04 jun 2025·8 min
Por qué la escalabilidad horizontal es más difícil que la vertical
Escalar verticalmente suele ser solo añadir CPU/RAM. Escalar horizontalmente requiere coordinación, particionado, consistencia y más trabajo operativo—aquí explico por qué es más difícil.
Escalar en lenguaje sencillo
Escalar significa “manejar más sin caerse”. Ese “más” puede ser:
- Más usuarios usando el producto al mismo tiempo
- Más peticiones API por segundo
- Más datos almacenados y consultados
- Más trabajo en background (emails, procesado de video, informes) ejecutándose detrás de escena
Cuando la gente habla de escalado, normalmente intenta mejorar una o más de estas cosas:
- Capacidad: cuánto tráfico o datos puede manejar el sistema.
- Velocidad: qué tan rápido responde bajo carga.
- Fiabilidad: qué tan bien sigue funcionando cuando algo se rompe.
Casi todo esto se reduce a un tema: escalar verticalmente mantiene la sensación de “un único sistema”, mientras que escalar horizontalmente convierte tu sistema en un grupo coordinado de máquinas independientes—y esa coordinación es donde la dificultad explota.
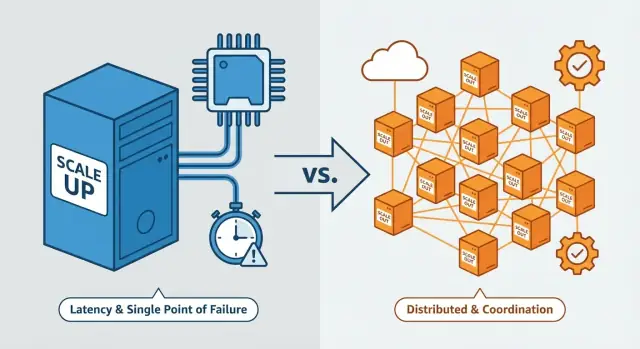
Escala vertical vs. escala horizontal (definiciones rápidas)
Escalado vertical (scale up)
Escalar verticalmente significa hacer una máquina más potente. Mantienes la misma arquitectura básica, pero actualizas el servidor (o VM): más núcleos CPU, más RAM, discos más rápidos, mayor throughput de red.
Piénsalo como comprar un camión más grande: sigues teniendo un conductor y un vehículo, solo que carga más.
Escalado horizontal (scale out)
Escalar horizontalmente significa añadir más máquinas o instancias y repartir el trabajo entre ellas—a menudo detrás de un balanceador de carga. En vez de un servidor más potente, ejecutas varios servidores que trabajan juntos.
Es como usar más camiones: puedes mover más carga en total, pero ahora debes ocuparte de la programación, la ruta y la coordinación.
¿Qué suele forzar la decisión?
Desencadenantes comunes incluyen:
- Picos de tráfico (campañas de marketing, estacionalidad, crecimiento viral)
- Crecimiento sostenido del producto durante meses o años
- Conjuntos de datos más grandes (más clientes, más eventos, más historial que almacenar)
Una matización importante: la mayoría de los sistemas reales usan ambos
Los equipos suelen escalar verticalmente primero porque es rápido (actualizar la máquina), y luego escalan horizontalmente cuando una sola máquina alcanza límites o cuando necesitan mayor disponibilidad. Las arquitecturas maduras suelen mezclar ambos: nodos más grandes y más nodos, según el cuello de botella.
Por qué escalar verticalmente parece más sencillo
La escalabilidad vertical atrae porque mantiene tu sistema en un solo lugar. Con un único nodo, típicamente hay una única fuente de verdad para la memoria y el estado local. Un proceso posee la caché en memoria, la cola de trabajos, la sesión (si las sesiones están en memoria) y los archivos temporales.
Menos piezas móviles
En un servidor, muchas operaciones son sencillas porque hay poca o ninguna coordinación entre nodos:
- Depurar es más fácil porque logs y métricas suelen estar en un sitio.
- Las fallas son más claras: o la máquina está sana o no.
- Muchos cuellos de botella son locales y medibles.
La optimización de rendimiento permanece “local”
Al escalar verticalmente, tiras de palancas familiares: añadir CPU/RAM, usar almacenamiento más rápido, mejorar índices, afinar consultas y configuraciones. No tienes que rediseñar cómo se distribuyen los datos o cómo varios nodos acuerdan “qué ocurre después”.
Las compensaciones que aceptas
Escalar verticalmente no es “gratis”—solo mantiene la complejidad contenida.
Eventualmente alcanzas límites: la instancia más grande que puedes alquilar, rendimientos decrecientes o una curva de coste pronunciada. También puedes asumir mayor riesgo de downtime: si la única máquina grande falla o necesita mantenimiento, gran parte del sistema cae a menos que hayas añadido redundancia.
Sobrecarga de coordinación: más nodos, más reglas
Al escalar horizontalmente, no solo obtienes “más servidores”. Obtienes más actores independientes que deben acordar quién es responsable de cada trabajo, en qué momento y usando qué datos.
Con una máquina, la coordinación suele ser implícita: un espacio de memoria, un proceso, un lugar donde mirar el estado. Con muchas máquinas, la coordinación se convierte en una característica que debes diseñar.
Cómo se ve la coordinación en la práctica
Herramientas y patrones comunes incluyen:
- Elección de líder: escoger un nodo para tomar decisiones (por ejemplo, qué worker procesa el siguiente trabajo). Si el líder muere, todos deben ponerse de acuerdo en un reemplazo.
- Locks/leases: asegurar que solo un nodo realice una tarea a la vez (por ejemplo, enviar una factura o ejecutar una migración). Los leases expiran, los relojes se desincronizan y “quién tiene el lock” se complica.
- Sistemas de consenso: un pequeño grupo de nodos mantiene una vista acordada del estado crítico (configuración, miembros, liderazgo). Son potentes, pero operativamente exigentes.
Síntomas cuando la coordinación falla
Los bugs de coordinación rara vez parecen caídas limpias. Con frecuencia verás:
- Condiciones de carrera: dos nodos actúan sobre los mismos datos en el orden equivocado.
- Trabajo duplicado: el mismo trabajo se ejecuta dos veces porque dos workers pensaron que estaba sin reclamar.
- Split brain: un fallo de red crea dos “líderes”, cada uno tomando decisiones conflictivas.
Estos problemas suelen aparecer solo bajo carga real, durante despliegues o cuando ocurren fallos parciales (un nodo va lento, un switch pierde paquetes, una zona hace un breve parpadeo). El sistema parece bien… hasta que se estresa.
Particionado de datos y sharding: difíciles de clavar
Al escalar horizontalmente, a menudo no puedes mantener todos los datos en un solo lugar. Los repartes entre máquinas (shards) para que varias puedan almacenar y servir peticiones en paralelo. Ese reparto es donde empieza la complejidad: cada lectura y escritura depende de “¿qué shard contiene este registro?”.
Estrategias comunes: rango vs. hash
Particionado por rango agrupa datos por una clave ordenada (por ejemplo, usuarios A–F en shard 1, G–M en shard 2). Es intuitivo y admite bien consultas por rango (“mostrar pedidos de la semana pasada”). La desventaja es la carga desigual: si un rango se pone popular, ese shard se convierte en cuello de botella.
Particionado por hash aplica una función hash a la clave y distribuye los resultados entre shards. Reparte la carga más uniformemente, pero complica las consultas por rango porque registros relacionados quedan dispersos.
Reequilibrar no es gratis
Añades un nodo y quieres usarlo—eso significa que parte de los datos debe moverse. Quitas un nodo (planificado o por fallo) y otros shards deben asumir su carga. Rebalancear puede generar transferencias grandes, calentamiento de cachés y caídas temporales de rendimiento. Durante el movimiento también debes prevenir lecturas obsoletas y escrituras mal enroutadas.
Particiones calientes y sesgos
Incluso con hash, el tráfico real no es uniforme. Una cuenta de celebrity, un producto popular o patrones de acceso por tiempo pueden concentrar lecturas/escrituras en un shard. Un shard caliente puede limitar el throughput de todo el sistema.
Trabajo operativo que no puedes ignorar
El sharding introduce responsabilidades permanentes: mantener reglas de enrutamiento, ejecutar migraciones, realizar backfills tras cambios de esquema y planear splits/merges sin romper clientes.
Estado: sesiones, cachés y trabajo en background
Prototipa la siguiente versión
Levanta una app React con backend en Go y PostgreSQL desde un chat sencillo.
Al escalar horizontalmente, no solo añades servidores: añades más copias de tu aplicación. La parte difícil es el estado: cualquier cosa que tu app “recuerde” entre peticiones o mientras el trabajo está en curso.
Sesiones: ¿dónde vive el login?
Si un usuario se autentica en el Servidor A pero su siguiente petición llega al Servidor B, ¿sabe B quién es?
- Sesiones pegajosas: el usuario sigue siendo enviado al mismo servidor. Simple, pero frágil: reinicios y carga desigual se vuelven visibles para el usuario.
- Un almacenamiento de sesiones compartido (Redis o base de datos) permite que cualquier servidor atienda cualquier petición. Más robusto—pero añade coste y una dependencia. Si el store de sesiones va lento, toda la app se siente lenta.
Cachés: rápidos hasta que discrepan
Las cachés aceleran, pero múltiples servidores significan múltiples cachés. Ahora lidias con:
- Invalidación: cuando los datos cambian, ¿cómo evitas que todas las cachés sigan sirviendo el valor antiguo?
- Coherencia: los nodos pueden discrepar sobre qué es “verdadero” durante ventanas cortas.
- Tasas de acierto desiguales: un servidor está caliente y otro frío, produciendo rendimiento inconsistente.
Trabajo en background: evitar procesar dos veces
Con muchos workers, los jobs en background pueden ejecutarse dos veces a menos que lo diseñes para evitarlo. Normalmente necesitas una cola, locks/leases o lógica idempotente para que “enviar factura” o “cobrar tarjeta” no ocurra dos veces—especialmente durante reintentos y reinicios.
La consistencia y la concurrencia se multiplican
Con un solo nodo (o una DB primaria), suele haber una fuente de verdad clara. Al escalar, los datos y las peticiones se reparten entre máquinas, y mantener a todos sincronizados se vuelve una preocupación constante.
Consistencia fuerte vs. eventual (en palabras sencillas)
- Consistencia fuerte: una vez que una escritura tiene éxito, todos los lectores ven el último valor inmediatamente.
- Consistencia eventual: las actualizaciones se propagan, pero por una ventana corta algunos lectores pueden ver valores antiguos.
La consistencia eventual suele ser más rápida y barata a escala, pero introduce casos límite sorprendentes.
Qué falla en sistemas reales
Problemas comunes:
- Lecturas obsoletas: un usuario actualiza su dirección, refresca y todavía ve la antigua.
- Conflictos de escritura: dos actualizaciones casi simultáneas se sobreescriben.
- Pérdida de actualizaciones: “el último en escribir gana” descarta silenciosamente un cambio que debería haberse combinado.
Patrones que reducen el daño
No puedes eliminar fallos, pero puedes diseñar para ellos:
- Claves de idempotencia: reintentos de “crear pago” no duplican cargos.
- Reintentos con backoff: reintentar tras 200 ms, luego 400 ms, luego 800 ms (con jitter) para evitar estampidas.
- Desduplicación: cuando los mensajes llegan dos veces, procésealos una sola vez.
Por qué las transacciones distribuidas son complicadas
Una transacción entre servicios (pedido + inventario + pago) requiere que múltiples sistemas estén de acuerdo. Si un paso falla a mitad, necesitas acciones compensatorias y contabilidad cuidadosa. El comportamiento clásico de “todo o nada” es difícil cuando redes y nodos fallan independientemente.
Dónde importa la consistencia fuerte
Usa consistencia fuerte para cosas que deben ser correctas: pagos, saldos de cuentas, recuentos de inventario, reservas de plazas. Para datos menos críticos (analítica, recomendaciones), la consistencia eventual suele ser aceptable.
Red: latencia, timeouts y reintentos
Al escalar verticalmente muchas llamadas son llamadas de función en el mismo proceso: rápidas y previsibles. Al escalar horizontalmente, la misma interacción se convierte en una llamada de red—añadiendo latencia, jitter y modos de fallo que tu código debe manejar.
La latencia no es solo “un poco más lenta”
Las llamadas de red tienen coste fijo (serialización, colas, saltos) y coste variable (congestión, enrutamiento, vecinos ruidosos). Aunque la latencia media esté bien, la latencia en la cola alta (el 1–5% más lento) puede dominar la experiencia del usuario porque una dependencia lenta frena toda la petición.
El ancho de banda y la pérdida de paquetes también son restricciones: a altas tasas de petición, los pequeños payloads suman y las retransmisiones aumentan silenciosamente la carga.
Timeouts, reintentos y tormentas de reintentos
Sin timeouts, las llamadas lentas se acumulan y los hilos quedan bloqueados. Con timeouts y reintentos, puedes recuperarte—hasta que los reintentos amplifican la carga.
Un patrón de fallo común es la tormenta de reintentos: un backend se enlentece, los clientes hacen timeout y reintentan, los reintentos aumentan la carga y el backend se hace aún más lento.
Reintentos más seguros generalmente requieren:
- timeouts conservadores basados en datos reales de latencia
- reintentos limitados (a menudo 0–1) con retroceso exponencial y jitter
- reglas claras sobre qué es seguro reintentar (operaciones idempotentes)
Balanceadores y descubrimiento de servicio
Con múltiples instancias, los clientes necesitan saber dónde enviar peticiones—vía un balanceador o descubrimiento de servicio con balanceo del lado cliente. De cualquier forma, añades piezas móviles: health checks, drenado de conexiones, distribución desigual de tráfico y el riesgo de enrutar a una instancia medio rota.
Backpressure y rate limiting
Para evitar que la sobrecarga se propague, necesitas backpressure: colas acotadas, circuit breakers y limitación de tasa. El objetivo es fallar rápido y de forma predecible en lugar de dejar que una pequeña lentitud se convierta en un incidente de sistema entero.
Los modos de fallo cambian: el fallo parcial se vuelve normal
Explora el escalado horizontal con seguridad
Prueba patrones sin estado y ideas de estado compartido sin tener que construir toda la canalización.
Escalar verticalmente tiende a fallar de forma más directa: una máquina más grande sigue siendo un punto único. Si se enlentece o cae, el impacto es evidente.
Escalar horizontalmente cambia la matemática. Con muchos nodos es normal que algunas máquinas estén poco saludables mientras otras están bien. El sistema está “arriba”, pero los usuarios aún ven errores, páginas lentas o comportamiento inconsistente. Esto es fallo parcial, y se vuelve el estado por defecto para el que debes diseñar.
Cómo el fallo parcial se convierte en fallos en cascada
En un entorno distribuido, los servicios dependen de otros: bases de datos, cachés, colas, APIs downstream. Un pequeño problema puede propagarse:
- Un nodo no alcanza la base de datos → reintenta agresivamente
- Los reintentos aumentan la carga en la BD → la latencia sube para todos
- Más latencia provoca más timeouts → más reintentos → más carga
- Las colas se acumulan, las cachés fallan y las APIs downstream son golpeadas
La redundancia ayuda, pero añade reglas
Para sobrevivir a fallos parciales, los sistemas añaden redundancia:
- Replicación: múltiples copias de datos o servicios
- Quórums: “éxito solo si N de M réplicas acuerdan”
- Despliegues multi-zona: repartir para que la caída de una zona no lo lleve todo abajo
Esto aumenta la disponibilidad, pero introduce casos límite: split-brain, réplicas obsoletas y decisiones sobre qué hacer cuando no hay quórum.
Herramientas de resiliencia que acabarás necesitando
Patrones comunes:
- Circuit breakers para dejar de llamar a una dependencia que falla
- Bulkheads para aislar fallos y que un componente ruidoso no hunda todo
- Degradación elegante para ofrecer una experiencia más simple en lugar de errores duros
Observabilidad y depuración entre muchas máquinas
Con una sola máquina, la “historia del sistema” vive en un sitio: un conjunto de logs, un gráfico de CPU, un proceso para inspeccionar. Con escala horizontal, la historia está dispersa.
Más máquinas, más contexto perdido
Cada nodo añade otra corriente de logs, métricas y trazas. Lo difícil no es recoger datos, es correlacionarlos. Un error en checkout puede empezar en un nodo web, llamar a dos servicios, golpear una caché y leer de un shard específico, dejando pistas en distintos lugares y momentos.
Los problemas también se vuelven selectivos: un nodo tiene mala configuración, un shard está caliente, una zona tiene más latencia. Depurar puede parecer aleatorio porque “funciona bien” la mayoría del tiempo.
Trazado y IDs de correlación (en palabras sencillas)
El trazado distribuido es como poner un número de seguimiento a una petición. Un ID de correlación es ese número. Lo pasas entre servicios y lo incluyes en logs para que puedas buscar un ID y ver el viaje completo de extremo a extremo.
Alertas que ayudan en lugar de abrumar
Más componentes suele significar más alertas. Sin afinarlas, los equipos sufren fatiga de alertas. Apunta a alertas accionables que aclaren:
- qué está roto
- quién está afectado
- qué comprobar primero
Vigila la saturación, no solo los errores
Los problemas de capacidad a menudo aparecen antes que los fallos. Monitoriza señales de saturación como CPU, memoria, profundidad de colas y uso de pools de conexión. Si la saturación aparece solo en un subconjunto de nodos, sospecha de balanceo, sharding o deriva de configuración, no solo “más tráfico”.
Despliegues, upgrades y rollbacks se vuelven más arriesgados
Al escalar horizontalmente, un deploy ya no es “reemplazar una caja”. Es coordinar cambios en muchas máquinas manteniendo el servicio disponible.
Rolling updates, canarios y blue/green
Los despliegues horizontales suelen usar rolling updates (reemplazar nodos gradualmente), canarios (enviar un pequeño porcentaje de tráfico a la nueva versión) o blue/green (cambiar tráfico entre dos entornos completos). Reducen el radio de blast, pero añaden requisitos: cambio de tráfico, health checks, drenado de conexiones y una definición de “suficientemente bueno para continuar”.
Skew de versiones es la norma
Durante cualquier despliegue gradual, conviven versiones viejas y nuevas. Ese desajuste significa que el sistema debe tolerar comportamiento mixto:
- nuevos nodos llamando a nodos viejos (y viceversa)
- clientes viejos golpeando servidores nuevos
- diferentes formatos de caché o payloads de jobs en vuelo
Compatibilidad se convierte en requisito
Las APIs necesitan compatibilidad hacia atrás/adelante, no solo corrección. Los cambios de esquema en BD deben ser aditivos cuando sea posible (añadir columnas nullable antes de hacerlas obligatorias). Los formatos de mensajes deben versionarse para que consumidores lean eventos viejos y nuevos.
Los rollbacks son complicados con migraciones de datos
Hacer rollback de código es fácil; hacer rollback de datos no lo es. Si una migración borra o reescribe campos, el código antiguo puede fallar o manejar mal registros. Las migraciones “expandir/contraer” ayudan: despliega código que soporte ambos esquemas, migra datos y después elimina caminos antiguos.
Config y secretos deben ser consistentes
Con muchos nodos, la gestión de configuración forma parte del deploy. Un único nodo con config obsoleta, flags mal puestas o credenciales expiradas puede crear fallos intermitentes y difíciles de reproducir.
Coste y complejidad del equipo suelen subir con el scale out
Haz los rollbacks rutinarios
Captura un punto estable antes de cambios importantes y vuelve atrás rápido si es necesario.
Escalar horizontalmente puede parecer más barato en papel: muchas instancias pequeñas, cada una con precio horario bajo. Pero el coste total no es solo compute. Añadir nodos también implica más red, más monitorización, más coordinación y más tiempo manteniendo la coherencia.
Pocas máquinas grandes vs. muchas instancias pequeñas
Escalar verticalmente concentra el gasto en menos máquinas—a menudo menos hosts que parchear, menos agentes que ejecutar, menos logs que enviar, menos métricas que raspar.
Con el scale out, el precio por unidad puede ser menor, pero a menudo pagas por:
- balanceadores, descubrimiento de servicio y ancho de banda extra
- más réplicas para cumplir objetivos de rendimiento y disponibilidad
- mayor capacidad base porque necesitas margen en muchos sitios, no solo en uno
Utilización y sobreaprovisionamiento
Para manejar picos con seguridad, los sistemas distribuidos suelen correr con capacidad infrautilizada. Mantienes espacio en múltiples capas (web, workers, BD, cachés), lo que puede significar pagar por capacidad ociosa en docenas o cientos de instancias.
Coste operativo: el multiplicador oculto
El scale out aumenta la carga on-call y exige tooling maduro: afinado de alertas, runbooks, simulacros de incidentes y formación. Los equipos también dedican tiempo a límites de propiedad (quién posee qué servicio) y coordinación en incidentes.
El resultado: “más barato por unidad” puede salir más caro al contar tiempo de personas, riesgo operativo y trabajo necesario para hacer que muchas máquinas se comporten como un sistema coherente.
Elegir el camino correcto: cuándo escalar verticalmente vs. horizontalmente
La decisión no es solo precio. Es forma de la carga de trabajo y cuánta complejidad operativa puede absorber tu equipo.
Criterios de decisión que realmente importan
Empieza por la carga de trabajo:
- Tipo de trabajo: tareas vinculadas a CPU suelen beneficiarse de scale up; tráfico web con muchas peticiones suele beneficiarse de scale out detrás de un balanceador.
- Estado: si las peticiones dependen de estado local (sesiones, cachés, trabajo en curso), scale out te obliga a rediseñar dónde vive ese estado.
- Necesidades de consistencia: si la corrección es estricta (pagos, inventario), scale out introduce trade-offs más difíciles en concurrencia y consistencia.
- Tasa de crecimiento y picos: crecimiento predecible puede resolverse escalando verticalmente en pasos; picos impredecibles pueden empujarte hacia capacidad horizontal.
Una progresión práctica (que ahorra tiempo)
Un camino común y sensato:
- Optimiza cuellos de botella obvios (consultas lentas, índices faltantes, endpoints ineficientes).
- Escala verticalmente primero (VM/instancia DB más grande), porque cambia menos suposiciones.
- Escala horizontalmente una vez que una sola máquina es realmente el factor limitante—o cuando necesitas disponibilidad que una máquina no puede ofrecer.
Los patrones híbridos son normales
Muchos equipos mantienen la base de datos vertical (o levemente clusterizada) mientras escalan horizontalmente la capa de app sin estado. Esto limita el dolor del sharding mientras permite añadir capacidad web con rapidez.
Señales de “listo” para escalar horizontalmente
Estás más cerca cuando tienes monitorización y alertas sólidas, failover probado, pruebas de carga y despliegues repetibles con rollbacks seguros.
Preguntas para hacer antes de comprometerse
- ¿Podemos cumplir los objetivos optimizando o escalando verticalmente los próximos 6–12 meses?
- ¿Dónde vivirán sesiones, cachés y trabajos en background?
- ¿Necesitamos consistencia fuerte y qué fallos son aceptables?
- ¿Cuál es nuestro plan de particionado de datos (si lo hay) y de reequilibrado?
- ¿Tenemos herramientas para depurar problemas entre múltiples nodos?
Dónde encaja Koder.ai (ayuda práctica sin reinventar todo)
Mucho del dolor de escalar no es solo arquitectura: es el bucle operativo: iterar con seguridad, desplegar con fiabilidad y revertir rápido cuando la realidad contradice el plan.
Si estás construyendo sistemas web, backend o móviles y quieres avanzar rápido sin perder control, Koder.ai puede ayudarte a prototipar y enviar cambios más rápido mientras tomas decisiones de escala. Es una plataforma de "vibe-coding" donde construyes aplicaciones a través de chat, con una arquitectura basada en agentes bajo el capó. En la práctica eso significa que puedes:
- Levantar rápidamente una app React, un backend Go + PostgreSQL o una app Flutter, y luego iterar conforme descubres cuellos de botella.
- Usar el modo de planificación para pensar cambios de “scale up vs. scale out” antes de implementarlos.
- Reducir el riesgo de despliegue con snapshots y rollback, algo que importa más a medida que añades nodos y el desajuste de versiones se vuelve habitual.
- Exportar el código fuente cuando estés listo para moverte a tu propia pipeline y desplegar/hostear con dominios personalizados.
Como Koder.ai corre globalmente en AWS, también puede soportar despliegues en diferentes regiones para cumplir restricciones de latencia y transferencia de datos—útil cuando la disponibilidad multi-zona o multi-región forma parte de tu historia de escalado.
Preguntas frecuentes
¿Cuál es la diferencia entre escalabilidad vertical y escalabilidad horizontal?
La escalabilidad vertical significa hacer más potente una sola máquina (más CPU/RAM/disco más rápido). La escalabilidad horizontal significa añadir más máquinas y repartir el trabajo entre ellas.
La vertical suele parecer más simple porque tu aplicación sigue comportándose como “un único sistema”, mientras que la horizontal obliga a varios sistemas a coordinarse y mantenerse consistentes.
¿Por qué la escalabilidad horizontal introduce más complejidad que la vertical?
Porque en cuanto aparecen múltiples nodos hace falta coordinación explícita:
- decidir quién maneja cada tarea
- evitar el procesamiento duplicado
- gestionar latencias de red y fallos parciales
Una sola máquina evita muchos de estos problemas de sistemas distribuidos de forma implícita.
¿Qué es la “sobrecarga de coordinación” en un sistema escalado horizontalmente?
Es el tiempo y la lógica necesarios para lograr que varias máquinas se comporten como una sola:
- elección de líder y reglas de failover
- locks/leases y problemas por deriva de relojes
- evitar situaciones de split-brain
Aunque cada nodo sea simple, el comportamiento del sistema se vuelve difícil de razonar bajo carga y fallos.
¿Por qué son tan difíciles de acertar el sharding y el particionado de datos?
El sharding (particionado) divide los datos entre nodos para que ninguna máquina tenga que almacenar/servir todo. Es difícil porque debes:
- enrutar cada lectura/escritura al shard correcto
- reequilibrar datos al añadir o quitar capacidad
- gestionar particiones calientes que se convierten en cuellos de botella
Además aumenta el trabajo operativo (migraciones, backfills, mapas de shards).
¿Qué significa “estado” y por qué importa para escalar horizontalmente?
Estado es todo lo que tu app “recuerda” entre peticiones o mientras trabaja (sesiones, cachés en memoria, ficheros temporales, progreso de trabajos).
Con escala horizontal, las peticiones pueden aterrizar en distintos servidores, así que necesitas un estado compartido (por ejemplo Redis/BD) o aceptas compensaciones como sesiones pegajosas.
¿Cómo evitas que los trabajos en background se ejecuten dos veces al escalar?
Si varios workers pueden tomar el mismo trabajo (o hay reintentos), puedes acabar facturando dos veces o enviando correos duplicados.
Mitigaciones comunes:
- manejadores idempotentes
- locks/leases alrededor de la reclamación de trabajos
- deduplicación con IDs únicos de trabajo
- políticas de reintento cuidadosas con backoff
¿Cuál es la diferencia práctica entre consistencia fuerte y eventual?
La consistencia fuerte significa que una vez que una escritura tiene éxito, todos los lectores ven inmediatamente el último valor. La consistencia eventual significa que las actualizaciones se propagan con el tiempo, así que algunos lectores pueden ver datos antiguos durante una ventana breve.
Usa consistencia fuerte para datos críticos (pagos, saldos, inventario). Para datos menos críticos (analítica, recomendaciones) la eventual suele ser aceptable.
¿Por qué los timeouts y reintentos son más importantes con la escalabilidad horizontal?
En un sistema distribuido las llamadas se convierten en llamadas de red, que añaden latencia, jitter y modos de fallo.
Lo esencial:
- poner timeouts para que las peticiones no queden bloqueadas
- limitar reintentos y usar retroceso exponencial + jitter
- reintentar solo operaciones seguras (idempotentes) para evitar efectos duplicados
¿Qué es el “fallo parcial” y por qué es normal a escala?
Fallo parcial significa que algunos componentes están rotos o lentos mientras otros funcionan. El sistema puede estar “activo” pero producir errores, timeouts o comportamiento inconsistente.
Las respuestas de diseño incluyen replicación, quórums, despliegues multi-zona, circuit breakers y degradación gradual para evitar que los fallos se propaguen.
¿Cómo depuras problemas cuando tu app corre en muchos servidores?
Con muchas máquinas, la evidencia del problema está fragmentada: logs, métricas y trazas en nodos distintos.
Pasos prácticos:
- usar IDs de correlación de extremo a extremo
- adoptar trazado distribuido para ver el recorrido de una petición
- alertar sobre señales de saturación (CPU, profundidad de colas, pools de conexión), no solo sobre errores