13 may 2025·8 min
Crea una aplicación web para rastrear la adopción del producto por nivel de cuenta
Aprende a diseñar datos, eventos y paneles para medir la adopción del producto por niveles de cuenta y actuar según los insights con alertas y automatizaciones.
Objetivos, usuarios y definiciones de niveles de cuenta
Antes de construir paneles o instrumentar eventos, aclara para qué sirve la app, a quién atiende y cómo se definen los niveles de cuenta. La mayoría de los proyectos de “seguimiento de adopción” fallan porque empiezan por los datos y acaban en desacuerdos.
Una regla práctica: si dos equipos no pueden definir “adopción” en la misma frase, luego no confiarán en el panel.
¿Quién usará esta app?
Nombra las audiencias principales y qué necesita hacer cada una tras revisar los datos:
- Producto: entender si las nuevas funciones se descubren, se usan de forma repetida y se retienen.
- Customer Success (CS): detectar brechas de onboarding, riesgo de adopción y cuentas que necesitan enablement.
- Ventas / Account Management: identificar señales de expansión (alto uso, amplitud de funciones) y riesgo de renovación.
- Ejecutivos: seguir la salud general de adopción y si las iniciativas estratégicas están moviendo la aguja.
Una prueba útil: cada audiencia debería poder responder “¿y qué?” en menos de un minuto.
Define “adopción” para tu producto
La adopción no es una métrica única. Escribe una definición con la que el equipo pueda estar de acuerdo—usualmente como una secuencia:
- Activación: el primer éxito significativo (p. ej., invitados, primer proyecto creado, configuración completada).
- Uso de la función: uso repetido de funciones clave que se correlacionan con valor (no clics vanidosos).
- Retención: el uso continúa semana tras semana/mes tras mes.
Mantenlo anclado en el valor al cliente: qué acciones señalan que están obteniendo resultados, no solo explorando.
Niveles de cuenta y reglas de asignación
Lista tus niveles y haz la asignación determinista. Niveles comunes incluyen SMB / Mid-Market / Enterprise, Free / Trial / Paid, o Bronze / Silver / Gold.
Documenta las reglas en lenguaje llano (y luego en código):
- ¿Qué fuente de verdad decide el nivel (sistema de facturación, CRM, tabla interna)?
- ¿El nivel se basa en ARR, asientos comprados, plan, industria o nivel de soporte?
- ¿Qué ocurre cuando los datos entran en conflicto (p. ej., CRM dice Enterprise, facturación dice Pro)?
- ¿Cuándo entra en efecto un cambio de nivel, y necesitas historial de niveles para reportes?
Decisiones que quieres soportar
Anota las decisiones que la app debe permitir. Por ejemplo:
- Onboarding: ¿quién no se ha activado dentro de 7 días?
- Riesgo: ¿qué cuentas de alto valor muestran uso en declive?
- Expansión: ¿qué cuentas están llegando a límites o adoptando múltiples funciones avanzadas?
3–5 preguntas clave del panel
Usa estas como criterios de aceptación:
- ¿Qué niveles están mejorando o empeorando en adopción este mes?
- Para cada nivel, ¿qué porcentaje de cuentas está activado y qué porcentaje se retiene?
- ¿Qué funciones marcan la mayor diferencia entre cuentas saludables y en riesgo por nivel?
- ¿Qué cuentas top en cada nivel necesitan intervención y por qué (brecha de activación, baja amplitud, caída en frecuencia)?
- Tras un lanzamiento o cambio de onboarding, ¿subió la adopción para el nivel objetivo?
Métricas de adopción que tienen sentido por nivel
Los niveles de cuenta se comportan de forma distinta, así que una única métrica de “adopción” castigará a clientes pequeños o esconderá riesgo en los grandes. Empieza definiendo qué éxito parece por nivel y luego elige métricas que reflejen esa realidad.
1) Elige resultados norte por nivel
Escoge un resultado principal que represente valor real:
- Starter/SMB: “Cuentas activadas” (llegaron al primer valor rápido).
- Mid-market: “Cuentas activas semanalmente con uso de funciones clave”.
- Enterprise: “Cuentas con adopción multi-equipo” o “cuentas que cumplen hitos de despliegue”.
Tu norte debe ser contable, segmentado por nivel y difícil de manipular.
2) Define etapas del embudo con calificación clara
Escribe tu embudo de adopción como etapas con reglas explícitas—para que la respuesta del panel no dependa de la interpretación.
Ejemplo de etapas:
- Invitado → Registrado: al menos un usuario creado
- Activado: checklist de configuración completado y primera acción clave realizada
- Integrado: al menos una integración clave conectada
- Adoptando: acciones clave repetidas en varios días/semanas
Las diferencias por nivel importan: la “Activación” en Enterprise puede requerir una acción de admin y al menos una acción de usuario final.
3) Elige indicadores líderes vs rezagados
Usa indicadores líderes para detectar impulso temprano:
- Configuración completada
- Integración clave conectada
- Primer flujo de trabajo publicado/compartido
Usa indicadores rezagados para confirmar adopción durable:
- Retención por nivel (p. ej., tasa activa a 4 semanas)
- Profundidad de uso (acciones por usuario activo, proyectos creados, asientos activos)
- Proxies de renovación (señales de salud contractual, eventos de expansión)
4) Establece objetivos realistas por nivel
Los objetivos deben reflejar tiempo-para-valor y complejidad organizacional. Por ejemplo, SMB puede apuntar a activación en 7 días; Enterprise a integración en 30–60 días.
Anota objetivos para que alertas y scorecards permanezcan consistentes entre equipos.
Modelo de datos para cuentas, usuarios e historial de niveles
Un modelo de datos claro evita “matemáticas misteriosas” después. Quieres responder preguntas simples—quién usó qué, en qué cuenta, bajo qué nivel, en ese momento—sin coser lógica ad-hoc en cada panel.
Entidades principales a modelar
Empieza con un conjunto pequeño de entidades que reflejen cómo compran y usan los clientes:
- Account: el registro del cliente al que vendes (empresa u organización). Guarda identificadores (
account_id), nombre, estado y campos de ciclo de vida (created_at,churned_at). - User: una persona. Incluye
user_id, dominio de email (útil para matching),created_at,last_seen_at. - Workspace / Project (opcional): si tu producto tiene múltiples espacios bajo una cuenta, módelos explícitamente con
workspace_idy una FK aaccount_id. - Subscription: el objeto de facturación. Guarda plan, periodo de facturación, asientos, MRR y timestamps.
- Tier: una tabla normalizada (p. ej., Free, Team, Business, Enterprise) para que los nombres se mantengan consistentes.
Decide la granularidad del tracking
Sé explícito sobre el “grain” analítico:
- Eventos a nivel de usuario responden: ¿Qué personas adoptaron la función X?
- Rollups a nivel de cuenta responden: ¿Está este cliente sano?
Un por defecto práctico es trackear eventos a nivel de usuario (con account_id adjunto) y luego agregar a nivel de cuenta. Evita eventos solo por cuenta salvo que no exista usuario (p. ej., importaciones de sistema).
Modela el tiempo: eventos vs snapshots
Los eventos te dicen qué pasó; los snapshots qué era verdad.
- Mantén una tabla de eventos como fuente de verdad.
- Añade snapshots diarios por cuenta (una fila por cuenta/día) para dashboards rápidos: usuarios activos, recuentos de funciones clave, puntuación de adopción y el nivel de ese día.
Captura el historial de niveles (los niveles cambian)
No sobrescribas el “nivel actual” y pierdas contexto. Crea una tabla account_tier_history:
account_id,tier_idvalid_from,valid_to(nullable para el actual)source(facturación, anulación de ventas)
Esto te permite calcular adopción mientras la cuenta era Team, aunque luego haya subido.
Documenta las definiciones de métricas
Escribe las definiciones una vez y trátalas como requisitos de producto: qué cuenta como “usuario activo”, cómo atribuyes eventos a cuentas y cómo manejas cambios de nivel a mitad de mes. Esto evita que dos paneles muestren dos verdades distintas.
Plan de tracking de eventos e instrumentación básica
Tu analítica de adopción solo será tan buena como los eventos que recolectes. Empieza mapeando un pequeño conjunto de acciones del “camino crítico” que indiquen progreso real por nivel, y luego instrúyelas de forma consistente en web, móvil y backend.
Eventos críticos a trackear
Enfócate en eventos que representen pasos significativos —no cada clic. Un conjunto práctico inicial:
signup_completed(cuenta creada)user_invitedyinvite_accepted(crecimiento del equipo)first_value_received(tu momento “aha”; defínelo explícitamente)key_feature_used(acción repetible de valor; puede haber múltiples por función)integration_connected(si las integraciones impulsan retención)
Propiedades de eventos (hazlas consultables)
Cada evento debe llevar suficiente contexto para cortar por nivel y por rol:
account_id(requerido)user_id(requerido cuando hay persona involucrada)tier(capturar en el momento del evento)plan(billing plan/SKU si es relevante)role(p. ej., owner/admin/member)- Opcional pero útil:
workspace_id,feature_name,source(web/mobile/api),timestamp
Convenciones de nombres que puedes imponer
Usa un esquema predecible para que los paneles no se conviertan en un proyecto de diccionario:
- Eventos: verbs en
snake_case, pasado (report_exported,dashboard_shared) - Propiedades: sustantivos consistentes (
account_id, noacctId) - Eventos de funciones: o eventos dedicados (
invoice_sent) o un único evento confeature_name; elige un enfoque y mantenlo.
Identidad: cross-device y multi-workspace
Soporta actividad anónima y autenticada:
- Asigna un
anonymous_iden la primera visita y enlázalo auser_idal iniciar sesión. - En productos multi-workspace, siempre incluye
workspace_idy mapea aaccount_idserver-side para evitar bugs del cliente.
Eventos server-side para fiabilidad
Instrumenta acciones del sistema en backend para que métricas clave no dependan de navegadores o bloqueadores. Ejemplos: subscription_started, payment_failed, seat_limit_reached, audit_log_exported.
Estos eventos server-side también son ideales como disparadores para alertas y workflows.
Canal de ingestión, almacenamiento y pipeline de agregación
Aquí el tracking se convierte en sistema: los eventos llegan desde tu app, se limpian, se guardan con seguridad y se convierten en métricas que el equipo puede usar.
Elige un camino de ingestión que encaje con tu producto
La mayoría de equipos usa una mezcla:
- SDK (cliente/servidor): lo mejor para tracking estructurado y consistente.
- HTTP API: bueno para servicios backend, partners o importar eventos.
- Logs de aplicación: útil si ya tienes logs ricos; necesitarás parsing y esquemas más estrictos.
- Message queue (Kafka/SQS/PubSub): ideal para alto volumen o cuando necesitas resiliencia y replay.
Hagas lo que hagas, trata la ingestión como un contrato: si un evento no se puede interpretar, debe ponerse en cuarentena, no aceptarse silenciosamente.
Normaliza temprano: timestamps, IDs y propiedades
En el momento de ingestión, estandariza los pocos campos que hacen que el reporting downstream sea fiable:
- Convierte todos los timestamps a UTC y guarda el timestamp original del origen cuando sea relevante.
- Mapea identificadores a formas canónicas:
account_id,user_id, y (si aplica)workspace_id. - Valida propiedades requeridas (p. ej.,
event_name,tier,plan,feature_key) y añade defaults solo cuando sean explícitos.
Almacena eventos crudos separados de agregados
Decide dónde viven los eventos crudos según coste y patrones de consulta:
- Warehouse (Snowflake/BigQuery/Redshift): más fácil para analítica y queries ad-hoc.
- Object storage (S3/GCS) + query engine: más barato a escala, con algo más de setup.
- BD operativa: solo para volúmenes pequeños; ojo al rendimiento.
Rollups: jobs programados que casan con decisiones
Construye jobs de agregación diarios/horarios que produzcan tablas como:
- Cuentas activas diarias por nivel
- Recuentos de adopción de funciones por nivel
- Inputs para la puntuación de adopción a nivel de cuenta
Mantén los rollups deterministas para poder re-ejecutarlos cuando definiciones de nivel o backfills cambien.
Reglas de retención
Define retenciones claras para:
- Eventos crudos: más largos (p. ej., 12–36 meses) para auditoría y reprocesos
- Agregados: más largos o indefinidos, ya que son compactos y alimentan paneles y alertas
Puntuación de adopción y rollups por nivel
Planifica tu MVP de adopción
Convierte tus definiciones de niveles, eventos y preguntas del panel en un plan de desarrollo en minutos.
Una puntuación de adopción da a equipos ocupados un número único para vigilar, pero solo funciona si es simple y explicable. Apunta a una puntuación 0–100 que refleje comportamientos significativos (no actividad vana) y pueda descomponerse en “por qué se movió”.
Una puntuación 0–100 simple y explicable
Empieza con una checklist ponderada, limitada a 100 puntos. Mantén pesos estables por un trimestre para que las tendencias sean comparables.
Ejemplo de ponderación (ajusta a tu producto):
- Activación (40 pts): pasos de onboarding completados, primer proyecto creado, invitado un teammate.
- Uso core (40 pts): usó la función principal en 3+ días distintos en los últimos 14 días.
- Expansión (20 pts): adoptó una función secundaria (integraciones, exportaciones, aprobaciones).
Cada comportamiento debe mapearse a una regla de evento clara (p. ej., “usó función core” = core_action en 3 días separados). Cuando la puntuación cambie, guarda factores contribuyentes para poder mostrar: “+15 por invitar 2 usuarios” o “-10 porque el uso core bajó por debajo de 3 días”.
Rollups por cuenta y por nivel
Calcula la puntuación por cuenta (snapshot diario o semanal), luego agrega por nivel usando distribuciones, no solo promedios:
- Mediana de puntuación por nivel
- 25º/75º percentiles (y opcionalmente 10º/90º)
- % de cuentas por encima de umbrales (p. ej., 60+ = “adopción saludable”)
Tendencias sin comparaciones engañosas
Registra cambio semanal y cambio en 30 días por nivel, pero evita mezclar tamaños de nivel:
- Muestra conteos (p. ej., 38 cuentas mejoraron) junto a porcentajes (p. ej., 12% mejoró).
Esto hace que niveles pequeños sean legibles sin que los grandes dominen la narrativa.
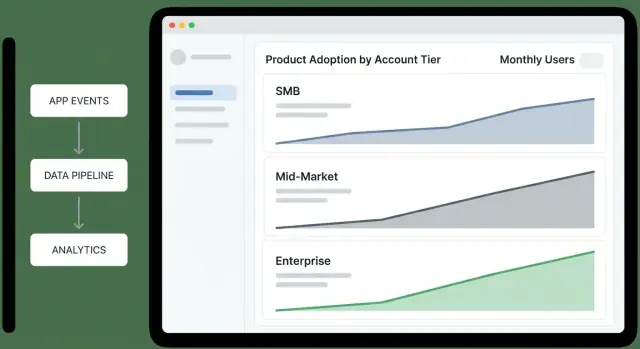
Paneles: vista por nivel y resumen ejecutivo
Un panel de vista por nivel debe permitir a un ejecutivo responder en un minuto: “¿Qué niveles mejoran, cuáles flaquean y por qué?” Trátalo como una pantalla de decisión, no un álbum de reportes.
Qué mostrar (y qué responde cada gráfico)
Embudo por nivel (Awareness → Activation → Habit): “¿Dónde se atascan las cuentas por nivel?” Mantén los pasos consistentes con tu producto (p. ej., “Usuarios invitados” → “Primera acción clave completada” → “Activos semanalmente”).
Tasa de activación por nivel: “¿Las cuentas nuevas o reactivadas alcanzan el primer valor?” Acompaña la tasa con el denominador (cuentas elegibles) para distinguir señal de ruido de muestras pequeñas.
Retención por nivel (p. ej., 7/28/90 días): “¿Mantienen las cuentas el uso tras el primer triunfo?” Muestra una línea simple por nivel; evita sobre-segmentar en la vista general.
Profundidad de uso (amplitud de funciones): “¿Adoptan varias áreas del producto o se quedan superficiales?” Un bar apilado por nivel funciona: % usando 1 área, 2–3 áreas, 4+ áreas.
Comparaciones que impulsan acción
Añade dos comparaciones en todas partes:
- Esta semana vs la semana pasada (o últimos 7 vs 7 previos) para feedback rápido.
- Nivel vs nivel para detectar mismatch (p. ej., SMB superando a Enterprise en activación).
Usa deltas consistentes (puntos porcentuales absolutos) para que los ejecutivos escaneen rápido.
Filtros que no rompen la historia
Limita filtros, hazlos globales y persistentes:
- Rango de tiempo (preajustes más custom)
- Área del producto (para contexto de profundidad de uso)
- Región (para revelar efectos de rollout o mercado)
- Owner de cuenta (para responsabilidad GTM)
Si un filtro cambiaría la definición de métricas, no lo ofrezcas aquí—llévalo a vistas de drill-down.
“Principales drivers” por nivel
Incluye un panel pequeño por nivel: “¿Qué se asocia más con mayor adopción este periodo?” Ejemplos:
- Top 3 funciones/eventos correlacionados con alta puntuación
- Paso del embudo con mayor caída
- Cuentas con mayor cambio semana a semana (positivo y negativo)
Mantenlo explicable: prefiere “Cuentas que configuraron X en los primeros 3 días retienen 18pp más” sobre salidas opacas de modelos.
Un layout útil
Coloca tarjetas KPI por nivel arriba (activación, retención, profundidad), una pantalla de gráficos de tendencia en el centro y drivers + siguientes acciones abajo. Cada widget debe responder una pregunta—si no, no va en el resumen ejecutivo.
Vistas de drill-down: de nivel a cuentas individuales
Un panel por nivel es útil para priorizar, pero el trabajo real ocurre cuando puedes hacer clic para ver por qué un nivel se movió y quién necesita atención. Diseña las vistas de drill-down como un camino guiado: nivel → segmento → cuenta → usuario.
Nivel → Segmento: estrecha la pregunta
Empieza con una tabla de resumen por nivel y permite cortar por segmentos significativos sin construir reportes custom. Filtros comunes:
- Estado de onboarding (no iniciado / en progreso / completo)
- Industria, plan, región, etapa de ciclo de vida
- “En riesgo” vs “saludable” según tu puntuación de adopción
Cada página de segmento debe responder: “¿Qué cuentas están impulsando la puntuación de este nivel hacia arriba o abajo?” Incluye lista ordenada de cuentas con cambio de puntuación y funciones contribuyentes.
Vista de perfil de cuenta: línea de tiempo, puntuación, hitos
Tu perfil de cuenta debe sentirse como un expediente:
- Línea de uso (30/90 días): eventos clave, días activos, toques de funciones importantes
- Puntuación de adopción con desglose simple (activación, amplitud, profundidad)
- Hitos: primera acción clave, función X adoptada, invitados enviados, umbral Y alcanzado
Hazlo escaneable: muestra deltas (“+12 esta semana”) y anota picos con el evento/función que los causó.
Drill-down por usuario y vistas de cohortes
Desde la página de cuenta, lista usuarios por actividad reciente y rol. Al hacer clic en un usuario muestra su uso de funciones y último visto.
Añade vistas de cohortes para explicar patrones: mes de signup, programa de onboarding y nivel al registrarse. Esto ayuda a CS a comparar similar con similar en vez de mezclar cuentas nuevas con maduras.
Adopción de funciones por nivel + exportación para workflows
Incluye una vista “Quién usa qué” por nivel: tasa de adopción, frecuencia y tendencias, con lista clicable de cuentas que usan (o no usan) cada función.
Para CS y Ventas, añade opciones de exportar/compartir: exportar CSV, vistas guardadas y enlaces internos compartibles (p. ej., /accounts/{id}) que abran con filtros aplicados.
Alertas y workflows accionables por nivel
Crea el panel de resumen de niveles
Prototipa un panel en React y vistas detalladas a partir de un chat sencillo.
Los paneles ayudan a entender adopción, pero los equipos actúan cuando reciben un empujón en el momento correcto. Las alertas deben ligarse al nivel de cuenta para que CS y Ventas no reciban ruido de bajo valor—o, peor, pierdan problemas críticos en las cuentas más valiosas.
Define señales de riesgo por nivel
Empieza con unas pocas señales de “algo va mal”:
- Caída de uso: descenso significativo en usuarios activos semanales, eventos clave o sesiones vs la línea base de la cuenta.
- Onboarding estancado: sin progreso tras hitos de activación dentro de la ventana esperada.
- Baja activación: la cuenta no alcanza el umbral mínimo de “aha” tras signup o compra.
Haz estas señales conscientes del nivel. Por ejemplo, Enterprise puede alertar en una caída del 15% semana a semana en un workflow core, mientras SMB puede requerir 40% para evitar ruido por uso esporádico.
Define señales de expansión por nivel
Las alertas de expansión deben destacar cuentas que están creciendo en valor:
- Aparición de power users: varios usuarios completando workflows de alto valor repetidamente.
- Amplitud de funciones: adopción en varias funciones clave (no solo una).
- Alto crecimiento: aumento de asientos, invitaciones enviadas o incrementos sostenidos de usuarios activos.
De nuevo, los umbrales difieren por nivel: un power user importa en SMB; para Enterprise la expansión debería requerir adopción multi-equipo.
Notificaciones que impulsan acción
Enruta alertas a donde se hace el trabajo:
- Slack/email para señales en tiempo real (p. ej., onboarding estancado en una cuenta top).
- Resumen semanal para insights de menor urgencia (p. ej., cuentas con tendencia positiva en amplitud de funciones).
Mantén la carga útil accionable: nombre de la cuenta, nivel, qué cambió, ventana de comparación y un enlace al drill-down (p. ej., /accounts/{account_id}).
Playbooks: qué hacer cuando salta una alerta
Cada alerta necesita un dueño y un playbook corto: quién responde, las 2–3 primeras comprobaciones (frescura de datos, releases recientes, cambios admin) y el outreach o guía in-app recomendada.
Documenta playbooks junto a las definiciones de métricas para que las respuestas sean consistentes y las alertas mantengan su confianza.
Calidad de datos, monitorización y gobernanza de métricas
Si las métricas de adopción impulsan decisiones por nivel (outreach de CS, conversaciones de pricing, bets de roadmap), los datos necesitan guardrails. Un conjunto pequeño de checks y hábitos de gobernanza evitarán “caídas misteriosas” en paneles y mantendrán a las partes alineadas sobre el significado de los números.
Validación en el borde
Valida eventos lo antes posible (SDK cliente, gateway API o worker de ingestión). Rechaza o cuarentena eventos que no se puedan confiar.
Implementa checks como:
- Falta de
account_idouser_id(o valores que no existen en la tabla de cuentas) - Valores de
tierinválidos (fuera del enum aprobado) - Timestamps imposibles (futuro/lejos en el pasado) y propiedades requeridas faltantes para eventos clave
Mantén una tabla de cuarentena para inspeccionar eventos malos sin contaminar la analítica.
Monitoriza volumen y frescura
El seguimiento de adopción es sensible al tiempo; eventos tardíos distorsionan usuarios activos semanales y rollups por nivel. Monitoriza:
- Volumen de eventos por tipo y nivel (picos/caídas súbitas)
- Frescura y distribución de retrasos (p. ej., p95 de lag de ingestión)
- Salud del pipeline (jobs fallidos, backfills en curso, dependencias rotas)
Enruta monitores a un canal on-call, no a todo el mundo.
Duplicados, reintentos e idempotencia
Los reintentos ocurren (red móvil, redeliveries de webhooks, replays de batch). Haz la ingestión idempotente usando un idempotency_key o un event_id estable, y dedupe en una ventana temporal.
Tus agregaciones deben ser re-ejecutables sin doble conteo.
Gobernanza de métricas: un significado, un owner
Crea un glosario que defina cada métrica (inputs, filtros, ventana temporal, reglas de atribución de nivel) y trátalo como la única fuente de verdad. Enlaza paneles y docs a ese glosario (p. ej., /docs/metrics).
Añade logs de auditoría para cambios en definiciones y reglas de scoring—quién cambió qué, cuándo y por qué—para poder explicar rápidamente cambios en tendencias.
Privacidad, seguridad y control de acceso
Itera sin romper la confianza
Experimenta de forma segura con instantáneas y reversiones cuando cambian las reglas de métricas.
La analítica de adopción solo es útil si la gente confía en ella. Lo más seguro es diseñar la app para responder preguntas de adopción recogiendo la menor cantidad de datos sensibles posible, y hacer de “quién puede ver qué” una característica de primera clase.
Minimiza datos personales (por diseño)
Empieza con identificadores suficientes para insights de adopción: account_id, user_id (o un id seudónimo), timestamp, función y un pequeño set de propiedades de comportamiento (plan, nivel, plataforma). Evita capturar nombres, emails, inputs en texto libre o cualquier cosa que pueda contener secretos.
Si necesitas análisis a nivel de usuario, almacena identificadores de usuario separados de PII y únelos solo cuando sea necesario. Trata IPs y device ids como sensibles; si no los necesitas para scoring, no los guardes.
Roles, permisos y defaults seguros
Define roles claros:
- Exec/Leadership: rollups por cuenta y nivel
- CS/Sales: detalles por cuenta; vistas limitadas a nivel de usuario si hace falta
- Producto/Analytics: exploración profunda a nivel de usuario con trails de auditoría
- Admin: configuración, retención y controles de eliminación
Por defecto muestra vistas agregadas. Hacer drill-down a nivel de usuario debe ser un permiso explícito y oculta campos sensibles (emails, nombres completos, ids externos) salvo que un rol lo requiera.
Retención, eliminación y consentimiento
Soporta solicitudes de eliminación pudiendo remover el historial de eventos de un usuario (o anonimizarlo) y eliminar datos de cuenta al terminar contrato.
Implementa reglas de retención (por ejemplo, eventos crudos N días, agregados más tiempo) y documéntalas en tu política. Registra consentimiento y responsabilidades de procesamiento donde aplique.
Opciones de arquitectura y roadmap práctico de construcción
La forma más rápida de obtener valor es elegir una arquitectura que casen con donde ya viven tus datos. Puedes evolucionarla después—lo importante es poner insights por nivel en manos de la gente.
Dos enfoques comunes de construcción
Warehouse-first analytics: los eventos fluyen a un warehouse (BigQuery/Snowflake/Postgres), luego calculas métricas de adopción y las sirves a una app web ligera. Ideal si ya usas SQL, tienes analistas o quieres una fuente de verdad compartida.
App-first analytics: la app escribe eventos en su propia BD y calcula métricas en la aplicación. Puede ser más rápido para un producto pequeño, pero es más fácil de superar cuando crece el volumen de eventos y la necesidad de reprocesos históricos.
Un por defecto práctico para la mayoría de equipos SaaS es warehouse-first con una pequeña BD operativa para tablas de configuración (niveles, definiciones de métricas, reglas de alerta).
Componentes núcleo (mantenlo simple)
- Web UI: vista por nivel + páginas de drill-down de cuenta.
- API: sirve métricas pre-agregadas, listas de cuentas y filtros.
- Warehouse / DB analítica: eventos crudos + tablas modeladas para métricas diarias de adopción.
- Job runner: transformaciones programadas (diarias/horarias), backfills y scoring.
Decisiones de comprar vs construir que ahorran semanas
- Gráficos: empieza con una librería probada (o embebe una herramienta BI) en vez de construir primitives.
- Auth: usa un provider establecido (SSO, roles) para evitar fallos de seguridad.
- Recolección de eventos: usa un SDK o gateway confiable; construye un collector custom solo si tienes requisitos estrictos.
Roadmap MVP (2–4 semanas)
Lanza una primera versión con:
-
3–5 métricas (p. ej., cuentas activas, uso de función clave, puntuación de adopción, retención semanal, tiempo al primer valor).
-
Una página de vista por nivel: puntuación de adopción por nivel + tendencia en el tiempo.
-
Una vista de cuenta: nivel actual, última actividad, funciones top usadas y un “por qué la puntuación es lo que es”.
Iterar sin romper la confianza
Añade bucles de feedback temprano: permite que Ventas/CS marquen “esto parece incorrecto” desde el panel. Versiona definiciones de métricas para cambiar fórmulas sin reescribir el histórico en silencio.
Haz rollout gradual (un equipo → toda la org) y mantén un changelog de actualizaciones de métricas en la app (p. ej., /docs/metrics) para que stakeholders siempre sepan qué ven.
Dónde encaja Koder.ai (prototipado rápido sin vendor lock-in)
Si quieres pasar de “especificación” a una app interna funcionando rápidamente, un enfoque de vibe-coding puede ayudar—especialmente en la fase MVP cuando validas definiciones, no perfecciones infraestructura.
Con Koder.ai, los equipos pueden prototipar una app de adopción a través de una interfaz conversacional y generar código real y editable. Esto encaja bien porque el alcance es transversal (UI React, una API, modelo Postgres y rollups programados) y suele evolucionar rápido a medida que los stakeholders convergen en definiciones.
Un workflow común:
- Usa Planning Mode para mapear el modelo de niveles, esquema de eventos y preguntas del panel en un plan de implementación.
- Genera un UI en React y un backend en Go respaldado por PostgreSQL para tablas de configuración (niveles, definiciones de métricas, reglas de alerta).
- Exporta el código cuando estés listo para entregarlo a ingeniería y usa snapshots/rollback para iterar seguro conforme cambian definiciones.
Como Koder.ai soporta despliegue/hosting, dominios personalizados y export de código, puede ser una forma práctica de llegar a un MVP interno creíble manteniendo abiertas las decisiones arquitectónicas a largo plazo (warehouse-first vs app-first).
Preguntas frecuentes
¿Qué significa “adopción del producto” en un producto B2B SaaS con niveles?
Empieza con una definición compartida de adopción como una secuencia:
- Activación: el primer éxito significativo que demuestra valor.
- Uso de funciones: uso repetido de las funciones clave que generan valor.
- Retención: uso continuado semana tras semana/mes tras mes.
Luego hazla consciente del nivel de cuenta (por ejemplo, activación de SMB en 7 días frente a Enterprise que requiere acciones del administrador y de usuarios finales).
¿Por qué debería segmentar el seguimiento de adopción por nivel de cuenta?
Porque los niveles se comportan de forma diferente. Una única métrica puede:
- Castigar a SMB por una frecuencia naturalmente menor.
- Ocultar el riesgo en Enterprise cuando unos pocos usuarios intensivos enmascaran la baja adopción por equipos.
Segmentar por nivel te permite fijar objetivos realistas, elegir la métrica norte adecuada por nivel y activar las alertas correctas para las cuentas de mayor valor.
¿Cómo defino los niveles de cuenta para que los informes sean consistentes en el tiempo?
Usa un conjunto de reglas deterministas y documentadas:
- Elige una fuente de verdad (facturación, CRM o una tabla interna de mapeo).
- Define desempates para conflictos (p. ej., facturación prevalece sobre CRM salvo que haya una anulación de ventas).
- Establece una fecha de efecto y guarda un historial en
account_tier_historyconvalid_from/ .
¿Cuál es una buena métrica “norte” para la adopción por nivel?
Elige un resultado principal por nivel que represente valor real:
- Starter/SMB: cuentas activadas (tiempo rápido al primer valor).
- Mid-market: cuentas activas semanalmente que usan funciones clave.
- Enterprise: adopción multi-equipo o hitos de despliegue.
Que sea contable, difícil de manipular y claramente ligado a resultados del cliente —no a clics—.
¿Cómo diseño un embudo de adopción con definiciones de etapa inequívocas?
Define etapas explícitas y reglas de calificación para que la interpretación no derive. Ejemplo:
- Invitado → Registrado: al menos un usuario creado.
- Activado: checklist de configuración completado y primera acción clave realizada.
- Integrado: al menos una integración conectada.
- : acciones clave repetidas en varios días/semanas.
¿Qué eventos debo instrumentar primero para el seguimiento de adopción?
Instrumenta un pequeño conjunto de eventos críticos:
signup_completeduser_invited,invite_acceptedfirst_value_received(define con precisión tu “aha”)
¿Qué propiedades de eventos son esenciales para la analítica de adopción por nivel?
Incluye propiedades que permitan segmentar y atribuir con fiabilidad:
¿Debo modelar la adopción con eventos crudos, snapshots o ambos?
Usa ambos:
- Eventos crudos como fuente de verdad.
- Snapshots diarios por cuenta para paneles rápidos (una fila por cuenta y día).
Los snapshots suelen almacenar usuarios activos, recuentos clave por función, componentes de la puntuación de adopción y el nivel de ese día, para que los cambios de nivel no reescriban históricos.
¿Cómo puedo construir una puntuación de adopción en la que los equipos confíen?
Hazla simple, explicable y estable:
- Puntuación 0–100 basada en una lista ponderada (p. ej., Activación 40, Uso core 40, Expansión 20).
- Define cada regla en términos de eventos (por ejemplo, uso core =
core_actionen 3 días distintos dentro de 14 días). - Guarda factores contribuyentes para poder explicar por qué cambió.
Agrupa por nivel usando distribuciones (mediana, percentiles, % por encima de un umbral), no solo promedios.
¿Cómo configuro alertas conscientes del nivel sin saturar a CS y Ventas?
Haz las alertas específicas por nivel y accionables:
- Señales de riesgo: caída de uso respecto a la línea base, onboarding estancado, baja activación.
- Señales de expansión: aumento de asientos, más usuarios activos, adopción más amplia de funciones.
Enruta notificaciones al lugar donde se actúa (Slack/email para urgentes, resúmenes semanales para menor urgencia) e incluye lo esencial: qué cambió, ventana de comparación y un enlace al detalle como /accounts/{account_id}.