14 oct 2025·8 min
¿Qué es GraphQL? Guía clara para APIs y obtención de datos
Aprende qué es GraphQL, cómo funcionan consultas, mutaciones y esquemas, y cuándo usarlo en lugar de REST—además de ventajas, desventajas y ejemplos prácticos.
Aprende qué es GraphQL, cómo funcionan consultas, mutaciones y esquemas, y cuándo usarlo en lugar de REST—además de ventajas, desventajas y ejemplos prácticos.
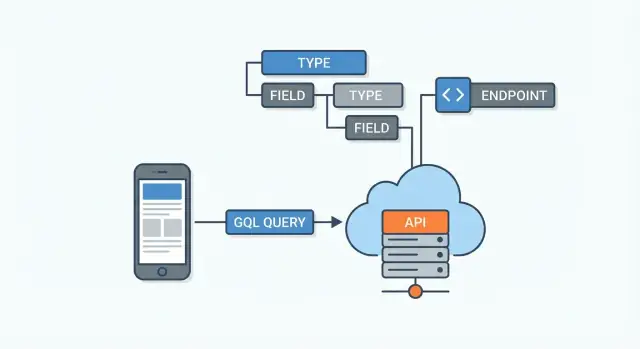
GraphQL es un lenguaje de consultas y un runtime para APIs. En pocas palabras: es la forma en que una app (web, móvil u otro servicio) solicita datos a una API mediante una petición clara y estructurada, y el servidor devuelve una respuesta que coincide con esa petición.
Muchas APIs obligan a los clientes a aceptar lo que devuelve un endpoint fijo. Eso suele provocar dos problemas:
Con GraphQL, el cliente puede solicitar exactamente los campos que necesita, ni más ni menos. Esto es especialmente útil cuando distintas pantallas (o distintas apps) necesitan “rebanadas” diferentes de los mismos datos subyacentes.
GraphQL suele ubicarse entre las apps cliente y tus fuentes de datos. Esas fuentes pueden ser:
El servidor GraphQL recibe una consulta, decide cómo obtener cada campo solicitado desde el lugar adecuado y luego monta la respuesta JSON final.
Piensa en GraphQL como pedir una respuesta con forma personalizada:
GraphQL se malinterpreta con frecuencia, así que unas aclaraciones:
Si mantienes esa definición central—lenguaje de consultas + runtime para APIs—tendrás la base correcta para todo lo demás.
GraphQL nació para resolver un problema práctico de producto: los equipos dedicaban demasiado tiempo a adaptar APIs a pantallas reales.
Las APIs tradicionales basadas en endpoints a menudo obligan a elegir entre enviar datos que no necesitas o hacer llamadas extra para obtener lo que sí necesitas. A medida que los productos crecen, esa fricción se traduce en páginas más lentas, código cliente más complicado y coordinación dolorosa entre frontend y backend.
La sobrelectura ocurre cuando un endpoint devuelve un objeto “completo” aunque una pantalla solo necesite unos pocos campos. Una vista de perfil móvil podría necesitar solo nombre y avatar, pero la API devuelve direcciones, preferencias, campos de auditoría y más. Eso desperdicia ancho de banda y puede afectar la experiencia de usuario.
La sublectura es lo contrario: ningún endpoint único tiene todo lo que una vista necesita, así que el cliente debe hacer varias solicitudes y combinar resultados. Eso añade latencia y aumenta las probabilidades de fallos parciales.
Muchas APIs REST responden al cambio añadiendo nuevos endpoints o versionando (v1, v2, v3). El versionado puede ser necesario, pero crea trabajo de mantenimiento prolongado: clientes antiguos siguen usando versiones viejas mientras las nuevas características se apilan en otro lugar.
El enfoque de GraphQL es evolucionar el esquema añadiendo campos y tipos con el tiempo, manteniendo los campos existentes estables. Eso reduce la presión de crear “nuevas versiones” solo para soportar nuevas necesidades de UI.
Los productos modernos rara vez tienen un solo consumidor. Web, iOS, Android e integraciones de partners necesitan a menudo formas de datos distintas.
GraphQL fue diseñado para que cada cliente pueda solicitar exactamente los campos que necesita—sin que el backend tenga que crear un endpoint separado para cada pantalla o dispositivo.
Una API GraphQL se define por su esquema. Piénsalo como el acuerdo entre el servidor y todos los clientes: lista qué datos existen, cómo están conectados y qué se puede solicitar o cambiar. Los clientes no adivinan endpoints: leen el esquema y piden campos específicos.
El esquema está compuesto por tipos (como User o Post) y campos (como name o title). Los campos pueden apuntar a otros tipos, que es la forma en que GraphQL modela relaciones.
Aquí hay un ejemplo sencillo en Schema Definition Language (SDL):
type User {
id: ID!
name: String!
posts: [Post!]!
}
type Post {
id: ID!
title: String!
body: String
author: User!
comments: [Comment!]!
}
type Comment {
id: ID!
text: String!
author: User!
post: Post!
}
Debido a que el esquema es fuertemente tipado, GraphQL puede validar una petición antes de ejecutarla. Si un cliente pide un campo que no existe (por ejemplo, Post.publishDate cuando el esquema no tiene tal campo), el servidor puede rechazar o cumplir parcialmente la solicitud con errores claros—sin un comportamiento ambiguo de “tal vez funciona”.
Los esquemas están diseñados para crecer. Normalmente puedes añadir nuevos campos (como User.bio) sin romper a los clientes existentes, porque los clientes solo reciben lo que piden. Eliminar o cambiar campos es más sensible, por lo que los equipos suelen marcar campos como obsoletos primero y migrar los clientes gradualmente.
Una API GraphQL típicamente se expone a través de un endpoint único (por ejemplo, /graphql). En lugar de tener muchas URLs para distintos recursos (como /users, /users/123, /users/123/posts), envías una consulta a un solo lugar y describes exactamente los datos que quieres recibir.
Una consulta es básicamente una “lista de la compra” de campos. Puedes pedir campos simples (como id y name) y también datos anidados (como los posts recientes de un usuario) en la misma petición—sin descargar campos extras que no necesitas.
Aquí tienes un pequeño ejemplo:
query GetUserWithPosts {
user(id: "123") {
id
name
posts(limit: 2) {
id
title
}
}
}
Las respuestas de GraphQL son predecibles: el JSON que recibes refleja la estructura de tu consulta. Eso facilita el trabajo en frontend, porque no tienes que adivinar dónde aparecerán los datos ni analizar distintos formatos de respuesta.
Un esquema de respuesta simplificado podría verse así:
{
"data": {
"user": {
"id": "123",
"name": "Sam",
"posts": [
{ "id": "p1", "title": "Hello GraphQL" },
{ "id": "p2", "title": "Queries in Practice" }
]
}
}
}
Si no pides un campo, no se incluirá. Si lo pides, puedes esperar encontrarlo en el lugar correspondiente—lo que convierte a las consultas GraphQL en una forma limpia de obtener exactamente lo que cada pantalla o característica necesita.
Las consultas son para leer; las mutaciones son cómo cambias datos en una API GraphQL—crear, actualizar o eliminar registros.
La mayoría de las mutaciones siguen el mismo patrón:
input) con los campos a actualizar.Las mutaciones en GraphQL suelen devolver datos a propósito, en lugar de solo "success: true". Devolver el objeto actualizado (o al menos su id y campos clave) ayuda a la UI a:
Un diseño común es un tipo “payload” que incluye tanto la entidad actualizada como los errores.
mutation UpdateEmail($input: UpdateUserEmailInput!) {
updateUserEmail(input: $input) {
user {
id
email
}
errors {
field
message
}
}
}
Para APIs orientadas a UI, una buena regla es: devuelve lo que necesitas para renderizar el siguiente estado (por ejemplo, el user actualizado más cualquier errors). Eso mantiene el cliente simple, evita adivinar qué cambió y facilita manejar fallos con gracia.
Un esquema GraphQL describe lo que se puede pedir. Los resolvers describen cómo obtenerlo realmente. Un resolver es una función adjunta a un campo específico del esquema. Cuando un cliente solicita ese campo, GraphQL llama al resolver para obtener o calcular el valor.
GraphQL ejecuta una consulta recorriendo la forma solicitada. Para cada campo, encuentra el resolver correspondiente y lo ejecuta. Algunos resolvers simplemente devuelven una propiedad de un objeto ya en memoria; otros llaman a una base de datos, a otro servicio o combinan múltiples fuentes.
Por ejemplo, si tu esquema tiene User.posts, el resolver de posts podría consultar una tabla posts por userId o llamar a un servicio de Posts separado.
Los resolvers son el pegamento entre el esquema y tus sistemas reales:
Este mapeo es flexible: puedes cambiar la implementación del backend sin modificar la forma de la consulta del cliente—siempre que el esquema se mantenga consistente.
Porque los resolvers pueden ejecutarse por campo y por ítem en una lista, es fácil desencadenar muchas llamadas pequeñas (por ejemplo, obtener posts para 100 usuarios con 100 consultas separadas). Este patrón “N+1” puede ralentizar las respuestas.
Soluciones comunes incluyen batching y caching (p. ej., reunir IDs y obtenerlos en una sola consulta) y ser intencional sobre qué campos anidados fomentas que pidan los clientes.
La autorización suele aplicarse en los resolvers (o en middleware compartido) porque los resolvers saben quién pide y qué dato se está accediendo (a través del contexto). La validación normalmente ocurre en dos niveles: GraphQL maneja validación de tipos/estructura automáticamente, mientras que los resolvers aplican reglas de negocio (como “solo los admins pueden establecer este campo”).
Algo que sorprende a quienes conocen poco GraphQL es que una solicitud puede “tener éxito” e incluir aun así errores. Esto se debe a que GraphQL está orientado a campos: si algunos campos pueden resolverse y otros no, puedes recibir datos parciales.
Una respuesta típica de GraphQL puede contener tanto data como un arreglo errors:
{
"data": {
"user": {
"id": "123",
"email": null
}
},
"errors": [
{
"message": "Not authorized to read email",
"path": ["user", "email"],
"extensions": { "code": "FORBIDDEN" }
}
]
}
Esto es útil: el cliente puede seguir renderizando lo que tiene (por ejemplo, el perfil de usuario) mientras maneja el campo faltante.
data suele ser null.Escribe mensajes de error pensados para el usuario final, no para depuración. Evita exponer trazas de pila, nombres de bases de datos o IDs internos. Un buen patrón es:
message corto y seguroextensions.code legible por máquina y estableretryable: true)Registra el error detallado en el servidor con un ID de solicitud para investigarlo sin exponer detalles internos.
Define un pequeño “contrato” de errores que compartan web y móvil: valores comunes de extensions.code (como UNAUTHENTICATED, FORBIDDEN, BAD_USER_INPUT), cuándo mostrar un toast vs errores inline, y cómo manejar datos parciales. La consistencia evita que cada cliente invente sus propias reglas de error.
Las subscriptions son la forma de GraphQL para empujar datos a los clientes cuando cambian, en lugar de que el cliente pregunte repetidamente. Normalmente se entregan por una conexión persistente (más comúnmente WebSockets), de modo que el servidor puede enviar eventos en cuanto ocurran.
Una subscription se parece mucho a una consulta, pero el resultado no es una única respuesta. Es un flujo de resultados, cada uno representando un evento.
Bajo el capó, un cliente “se suscribe” a un tema (por ejemplo, messageAdded en una app de chat). Cuando el servidor publica un evento, los suscriptores conectados reciben una carga que coincide con el selection set de la subscription.
Las subscriptions destacan cuando se esperan cambios instantáneos:
Con polling, el cliente pregunta “¿hay algo nuevo?” cada N segundos. Es simple, pero puede desperdiciar solicitudes (especialmente cuando no hay cambios) y sigue teniendo retraso.
Con subscriptions, el servidor envía la actualización inmediatamente. Eso puede reducir tráfico innecesario y mejorar la percepción de rapidez—a costa de mantener conexiones abiertas y gestionar infraestructura en tiempo real.
No siempre valen la pena. Si las actualizaciones son infrecuentes, no son críticas o se pueden agrupar, el polling (o volver a hacer fetch tras acciones del usuario) suele ser suficiente.
También añaden sobrecarga operativa: escalado de conexiones, auth en sesiones de larga duración, reintentos y monitorización. Una buena regla: usa subscriptions solo cuando el tiempo real sea un requisito del producto, no solo un extra agradable.
GraphQL suele describirse como “poder al cliente”, pero ese poder tiene costes. Conocer las compensaciones te ayuda a decidir cuándo GraphQL encaja bien y cuándo puede ser excesivo.
La mayor ventaja es la flexibilidad al obtener datos: los clientes pueden pedir exactamente los campos que necesitan, lo que reduce la sobrelectura y facilita cambios de UI.
Otra ventaja importante es el contrato fuerte que proporciona el esquema GraphQL. El esquema se convierte en una única fuente de verdad para tipos y operaciones disponibles, lo que mejora la colaboración y las herramientas.
Los equipos suelen ver mayor productividad en el cliente porque los desarrolladores frontend pueden iterar sin esperar nuevas variantes de endpoints, y herramientas como Apollo Client pueden generar tipos y simplificar la obtención de datos.
GraphQL puede complicar el cacheo. Con REST, el cacheo suele ser “por URL”. Con GraphQL, muchas consultas comparten el mismo endpoint, así que el cacheo depende de la forma de la consulta, caches normalizados y configuración cuidadosa entre servidor y cliente.
En el servidor, hay peligros de rendimiento. Una consulta aparentemente pequeña puede desencadenar muchas llamadas a backend si no diseñas bien los resolvers (batching, evitar patrones N+1 y controlar campos costosos).
También existe una curva de aprendizaje: esquemas, resolvers y patrones de cliente pueden ser desconocidos para equipos acostumbrados a APIs basadas en endpoints.
Como los clientes pueden pedir mucho, las APIs GraphQL deben aplicar límites de profundidad y complejidad de consulta para evitar peticiones abusivas o accidentales “demasiado grandes”.
Autenticación y autorización deben aplicarse por campo, no solo a nivel de ruta, ya que distintos campos pueden tener reglas de acceso distintas.
Operativamente, invierte en logging, tracing y monitorización que entiendan GraphQL: registra nombres de operaciones, variables (con cuidado), tiempos de resolvers y tasas de error para detectar consultas lentas y regresiones temprano.
GraphQL y REST ambas permiten que apps hablen con servidores, pero estructuran esa conversación de formas muy distintas.
REST es basado en recursos. Obtienes datos llamando a múltiples endpoints (URLs) que representan “cosas” como /users/123 o /orders?userId=123. Cada endpoint devuelve una forma fija de datos decidida por el servidor.
REST también se apoya en semántica HTTP: métodos como GET/POST/PUT/DELETE, códigos de estado y reglas de cacheo. Eso puede hacer que REST sea natural cuando haces CRUD sencillo o dependes de caches a nivel de navegador/proxy.
GraphQL es basado en esquema. En lugar de muchos endpoints, normalmente tienes un endpoint, y el cliente envía una consulta describiendo los campos exactos que quiere. El servidor valida esa petición contra el esquema GraphQL y devuelve una respuesta que coincide con la forma de la consulta.
Esta “selección impulsada por el cliente” es por qué GraphQL puede reducir sobrelectura y sublectura, especialmente en pantallas que necesitan datos de varios modelos relacionados.
REST suele encajar mejor cuando:
Muchos equipos mezclan ambos:
La pregunta práctica no es “¿Cuál es mejor?” sino “¿Qué encaja en este caso de uso con la menor complejidad?”.
Diseñar una API GraphQL es más fácil cuando la tratas como un producto para las personas que construyen pantallas, no como un reflejo de tu base de datos. Comienza pequeño, valida con casos reales y expande según crezcan las necesidades.
Lista tus pantallas clave (por ejemplo, “Lista de productos”, “Detalle de producto”, “Checkout”). Para cada pantalla, anota los campos exactos que necesita y las interacciones que soporta.
Esto ayuda a evitar “consultas todopoderosas”, reduce la sobrelectura y aclara dónde necesitarás filtrado, ordenamiento y paginación.
Define primero tus tipos principales (p. ej., User, Product, Order) y sus relaciones. Luego añade:
Prefiere nombres orientados al negocio sobre nombres de base de datos. “placeOrder” comunica la intención mejor que “createOrderRecord”.
Mantén nombres consistentes: singular para ítems (product), plural para colecciones (products). Para paginación, elige normalmente una de dos:
Decidir pronto moldea la estructura de las respuestas de tu API.
GraphQL soporta descripciones directamente en el esquema—úsalas para campos, argumentos y casos especiales. Luego añade algunos ejemplos copy-paste en tu documentación (incluyendo paginación y escenarios comunes de error). Un esquema bien descrito hace que la introspección y los exploradores de API sean mucho más útiles.
Empezar con GraphQL es sobre elegir algunas herramientas bien soportadas y establecer un flujo de trabajo confiable. No necesitas adoptar todo a la vez—haz que una consulta funcione de punta a punta y luego expande.
Escoge un servidor según tu stack y cuánto quieres que incluya:
Un primer paso práctico: define un esquema pequeño (un par de tipos + una query), implementa resolvers y conecta una fuente de datos real (aunque sea una lista en memoria stub).
Si quieres moverte rápido de “idea” a API funcional, una plataforma de scaffolding como Koder.ai puede ayudarte a crear una app full-stack pequeña (React en frontend, Go + PostgreSQL en backend) y iterar en esquema/resolvers vía chat—luego exportas el código cuando estés listo para manejar la implementación.
En frontend, la elección suele depender de si quieres convenciones opinadas o flexibilidad:
Si migras desde REST, empieza usando GraphQL en una pantalla o funcionalidad y mantén REST para el resto hasta que el enfoque se demuestre.
Trata tu esquema como un contrato de API. Capas útiles de pruebas incluyen:
Para profundizar, continúa con:
GraphQL es un lenguaje de consultas y un runtime para APIs. Los clientes envían una consulta que describe los campos exactos que desean, y el servidor devuelve una respuesta JSON que refleja esa estructura.
Se entiende mejor como una capa entre los clientes y una o varias fuentes de datos (bases de datos, servicios REST, APIs de terceros, microservicios).
GraphQL ayuda principalmente con:
Al permitir que el cliente solicite solo campos específicos (incluidos campos anidados), GraphQL puede reducir la transferencia de datos innecesaria y simplificar el código del cliente.
GraphQL no es:
Trátalo como un contrato de API + motor de ejecución, no como una solución mágica de almacenamiento o rendimiento.
La mayoría de las APIs GraphQL exponen un endpoint único (a menudo /graphql). En lugar de múltiples URLs, envías diferentes operaciones (queries/mutations) a ese único endpoint.
Implicación práctica: el cacheo y la observabilidad suelen basarse en el nombre de la operación + variables, no en la URL.
El esquema es el contrato de la API. Define:
User, Post)User.name)User.posts)Al ser , el servidor puede validar las consultas antes de ejecutarlas y devolver errores claros cuando un campo no existe.
Las consultas GraphQL son operaciones de lectura. Especificas los campos que necesitas y la respuesta JSON refleja la estructura de la consulta.
Consejos:
query GetUserWithPosts) para mejorar depuración y monitorización.posts(limit: 2)).Las mutaciones son operaciones de escritura (crear/actualizar/eliminar). Un patrón común es:
inputDevolver datos (no solo success: true) ayuda a la UI a actualizarse inmediatamente y mantiene consistentes las caches.
Los resolvers son funciones a nivel de campo que indican cómo obtener o calcular cada campo.
En la práctica, los resolvers pueden:
La autorización con frecuencia se aplica en los resolvers (o en middleware compartido) porque ellos conocen quién solicita y qué dato se está accediendo.
Es fácil crear un patrón N+1 (por ejemplo, cargar posts por separado para cada uno de 100 usuarios).
Mitigaciones comunes:
Mide el tiempo de los resolvers y busca llamadas repetidas a servicios externos durante una sola solicitud.
GraphQL puede devolver datos parciales junto con un arreglo errors. Eso ocurre cuando algunos campos se resuelven correctamente y otros fallan (por ejemplo, campo prohibido o timeout en un servicio descendente).
Buenas prácticas:
message cortos y seguros para el usuarioextensions.code (p. ej., FORBIDDEN, BAD_USER_INPUT)Los clientes deben decidir cuándo renderizar datos parciales o tratar la operación como un fallo total.