22 sept 2025·8 min
¿Qué es Kafka y cómo se usa en sistemas modernos?
Aprende qué es Apache Kafka, cómo funcionan topics y particiones, y dónde encaja Kafka en sistemas modernos para eventos en tiempo real, registros y canalizaciones de datos.
Aprende qué es Apache Kafka, cómo funcionan topics y particiones, y dónde encaja Kafka en sistemas modernos para eventos en tiempo real, registros y canalizaciones de datos.
Apache Kafka es una plataforma distribuida de transmisión de eventos. En pocas palabras, es una “tubería” compartida y duradera que permite a muchos sistemas publicar hechos sobre lo que pasó y a otros sistemas leer esos hechos—rápido, a escala y en orden.
Los equipos usan Kafka cuando los datos deben moverse de forma fiable entre sistemas sin acoplamiento fuerte. En lugar de que una aplicación llame directamente a otra (y falle cuando ésta está caída o lenta), los productores escriben eventos en Kafka. Los consumidores los leen cuando están listos. Kafka almacena eventos durante un periodo configurable, de modo que los sistemas pueden recuperarse de interrupciones e incluso reprocesar el historial.
Esta guía es para ingenieros orientados al producto, personal de datos y líderes técnicos que quieren un modelo mental práctico de Kafka.
Aprenderás los bloques básicos (productores, consumidores, topics, brokers), cómo Kafka escala con particiones, cómo almacena y reprocesa eventos, y dónde encaja en la arquitectura dirigida por eventos. También cubriremos casos de uso comunes, garantías de entrega, fundamentos de seguridad, planificación operativa y cuándo Kafka es (o no es) la herramienta correcta.
Kafka es más fácil de entender como un log de eventos compartido: las aplicaciones escriben eventos en él y otras aplicaciones leen esos eventos después—a menudo en tiempo real, a veces horas o días después.
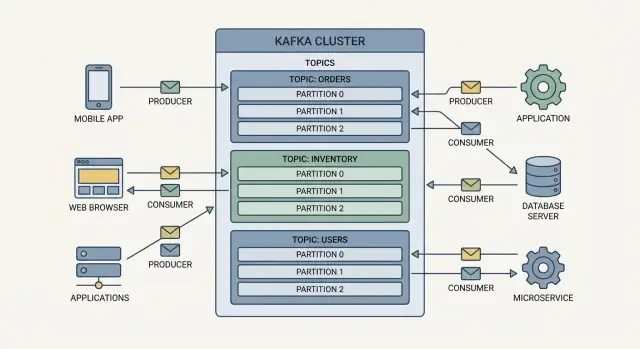
Productores son los escritores. Un productor puede publicar un evento como “order placed”, “payment confirmed” o “temperature reading”. Los productores no envían eventos directamente a aplicaciones específicas—los envían a Kafka.
Consumidores son los lectores. Un consumidor puede alimentar un panel de control, activar un flujo de envío o cargar datos en analítica. Los consumidores deciden qué hacer con los eventos y pueden leer a su propio ritmo.
Los eventos en Kafka se agrupan en topics, que son básicamente categorías con nombre. Por ejemplo:
orders para eventos relacionados con pedidospayments para eventos de pagosinventory para cambios de stockUn topic se convierte en la secuencia “fuente de la verdad” para ese tipo de evento, lo que facilita que varios equipos reutilicen los mismos datos sin construir integraciones puntuales.
Un broker es un servidor Kafka que almacena eventos y se los sirve a los consumidores. En la práctica, Kafka funciona como un clúster (múltiples brokers colaborando) para manejar más tráfico y seguir operativo incluso si una máquina falla.
Los consumidores suelen ejecutarse en un grupo de consumidores. Kafka reparte la lectura entre el grupo, de modo que puedes añadir más instancias consumidoras para escalar el procesamiento—sin que cada instancia haga el mismo trabajo.
Kafka escala dividiendo el trabajo en topics (flujos de eventos relacionados) y luego dividiendo cada topic en particiones (porciones más pequeñas e independientes de ese flujo).
Un topic con una partición solo puede ser leído por un consumidor a la vez dentro de un grupo de consumidores. Añade más particiones y puedes añadir más consumidores para procesar eventos en paralelo. Así Kafka soporta flujos de eventos de alto volumen y canalizaciones de datos en tiempo real sin convertir cada sistema en un cuello de botella.
Las particiones también ayudan a distribuir la carga entre brokers. En lugar de que una máquina gestione todas las escrituras y lecturas de un topic, varios brokers pueden alojar diferentes particiones y compartir el tráfico.
Kafka garantiza orden dentro de una única partición. Si los eventos A, B y C se escriben en la misma partición en ese orden, los consumidores los leerán A → B → C.
No se garantiza el orden entre particiones. Si necesitas orden estricto para una entidad concreta (como un cliente o un pedido), normalmente te aseguras de que todos los eventos de esa entidad vayan a la misma partición.
Cuando los productores envían un evento, pueden incluir una clave (por ejemplo, order_id). Kafka usa la clave para enrutar de forma consistente eventos relacionados a la misma partición. Eso te da un orden predecible para esa clave mientras el topic en su conjunto escala entre muchas particiones.
Cada partición puede ser replicada en otros brokers. Si un broker falla, otro broker con una réplica puede tomar el relevo. La replicación es una razón importante por la que Kafka es confiable para mensajería pub-sub crítica y sistemas dirigidos por eventos: mejora la disponibilidad y soporta tolerancia a fallos sin que cada aplicación tenga que construir su propia lógica de failover.
Una idea clave en Apache Kafka es que los eventos no solo se transmiten y se olvidan. Se escriben en disco en un registro ordenado, por lo que los consumidores pueden leerlos ahora o más tarde. Esto hace a Kafka útil no solo para mover datos, sino también para mantener un historial duradero de lo que ocurrió.
Cuando un productor envía un evento a un topic, Kafka lo añade al almacenamiento del broker. Los consumidores leen desde ese registro almacenado a su propio ritmo. Si un consumidor está caído durante una hora, los eventos siguen existiendo y pueden ponerse al día cuando se recupere.
Kafka mantiene eventos según políticas de retención:
La retención se configura por topic, lo que te permite tratar los topics de “pista de auditoría” de forma diferente a los topics de telemetría de alto volumen.
Algunos topics son más bien un changelog que un archivo histórico—por ejemplo, “configuración actual del cliente”. La compactación de logs conserva al menos el evento más reciente por clave, mientras que los registros antiguos que han sido sustituidos pueden eliminarse. Así obtienes una fuente de verdad duradera del estado más reciente sin crecimiento descontrolado.
Porque los eventos permanecen almacenados, puedes reproducirlos para reconstruir estado:
En la práctica, la reproducción se controla por dónde un consumidor “comienza a leer” (su offset), lo que da a los equipos una red de seguridad poderosa cuando los sistemas evolucionan.
Kafka está construido para mantener el flujo de datos incluso cuando partes del sistema fallan. Lo hace con replicación, reglas claras sobre quién está “a cargo” de cada partición y confirmaciones de escritura configurables.
Cada partición de un topic tiene un broker líder y una o más réplicas seguidores en otros brokers. Productores y consumidores hablan con el líder de esa partición.
Los seguidores copian continuamente los datos del líder. Si el líder cae, Kafka puede promover a un seguidor actualizado para que sea el nuevo líder y así la partición permanezca disponible.
Si un broker falla, las particiones que hospedaba como líderes quedan indisponibles por un momento. El controlador de Kafka (coordinación interna) detecta la falla y dispara una elección de líder para esas particiones.
Si al menos una réplica seguidora está suficientemente actualizada, puede tomar el puesto de líder y los clientes reanudarán la producción/consumo. Si no hay réplicas en sincronía, Kafka puede pausar las escrituras (según tu configuración) para evitar perder datos que ya se habían confirmado.
Dos parámetros importantes moldean la durabilidad:
A nivel conceptual:
Para reducir duplicados durante reintentos, los equipos suelen combinar acks más seguros con productores idempotentes y un manejo sólido en el consumidor (cubierto más adelante).
Mayor seguridad típicamente implica esperar más confirmaciones y mantener más réplicas en sincronía, lo que puede añadir latencia y reducir el rendimiento máximo.
Configuraciones de baja latencia pueden ser aceptables para telemetría o clickstream donde alguna pérdida ocasional es tolerable, pero pagos, inventario y registros de auditoría suelen justificar la seguridad extra.
La arquitectura dirigida por eventos (EDA) es una forma de construir sistemas donde las cosas que suceden en el negocio—un pedido realizado, un pago confirmado, un paquete enviado—se representan como eventos a los que otras partes del sistema pueden reaccionar.
Kafka a menudo se sitúa en el centro de la EDA como el “flujo de eventos” compartido. En lugar de que el Servicio A llame al Servicio B directamente, el Servicio A publica un evento (por ejemplo, OrderCreated) en un topic de Kafka. Cualquier número de servicios puede consumir ese evento y actuar—enviar un correo, reservar inventario, iniciar controles de fraude—sin que el Servicio A tenga que conocerlos.
Porque los servicios se comunican mediante eventos, no tienen que coordinar APIs request/response para cada interacción. Esto reduce dependencias fuertes entre equipos y facilita añadir nuevas funcionalidades: puedes introducir un nuevo consumidor para un evento existente sin cambiar al productor.
La EDA es naturalmente asíncrona: los productores escriben eventos rápidamente y los consumidores los procesan a su propio ritmo. Durante picos de tráfico, Kafka ayuda a amortiguar la oleada para que los sistemas downstream no se colapsen de inmediato. Los consumidores pueden escalar para ponerse al día, y si un consumidor cae temporalmente, puede reanudar desde donde quedó.
Piensa en Kafka como el “feed de actividad” del sistema. Los productores publican hechos; los consumidores se suscriben a los hechos que les importan. Ese patrón permite canalizaciones de datos en tiempo real y flujos dirigidos por eventos manteniendo los servicios más simples e independientes.
Kafka suele aparecer donde los equipos necesitan mover muchos “hechos que ocurrieron” (eventos) entre sistemas—rápido, con fiabilidad y de modo que múltiples consumidores puedan reutilizarlos.
Las aplicaciones suelen necesitar un historial solo-append: inicios de sesión, cambios de permisos, actualizaciones de registros o acciones administrativas. Kafka funciona bien como un flujo central de estos eventos, de modo que herramientas de seguridad, informes y exportaciones de cumplimiento puedan leer la misma fuente sin añadir carga a la base de datos de producción. Como los eventos se retienen un periodo, también puedes reproducirlos para reconstruir una vista de auditoría tras un bug o un cambio de esquema.
En lugar de que los servicios se llamen directamente, pueden publicar eventos como “order created” o “payment received”. Otros servicios se suscriben y reaccionan a su tiempo. Esto reduce el acoplamiento, ayuda a que los sistemas sigan funcionando durante fallas parciales y facilita añadir capacidades (por ejemplo, controles de fraude) consumiendo el flujo de eventos existente.
Kafka es una columna vertebral común para mover datos de sistemas operacionales a plataformas analíticas. Los equipos pueden transmitir cambios desde bases de datos de aplicaciones y entregarlos a un data warehouse o un data lake con baja latencia, manteniendo la aplicación de producción separada de consultas analíticas pesadas.
Sensores, dispositivos y telemetría de aplicaciones suelen llegar en picos. Kafka puede absorber los estallidos, bufferizarlos de forma segura y permitir que el procesamiento downstream se ponga al día—útil para monitorización, alertas y análisis a largo plazo.
Kafka es más que brokers y topics. La mayoría de equipos dependen de herramientas compañeras que hacen a Kafka práctico para movimiento de datos diario, procesamiento en streaming y operaciones.
Kafka Connect es el marco de integración de Kafka para meter datos en Kafka (sources) y sacarlos de Kafka (sinks). En lugar de construir y mantener pipelines puntuales, ejecutas Connect y configuras conectores.
Ejemplos comunes incluyen extraer cambios de bases de datos, ingerir eventos SaaS o entregar datos de Kafka a un almacén o almacenamiento de objetos. Connect también estandariza preocupaciones operativas como reintentos, offsets y paralelismo.
Si Connect es para integración, Kafka Streams es para computación. Es una librería que añades a tu aplicación para transformar flujos en tiempo real—filtrar eventos, enriquecerlos, unir flujos y construir agregados (por ejemplo, “pedidos por minuto”).
Como las apps Streams leen de topics y escriben de nuevo en topics, encajan naturalmente en sistemas dirigidos por eventos y pueden escalar añadiendo más instancias.
A medida que varios equipos publican eventos, la consistencia importa. La gestión de esquemas (a menudo vía un schema registry) define qué campos debe tener un evento y cómo evolucionan con el tiempo. Eso ayuda a evitar roturas como que un productor renombre un campo del que depende un consumidor.
Kafka es operacionalmente sensible, así que la monitorización básica es esencial:
La mayoría de equipos también usan UIs de gestión y automatización para despliegues, configuración de topics y políticas de control de acceso (ver /blog/kafka-security-governance).
Kafka se describe a menudo como “log duradero + consumidores”, pero lo que la mayoría de equipos realmente quieren saber es: ¿procesaré cada evento una vez y qué pasa cuando algo falla? Kafka te da bloques de construcción y tú eliges los trade-offs.
Como máximo una vez (at-most-once) significa que puedes perder eventos, pero no procesarás duplicados. Esto ocurre si un consumidor confirma su posición antes y luego falla antes de completar el trabajo.
Al menos una vez (at-least-once) significa que no perderás eventos, pero pueden aparecer duplicados (por ejemplo, el consumidor procesa un evento, falla y luego lo reprocesa al reiniciar). Este es el patrón por defecto más común.
Exactamente una vez busca evitar tanto pérdidas como duplicados de extremo a extremo. En Kafka, esto suele implicar productores transaccionales y procesamiento compatible (a menudo vía Kafka Streams). Es poderoso, pero más restrictivo y requiere configuración cuidadosa.
En la práctica, muchos sistemas aceptan at-least-once y añaden salvaguardas:
Un offset de consumidor es la posición del último registro procesado en una partición. Cuando confirmas offsets, estás diciendo “he terminado hasta aquí”. Confirmar muy pronto y arriesgas pérdida; confirmar muy tarde y aumentas duplicados tras fallos.
Los reintentos deben estar acotados y ser visibles. Un patrón común es:
Esto evita que un único “mensaje venenoso” bloquee a todo un grupo de consumidores y al mismo tiempo preserva los datos para correcciones posteriores.
Kafka suele transportar eventos críticos del negocio (pedidos, pagos, actividad de usuarios). Eso hace que la seguridad y la gobernanza formen parte del diseño, no algo añadido al final.
La autenticación responde “¿quién eres?” La autorización responde “¿qué puedes hacer?”. En Kafka, la autenticación se hace comúnmente con SASL (por ejemplo, SCRAM o Kerberos), mientras que la autorización se aplica con ACLs en niveles de topic, grupo de consumidores y clúster.
Un patrón práctico es privilegio mínimo: los productores solo pueden escribir en los topics que poseen y los consumidores solo pueden leer los topics que necesitan. Esto reduce la exposición accidental de datos y limita el radio de impacto si credenciales se filtran.
TLS cifra los datos mientras se mueven entre apps, brokers y herramientas. Sin TLS, los eventos pueden ser interceptados en redes internas, no solo en Internet público. TLS también ayuda a prevenir ataques “man-in-the-middle” validando identidades de brokers.
Cuando varios equipos comparten un clúster, las reglas importan. Convenciones claras de nombres de topics (por ejemplo, <equipo>.<dominio>.<evento>.<versión>) hacen obvia la propiedad y ayudan a que las herramientas apliquen políticas consistentemente.
Combina el nombrado con cuotas y plantillas de ACL para que una carga ruidosa no deprima a otras y para que nuevos servicios empiecen con valores seguros por defecto.
Trata a Kafka como sistema de registro de historial solo cuando lo pretendas. Si los eventos incluyen PII, usa minimización de datos (envía IDs en vez de perfiles completos), considera cifrado a nivel de campo y documenta qué topics son sensibles.
Las políticas de retención deben coincidir con requisitos legales y de negocio. Si la política dice “eliminar después de 30 días”, no guardes 6 meses “por si acaso”. Revisiones y auditorías periódicas mantienen las configuraciones alineadas conforme los sistemas evolucionan.
Ejecutar Apache Kafka no es solo “instalar y olvidar”. Se comporta más como una utilidad compartida: muchos equipos dependen de ella y pequeños errores pueden propagarse a aplicaciones downstream.
La capacidad de Kafka es mayormente un problema de cálculo que revisas regularmente. Las palancas más grandes son particiones (paralelismo), rendimiento (MB/s de entrada y salida) y crecimiento de almacenamiento (cuánto tiempo retienes datos).
Si el tráfico se duplica, puede que necesites más particiones para repartir la carga entre brokers, más disco para mantener la retención y más margen de red para la replicación. Un hábito práctico es estimar la tasa máxima de escritura y multiplicarla por la retención para estimar crecimiento de disco, luego añadir margen para replicación y “éxito inesperado”.
Espera trabajo rutinario más allá de mantener servidores activos:
Los costes vienen de discos, egress de red y del número/tamaño de brokers. Kafka gestionado puede reducir la carga de personal y simplificar upgrades, mientras que alojarlo uno mismo puede ser más barato a escala si tienes operadores experimentados. El intercambio es tiempo de recuperación y carga de on-call.
Los equipos suelen monitorizar:
Buenos dashboards y alertas convierten a Kafka de una “caja misteriosa” en un servicio entendible.
Kafka encaja bien cuando necesitas mover muchos eventos de forma fiable, guardarlos durante un tiempo y permitir que múltiples sistemas reaccionen al mismo flujo de datos a su propio ritmo. Es especialmente útil cuando los datos deben ser reproducibles (para backfills, auditorías o reconstruir un servicio) y cuando esperas añadir más productores/consumidores con el tiempo.
Kafka suele brillar cuando tienes:
Kafka puede ser exagerado si tus necesidades son simples:
En estos casos, la sobrecarga operativa (dimensionado del clúster, upgrades, monitorización, on-call) puede superar los beneficios.
Kafka también complementa—no reemplaza—bases de datos (sistema de registro), caches (lecturas rápidas) y herramientas de ETL por lotes (transformaciones periódicas grandes).
Pregúntate:
Si respondes “sí” a la mayoría, Kafka suele ser una elección sensata.
Kafka encaja mejor cuando necesitas una “fuente de la verdad” compartida para flujos de eventos en tiempo real: muchos productores que generan hechos (pedidos creados, pagos autorizados, inventario cambiado) y muchos consumidores que usan esos hechos para alimentar pipelines, analítica y funcionalidades reactivas.
Empieza con un flujo estrecho y de alto valor—como publicar eventos “OrderPlaced” para servicios downstream (correo, controles de fraude, cumplimiento). Evita convertir a Kafka en una cola general desde el primer día.
Escribe:
Mantén esquemas iniciales simples y consistentes (timestamps, IDs y un nombre claro de evento). Decide si harás cumplir esquemas desde el principio o evolucionarás con cuidado.
Kafka funciona cuando alguien se encarga de:
Añade monitorización inmediatamente (consumer lag, salud de brokers, throughput, tasas de error). Si aún no tienes un equipo de plataforma, empieza con una oferta gestionada y límites claros.
Produce eventos desde un sistema, consúmelos en un lugar y demuestra el bucle de extremo a extremo. Solo entonces amplia a más consumidores, particiones e integraciones.
Si quieres moverte rápido desde la idea a un servicio dirigido por eventos funcional, herramientas como Koder.ai pueden ayudarte a prototipar la aplicación periférica rápidamente (UI web en React, backend en Go, PostgreSQL) e ir añadiendo productores/consumidores de Kafka mediante un flujo guiado por chat. Es especialmente útil para construir paneles internos y servicios ligeros que consumen topics, con características como modo de planificación, exportación de código fuente, despliegue/alojamiento y snapshots con rollback.
Si estás mapeando esto a un enfoque dirigido por eventos, ve a /blog/event-driven-architecture. Para planificar costes y entornos, consulta /pricing.
Kafka es una plataforma distribuida de transmisión de eventos que almacena eventos en registros duraderos y solo-append.
Los productores escriben eventos en topics, y los consumidores los leen de forma independiente (a menudo en tiempo real, pero también más tarde) porque Kafka conserva los datos durante un período configurado.
Usa Kafka cuando varios sistemas necesiten el mismo flujo de eventos, quieras acoplamiento suelto y puedas necesitar reproducir el historial.
Es especialmente útil para:
Un topic es una categoría con nombre de eventos (como orders o payments).
Una partición es una porción de un topic que permite:
Kafka garantiza el orden solo dentro de una única partición.
Kafka usa la clave del registro (por ejemplo, order_id) para enrutar de forma consistente eventos relacionados a la misma partición.
Regla práctica: si necesitas orden por entidad (todos los eventos de un pedido/cliente en secuencia), elige una clave que represente esa entidad para que los eventos caigan en la misma partición.
Un grupo de consumidores es un conjunto de instancias consumidoras que comparten el trabajo de un topic.
Dentro de un grupo:
Si dos aplicaciones distintas deben recibir cada evento, deben usar grupos de consumidores diferentes.
Kafka conserva eventos en disco según políticas de retención para que los consumidores puedan ponerse al día tras una caída o reprocesar el historial.
Tipos comunes de retención:
La retención se configura por topic, así que streams de auditoría pueden guardarse más tiempo que telemetría de alto volumen.
La compactación de logs mantiene al menos el registro más reciente por clave, eliminando con el tiempo registros antiguos que han sido reemplazados.
Es útil para streams de “estado actual” (como configuraciones o perfiles) donde te interesa el último valor por clave y no cada cambio histórico, manteniendo a la vez una fuente de verdad duradera.
El patrón más común en Kafka es at-least-once: no perderás eventos, pero pueden aparecer duplicados.
Para manejarlo de forma segura:
Los offsets son el “marcador” de un consumidor por partición.
Si confirmas offsets demasiado pronto, puedes perder trabajo ante un fallo; si lo haces demasiado tarde, aumentarás duplicados tras reinicios.
Un patrón operativo común es reintentos acotados con backoff y, en caso de fallo persistente, publicar el registro fallido en un topic de dead-letter para que no paralice al grupo entero.
Kafka Connect mueve datos hacia/dentro de Kafka usando conectores (fuentes y sinks) en vez de código personalizado.
Kafka Streams es una librería para transformar y agregar flujos en tiempo real dentro de tus aplicaciones (filtrar, unir, enriquecer, agregar), leyendo de topics y escribiendo de nuevo en topics.
En resumen: Connect es para integración; Streams es para computación en streaming.