02 sept 2025·8 min
Protobuf vs JSON para APIs: velocidad, tamaño y compatibilidad
Compara Protobuf y JSON para APIs: tamaño de payload, velocidad, legibilidad, herramientas, versionado y cuándo usar cada formato en productos reales.
Compara Protobuf y JSON para APIs: tamaño de payload, velocidad, legibilidad, herramientas, versionado y cuándo usar cada formato en productos reales.
Cuando tu API envía o recibe datos, necesita un formato de datos: una manera estandarizada de representar la información en los cuerpos de petición y respuesta. Ese formato se serializa (se convierte en bytes) para transportarlo por la red, y se deserializa de nuevo en objetos utilizables en cliente y servidor.
Dos de las opciones más comunes son JSON y Protocol Buffers (Protobuf). Pueden representar los mismos datos de negocio (usuarios, órdenes, timestamps, listas de ítems), pero hacen diferentes concesiones en rendimiento, tamaño de la carga y flujo de trabajo del desarrollador.
JSON (JavaScript Object Notation) es un formato basado en texto construido con estructuras simples como objetos y arrays. Es popular en APIs REST porque es fácil de leer, fácil de registrar y fácil de inspeccionar con herramientas como curl y las DevTools del navegador.
Una gran razón por la que JSON está en todas partes: la mayoría de lenguajes tienen excelente soporte, y puedes inspeccionar visualmente una respuesta y entenderla de inmediato.
Protobuf es un formato de serialización binaria creado por Google. En lugar de enviar texto, envía una representación binaria compacta definida por un esquema (un archivo .proto). El esquema describe los campos, sus tipos y sus etiquetas numéricas.
Porque es binario y guiado por esquema, Protobuf suele producir cargas útiles más pequeñas y puede ser más rápido de parsear—lo que importa cuando tienes volúmenes altos de peticiones, redes móviles o servicios sensibles a la latencia (común en setups gRPC, aunque no limitado a gRPC).
Es importante separar qué estás enviando de cómo se codifica. Un “usuario” con id, nombre y email puede modelarse tanto en JSON como en Protobuf. La diferencia es el coste que pagas en:
No hay una respuesta única. Para muchas APIs públicas, JSON sigue siendo el valor por defecto por accesibilidad y flexibilidad. Para comunicación interna entre servicios, sistemas sensibles al rendimiento o contratos estrictos, Protobuf puede encajar mejor. El objetivo de esta guía es ayudarte a elegir según restricciones—no por ideología.
Cuando una API devuelve datos, no puede enviar “objetos” directamente por la red. Tiene que convertirlos primero a una secuencia de bytes. Esa conversión es la serialización—piénsalo como empaquetar datos en una forma transportable. En el otro extremo, el cliente hace la operación inversa (deserialización), desempaquetando los bytes de nuevo en estructuras de datos.
Un flujo típico de petición/respuesta se ve así:
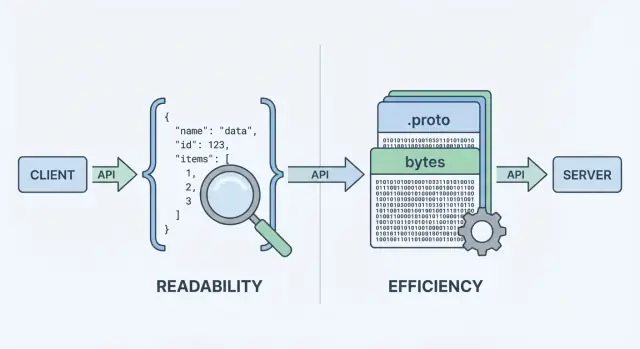
Ese paso de “codificación” es donde la elección del formato importa. La codificación JSON produce texto legible como {"id":123,"name":"Ava"}. La codificación Protobuf produce bytes binarios compactos que no son significativos para humanos sin herramientas.
Porque cada respuesta debe empaquetarse y desempaquetarse, el formato influye en:
Tu estilo de API a menudo inclina la decisión:
curl y simple de registrar e inspeccionar.Puedes usar JSON con gRPC (vía transcoding) o usar Protobuf sobre HTTP plano, pero la ergonomía por defecto de tu stack—frameworks, gateways, librerías cliente y hábitos de depuración—a menudo decidirá qué es más fácil de mantener día a día.
Cuando la gente compara protobuf vs json, normalmente empieza con dos métricas: cuán grande es la carga y cuánto tarda en codificarse/decodificarse. El titular es simple: JSON es texto y tiende a ser verboso; Protobuf es binario y tiende a ser compacto.
JSON repite nombres de campo y usa representaciones textuales para números, booleanos y estructura, por lo que a menudo envía más bytes por la red. Protobuf reemplaza nombres por etiquetas numéricas y empaqueta valores eficientemente, lo que suele llevar a cargas notoriamente más pequeñas—especialmente para objetos grandes, campos repetidos y datos profundamente anidados.
Dicho esto, la compresión puede cerrar la brecha. Con gzip o brotli, las claves repetidas de JSON se comprimen muy bien, por lo que las diferencias de tamaño entre JSON y Protobuf pueden reducirse en despliegues reales. Protobuf también puede comprimirse, pero la ganancia relativa suele ser menor.
Los parsers de JSON deben tokenizar y validar texto, convertir cadenas en números y lidiar con casos límite (escaping, espacios en blanco, unicode). La decodificación de Protobuf es más directa: leer etiqueta → leer valor tipado. En muchos servicios, Protobuf reduce tiempo de CPU y creación de basura, lo que puede mejorar la latencia en cola bajo carga.
En redes móviles o enlaces de alta latencia, menos bytes típicamente significa transferencias más rápidas y menos tiempo de radio (lo que también puede ayudar la batería). Pero si tus respuestas ya son pequeñas, la sobrecarga del handshake, TLS y el procesamiento del servidor pueden dominar—haciendo que la elección del formato sea menos visible.
Mide con tus cargas representativas:
Esto convierte debates de “serialización de API” en datos confiables para tu API.
La experiencia del desarrollador es donde JSON suele ganar por defecto. Puedes inspeccionar una petición o respuesta JSON casi en cualquier lugar: DevTools del navegador, salida de curl, Postman, proxies reversos y logs en texto plano. Cuando algo falla, “¿qué enviamos realmente?” suele estar a un copiar/pegar de distancia.
Protobuf es diferente: es compacto y estricto, pero no legible. Si registras bytes Protobuf crudos, verás blobs en base64 o binario ilegible. Para entender la carga necesitas el .proto correcto y un decodificador (por ejemplo, protoc, herramientas específicas por lenguaje o los tipos generados del servicio).
Con JSON, reproducir problemas es directo: toma una carga registrada, enmascara secretos, reprodúcela con curl y ya tienes un caso de prueba mínimo.
Con Protobuf, normalmente depurarás capturando la carga binaria (a menudo codificada en base64), decodificándola con la versión correcta del esquema y re-codificándola para reproducir la petición.
Ese paso extra es manejable—pero solo si el equipo tiene un flujo repetible.
El logging estructurado ayuda a ambos formatos. Registra IDs de petición, nombres de método, identificadores de usuario/cuenta y campos clave en lugar de cuerpos completos.
Para Protobuf en particular:
.proto usamos?”.Para JSON, considera registrar JSON canónico (orden estable de claves) para facilitar diffs y líneas temporales de incidentes.
Las APIs no solo mueven datos—mueven significado. La mayor diferencia entre JSON y Protobuf es cuán claramente ese significado está definido y aplicado.
JSON es “sin esquema” por defecto: puedes enviar cualquier objeto con campos cualquiera, y muchos clientes lo aceptarán mientras parezca razonable.
Esa flexibilidad es cómoda al principio, pero también puede ocultar errores. Puntos críticos comunes incluyen:
userId en una respuesta, user_id en otra, o campos faltantes según la ruta de código."42", "true" o "2025-12-23"—fácil de producir, fácil de malinterpretar.null puede significar “desconocido”, “no establecido” o “vacío intencionalmente”, y clientes distintos pueden tratarlo distinto.Puedes añadir JSON Schema u OpenAPI, pero JSON en sí no obliga a los consumidores a seguirlo.
Protobuf requiere un esquema definido en un archivo .proto. Un esquema es un contrato compartido que dice:
Ese contrato ayuda a prevenir cambios accidentales—como convertir un entero en cadena—porque el código generado espera tipos específicos.
Con Protobuf, los números siguen siendo números, los enums están acotados a valores conocidos y los timestamps suelen modelarse con tipos bien conocidos (en lugar de formatos de cadena improvisados). “No establecido” también es más claro: en proto3, la ausencia es distinta de los valores por defecto cuando usas campos optional o tipos wrapper.
Si tu API depende de tipos precisos y parseo predecible entre equipos y lenguajes, Protobuf provee protecciones que JSON suele alcanzar por convención.
Las APIs evolucionan: añades campos, ajustas comportamientos y retiras partes antiguas. La meta es cambiar el contrato sin sorprender a los consumidores.
Una buena estrategia busca ambos, pero la compatibilidad hacia atrás suele ser la mínima aceptable.
En Protobuf, cada campo tiene un número (p. ej., email = 3). Ese número—no el nombre del campo—es lo que va en la red. Los nombres son principalmente para humanos y para el código generado.
Por eso:
Cambios seguros (habitualmente):
Cambios riesgosos (a menudo rompientes):
Mejor práctica: usa reserved para números/nombres antiguos y mantiene un changelog.
JSON no tiene esquema integrado, así que la compatibilidad depende de tus patrones:
Documenta las deprecaciones pronto: cuándo un campo queda deprecado, cuánto tiempo se soportará y qué lo reemplaza. Publica una política de versionado simple (p. ej., “cambios aditivos son no rompientes; remociones requieren una nueva versión mayor”) y cúmplela.
Elegir entre JSON y Protobuf suele reducirse a dónde necesita correr tu API—y qué quiere mantener tu equipo.
JSON es prácticamente universal: cada navegador y runtime backend puede parsearlo sin dependencias extra. En una web app, fetch() + JSON.parse() es el camino feliz, y proxies, gateways y herramientas de observabilidad tienden a “entender” JSON por defecto.
Protobuf también puede ejecutarse en el navegador, pero no es un default sin coste. Normalmente añadirás una librería Protobuf (o código JS/TS generado), gestionarás el tamaño del bundle y decidirás si envías Protobuf sobre endpoints HTTP que tus herramientas de navegador puedan inspeccionar fácilmente.
En iOS/Android y en lenguajes backend (Go, Java, Kotlin, C#, Python, etc.), el soporte de Protobuf está maduro. La gran diferencia es que Protobuf asume que usarás librerías por plataforma y normalmente generarás código desde .proto.
La generación de código trae beneficios reales:
También añade costes:
.proto compartidos, pinning de versiones)Protobuf está estrechamente asociado con gRPC, que te ofrece una historia completa de tooling: definiciones de servicio, stubs cliente, streaming e interceptores. Si consideras gRPC, Protobuf es el ajuste natural.
Si estás construyendo una API REST tradicional en JSON, el ecosistema de JSON (DevTools del navegador, depuración con curl, gateways genéricos) sigue siendo más simple—especialmente para APIs públicas e integraciones rápidas.
Si aún exploras la superficie de la API, ayuda prototipar en ambos estilos antes de estandarizar. Por ejemplo, equipos que usan Koder.ai a menudo levantan rápidamente una API REST JSON para compatibilidad amplia y un servicio interno gRPC/Protobuf para eficiencia, y luego benchmarkean cargas reales antes de decidir qué se vuelve “por defecto”. Dado que Koder.ai puede generar apps full-stack (React en web, Go + PostgreSQL en backend, Flutter en móvil) y soporta modo de planificación más snapshots/rollback, es práctico iterar sobre contratos sin convertir la decisión de formato en una refactorización de largo plazo.
Elegir entre JSON y Protobuf no es solo tamaño de payload o velocidad. También afecta cuán bien encaja tu API con capas de caching, gateways y las herramientas que el equipo usa durante incidentes.
La mayoría de infraestructuras de caching HTTP (caches del navegador, proxies reversos, CDNs) están optimizadas alrededor de semánticas HTTP, no de un formato de cuerpo particular. Un CDN puede cachear cualquier bytes si la respuesta es cacheable.
Dicho eso, muchos equipos esperan HTTP/JSON en el borde porque es fácil de inspeccionar y depurar. Con Protobuf, el caching sigue funcionando, pero deberás ser deliberado sobre:
Vary)Cache-Control, ETag, Last-Modified)Content-Type y Accept)Si soportas JSON y Protobuf, usa negociación de contenido:
Accept: application/json o Accept: application/x-protobufContent-Type correspondienteAsegúrate de que las caches entiendan esto poniendo Vary: Accept. Si no, una cache podría almacenar una respuesta JSON y servirla a un cliente Protobuf (o viceversa).
Gateways API, WAFs, transformadores de petición/respuesta y herramientas de observabilidad a menudo asumen cuerpos JSON para:
El Protobuf binario puede limitar esas funcionalidades a menos que tu tooling entienda Protobuf (o añadas pasos de decodificación).
Un patrón común es JSON en el borde, Protobuf dentro:
Esto mantiene integraciones externas simples y captura los beneficios de rendimiento de Protobuf donde controlas ambos extremos.
Elegir JSON o Protobuf cambia cómo se codifican y parsean los datos—pero no reemplaza requisitos de seguridad como autenticación, cifrado, autorización y validación en servidor. Un serializador rápido no salvará una API que acepte entrada no confiable sin límites.
Puede ser tentador ver a Protobuf como “más seguro” porque es binario y menos legible. Eso no es una estrategia de seguridad. Los atacantes no necesitan que tus payloads sean legibles: solo apuntan al endpoint. Si la API filtra campos sensibles, acepta estados inválidos o tiene auth débil, cambiar de formato no lo arreglará. Cifra el transporte (TLS), aplica checks de autorización, valida entradas y registra de forma segura, sin importar JSON o grpc protobuf.
Ambos formatos comparten riesgos comunes:
Para mantener APIs dependables bajo carga y abuso, aplica los mismos guardarraíles a ambos formatos:
La conclusión: “binario vs texto” afecta principalmente rendimiento y ergonomía. Seguridad y fiabilidad vienen de límites consistentes, dependencias actualizadas y validación explícita—independientemente del serializador.
Elegir entre JSON y Protobuf trata menos de cuál es “mejor” y más de qué necesita optimizar tu API: amabilidad humana y alcance, o eficiencia y contratos estrictos.
JSON suele ser la opción más segura cuando necesitas compatibilidad amplia y depuración sencilla.
Escenarios típicos:
Protobuf suele ganar cuando el rendimiento y la consistencia importan más que la legibilidad humana.
Escenarios típicos:
Usa estas preguntas para reducir la elección:
Si sigues indeciso, la aproximación “JSON en el borde, Protobuf dentro” es a menudo un compromiso práctico.
Migrar formatos es menos reescribir todo y más reducir riesgo para consumidores. Los movimientos más seguros mantienen la API usable durante la transición y facilitan rollback.
Escoge una superficie de bajo riesgo—a menudo una llamada interna entre servicios o un endpoint de solo lectura. Esto te permite validar el esquema Protobuf, clientes generados y cambios en observabilidad sin convertir toda la API en un proyecto de "big bang".
Un primer paso práctico es añadir una representación Protobuf para un recurso existente mientras mantienes la forma JSON sin cambios. Aprenderás rápidamente dónde tu modelo de datos es ambiguo (null vs ausente, números vs cadenas, formatos de fecha) y podrás resolverlo en el esquema.
Para APIs externas, el soporte dual suele ser la vía más suave:
Content-Type y Accept./v2/...) solo si la negociación es difícil con tu tooling.Durante este periodo, asegúrate de que ambos formatos se produzcan desde el mismo modelo fuente para evitar divergencias sutiles.
Planifica para:
Publica archivos .proto, comentarios de campo y ejemplos concretos de request/response (JSON y Protobuf) para que los consumidores verifiquen que interpretan los datos correctamente. Una breve "guía de migración" y un changelog reducen la carga de soporte y acortan el tiempo de adopción.
Elegir entre JSON y Protobuf suele depender de la realidad de tu tráfico, clientes y limitaciones operacionales. El camino más fiable es medir, documentar las decisiones y mantener los cambios aburridos.
Ejecuta un experimento pequeño en endpoints representativos.
Mide:
Haz esto en staging con datos similares a producción y luego valida en producción en una pequeña fracción del tráfico.
Ya uses JSON Schema/OpenAPI o archivos .proto:
Incluso si eliges Protobuf por rendimiento, mantén la documentación amigable:
Si mantienes docs o guías de SDK, enlázalos claramente (por ejemplo: /docs y /blog). Si precios o límites de uso afectan la elección de formato, hazlo visible también (/pricing).
JSON es un formato de texto que es fácil de leer, registrar y probar con herramientas comunes. Protobuf es un formato binario compacto definido por un esquema .proto, que a menudo produce cargas útiles más pequeñas y un análisis más rápido.
Elige según las restricciones: alcance y facilidad de depuración (JSON) frente a eficiencia y contratos estrictos (Protobuf).
Las APIs envían bytes, no objetos en memoria. La serialización codifica tus objetos del servidor en una carga (texto JSON o binario Protobuf) para el transporte; la deserialización decodifica esos bytes de nuevo en objetos del cliente/servidor.
La elección del formato afecta el ancho de banda, la latencia y la CPU usada para codificar/decodificar.
A menudo sí, especialmente con objetos grandes o anidados y campos repetidos, porque Protobuf usa etiquetas numéricas y codificación binaria eficiente.
Sin embargo, si activas gzip/brotli, las claves repetidas de JSON se comprimen muy bien, por lo que la diferencia en tamaño en el mundo real puede reducirse. Mide ambos tamaños: sin comprimir y comprimido.
Puede serlo. El parseo de JSON requiere tokenizar texto, manejar escapado/unicode y convertir cadenas a números. La decodificación de Protobuf es más directa (etiqueta → valor tipado), lo que a menudo reduce tiempo de CPU y asignaciones.
Dicho esto, si las cargas útiles son muy pequeñas, la latencia total puede dominarse por TLS, la RTT de la red y el trabajo de la aplicación en lugar de la serialización.
Lo es por defecto. JSON es legible y fácil de inspeccionar en DevTools, logs, curl y Postman. Las cargas Protobuf son binarias, por lo que normalmente necesitas el .proto correspondiente y herramientas de decodificación.
Una mejora común en el flujo de trabajo es registrar una vista de depuración decodificada y enmascarada (a menudo en JSON) junto con los IDs de petición y campos clave.
JSON es flexible y, por defecto, “sin esquema” a menos que apliques JSON Schema/OpenAPI. Esa flexibilidad puede generar campos inconsistentes, valores “stringly-typed” y semánticas ambiguas de null.
Protobuf aplica tipos mediante un contrato .proto, genera código fuertemente tipado y facilita contratos evolutivos claros, especialmente entre equipos y lenguajes múltiples.
La compatibilidad en Protobuf la determinan los números de campo (tags). Los cambios seguros suelen ser aditivos (añadir campos opcionales con números nuevos). Cambios que rompen incluyen reutilizar números de campo o cambiar tipos de forma incompatible.
En Protobuf, reserva números/nombres eliminados (reserved) y mantiene un registro de cambios. En JSON, prefiere campos aditivos, mantiene tipos estables y trata campos desconocidos como ignorables.
Sí. Usa negociación de contenido:
Accept: application/json o Accept: application/x-protobufContent-Type correspondienteVary: Accept para que las caches no mezclen formatosSi la negociación es difícil con tu tooling, un endpoint/version separado puede ser una táctica de migración temporal.
Depende del entorno:
Considera el coste de mantenimiento del codegen y la versionación compartida del esquema al elegir Protobuf.
Considera ambos formatos como entrada no confiable. La elección de formato no es una capa de seguridad.
Guardarraíles prácticos para ambos:
Mantén los parsers/librerías actualizados para reducir exposición a vulnerabilidades de parsing.