05 oct 2025·8 min
RabbitMQ para tus aplicaciones: patrones, configuración y operaciones
Aprende a usar RabbitMQ en tus aplicaciones: conceptos clave, patrones comunes, consejos de fiabilidad, escalado, seguridad y monitorización para producción.
Aprende a usar RabbitMQ en tus aplicaciones: conceptos clave, patrones comunes, consejos de fiabilidad, escalado, seguridad y monitorización para producción.
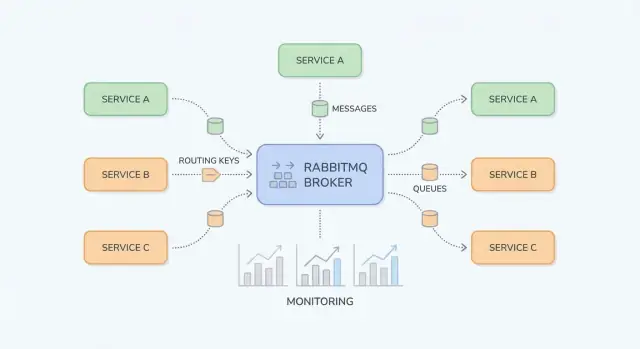
RabbitMQ es un broker de mensajería: se sitúa entre las partes de tu sistema y mueve de forma fiable "trabajo" (mensajes) de productores a consumidores. Los equipos lo usan cuando llamadas directas síncronas (HTTP entre servicios, bases de datos compartidas, cron jobs) empiezan a crear dependencias frágiles, carga irregular y cadenas de fallos difíciles de depurar.
Picos de tráfico y cargas desiguales. Si tu app recibe 10× más registros u órdenes en una ventana corta, procesarlo todo de inmediato puede abrumar servicios posteriores. Con RabbitMQ, los productores encolan tareas rápidamente y los consumidores las procesan a un ritmo controlado.
Acoplamiento fuerte entre servicios. Si el Servicio A debe llamar al B y esperar, fallos y latencia se propagan. El mensajería los desacopla: A publica un mensaje y sigue; B lo procesa cuando esté disponible.
Manejo de fallos más seguro. No todo fallo debería mostrarse como un error al usuario. RabbitMQ te ayuda a reintentar en segundo plano, aislar mensajes "venenosos" y evitar pérdida de trabajo durante cortes temporales.
Normalmente obtienen cargas más suaves (amortiguar picos), servicios desacoplados (menos dependencias en tiempo de ejecución) y reintentos controlados (menos reprocesos manuales). Igual de importante: es más fácil razonar dónde está atascado el trabajo — en el productor, en una cola o en el consumidor.
Esta guía se centra en RabbitMQ práctico para equipos de aplicación: conceptos básicos, patrones comunes (pub/sub, work queues, reintentos y dead-letter queues) y asuntos operativos (seguridad, escalado, observabilidad, resolución de problemas).
No pretende ser una especificación completa de AMQP ni un análisis profundo de todos los plugins de RabbitMQ. El objetivo es ayudarte a diseñar flujos de mensajes mantenibles en sistemas reales.
RabbitMQ es un broker de mensajería que enruta mensajes entre partes de tu sistema, de modo que los productores pueden delegar trabajo y los consumidores procesarlo cuando estén listos.
Con una llamada HTTP directa, el Servicio A envía una petición al Servicio B y típicamente espera una respuesta. Si B está lento o caído, A falla o se bloquea, y tienes que manejar timeouts, reintentos y backpressure en cada cliente.
Con RabbitMQ (comúnmente via AMQP), el Servicio A publica un mensaje al broker. RabbitMQ lo almacena y enruta a la(s) cola(s) correcta(s), y el Servicio B lo consume de forma asíncrona. El cambio clave es que te comunicas a través de una capa intermedia durable que amortigua picos y suaviza cargas irregulares.
La mensajería encaja cuando:
No conviene cuando:
Síncrono (HTTP):
Un servicio de checkout llama por HTTP al de facturación: "Crear factura." El usuario espera mientras se genera. Si facturación es lenta, la latencia del checkout crece; si está caída, checkout falla.
Asíncrono (RabbitMQ):
Checkout publica invoice.requested con el id de orden. El usuario recibe confirmación inmediata de que la orden fue recibida. Facturación consume el mensaje, genera la factura y publica invoice.created para que correo/notifications lo recojan. Cada paso puede reintentarse independientemente y las caídas temporales no rompen automáticamente el flujo.
RabbitMQ es más fácil de entender si separas “dónde se publican mensajes” de “dónde se almacenan”. Los productores publican en exchanges; los exchanges enrutan a colas; los consumidores leen de colas.
Un exchange no almacena mensajes. Evalúa reglas y reenvía mensajes a una o varias colas.
billing o email).region=eu AND tier=premium), pero mantenlo para excepciones porque es más difícil de razonar.Una cola es donde los mensajes esperan hasta que un consumidor los procesa. Una cola puede tener un consumidor o muchos (consumidores competidores), y típicamente cada mensaje se entrega a un consumidor a la vez.
Un binding conecta un exchange con una cola y define la regla de enrutamiento. Piensa: “Cuando un mensaje llega al exchange X con routing key Y, entrégalo a la cola Q.” Puedes enlazar múltiples colas al mismo exchange (pub/sub) o enlazar una sola cola varias veces para diferentes routing keys.
Para direct exchanges, el enrutado es exacto. Para topic exchanges, las routing keys parecen palabras separadas por puntos, por ejemplo:
orders.createdorders.eu.refundedLos bindings pueden incluir comodines:
* coincide con exactamente una palabra (p. ej., orders.* coincide con orders.created)# coincide con cero o más palabras (p. ej., orders.# coincide con orders.created y orders.eu.refunded)Esto te da una forma limpia de añadir nuevos consumidores sin cambiar productores: crea una nueva cola y enlázala con el patrón que necesites.
Después de que RabbitMQ entrega un mensaje, el consumidor reporta lo sucedido:
Ten cuidado con requeue: un mensaje que siempre falla puede entrar en un bucle infinito y bloquear la cola. Muchos equipos combinan nacks con una estrategia de reintentos y una dead-letter queue (cubierta más adelante) para que los fallos se manejen de forma predecible.
RabbitMQ brilla cuando necesitas mover trabajo o notificaciones entre partes del sistema sin hacer que todo espere por un paso lento. A continuación, patrones prácticos que aparecen en productos cotidianos.
Cuando varios consumidores deben reaccionar al mismo evento —sin que el publicador los conozca— el pub/sub es una buena opción.
Ejemplo: cuando un usuario actualiza su perfil, puedes notificar indexado de búsqueda, analítica y sincronización con CRM en paralelo. Con un fanout haces broadcast a todas las colas enlazadas; con un topic enrutas selectivamente (p. ej., user.updated, user.deleted). Esto evita acoplar servicios y permite añadir suscriptores sin cambiar al productor.
Si una tarea tarda, encolala y deja que los workers la procesen asíncronamente:
Esto mantiene rápidas las peticiones web y permite escalar workers independientemente. También es una forma natural de controlar concurrencia: la cola es la "lista de tareas" y el número de workers es la "perilla de throughput".
Muchos flujos cruzan límites de servicio: order → billing → shipping. En vez de que un servicio llame al siguiente y se bloquee, cada servicio puede publicar un evento al finalizar su paso. Servicios downstream consumen eventos y continúan el flujo.
Esto mejora la resiliencia (una caída temporal en shipping no rompe checkout) y aclara la propiedad: cada servicio reacciona a los eventos que le importan.
RabbitMQ también actúa como buffer entre tu app y dependencias lentas o inestables (APIs de terceros, sistemas legacy, bases por lotes). Encolas solicitudes rápidamente y las procesas con reintentos controlados. Si la dependencia cae, el trabajo se acumula de forma segura y se vacía después, en lugar de provocar timeouts en toda la aplicación.
Si planeas introducir colas gradualmente, un pequeño "outbox asíncrono" o una cola de trabajo única suele ser un buen primer paso (ver /blog/next-steps-rollout-plan).
Una configuración de RabbitMQ es agradable de usar cuando las rutas son predecibles, los nombres consistentes y los payloads evolucionan sin romper consumidores antiguos. Antes de añadir otra cola, asegúrate de que la "historia" de un mensaje sea obvia: dónde nace, cómo se enruta y cómo puede alguien depurarlo end-to-end.
Elegir el exchange correcto reduce bindings puntuales y fan-outs sorpresa:
billing.invoice.created).billing.*.created, *.invoice.*). Es la elección más común para enrutado de eventos mantenible.Regla práctica: si estás "inventando" lógica de enrutado compleja en código, quizá pertenezca a un topic exchange.
Trata los cuerpos de mensaje como APIs públicas. Usa versionado explícito (por ejemplo, un campo superior schema_version: 2) y busca compatibilidad hacia atrás:
Así los consumidores antiguos siguen funcionando mientras los nuevos migran a su ritmo.
Facilita la resolución de problemas estandarizando metadata:
correlation_id: liga comandos/eventos que pertenecen a la misma acción de negocio.trace_id (o traceparent W3C): conecta mensajes con trazas distribuidas en HTTP y flujos asíncronos.Si cada publicador establece esto consistentemente, puedes seguir una transacción a través de múltiples servicios sin adivinar.
Usa nombres previsibles y buscables. Un patrón común:
<dominio>.<tipo> (p. ej., billing.events)<dominio>.<entidad>.<verbo> (p. ej., billing.invoice.created)<servicio>.<propósito> (p. ej., reporting.invoice_created.worker)La consistencia vence a la creatividad: el tú del futuro (y el equipo de on-call) te lo agradecerán.
La mensajería fiable se trata de planificar fallos: consumidores que se caen, APIs que timeoutean y eventos malformados. RabbitMQ te da herramientas, pero el código de la aplicación debe colaborar.
Una configuración común es at-least-once delivery: un mensaje puede entregarse más de una vez, pero no debe perderse silenciosamente. Esto ocurre cuando un consumidor recibe un mensaje, empieza a trabajar y falla antes de ackear — RabbitMQ reencola y redelivera.
Conclusión práctica: los duplicados son normales, así que tu handler debe ser seguro para ejecutarse múltiples veces.
Idempotencia significa “procesar el mismo mensaje dos veces tiene el mismo efecto que procesarlo una vez”. Enfoques útiles:
message_id estable (o clave de negocio como order_id + event_type + version) y almacénalo en una tabla/cache de procesados con TTL.PENDING) o restricciones de unicidad en la base de datos.Los reintentos se tratan mejor como un flujo separado, no como un bucle apretado en el consumidor.
Un patrón común:
Esto crea backoff sin mantener mensajes “atascados” como unacked.
Algunos mensajes nunca tendrán éxito (esquema malo, datos referenciados faltantes, bug). Delimítalos por:
Enrútalos a una DLQ para cuarentena. Trata la DLQ como una bandeja operativa: inspecciona payloads, arregla el asunto subyacente y reproduce manualmente mensajes seleccionados (idealmente con una herramienta o script controlado) en lugar de volver a volcarlo todo en la cola principal.
El rendimiento de RabbitMQ suele limitarse por unos pocos factores prácticos: cómo gestionas conexiones, la velocidad de procesamiento de consumidores y si usas colas como “almacenamiento”. El objetivo es throughput constante sin acumular backlog.
Un error común es abrir una nueva conexión TCP por cada publicador o consumidor. Las conexiones son más pesadas de lo que piensas (handshakes, heartbeats, TLS), así que mantenlas persistentes y reutilízalas.
Usa canales para multiplexar trabajo sobre menos conexiones. Regla práctica: pocas conexiones, muchos canales. Aun así, no crees miles de canales a lo tonto: cada canal tiene sobrecarga y tu librería cliente puede tener límites. Prefiere un pequeño pool de canales por servicio y reutiliza canales para publicar.
Si los consumidores toman demasiados mensajes a la vez verás picos de memoria, tiempos de procesamiento largos y latencia irregular. Ajusta un prefetch (QoS) para que cada consumidor tenga un número controlado de mensajes sin ack.
Guía práctica:
Mensajes grandes reducen throughput e incrementan presión de memoria (en publicadores, broker y consumidores). Si tu payload es grande (documentos, imágenes, JSON voluminoso), considera almacenarlo en object storage o base de datos y enviar solo un ID + metadatos por RabbitMQ.
Heurística: mantén mensajes en el rango de KB, no MB.
El crecimiento de colas es un síntoma, no una estrategia. Añade backpressure para que los productores ralenticen cuando los consumidores no dan abasto:
Cuando dudes, cambia un parámetro a la vez y mide: tasa de publicación, tasa de ack, longitud de cola y latencia end-to-end.
La seguridad de RabbitMQ consiste en endurecer los “bordes”: cómo se conectan los clientes, quién puede hacer qué y cómo mantener credenciales fuera de lugares indebidos. Usa esta checklist como base y adáptala a tus requisitos de cumplimiento.
Los permisos de RabbitMQ son potentes si se usan con disciplina.
Para endurecimiento operacional (puertos, firewalls, auditoría), mantén un runbook corto interno y enlázalo desde /docs/security para que los equipos sigan un estándar.
Cuando RabbitMQ falla, los síntomas aparecen primero en la app: endpoints lentos, timeouts, actualizaciones que faltan o trabajos que “nunca terminan”. Buena observabilidad te permite confirmar si el broker es la causa, localizar el cuello de botella (publisher, broker o consumer) y actuar antes de que los usuarios lo noten.
Empieza con un conjunto pequeño de señales que indiquen si los mensajes fluyen:
Alerta sobre tendencias, no solo sobre umbrales absolutos.
Los logs del broker ayudan a separar “RabbitMQ caído” de “clientes malusándolo”. Busca fallos de autenticación, conexiones bloqueadas (resource alarms) y errores frecuentes de canal. En la app, asegúrate de que cada intento de procesamiento registre un correlation ID, nombre de cola y resultado (acked, rejected, retried).
Si usas trazado distribuido, propaga encabezados de traza en las propiedades del mensaje para conectar “petición HTTP → mensaje publicado → trabajo del consumidor”.
Construye un dashboard por flujo crítico: tasa de publicación, tasa de ack, profundidad, unacked, requeues y número de consumidores. Añade enlaces directos al runbook interno, p. ej. /docs/monitoring, y una checklist “qué comprobar primero” para los on-call.
Cuando algo “simplemente deja de moverse”, resiste la tentación de reiniciar primero. La mayoría de los problemas se hacen evidentes mirando (1) bindings y enrutamiento, (2) salud del consumidor y (3) alarmas de recursos.
Si los publicadores informan “enviado con éxito” pero las colas están vacías (o la cola incorrecta se llena), revisa el enrutamiento antes del código.
Empieza en la UI de Management:
topic).Si la cola tiene mensajes pero nadie los consume, confirma:
Los duplicados vienen típicamente de reintentos (consumidor cae después de procesar pero antes de ack), interrupciones de red o requeue manual. Mitiga con handlers idempotentes (p. ej., dedupe por message ID en BD).
El desorden es esperado si tienes múltiples consumidores o requeues. Si el orden importa, usa un único consumidor para esa cola o particiona por clave en múltiples colas.
Las alarmas significan que RabbitMQ se protege:
Antes de reproducir, arregla la causa raíz y evita bucles de mensajes venenosos. Reencola en lotes pequeños, añade un tope de reintentos y anota metadata de fallo (conteo de intentos, último error). Considera enviar los mensajes reproducidos a una cola separada primero, para poder parar rápido si el mismo error vuelve a ocurrir.
Elegir una herramienta de mensajería no es tanto "mejor" sino emparejar patrón de tráfico, tolerancia a fallos y comodidad operativa.
RabbitMQ destaca cuando necesitas entrega fiable de mensajes y enrutado flexible entre componentes de aplicación. Es buena elección para flujos asíncronos clásicos —comandos, trabajos en background, notificaciones fan-out y patrones request/response— especialmente si quieres:
Si tu objetivo es mover trabajo más que conservar un largo historial de eventos, RabbitMQ suele ser un valor predeterminado cómodo.
Kafka y sistemas similares están diseñados para streaming de alto rendimiento y logs de eventos de larga duración. Elige un sistema tipo Kafka cuando necesites:
Contra: sistemas tipo Kafka pueden tener mayor sobrecarga operativa y te empujan a diseños orientados a throughput (batching, estrategia de partición). RabbitMQ suele ser más fácil para throughput moderado/alto con baja latencia end-to-end y enrutado complejo.
Si tienes una app que produce trabajos y un worker pool que los consume, y estás cómodo con semánticas más simples, una cola basada en Redis (o servicio gestionado) puede ser suficiente. Los equipos suelen sobrepasarla cuando necesitan garantías más fuertes de entrega, dead-lettering, múltiples patrones de enrutado o separación clara entre productores/consumidores.
Diseña contratos de mensajes como si pudieras migrar después:
Si luego necesitas streams reproducibles, puedes puentear eventos de RabbitMQ hacia un sistema tipo log manteniendo RabbitMQ para flujos operativos. Para un plan práctico de rollout, ver /blog/rabbitmq-rollout-plan-and-checklist.
Desplegar RabbitMQ funciona mejor si lo tratas como un producto: empieza pequeño, define propiedad y demuestra fiabilidad antes de expandirlo.
Elige un flujo que se beneficie del procesamiento asíncrono (p. ej., envío de correos, generación de reportes, sincronización con una API externa).
Si necesitas una plantilla de referencia para nombres, niveles de reintento y políticas básicas, centralízala en /docs.
Mientras implementas estos patrones, considera estandarizar el andamiaje entre equipos. Por ejemplo, equipos que usan Koder.ai a menudo generan un esqueleto de servicio productor/consumidor desde un prompt (incluyendo convención de nombres, wiring de retry/DLQ y headers de trace/correlation), exportan el código para revisión y iteran en "modo planificación" antes del rollout.
RabbitMQ tiene éxito cuando “alguien posee la cola”. Decide esto antes de producción:
Si formalizas soporte o hosting gestionado, alinea expectativas temprano (ver /pricing) y establece un canal de contacto para incidentes o onboarding en /contact.
Realiza ejercicios pequeños y limitados en el tiempo para generar confianza:
Una vez que un servicio sea estable por unas semanas, replica los mismos patrones —no los reinventes por equipo.
Usa RabbitMQ cuando quieras desacoplar servicios, absorber picos de tráfico o mover trabajo lento fuera del camino de la petición.
Encaja bien en trabajos en segundo plano (correos, PDFs), notificaciones a múltiples consumidores y flujos que deben seguir funcionando durante caídas temporales de dependencias.
Evítalo cuando necesites una respuesta inmediata (lecturas/validaciones simples) o cuando no estés dispuesto a gestionar versionado, reintentos y monitorización — esas cosas no son opcionales en producción.
Publica a un exchange y enruta a colas:
orders.* o orders.#.La mayoría de los equipos acaba usando topic exchanges para un enrutado de eventos mantenible.
Una cola almacena mensajes hasta que un consumidor los procesa; un binding es la regla que conecta un exchange con una cola.
Para depurar problemas de enrutamiento:
Estas tres comprobaciones explican la mayoría de los incidentes de “publicado pero no consumido”.
Usa una work queue cuando quieras que uno entre muchos workers procese cada tarea.
Consejos prácticos:
Entrega al menos una vez significa que un mensaje puede ser entregado más de una vez (por ejemplo, si un consumidor falla después de procesarlo pero antes de ack).
Haz que los consumidores sean seguros así:
message_id estable (o una clave de negocio) y registra los IDs procesados con un TTL.PENDING, o aplica restricciones de unicidad).Evita bucles de requeue cerrados. Un enfoque común es colas de reintento + DLQ:
Reproduce desde la DLQ solo tras arreglar la causa raíz y hazlo en lotes pequeños.
Empieza con nombres predecibles y trata los mensajes como APIs públicas:
schema_version en los payloads.Estandariza metadata:
Centra la observación en pocas señales que indiquen flujo de trabajo:
Alerta sobre tendencias (p. ej., “backlog creciendo durante 10 minutos”), y usa logs que incluyan el nombre de la cola, correlation_id y el resultado del procesamiento (acked/retried/rejected).
Haz lo básico y hazlo consistentemente:
Mantén un runbook interno corto para que los equipos sigan un estándar (por ejemplo, enlazado desde /docs/security).
Localiza dónde se detiene el flujo:
Reiniciar rara vez es la primera o mejor acción.
Asume que los duplicados son normales y diseña para ello.
correlation_id para unir eventos/comandos de una misma acción de negocio.trace_id (o encabezados W3C) para conectar trabajo asíncrono con trazas distribuidas.Esto facilita la incorporación y la respuesta a incidentes.