10 ago 2025·8 min
Por qué el prompting se está convirtiendo en una habilidad clave para Web, Backend y Móvil
El prompting está dejando de ser un truco para convertirse en una habilidad de ingeniería. Aprende patrones prácticos, herramientas, pruebas y flujos de trabajo para apps web, backend y móviles.
Qué significa “prompting” en el trabajo de ingeniería real
El prompting en ingeniería no es “charlar con una IA”. Es el acto de proporcionar entradas revisables que orientan a un asistente hacia un resultado específico y comprobable—similar a cómo escribes un ticket, una especificación o un plan de pruebas.
Un buen prompt suele ser un paquete pequeño de:
- Objetivo: qué construir o decidir
- Restricciones: lenguajes, frameworks, presupuestos de rendimiento, reglas de accesibilidad, contratos de API, límites de plataforma
- Contexto: patrones de código existentes, convenciones de nombres, límites arquitectónicos
- Ejemplos: entradas/salidas de ejemplo, casos límite, capturas de UI descritas en texto, endpoints existentes
- Criterios de aceptación: cómo verificarás que funcionó (tests, reglas de lint, comportamientos esperados)
El prompting es “escribir specs”, pero más ajustado
En proyectos reales no pides “una página de login”. Especificas “un formulario de login que coincida con nuestros tokens de diseño, valide el formato de email, muestre errores en línea y tenga tests unitarios para validación y estados de envío.” El prompt se convierte en un artefacto concreto que otra persona puede revisar, editar y reutilizar—a menudo incluido en el repo junto al código.
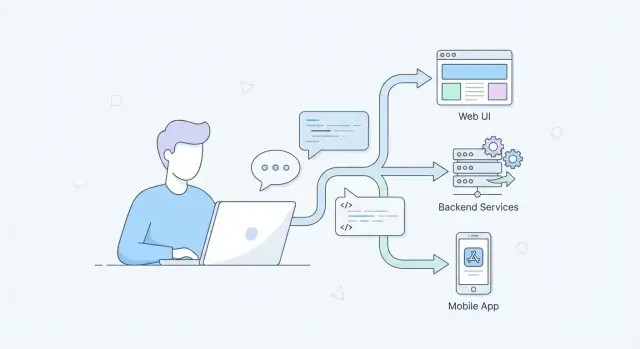
Por qué importa en toda la pila
- UI / UX / frontend: los prompts pueden codificar requisitos de accesibilidad, comportamiento responsive, microcopy y reglas de API de componentes para que la salida no se aparte de los sistemas de diseño.
- APIs / backend: los prompts pueden fijar formas de request/response, semántica de errores, idempotencia, paginación y restricciones de base de datos—reduciendo código “se ve bien” que falla bajo carga.
- Móvil: los prompts pueden considerar modo offline, batería, variabilidad de red, flujos de permisos, y restricciones específicas de dispositivo y políticas de tiendas de apps.
Lo que cubre (y evita) este artículo
Este post se centra en prácticas repetibles: patrones de prompt, workflows, pruebas de prompts y hábitos de revisión en equipo.
Evita el bombo y las “soluciones mágicas”. La asistencia por IA es útil, pero solo cuando el prompt deja las expectativas explícitas—y cuando los ingenieros verifican la salida de la misma forma que verifican código escrito por humanos.
Por qué el prompting se está volviendo una habilidad central ahora
El prompting pasa de ser un “gusto” a una competencia diaria porque cambia la velocidad con la que los equipos pasan de una idea a algo revisable.
Iteración más rápida sin perder rigor
Las herramientas asistidas por IA pueden bosquejar variantes de UI, proponer formas de API, generar casos de prueba o resumir logs en segundos. La velocidad es real—pero solo si tus prompts son lo bastante específicos para producir salidas evaluables. Los ingenieros que convierten intención difusa en instrucciones nítidas obtienen más iteraciones útiles por hora, y eso se compone a lo largo de los sprints.
Las especificaciones en lenguaje natural reemplazan algunos tickets—y aún necesitan precisión
Más trabajo se mueve a lenguaje natural: notas de arquitectura, criterios de aceptación, planes de migración, checklist de releases e informes de incidentes. Siguen siendo “especificaciones”, aunque no parezcan las tradicionales. El prompting es la habilidad de escribir esas specs para que sean inequívocas y comprobables: restricciones, casos límite, criterios de éxito y suposiciones explícitas.
Un buen prompt suele leerse como un mini-brief de diseño:
- Qué estás construyendo y para quién
- Entradas/salidas y restricciones (rendimiento, accesibilidad, límites de dispositivo)
- No-objetivos y compensaciones
- Ejemplos y contraejemplos
La IA entra en el IDE, CI y flujos de docs
A medida que las funciones de IA se integran en IDEs, pull requests, checks de CI y pipelines de documentación, el prompting deja de ser un chat ocasional y pasa a formar parte del flujo cotidiano de ingeniería. Pedirás código, luego tests, luego una revisión de riesgos—cada paso se beneficia de una estructura de prompt consistente y reutilizable.
Equipos cross-funcionales usan la misma interfaz
Diseño, producto, QA e ingeniería colaboran cada vez más mediante herramientas de IA compartidas. Un prompt claro se convierte en un objeto de frontera: todos pueden leerlo, criticarlo y alinearse sobre qué significa “hecho”. Esa claridad compartida reduce retrabajo y hace las revisiones más rápidas y serenas.
De peticiones vagas a prompts claros y comprobables
Una petición vaga como “crear una página de login” obliga al modelo a adivinar. Un prompt comprobable se parece a una mini-spec: declara entradas, salidas esperadas, casos límite y cómo sabrás que es correcto.
Convierte peticiones en requisitos
Empieza escribiendo qué recibe el sistema y qué debe producir.
- Entradas: acciones de usuario, payloads de API, restricciones del dispositivo
- Salidas: estados de UI, respuestas, logs/métricas
- Casos límite: datos inválidos, timeouts, estados vacíos, fallos parciales
Por ejemplo, reemplaza “haz que el formulario funcione” por: “Cuando el email es inválido, muestra un error inline y deshabilita enviar; cuando la API retorna 409, muestra ‘Account already exists’ y conserva los valores ingresados.”
Añade restricciones que eviten respuestas “bonitas pero equivocadas”
Las restricciones son cómo mantienes la salida alineada con tu realidad.
Incluye especificaciones como:
- Stack tecnológico (p. ej., React + TypeScript, Node + Express)
- Objetivos de rendimiento (p. ej., renderizar en < 100ms, evitar consultas N+1)
- Accesibilidad (nivel WCAG, navegación por teclado, expectativas ARIA)
- Manejo de errores (política de reintento, mensajes de usuario, logging)
Pide compensaciones y razonamiento
En vez de solicitar solo código, pide al modelo que explique decisiones y alternativas. Eso facilita las revisiones y saca a la luz suposiciones ocultas.
Ejemplo: “Propón dos enfoques, compara pros/contras en mantenibilidad y rendimiento, luego implementa la opción recomendada.”
Usa ejemplos y no-ejemplos
Los ejemplos reducen la ambigüedad; los no-ejemplos evitan malas interpretaciones.
Prompt débil: “Crea un endpoint para actualizar un usuario.”
Prompt más fuerte: “Diseña PATCH /users/{id}. Acepta JSON { displayName?: string, phone?: string }. Rechaza campos desconocidos (400). Si el usuario no existe (404). Valida el teléfono como E.164. Devuelve el usuario actualizado en JSON. Incluye tests para teléfono inválido, payload vacío y acceso no autorizado. No cambies el email.”
Una regla útil: si no puedes escribir un par de casos de prueba a partir del prompt, aún no es lo bastante específico.
Desarrollo Web: prompts para UI, UX y calidad frontend
El prompting web funciona mejor si tratas al modelo como un compañero junior: necesita contexto, restricciones y una definición de “hecho”. Para trabajo de UI eso significa especificar reglas de diseño, estados, accesibilidad y cómo se verificará el componente.
Generación de componentes con restricciones de diseño reales
En lugar de “Construye un formulario de login”, incluye el design system y los casos límite:
- Layout: puntos de quiebre responsive, escala de espaciado, anchos máximos
- Estados: default, loading, disabled, error, success
- A11y: etiquetas, orden de foco, interacciones por teclado, ARIA
Ejemplo de prompt: “Genera un LoginForm en React usando nuestros componentes Button/Input. Incluye estado loading en submit, validación inline y mensajes de error accesibles. Proporciona stories de Storybook para todos los estados.”
Refactorización de UI segura
Las refactorizaciones van mejor cuando defines guardrails:
“Refactoriza este componente para extraer UserCardHeader y UserCardActions. Mantén la API de props existente, preserva los nombres de clases CSS y no cambies la salida visual. Si debes renombrar, proporciona una nota de migración.”
Esto reduce cambios accidentales y ayuda a mantener consistencia en nombres y estilos.
Consistencia de contenido + UI
Pide explícitamente microcopy y textos de estado, no solo markup:
“Propón microcopy para estado vacío, error de red y permiso denegado. Mantén el tono neutral y conciso. Devuelve el copy + su ubicación en la UI.”
Depuración con pasos de reproducción y logs
Para bugs frontend, los prompts deben agrupar evidencia:
“Dados estos pasos para reproducir, logs de consola y el stack trace, propone causas probables y prioriza las soluciones por confianza. Incluye cómo verificar en el navegador y en un test unitario.”
Cuando los prompts incluyen restricciones y verificación, obtendrás salidas de UI más consistentes, accesibles y revisables.
Desarrollo Backend: prompts para APIs, datos y fiabilidad
Convierte indicaciones en builds
Convierte indicaciones tipo especificación en código web, backend o móvil revisable con Koder.ai.
El trabajo backend está lleno de casos límite: fallos parciales, datos ambiguos, reintentos y sorpresas de rendimiento. Los buenos prompts te ayudan a fijar decisiones que suelen pasarse por alto en un chat, pero son dolorosas de arreglar en producción.
Prompts de diseño de API (rutas, esquemas, códigos de estado)
En vez de pedir “construye una API”, exige al modelo que produzca un contrato que puedas revisar.
Pide:
- Rutas y verbos, con nombres de recursos claros
- Esquemas request/response (incluyendo campos requeridos vs opcionales)
- Códigos de estado para éxito y fallo
- Estrategia de paginación (cursor vs offset) y ordenamiento
- Reglas de idempotencia para escrituras (especialmente POST)
Ejemplo de prompt:
\nDesign a REST API for managing subscriptions.\nReturn:\n1) Endpoints with method + path\n2) JSON schemas for request/response\n3) Status codes per endpoint (include 400/401/403/404/409/422/429)\n4) Pagination and filtering rules\n5) Idempotency approach for create/cancel\nAssume multi-tenant, and include tenant scoping in every query.\n
Validación de datos y manejo de errores
Solicita validación consistente y una “forma de error” estable para que los clientes puedan reaccionar de manera predecible.
Restricciones útiles:
- Validar en el boundary (DTO/input), y de nuevo en persistencia si es necesario
- Usar códigos de error tipados (no solo strings)
- Mapear errores de dominio a HTTP statuses (p. ej., 409 para conflictos, 422 para validación semántica)
- Incluir IDs de correlación en respuestas y logs
Rendimiento: caché, batching, planeamiento de consultas
Los modelos tienden a generar código correcto-pero-lento a menos que pidas explícitamente decisiones de rendimiento. Indica tráfico esperado, objetivos de latencia y tamaño de datos, y pide compensaciones.
Buenas adiciones:
- “Asume 1k RPS y objetivo p95 50ms”
- “Evita consultas N+1; muestra plan de consulta o índices”
- “Sugiere capas de cache (in-memory vs Redis) y estrategia de invalidación”
- “Agrupa llamadas externas; añade timeouts y circuit breakers”
Observabilidad: logs, métricas, traces, alertas
Trata la observabilidad como parte de la feature. Pide qué vas a medir y qué dispararía acción.
Pide al modelo que entregue:
- Logs estructurados (nombre del evento + campos clave, sin datos sensibles)
- Métricas (RPS, tasa de error, latencia p50/p95/p99, profundidad de colas)
- Spans de trace alrededor de DB y llamadas externas
- Reglas de alerta accionables (síntoma + causas probables + pistas de runbook)
Desarrollo Móvil: prompts para restricciones y dispositivos reales
Las apps móviles no fallan solo por “mal código”. Fallan porque los dispositivos reales son desordenados: las redes caen, la batería se agota, la ejecución en background es limitada y pequeños errores de UI se vuelven barreras de accesibilidad. Hacer buenos prompts en móvil significa pedir al modelo que diseñe para restricciones, no solo para funcionalidades.
Prompts para offline, batería y variabilidad de red
En lugar de “Agregar modo offline”, pide un plan que haga explícitas las compensaciones:
- “Diseña un enfoque offline-first para esta pantalla. Especifica qué datos se cachean, reglas de invalidación y qué muestra la UI para datos ‘stale but usable’.”
- “Dada conectividad intermitente (2G–5G, captive portals), propone reglas de retry/backoff y mensajes al usuario. Incluye casos límite como backgrounding durante una petición.”
- “Sugiere formas de reducir el impacto en batería para esta feature. Considera tareas en background, uso de localización, intervalos de polling y cuándo detener trabajo.”
Estos prompts fuerzan al modelo a pensar más allá del happy path y producir decisiones revisables.
Gestión de estado y flujos de navegación
Los bugs móviles vienen a menudo de un estado que es “mayormente correcto” hasta que el usuario pulsa atrás, rota el dispositivo o vuelve desde un deep link.
Usa prompts que describan flujos:
“Estas son las pantallas y eventos (login → onboarding → home → details). Propón un modelo de estado y reglas de navegación. Incluye cómo restaurar estado tras la muerte del proceso y cómo manejar taps duplicados y navegación rápida hacia atrás.”
Si pegas un diagrama de flujo simplificado o una lista de rutas, el modelo puede producir una checklist de transiciones y modos de fallo para probar.
Guías de plataforma y comprobaciones de accesibilidad
Pide revisión específica por plataforma, no consejos UI genéricos:
“Revisa esta pantalla frente a iOS Human Interface Guidelines / Material Design y accesibilidad móvil. Enumera problemas concretos: tamaños de target táctil, contraste, escalado de fuente/dinámico, etiquetas para lector de pantalla, navegación por teclado y uso de haptics.”
Triaje de crashes con stack traces + contexto del dispositivo
Los reportes de crash son accionables cuando emparejas el stack trace con contexto:
“Dado este stack trace e info del dispositivo (versión OS, modelo, versión de app, presión de memoria, pasos para reproducir), propone las causas más probables, qué logs/métricas añadir y una solución segura con plan de despliegue.”
Esa estructura convierte “¿qué pasó?” en “¿qué hacemos ahora?”, que es donde el prompting aporta más valor en móvil.
Patrones de prompt que funcionan en web, backend y móvil
Los buenos prompts son reutilizables. Los mejores se leen como una pequeña especificación: intención clara, contexto suficiente para actuar y una salida comprobable. Estos patrones funcionan tanto si mejoras una UI, diseñas una API o depuras un crash móvil.
La estructura “Spec Prompt”
Una estructura fiable es:
- Rol: a quién debe actuar el modelo (p. ej., “senior frontend engineer”)
- Objetivo: cómo se ve el éxito
- Contexto: archivos relevantes, plataforma, restricciones, comportamiento actual
- Restricciones: rendimiento, accesibilidad, compatibilidad, librerías, versiones OS
- Ejemplos: entradas/salidas, casos límite, muestras de “hacer/no hacer”
- Formato de salida: qué devolver (bullets, patch, JSON)
Esto reduce la ambigüedad en todos los dominios: web (a11y + soporte de navegadores), backend (consistencia + contratos de error), móvil (batería + restricciones de dispositivo).
Paso a paso vs salida directa
Usa salida directa cuando ya sabes lo que necesitas: “Genera un type TypeScript + payload de ejemplo.” Es más rápido y evita explicaciones largas.
Pide compensaciones y razonamiento breve cuando importen las decisiones: elegir paginación, decidir límites de caché o diagnosticar un test móvil intermitente. Un compromiso práctico: “Explica brevemente suposiciones y compensaciones, y luego da la respuesta final.”
“Contratos” de prompt (salidas lintables)
Trata los prompts como mini-contratos pidiendo salida estructurada:
{
"changes": [{"file": "", "summary": "", "patch": ""}],
"assumptions": [],
"risks": [],
"tests": []
}
Esto hace los resultados revisables, amigables a diffs y fáciles de validar con chequeos de esquema.
Reducir alucinaciones
Añade guardrails:
- Pide al modelo que liste suposiciones y que haga preguntas si faltan inputs clave.
- Pide que señale incertidumbre: “Si no estás seguro, dilo y ofrece opciones.”
- Solicita pasos de verificación: comandos, casos de prueba o dónde mirar en el código.
- Si referencia hechos externos, pídele que cite fuentes (o afirma explícitamente “no se usaron fuentes”).
Workflow de ingeniería: prompts como artefactos de primera clase
Si tu equipo usa IA regularmente, los prompts dejan de ser “mensajes de chat” y se comportan como activos de ingeniería. La forma más rápida de mejorar la calidad es tratar los prompts igual que el código: intención clara, estructura consistente y un historial de cambios.
Trata los prompts como código
Asigna propiedad y guarda los prompts en control de versiones. Cuando un prompt cambia, debes poder responder: por qué, qué mejoró y qué rompió. Un enfoque ligero es una carpeta /prompts en cada repo, con un archivo por workflow (p. ej., pr-review.md, api-design.md). Revisa cambios en prompts en pull requests, igual que cualquier otra contribución.
Si usas una plataforma chat-like como Koder.ai, el mismo principio aplica: incluso cuando la interfaz es conversacional, las entradas que generan código de producción deben versionarse (o al menos capturarse como plantillas) para reproducir resultados entre sprints.
Usa plantillas para trabajo repetible
La mayoría de equipos repite las mismas tareas asistidas por IA: revisiones de PR, resúmenes de incidentes, migraciones de datos, notas de release. Crea plantillas de prompt que estandaricen inputs (contexto, restricciones, definición de hecho) y outputs (formato, checklists, criterios de aceptación). Esto reduce la variabilidad entre ingenieros y facilita la verificación.
Una plantilla buena suele incluir:
- Objetivo (qué resultado necesitas)
- Restricciones (lenguajes, frameworks, límites de tiempo/memoria)
- Contexto del proyecto (links a archivos, notas de arquitectura)
- Formato de salida (tablas, diffs, plan paso a paso)
Haz explícitas las aprobaciones
Documenta dónde deben aprobar los humanos—especialmente en áreas sensibles a seguridad, cumplimiento, cambios en BD de producción y todo lo que toque auth o pagos. Coloca estas reglas junto al prompt (o en /docs/ai-usage.md) para que nadie dependa de la memoria.
Cuando tu tooling lo permita, captura mecánicas de “iteración segura” en el propio flujo. Por ejemplo, plataformas como Koder.ai soportan snapshots y rollback, lo que facilita experimentar con cambios generados, revisar diffs y revertir si un prompt produjo una refactorización insegura.
Cuando los prompts son artefactos de primera clase obtienes repetibilidad, auditabilidad y entregas asistidas por IA más seguras—sin frenar al equipo.
Probar y evaluar la calidad de los prompts
Trata los prompts como cualquier otro activo de ingeniería: si no puedes evaluarlos, no puedes mejorarlos. “Parece funcionar” es frágil—especialmente cuando el mismo prompt lo va a reutilizar un equipo, correr en CI o aplicarse a nuevos codebases.
Construye casos de prueba golden
Crea una pequeña suite de “entradas conocidas → salidas esperadas” para tus prompts. La clave es hacer salidas comprobables:
- Prefiere salidas estructuradas (JSON, tablas, headings explícitos) sobre texto libre.
- Incluye casos límite (inputs vacíos, strings largos, locales inusuales, paths de error).
- Versiona el prompt y los casos golden juntos para que los cambios sean intencionales.
Ejemplo: un prompt que genera un contrato de errores de API debería producir siempre los mismos campos, con nombres y códigos de estado consistentes.
Usa evaluación basada en diffs
Cuando actualices un prompt, compara la nueva salida con la anterior y pregúntate: qué cambió y por qué. Los diffs hacen las regresiones obvias (campos faltantes, tono distinto, orden cambiado) y ayudan al revisor a centrarse en comportamiento en lugar de estilo.
Automatiza cheques en el pipeline
Los prompts pueden probarse con la misma disciplina que el código:
- Validación de esquema para salidas JSON
- Tests unitarios que aserten requisitos clave (p. ej., incluye paginación, maneja nulls)
- Análisis estático para código generado
- “¿Se compila y ejecuta?” para capturar errores de sintaxis y dependencias
Si generas aplicaciones completas (web, backend o móvil) vía un flujo de plataforma—como el proceso chat-driven de Koder.ai—estos cheques son aún más importantes, porque puedes producir cambios grandes rápidamente. La velocidad debe aumentar el throughput de revisión, no reducir el rigor.
Mide resultados reales
Por último, mide si los prompts realmente mejoran la entrega:
- Tiempo ahorrado por tarea (baseline vs asistido por IA)
- Tasa de defectos (bugs detectados en QA/producción)
- Tasa de retrabajo (con qué frecuencia las salidas requieren rehacerlas manualmente)
Si un prompt ahorra minutos pero aumenta retrabajo, no es “bueno”—solo es rápido.
Seguridad, privacidad y controles de riesgo para trabajo asistido por IA
Usar un LLM en ingeniería cambia lo que significa “seguro por defecto”. El modelo no puede saber qué detalles son confidenciales y puede generar código que parece razonable mientras introduce vulnerabilidades. Trata la asistencia por IA como una herramienta que necesita guardrails—igual que CI, escaneo de dependencias o revisión de código.
No leaks de secretos (ni siquiera por accidente)
Asume que todo lo que pegues en un chat podría almacenarse, registrarse o revisarse. Nunca incluyas keys de API, tokens, certificados privados, datos de clientes ni URLs internas. Usa placeholders y ejemplos sintéticos mínimos.
Si necesitas ayuda depurando, comparte:
- El snippet mínimo reproducible con valores falsos
- Un extracto de log redactado (quita IDs, emails, tokens)
- Una declaración clara de qué es público vs confidencial
Crea un workflow de redacción en equipo (plantillas y checklists) para que la gente no improvise sus propias reglas bajo presión.
Modelo de amenazas sobre la salida, no solo la entrada
El código generado por IA puede introducir problemas clásicos: riesgos de inyección, defaults inseguros, faltas de checks de autorización, dependencias frágiles y crypto débil.
Un hábito práctico de prompt es pedir al modelo que critique su propia salida:
- “Lista los riesgos de seguridad en este código, ordenados por impacto.”
- “¿Qué inputs podrían estar controlados por un atacante?”
- “¿Qué debería validarse server-side y cómo?”
Requiere prompts de revisión de seguridad para áreas sensibles
Para auth, criptografía, checks de permisos y control de acceso, haz que los “prompts de revisión de seguridad” formen parte de la definición de hecho. Combínalos con revisión humana y cheques automatizados (SAST, escaneo de dependencias). Si mantienes estándares internos, enlázalos en el prompt (p. ej., “Sigue nuestras guías de auth en /docs/security/auth”).
El objetivo no es prohibir la IA—es hacer que el comportamiento seguro sea lo más sencillo.
Habilidades de equipo: colaboración, revisiones y formación
El prompting escala mejor cuando se trata como una habilidad de equipo, no un truco personal. La meta no es “mejores prompts” en abstracto—es menos malentendidos, revisiones más rápidas y resultados más predecibles de trabajo asistido por IA.
Define qué significa “bueno”
Antes de que alguien escriba prompts, alinea una definición compartida de hecho. Convierte “mejóralo” en expectativas comprobables: criterios de aceptación, estándares de código, convenciones de nombres, requisitos de accesibilidad, presupuestos de rendimiento y necesidades de logging/observabilidad.
Un enfoque práctico es incluir un pequeño “contrato de salida” en los prompts:
- Qué debe hacer el cambio (criterios de aceptación)
- Qué no debe hacer (no-objetivos, restricciones)
- Cómo debe entregarse (archivos a editar, estilo de código, tests requeridos)
Cuando los equipos hacen esto de forma consistente, la calidad de los prompts se vuelve revisable—igual que el código.
Pair prompting: escribir + sondear
El pair prompting refleja el pair programming: una persona escribe el prompt, la otra lo revisa y sondea suposiciones. La tarea del revisor es hacer preguntas como:
- ¿Qué entradas, casos límite y estados de error se implican pero no se dicen?
- ¿Qué dependencias o reglas de producto podrían violarse?
- ¿Qué tests prueban que esto es correcto?
Esto atrapa la ambigüedad temprano y evita que la IA construya lo equivocado con confianza.
Entrena con un playbook compartido
Crea un playbook ligero con ejemplos del codebase: “plantilla de endpoint API”, “plantilla de refactor de componente frontend”, “plantilla de constraints móviles”, etc. Guárdalo donde los ingenieros ya trabajen (wiki o repo) y enlázalo en plantillas de PR.
Si tu organización usa una plataforma única para construcción cross-funcional (producto + diseño + ingeniería), captura esas plantillas allí también. Por ejemplo, equipos en Koder.ai suelen estandarizar prompts alrededor de planning mode (acordar alcance y criterios de aceptación primero), luego generar pasos de implementación y tests.
Construye bucles de feedback desde problemas reales
Cuando un bug o incidente se rastrea a un prompt poco claro, no solo arregles el código—actualiza la plantilla del prompt. Con el tiempo, tus mejores prompts se convierten en memoria institucional, reduciendo errores repetidos y el tiempo de onboarding.
Plan práctico de adopción para tu equipo de ingeniería
Adoptar el prompting funciona mejor como un cambio pequeño de ingeniería, no como una gran “iniciativa de IA”. Trátalo como cualquier otra práctica de productividad: empieza de forma acotada, mide impacto y luego expande.
Semana 1: elige casos de uso de alto valor
Elige 3–5 casos de uso por equipo que sean frecuentes, de bajo riesgo y fáciles de evaluar. Ejemplos:
- Scaffold de API (handlers, routing, snippets OpenAPI)
- Generación de tests (unitarios, casos límite, regresiones)
- Variantes de componentes UI (estados, notas de accesibilidad)
- Helpers para migraciones (migraciones SQL, scripts de validación de datos)
Escribe qué significa “bueno” (tiempo ahorrado, menos bugs, docs más claras) para que el equipo tenga un objetivo compartido.
Semanas 2–3: crea un set pequeño de plantillas de prompt
Construye una pequeña librería de plantillas (5–10) e itérala semanalmente. Mantén cada plantilla enfocada y estructurada: contexto, restricciones, output esperado y una rápida “definición de hecho”. Guarda las plantillas donde los ingenieros ya trabajan (carpeta del repo, wiki o sistema de tickets).
Si evalúas una aproximación por plataforma, considera si soporta el ciclo completo: generar código de app, ejecutar tests, desplegar y exportar fuente. Por ejemplo, Koder.ai puede crear apps web, backend y Flutter desde chat, soporta exportación de código fuente y ofrece despliegue/hosting—útil cuando quieres que los prompts vayan más allá de snippets y creen builds reproducibles.
Continuo: añade gobernanza ligera
Mantén la gobernanza simple para que no frene la entrega:
- Asigna un owner claro por plantilla
- Requiere revisión de pares rápida para cambios (como revisión de código)
- Mantén un changelog corto (qué cambió, por qué, impacto observado)
Mes 2: expande con formación y métricas compartidas
Haz sesiones internas de 30 minutos donde los equipos demuestren un prompt que haya ayudado de manera medible. Mide un par de métricas (reducción de tiempo de ciclo, menos comentarios en reviews, mejoras en cobertura de tests) y retira plantillas que no justifiquen su uso.
Para más patrones y ejemplos, explora /blog. Si evalúas tooling o flujos para soportar equipos a escala, consulta /pricing.
Preguntas frecuentes
¿Qué significa “prompting” en el trabajo de ingeniería real?
Escribir entradas revisables que orientan a un asistente hacia un resultado específico y verificable —como un ticket, una especificación o un plan de pruebas. La clave es que la salida se pueda evaluar frente a restricciones y criterios de aceptación explícitos, no solo que “se vea bien”.
¿Qué debe incluir un “buen prompt” para tareas de ingeniería?
Un prompt práctico normalmente incluye:
- Objetivo (qué construir/decidir)
- Restricciones (stack, rendimiento, accesibilidad, límites de la plataforma)
- Contexto (patrones existentes, límites, convenciones de nombres)
- Ejemplos (entradas/salidas, casos límite, no-ejemplos)
- Criterios de aceptación (pruebas, comportamientos esperados, pasos de verificación)
Si no puedes escribir un par de casos de prueba a partir del prompt, probablemente todavía es demasiado vago.
¿Cómo conviertes una petición vaga en un prompt comprobable?
Los prompts vagos obligan al modelo a adivinar tus reglas de producto, sistema de diseño y semántica de errores. Convierte peticiones en requisitos:
- Indica entradas y salidas
- Enumera casos límite (datos inválidos, timeouts, estados vacíos)
- Define cómo verificar (tests unitarios, stories, códigos de estado)
Ejemplo: especifica qué ocurre con un , qué campos son inmutables y qué texto de UI aparece para cada error.
¿Por qué son tan importantes las restricciones al hacer prompts?
Las restricciones evitan salidas “bonitas pero incorrectas”. Incluye cosas como:
- Stack tecnológico y librerías obligatorias
- Presupuestos de rendimiento (p. ej., objetivos p95, evitar N+1)
- Requisitos de accesibilidad (navegación por teclado, ARIA, nivel WCAG)
- Reglas de compatibilidad (no cambiar props/API pública, preservar clases CSS)
- Convenciones de manejo de errores (retry/backoff, forma del error)
Sin restricciones, el modelo rellenará huecos con suposiciones que podrían no coincidir con tu sistema.
¿Cómo deben diferir los prompts para trabajo frontend/UI?
Especifica requisitos de diseño y calidad desde el inicio:
- Reglas de API del componente (qué componentes del design system usar)
- Estados (default/loading/disabled/error/success)
- Comportamiento responsive (puntos de quiebre, anchos máximos)
- A11y (etiquetas, orden de foco, anuncios de error)
- Artefactos de verificación (stories de Storybook, tests)
Esto reduce la deriva respecto al sistema de diseño y agiliza las revisiones al dejar “hecho” explícito.
¿Qué hace fuerte a un prompt de backend/API?
Exige un contrato revisable en lugar de solo código:
- Endpoints (método + ruta) y nombres de recursos
- Esquemas de request/response (requeridos vs opcionales)
- Códigos de estado y semántica de errores (400/401/403/404/409/422/429)
- Estrategia de paginación/filtrado
- Reglas de idempotencia y scope por tenant
Pide tests que cubran payloads inválidos, fallos de auth y casos límite como actualizaciones vacías.
¿Cómo se promptea de forma eficaz para desarrollo móvil?
Incluye restricciones reales de dispositivo y modos de fallo:
- Comportamiento offline (qué datos se cachean, invalidación, UI “stale but usable”)
- Variabilidad de red (timeouts, retry/backoff, backgrounding durante una petición)
- Impacto en batería (cuándo iniciar/detener trabajo en segundo plano)
- Restauración de estado y navegación (rotación, deep links, muerte del proceso)
- Revisiones de accesibilidad específicas de la plataforma
Los prompts para móvil deben describir flujos y rutas de recuperación, no solo el happy path.
¿Cuándo pedir razonamiento paso a paso vs salida directa?
Usa salida directa cuando la tarea está bien definida (p. ej., “genera un tipo TypeScript + payload de ejemplo”). Pide razonamiento cuando importan las decisiones (paginación, límites de caché, diagnóstico de tests inestables).
Un punto medio práctico: solicita una breve lista de suposiciones y pros/contras, y luego el entregable final (código/contrato/tests).
¿Qué son los “contratos de prompt” y por qué son útiles?
Solicita una salida estructurada y validable para que los resultados sean fáciles de revisar y comparar, por ejemplo:
- JSON con
changes,assumptions,risks,tests - Un patch/diff por archivo con un resumen corto
- Una checklist de pasos de verificación
Las salidas estructuradas reducen la ambigüedad, hacen visibles las regresiones y permiten validación por esquemas en CI.
¿Cómo gestionas riesgos de seguridad y privacidad con ingeniería asistida por IA?
Usa prompts y flujos que reduzcan fugas y salidas riesgosas:
- Nunca pegues secretos o datos de clientes; usa placeholders y plantillas de redacción
- Pide al modelo que liste suposiciones y solicite inputs faltantes
- Exige una revisión de seguridad del código generado (auth, inyecciones, defaults inseguros)
- Haz que áreas sensibles requieran aprobación humana (auth, pagos, cambios en BD prod)
- Añade verificación: tests, análisis estático, build/run checks