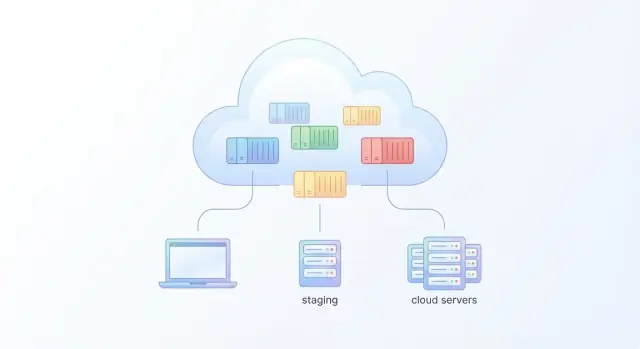
Por qué Docker es tan útil para despliegues en la nube
La mayoría del dolor en despliegues en la nube empieza con una sorpresa familiar: la app funciona en el portátil y luego falla cuando llega a un servidor en la nube. Tal vez el servidor tenga una versión distinta de Python o Node, una librería del sistema ausente, un archivo de configuración ligeramente diferente o un servicio de fondo que no está corriendo. Esas pequeñas diferencias se acumulan y los equipos acaban depurando el entorno en lugar de mejorar el producto.
Docker ayuda empaquetando tu aplicación junto con el runtime y las dependencias que necesita para ejecutarse. En lugar de enviar una lista de pasos como “instala la versión X, luego añade la librería Y, luego configura esto”, envías una imagen de contenedor que ya incluye esas piezas.
Un modelo mental útil es:
- Imagen = la app empaquetada (una instantánea con todo lo necesario para ejecutarla)
- Contenedor = una instancia en ejecución de esa imagen
Cuando ejecutas la misma imagen en la nube que probaste localmente, reduces drásticamente los problemas de “pero mi servidor es distinto”.
Quién se beneficia (pista: no son solo los desarrolladores)
Docker ayuda a distintos roles por diferentes razones:
- Desarrolladores obtienen un entorno predecible y un onboarding más rápido (“ejecuta este contenedor” es mejor que docs de setup de muchas páginas).
- Operaciones y equipos de plataforma consiguen despliegues más consistentes y límites más claros entre apps y servidores.
- Equipos pequeños obtienen un camino repetible a producción sin inventar scripts de despliegue personalizados para cada proyecto.
- Empresas grandes obtienen estandarización: el mismo formato de empaquetado en muchos equipos y servicios.
Una expectativa realista
Docker es extremadamente útil, pero no es la única herramienta que necesitarás. Aun así tendrás que gestionar configuración, secretos, almacenamiento de datos, redes, monitorización y escalado. Para muchos equipos, Docker es un bloque de construcción que funciona junto con herramientas como Docker Compose para flujos locales y plataformas de orquestación en producción.
Piensa en Docker como el contenedor de envío para tu app: hace que la entrega sea predecible. Lo que sucede en el puerto (la configuración y runtime en la nube) sigue importando, pero se vuelve mucho más sencillo cuando cada envío está empaquetado de la misma forma.
Conceptos básicos de Docker: contenedores, imágenes y registros
Docker puede parecer mucho vocabulario nuevo, pero la idea central es sencilla: empaqueta tu app para que se ejecute igual en cualquier lugar.
Contenedor vs máquina virtual (VM)
Una máquina virtual agrupa un sistema operativo invitado completo más tu app. Es flexible, pero más pesada de ejecutar y más lenta al arrancar.
Un contenedor agrupa tu app y sus dependencias, pero comparte el kernel del sistema host en lugar de llevar un sistema operativo completo. Por eso, los contenedores suelen ser más ligeros, arrancan en segundos y puedes ejecutar muchos más en el mismo servidor.
Términos clave que verás por todas partes
Imagen: una plantilla de solo lectura para tu app. Piensa en ella como un artefacto empaquetado que incluye tu código, runtime, librerías del sistema y configuraciones por defecto.
Contenedor: una instancia en ejecución de una imagen. Si una imagen es el plano, el contenedor es la casa en la que estás viviendo.
Dockerfile: las instrucciones paso a paso que Docker usa para construir una imagen (instalar dependencias, copiar archivos, establecer el comando de arranque).
Registro: un servicio de almacenamiento y distribución para imágenes. "Push" para subir imágenes a un registro y "pull" para bajarlas en servidores más tarde (registros públicos o privados dentro de tu empresa).
Por qué la estandarización importa
Una vez que tu app está definida como una imagen construida desde un Dockerfile, ganas una unidad de entrega estandarizada. Esa estandarización hace que los lanzamientos sean repetibles: la misma imagen que probaste es la que despliegas.
También simplifica las transferencias: en lugar de “funciona en mi máquina”, puedes señalar una versión específica de imagen en un registro y decir: ejecuta este contenedor con estas variables de entorno en este puerto. Esa es la base para entornos de desarrollo y producción coherentes.
Consistencia del portátil a la nube: el beneficio principal
La razón principal por la que Docker importa en despliegues en la nube es la consistencia. En lugar de confiar en lo que esté instalado en un portátil, en un runner de CI o en una VM de la nube, defines el entorno una vez (en un Dockerfile) y lo reutilizas en todas las etapas.
Qué significa “consistente” en la práctica
En la práctica, la consistencia se traduce en:
- Mismas versiones de runtime en dev, test y producción (por ejemplo, la misma versión de Node/Python/JVM y paquetes del sistema)
- Menos problemas por deriva de dependencias (librerías, paquetes del SO)
- Rollbacks más sencillos redeplegando una etiqueta anterior de la imagen
- Depuración más clara porque los entornos coinciden
Esa consistencia rinde frutos rápido. Un bug que aparece en producción puede reproducirse localmente ejecutando la misma etiqueta de imagen. Un despliegue que falla por una librería ausente deja de ser probable porque la librería también habría faltado en tu contenedor de prueba.
Por qué esto es distinto a “simplemente instalar lo mismo”
Los equipos a menudo intentan estandarizar con docs de setup o scripts que configuran servidores. El problema es la deriva: las máquinas cambian con el tiempo conforme llegan parches y actualizaciones de paquetes, y las diferencias se acumulan lentamente.
Con Docker, el entorno se trata como un artefacto. Si necesitas actualizarlo, reconstruyes una nueva imagen y la despliegas: los cambios son explícitos y revisables. Si la actualización causa problemas, el rollback suele ser tan simple como desplegar la etiqueta anterior conocida como buena.
Portabilidad entre nubes y servidores
La otra gran ventaja de Docker es la portabilidad. Una imagen de contenedor convierte tu aplicación en un artefacto portátil: constrúyela una vez y ejecútala en cualquier lugar donde exista un runtime de contenedores compatible.
La misma imagen, distintos hogares
Una imagen Docker incluye tu código de aplicación y sus dependencias de runtime (por ejemplo, Node.js, paquetes de Python, librerías del sistema). Eso significa que una imagen que ejecutas en el portátil también puede ejecutarse en:
- Una VM en AWS, Azure o Google Cloud
- Tus propios servidores en un centro de datos
- Plataformas de contenedores gestionadas (como servicios basados en Kubernetes)
Esto reduce el vendor lock-in a nivel de runtime de la aplicación. Puedes seguir usando servicios nativos de la nube (bases de datos, colas, almacenamiento), pero tu aplicación central no tiene que recompilarse solo porque cambiaste de host.
Dónde encajan los registros
La portabilidad funciona mejor cuando las imágenes se almacenan y versionan en un registro, público o privado. Un flujo típico es:
- Construir una imagen una vez (por ejemplo,
myapp:1.4.2).
- Subirla a un registro.
- Descargar y ejecutar esa imagen exacta en cada entorno.
Los registros también facilitan reproducir y auditar despliegues: si producción está ejecutando 1.4.2, puedes bajar ese mismo artefacto más tarde y obtener bits idénticos.
Escenarios prácticos
Migración de host: si te mudas de un proveedor de VM a otro, no vuelves a instalar la pila. Apuntas el nuevo servidor al registro, tiras la imagen y arrancas el contenedor con la misma configuración.
Escalar horizontalmente: ¿necesitas más capacidad? Arranca contenedores adicionales de la misma imagen en más servidores. Como cada instancia es idéntica, escalar se convierte en una operación repetible en lugar de una tarea manual.
Construir imágenes pequeñas, repetibles y mantenibles
Una buena imagen Docker no es solo “algo que corre”. Es un artefacto empaquetado y versionado que puedes reconstruir después y seguir confiando. Eso es lo que hace que los despliegues en la nube sean predecibles.
El Dockerfile: tu receta de construcción
Un Dockerfile describe cómo ensamblar la imagen de tu app paso a paso—como una receta con ingredientes e instrucciones exactas. Cada línea crea una capa y en conjunto definen:
- el punto de partida (imagen base)
- qué dependencias instalar
- cómo copiar tu código
- qué comando inicia la app
Mantener este archivo claro e intencional facilita depurar, revisar y mantener la imagen.
Buenas prácticas para mantener imágenes ligeras y repetibles
Las imágenes pequeñas se descargan más rápido, arrancan antes y tienen menos “cosas” que puedan romperse o contener vulnerabilidades.
- Elige una imagen base pequeña (por ejemplo,
alpine o variantes "slim") cuando sea compatible con tu app.
- Fija versiones para imágenes base y paquetes clave. Las versiones flotantes pueden cambiar y producir compilaciones diferentes.
- Minimiza capas y archivos: combina comandos relacionados y limpia caches de paquetes para no incluir basura temporal de construcción.
Construcciones multi-stage: compila grande, entrega pequeño
Muchas apps necesitan compiladores y herramientas de build para compilar, pero no para ejecutar. Las builds multi-stage te permiten usar una etapa para compilar y otra mínima para producción.
# build stage
FROM node:20 AS build
WORKDIR /app
COPY package*.json ./
RUN npm ci
COPY . .
RUN npm run build
# runtime stage
FROM nginx:1.27-alpine
COPY --from=build /app/dist /usr/share/nginx/html
El resultado es una imagen de producción más pequeña con menos dependencias que parchear.
Estrategia de etiquetado: haz los despliegues trazables
Las etiquetas son cómo identificas exactamente lo que desplegaste.
- Evita depender de
latest en producción; es ambiguo.
- Usa versiones semánticas (por ejemplo,
1.4.2) para releases.
- Añade una etiqueta con SHA del commit (por ejemplo,
1.4.2-<sha> o solo <sha>) para poder trazar siempre una imagen hasta el código que la produjo.
Esto soporta rollbacks limpios y auditorías claras cuando algo cambia en la nube.
Ejecutando apps reales: red, config y datos
Planifica tu configuración en la nube
Mapea servicios, puertos, variables de entorno y necesidades de datos antes de desplegar.
Una app “real” en la nube normalmente no es un único proceso. Es un pequeño sistema: un frontend web, una API, tal vez un worker en background y una base de datos o cache. Docker soporta tanto configuraciones simples como multi-servicio: solo necesitas entender cómo se comunican los contenedores, dónde vive la configuración y cómo los datos sobreviven a reinicios.
Apps de contenedor único vs multi-servicio
Una app de un solo contenedor puede ser un sitio estático o una API que no depende de nada más. Expones un puerto (por ejemplo, 8080) y la ejecutas.
Las apps multi-servicio son más comunes: web depende de api, api depende de db y un worker consume trabajos de una cola. En lugar de hardcodear IPs, los contenedores suelen comunicarse por nombre de servicio en una red compartida (por ejemplo, db:5432).
Docker Compose para dev y staging
Docker Compose es una opción práctica para desarrollo local y staging porque te permite arrancar todo el stack con un comando. Además documenta la “forma” de tu app (servicios, puertos, dependencias) en un archivo que todo el equipo puede compartir.
Una progresión típica es:
- Compose en local (feedback rápido)
- Compose en una VM de staging (comportamiento cercano a prod)
- Un runtime/orquestador en la nube en producción
Configuración: qué debe quedarse fuera de las imágenes
Las imágenes deben ser reutilizables y seguras para compartir. Mantén fuera de la imagen:
- Secretos (API keys, contraseñas de BD)
- URLs que difieren entre staging y prod
- Flags de funcionalidad
Pásalos vía variables de entorno, un archivo .env (con cuidado: no lo comitees) o el gestor de secretos de tu nube.
Persistir datos con volúmenes
Los contenedores son desechables; tus datos no deberían serlo. Usa volúmenes para todo lo que deba sobrevivir a un reinicio:
- Bases de datos (Postgres, MySQL)
- Subidas de usuarios
- Archivos generados que no puedes recrear fácilmente
En despliegues en la nube, el equivalente son storages gestionados (bases de datos gestionadas, discos de red, almacenamiento de objetos). La idea clave sigue siendo: los contenedores ejecutan la app; el almacenamiento persistente guarda el estado.
Flujos de despliegue: de la compilación a la ejecución en la nube
Un flujo de despliegue con Docker sano es intencionalmente simple: construye una imagen una vez y ejecuta esa misma imagen en todas partes. En lugar de copiar archivos a servidores o re-ejecutar instaladores, conviertes el despliegue en una rutina repetible: pull de imagen, run del contenedor.
El flujo básico: build → push → run
La mayoría de equipos siguen una canalización como esta:
- Construir una imagen versionada (por ejemplo,
myapp:1.8.3).
- Subirla a un registro (Docker Hub, un registro en la nube o uno privado).
- Desplegar tirando esa imagen en el entorno cloud y arrancando contenedores.
Ese último paso es lo que hace que Docker se sienta “aburrido” en el buen sentido:
docker build -t registry.example.com/myapp:1.8.3 .
docker push registry.example.com/myapp:1.8.3
docker pull registry.example.com/myapp:1.8.3
docker run -d --name myapp -p 80:8080 registry.example.com/myapp:1.8.3
Patrones comunes en la nube
Dos formas comunes de ejecutar apps dockerizadas en la nube:
- VM + Docker: gestionas una máquina virtual, instalas Docker y ejecutas contenedores tú mismo. Es directo y genial para setups pequeños.
- Servicios de contenedores gestionados: el proveedor de la nube gestiona los hosts de contenedores por ti. Sigues desplegando la misma imagen, pero el escalado, los reinicios y la red se automatizan más.
Conceptos básicos para cero-downtime
Para reducir interrupciones durante los lanzamientos, las producciones suelen añadir tres cosas:
- Health checks para confirmar que un contenedor está realmente listo (no solo “arrancado”).
- Rolling updates para reemplazar contenedores gradualmente, no todos a la vez.
- Load balancers para dirigir tráfico solo a contenedores sanos y repartir la carga.
Un registro es más que almacenamiento: es cómo mantienes la consistencia entre entornos. Una práctica común es promover la misma imagen de dev → staging → prod (a menudo re-etiquetando) en lugar de reconstruir cada vez. Así, producción ejecuta el artefacto exacto que ya probaste, lo que reduce sorpresas de “funcionó en staging”.
CI/CD con Docker: lanzamientos más rápidos y limpios
Aprende construyendo
Itera sobre servicios, configuraciones y la configuración de Docker con un flujo guiado por chat.
CI/CD (Integración Continua y Entrega Continua) es esencialmente la línea de montaje para enviar software. Docker hace esa línea de montaje más predecible porque cada paso se ejecuta contra un entorno conocido.
Dónde encaja Docker en la pipeline
Una pipeline amigable con Docker suele tener tres fases:
- Build: crear una imagen Docker versionada desde tu código (por ejemplo,
myapp:1.8.3).
- Test: ejecutar tests automatizados dentro de contenedores para que las herramientas y dependencias coincidan con lo que ejecutarás después.
- Publish: subir la imagen a un registro (privado o público) para que otros entornos puedan tirar el mismo artefacto.
Este flujo también es fácil de explicar a stakeholders no técnicos: “Construimos una caja sellada, probamos la caja y luego enviamos la misma caja a cada entorno”.
Probar dentro de contenedores (para que producción no sea una sorpresa)
Los tests suelen pasar localmente y fallar en producción por runtimes distintos, librerías del sistema faltantes o variables de entorno diferentes. Ejecutar tests en un contenedor reduce esas brechas. Tu runner de CI no necesita una máquina afinada: solo Docker.
Docker favorece “promover, no reconstruir”. En lugar de reconstruir para cada entorno, haces:
- Construir y testear
myapp:1.8.3 una vez.
- Desplegar esa misma imagen en dev.
- Si va bien, desplegar la misma imagen en staging.
- Finalmente, desplegar la misma imagen en producción.
Solo cambia la configuración entre entornos (URLs o credenciales), no el artefacto de la aplicación. Eso reduce la incertidumbre en el día del despliegue y hace que los rollbacks sean simples: redepliega la etiqueta anterior.
Dónde puede ayudar Koder.ai
Si vas rápido y quieres los beneficios de Docker sin pasar días montando la infraestructura, Koder.ai puede ayudarte a generar una app con forma de producción desde un flujo guiado por chat y luego contenerizarla de forma limpia.
Por ejemplo, los equipos usan Koder.ai para:
- crear un frontend en React y un backend en Go con PostgreSQL,
- añadir un Dockerfile y
docker-compose.yml pronto (para alinear dev y prod),
- exportar el código fuente completo y conectarlo a un pipeline estándar build → push → run,
- usar snapshots y rollback durante la iteración para que los cambios en despliegue se mantengan controlados.
La ventaja clave es que Docker sigue siendo el primitivo de despliegue, mientras Koder.ai acelera el camino desde la idea a una base de código lista para contenedores.
Escalar más allá de un servidor: Docker y orquestación
Docker facilita empaquetar y ejecutar un servicio en una máquina. Pero cuando tienes múltiples servicios, múltiples copias de cada servicio y varios servidores, necesitas un sistema que lo coordine. Eso es orquestación: software que decide dónde corren los contenedores, los mantiene saludables y ajusta la capacidad según la demanda.
Por qué la orquestación importa con muchos contenedores
Con solo unos pocos contenedores puedes arrancarlos manualmente y reiniciarlos cuando algo falla. A gran escala eso no funciona:
- Un servidor puede fallar y llevarse varios contenedores.
- Puedes necesitar 2, 10 o 100 copias de un servicio web según el tráfico.
- Las actualizaciones deben desplegarse sin dejar la app offline.
- Los servicios necesitan una forma consistente de encontrarse (service discovery) y compartir configuración.
Kubernetes, explicado sin tanto jerga
Kubernetes (o “K8s”) es el orquestador más común. Un modelo mental simple:
- Nodos: las máquinas (VMs o servidores) que ejecutan tus contenedores.
- Pods: la unidad más pequeña que ejecuta Kubernetes (normalmente un contenedor, a veces un par que deben vivir juntos).
- Deployments: “ejecuta N copias de este pod y mantenlas así”, incluyendo rolling updates.
- Services: redes estables para que otras partes de la app alcancen esos pods de forma fiable.
Cómo encajan las imágenes Docker en Kubernetes
Kubernetes no construye contenedores; los ejecuta. Sigues construyendo una imagen Docker, subiéndola a un registro, y luego Kubernetes la descarga en los nodos y arranca contenedores desde ella. Tu imagen sigue siendo el artefacto portátil y versionado usado en todas partes.
Cuando una opción más simple basta
Si estás en un solo servidor con pocos servicios, Docker Compose puede ser suficiente. La orquestación comienza a ser rentable cuando necesitas alta disponibilidad, despliegues frecuentes, autoescalado o varios servidores para capacidad y resiliencia.
Seguridad y cumplimiento básico para contenedores
Los contenedores no hacen que una app sea segura por arte de magia: principalmente facilitan estandarizar y automatizar el trabajo de seguridad que ya deberías hacer. La ventaja es que Docker te da puntos repetibles para añadir controles que auditorías y equipos de seguridad valoran.
Escaneo de imágenes (y por qué importa)
Una imagen de contenedor es un paquete de tu app más sus dependencias, así que vulnerabilidades suelen venir de imágenes base o paquetes del sistema que no controlas. El escaneo de imágenes busca CVEs conocidos antes de desplegar.
Haz del escaneo una puerta en tu pipeline: si encuentras una vulnerabilidad crítica, falla la build y reconstruye con una imagen base parcheada. Guarda los resultados del escaneo como artefactos para mostrar qué enviaste en revisiones de cumplimiento.
Menor privilegio por defecto
Ejecuta como un usuario no root siempre que sea posible. Muchos ataques aprovechan acceso root dentro del contenedor para escapar o manipular el sistema de archivos.
También considera un sistema de archivos en modo lectura y montar solo rutas específicas como escribibles (logs o uploads). Esto reduce lo que un atacante puede cambiar si entra.
Manejo de secretos: no los incluyas en imágenes
Nunca copies claves API, contraseñas o certificados privados dentro de tu imagen Docker ni los comitees en Git. Las imágenes se cachean, se comparten y se suben a registros: los secretos pueden filtrarse ampliamente.
En su lugar, inyecta secretos en tiempo de ejecución usando el store de secretos de tu plataforma (por ejemplo, Kubernetes Secrets o el gestor de secretos del proveedor de la nube) y restringe el acceso solo a los servicios que los necesitan.
Actualizaciones y parches: reconstruye con regularidad
A diferencia de servidores tradicionales, los contenedores no se parchean solos mientras corren. El enfoque estándar es: reconstruir la imagen con dependencias actualizadas y redeplegar.
Establece una cadencia (semanal o mensual) para reconstruir incluso cuando el código no cambie, y reconstruye de inmediato cuando CVEs de alta severidad afecten tu imagen base. Esta práctica mantiene tus despliegues más fáciles de auditar y con menor riesgo con el tiempo.
Errores comunes y cómo evitarlos
Ponla en tu dominio
Añade un dominio personalizado cuando tu app en contenedores esté lista para usuarios.
Incluso equipos que “usan Docker” pueden enviar despliegues poco fiables si se colan ciertos hábitos. Aquí los errores que causan más pain y maneras prácticas de prevenirlos.
1) Tratar contenedores como mascotas (cambios manuales en prod)
Un anti-patrón común es “hacer SSH al servidor y tocar algo”, o hacer exec en un contenedor en ejecución para parchear una configuración. Funciona una vez y luego falla porque nadie puede recrear exactamente ese estado.
En su lugar, trata los contenedores como ganado: desechables y reemplazables. Haz cada cambio a través de la build de la imagen y el pipeline de despliegue. Si necesitas depurar, hazlo en un entorno temporal y luego codifica la corrección en tu Dockerfile, configuración o infraestructura.
2) Imágenes sobredimensionadas y builds lentos por un Dockerfile desordenado
Imágenes enormes ralentizan CI/CD, aumentan costes de almacenamiento y amplían la superficie de seguridad.
Evítalo ajustando la estructura del Dockerfile:
- Usa una base más pequeña cuando sea razonable.
- Copia primero los archivos de dependencias (para que las instalaciones se cacheen) y luego el código de la app.
- Usa builds multi-stage para apps compiladas de modo que la imagen final solo contenga lo necesario para ejecutar.
- Añade un
.dockerignore para no enviar node_modules, artefactos de build o secretos locales.
El objetivo es una build repetible y rápida—incluso en una máquina limpia.
3) Ignorar logs y métricas (la observabilidad sigue importando)
Los contenedores no eliminan la necesidad de entender qué hace tu app. Sin logs, métricas y trazas, solo notarás problemas cuando los usuarios se quejen.
Como mínimo, asegúrate de que tu app escriba logs en stdout/stderr (no en archivos locales), tenga endpoints de health básicos y emita algunas métricas clave (tasa de errores, latencia, profundidad de colas). Luego conecta esas señales a la monitorización de tu stack en la nube.
4) No planear servicios stateful desde el inicio (BD, colas, archivos)
Los contenedores stateless son fáciles de reemplazar; los datos con estado no lo son. Los equipos a menudo descubren demasiado tarde que una base de datos en un contenedor “funcionaba” hasta que un reinicio borró datos.
Decide pronto dónde vivirá el estado:
- Usa bases de datos/colas gestionadas cuando sea posible.
- Si debes gestionar servicios stateful, diseña almacenamiento, backups y actualizaciones desde el día cero.
Docker es excelente para empaquetar apps, pero la fiabilidad viene de ser deliberado sobre cómo se construyen esos contenedores, cómo se observan y cómo se conectan al almacenamiento persistente.
Checklist práctico para empezar
Si eres nuevo en Docker, la forma más rápida de obtener valor es contenerizar un servicio real de extremo a extremo: construir, ejecutar en local, subir a un registro y desplegar. Usa este checklist para mantener el alcance pequeño y los resultados útiles.
1) Empieza con un servicio (end-to-end)
Elige un servicio stateless primero (una API, un worker o una web simple). Define lo que necesita para arrancar: el puerto en el que escucha, variables de entorno requeridas y dependencias externas (como una BD que puedas ejecutar por separado).
Mantén el objetivo claro: “Puedo ejecutar la misma app localmente y en la nube desde la misma imagen”.
2) Crea un Dockerfile minimal + Compose para uso local
Escribe el Dockerfile más pequeño que construya y ejecute tu app de forma confiable. Prefiere:
- una imagen base pequeña
- copiar solo lo necesario
- un comando de arranque claro
Luego añade un docker-compose.yml para desarrollo local que conecte variables de entorno y dependencias (como una BD) sin instalar nada en tu portátil aparte de Docker.
Si quieres un setup local más profundo después, puedes extenderlo—empieza simple.
3) Elige un registro y una convención de etiquetas
Decide dónde vivirán las imágenes (Docker Hub, GHCR, ECR, GCR, etc.). Luego adopta etiquetas que hagan los despliegues predecibles:
:dev para pruebas locales (opcional):git-sha (inmutable, lo mejor para despliegues):v1.2.3 para releases
Evita depender de :latest en producción.
4) Añade CI para build + publish automático
Configura CI para que cada merge a la rama main construya la imagen y la suba al registro. Tu pipeline debería:
- Construir la imagen
- Ejecutar una comprobación básica (tests o una ejecución smoke)
- Hacer push con las etiquetas acordadas
Cuando esto funcione, estás listo para conectar la imagen publicada al paso de despliegue en la nube e iterar desde ahí.