comportamiento de sesión, usa session pooling o evita PgBouncer y dimensiona los pools de la app con cuidado.
Usa esta regla orientativa:
max open connections podría exceder lo que Postgres puede manejar, añade PgBouncer.Los límites de conexión son un presupuesto. Si lo gastas todo de golpe, cada nueva solicitud espera y la latencia en cola se dispara. El objetivo es capar la concurrencia de forma controlada manteniendo un rendimiento estable.
Mide los picos y la latencia en colas actuales. Registra conexiones activas máximas (no promedios), y p50/p95/p99 para peticiones y consultas clave. Anota errores de conexión o timeouts.
Define un presupuesto seguro de conexiones Postgres para la app. Parte de max_connections y resta margen para acceso admin, migraciones, jobs en background y picos. Si varias servicios comparten la BD, reparte intencionalmente el presupuesto.
Mapea el presupuesto a límites Go por instancia. Divide el presupuesto por el número de instancias y fija MaxOpenConns en ese valor (o algo menor). Ajusta MaxIdleConns para evitar reconexiones constantes y pon lifetimes que reciclen conexiones sin churn.
Añade PgBouncer solo si lo necesitas y elige un modo. Usa session pooling si requieres estado de sesión. Usa transaction pooling cuando quieras la mayor reducción de conexiones servidor y tu app sea compatible.
Despliega gradualmente y compara antes/después. Cambia una cosa a la vez, pon canary y compara la latencia en cola, el tiempo de espera del pool y la CPU de la base de datos.
Ejemplo: si Postgres puede conceder 200 conexiones de forma segura y ejecutas 10 instancias Go, empieza con MaxOpenConns=15-18 por instancia. Eso deja margen para picos y reduce la probabilidad de que todas las instancias lleguen al tope a la vez.
Los problemas de pooling rara vez aparecen primero como “demasiadas conexiones”. Más bien, ves un aumento lento en los tiempos de espera y luego un salto repentino en p95 y p99.
Empieza con lo que reporta tu app Go. Con database/sql, monitoriza conexiones abiertas, in-use, idle, wait count y wait time. Si el wait count sube con tráfico estable, tu pool está subdimensionado o las conexiones se mantienen demasiado tiempo.
En la base de datos, sigue conexiones activas vs max, CPU y actividad de bloqueos. Si la CPU está baja pero la latencia alta, suele ser cola o bloqueos, no cálculo bruto.
Si usas PgBouncer, añade una tercera vista: conexiones cliente, conexiones servidor a Postgres y profundidad de cola. Una cola creciente con conexiones servidor estables es señal clara de que el presupuesto está saturado.
Señales de alerta útiles:
Los problemas de pooling suelen aparecer durante picos: las solicitudes se amontonan esperando una conexión, y luego todo vuelve a la normalidad. La raíz suele ser una configuración que es razonable en una instancia pero peligrosa cuando hay muchas réplicas.
Causas comunes:
MaxOpenConns fijado por instancia sin un presupuesto global. 100 conexiones por instancia en 20 instancias son 2.000 conexiones potenciales.ConnMaxLifetime / ConnMaxIdleTime demasiado bajos. Esto puede causar tormentas de reconexión cuando muchas conexiones se reciclan al mismo tiempo.Una forma sencilla de reducir picos es tratar el pooling como un límite compartido, no como un valor por defecto local: capar las conexiones totales entre instancias, mantener un pool idle moderado y usar lifetimes lo bastante largos para evitar reconexiones sincronizadas.
Cuando el tráfico sube, normalmente ves uno de tres resultados: las solicitudes se encolan esperando una conexión libre, las solicitudes hacen timeout, o todo se vuelve tan lento que los reintentos se acumulan.
La cola es la más traicionera. Tu handler sigue en ejecución, pero está aparcado esperando una conexión. Esa espera entra en el tiempo de respuesta, de modo que un pool pequeño puede convertir una consulta de 50 ms en un endpoint de varios segundos bajo carga.
Un modelo mental útil: si tu pool tiene 30 conexiones útiles y de repente tienes 300 peticiones concurrentes que necesitan la BD, 270 deben esperar. Si cada petición mantiene la conexión 100 ms, la latencia en cola sube rápidamente a segundos.
Define un presupuesto de timeouts y cúmplelo. El timeout de la app debe ser algo menor que el timeout de la base de datos para fallar rápido y reducir la presión en vez de dejar trabajo colgado.
statement_timeout para que una consulta mala no acapare conexionesLuego añade backpressure para no saturar el pool en primer lugar. Elige uno o dos mecanismos previsibles, como limitar concurrencia por endpoint, rechazar carga con errores claros (por ejemplo 429) o separar jobs en background del tráfico de usuarios.
Finalmente, arregla primero las consultas lentas. Bajo presión de pooling, las consultas lentas mantienen conexiones más tiempo, lo que aumenta esperas, timeouts y reintentos. Ese bucle hace que “un poco lento” se vuelva “todo lento”.
Trata las pruebas de carga como una forma de validar tu presupuesto de conexiones, no solo el rendimiento. El objetivo es confirmar que el pooling se comporta bajo presión igual que en staging.
Prueba con tráfico realista: la misma mezcla de endpoints, patrones de ráfaga y el mismo número de instancias que usas en producción. Los benchmarks sobre un solo endpoint suelen ocultar problemas de pool hasta el día del lanzamiento.
Incluye un warm-up para no medir caches fríos y efectos de ramp-up. Deja que los pools alcancen su tamaño normal y luego empieza a registrar números.
Si comparas estrategias, mantiene la carga idéntica y ejecuta:
database/sql, sin PgBouncer)Tras cada ejecución, registra una hoja de resultados que puedas reutilizar después de cada release:
Con el tiempo, esto convierte la planificación de capacidad en algo repetible en lugar de conjeturas.
Antes de tocar los tamaños de pool, escribe un número: tu presupuesto de conexiones. Es el máximo seguro de conexiones activas a Postgres para este entorno (dev, staging, prod), incluyendo jobs en background y acceso admin. Si no puedes nombrarlo, estás adivinando.
Una lista rápida:
MaxOpenConns) encaje en el presupuesto (o en el tope de PgBouncer).max_connections y cualquier conexión reservada coinciden con tu plan.Plan de despliegue que facilita rollback:
Si estás construyendo y alojando una app Go + PostgreSQL en Koder.ai (koder.ai), Planning Mode puede ayudarte a mapear el cambio y qué medir, y las snapshots más el rollback facilitan revertir si la latencia tail empeora.
Siguiente paso: añade una medición antes del próximo salto de tráfico. “Tiempo empleado esperando una conexión” en la app suele ser la más útil, porque muestra presión de pooling antes de que los usuarios la noten.
Un pool mantiene un pequeño conjunto de conexiones abiertas a PostgreSQL y las reutiliza entre solicitudes. Así se evita pagar repetidamente el coste de apertura (TCP/TLS, autenticación, arranque del backend) y se mantiene la latencia en las colas de espera durante picos.
Cuando el pool está saturado, las solicitudes esperan dentro de la app a que haya una conexión libre, y ese tiempo de espera aparece como respuestas lentas. A menudo parece “lentitud aleatoria” porque las medias pueden mantenerse bien mientras p95/p99 se disparan en picos de tráfico.
No. El pooling cambia principalmente cómo se comporta el sistema bajo carga: reduce el churn de reconexiones y controla la concurrencia. Si una consulta es lenta por escaneos, bloqueos o falta de índices, el pooling no la hará más rápida; solo limitará cuántas consultas lentas se ejecutan a la vez.
El pool en la app gestiona conexiones por proceso, de modo que cada réplica tiene su propio conjunto de conexiones y sus límites. PgBouncer se coloca delante de Postgres y aplica un presupuesto global de conexiones entre muchos clientes; es especialmente útil con muchas réplicas o tráfico explosivo.
Si tienes pocas instancias y las conexiones totales están cómodas por debajo del límite de la base de datos, afinar database/sql suele ser suficiente. Añade PgBouncer cuando muchas instancias, autoscaling o tráfico con picos puedan empujar las conexiones totales más allá de lo que Postgres maneja suave.
Un buen punto de partida es definir un presupuesto total de conexiones para el servicio, dividirlo entre las instancias y fijar MaxOpenConns algo por debajo de esa cifra por instancia. Empieza pequeño, vigila tiempos de espera y p95/p99, y solo sube si la base de datos tiene margen.
Para APIs HTTP en Go, el pooling por transacción suele ser un buen valor por defecto: permite que muchas conexiones cliente compartan menos conexiones servidor y se mantiene estable en picos. Usa pooling por sesión si tu código depende del estado de sesión persistente (tablas temporales, settings, prepared statements reutilizados).
Los prepared statements, tablas temporales, advisory locks y configuraciones a nivel de sesión pueden comportarse distinto porque el cliente puede no obtener siempre la misma conexión servidor. Si necesitas esos comportamientos, encapsula lo necesario en una única transacción por petición o usa pooling por sesión para evitar fallos confusos.
Vigila p95/p99 junto con el tiempo de espera del pool en la app, porque ese tiempo suele subir antes de que los usuarios lo noten. En Postgres, sigue conexiones activas, CPU y bloqueos; en PgBouncer, cliente vs servidor y la profundidad de la cola para ver si estás saturando el presupuesto de conexiones.
Primero, evita esperas ilimitadas poniendo deadlines en peticiones y statement_timeout en la base de datos para que una consulta lenta no bloquee conexiones. Luego aplica backpressure limitando concurrencia en endpoints pesados en BD o rechazando carga (por ejemplo 429) y reduce el churn evitando lifetimes demasiado cortos que provoquen oleadas de reconexiones.