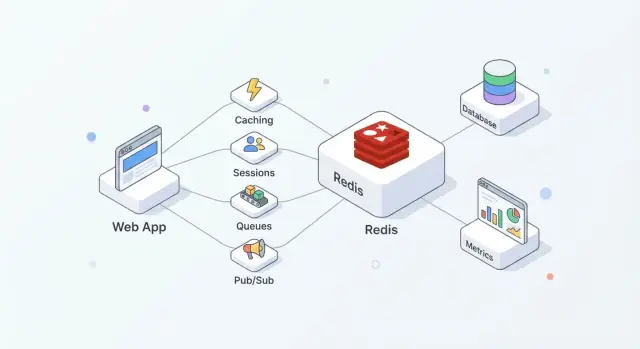
Qué hace Redis por las aplicaciones modernas
Redis es un almacén en memoria usado a menudo como una “capa rápida” compartida para aplicaciones. A los equipos les gusta porque es fácil de adoptar, extremadamente rápido para operaciones comunes y suficientemente flexible como para asumir más de una tarea (caché, sesiones, contadores, colas, pub/sub) sin introducir un sistema nuevo por cada necesidad.
En la práctica, Redis funciona mejor cuando lo tratas como velocidad + coordinación, mientras que tu base de datos principal sigue siendo la fuente de la verdad.
Dónde encaja Redis en una arquitectura típica
Una configuración común se ve así:
- Base de datos: datos durables y autorizados (pedidos, usuarios, facturas)
- Redis: acceso rápido y estado efímero compartido (páginas en caché, tokens de sesión, contadores de límite de tasa)
- App: decide qué va dónde y cuándo refrescar, invalidar o reconstruir
Esta separación mantiene tu base de datos enfocada en corrección y durabilidad, mientras que Redis absorbe lecturas/escrituras de alta frecuencia que, de otro modo, dispararían la latencia o la carga.
Qué sueles obtener de Redis
Usado correctamente, Redis suele ofrecer algunos resultados prácticos:
- Lecturas más rápidas: servir datos solicitados con frecuencia desde memoria en lugar de golpear la base de datos cada vez.
- Picos de tráfico más suaves: caché y contadores ligeros te ayudan a sobrevivir ráfagas sin que la DB sea el cuello de botella.
- Coordinación más simple: múltiples servidores de app pueden compartir estado efímero (sesiones, locks, claves de deduplicación) en lugar de reconstruir esa lógica por instancia.
Cuándo Redis no es la herramienta adecuada
Redis no reemplaza una base de datos primaria. Si necesitas consultas complejas, garantías de almacenamiento a largo plazo o reporting analítico, tu base de datos sigue siendo el lugar correcto.
Tampoco asumas que Redis es “durable por defecto”. Si perder incluso unos segundos de datos es inaceptable, necesitarás ajustes cuidadosos de persistencia—o un sistema diferente—según tus requerimientos reales de recuperación.
Fundamentos de Redis que debes conocer antes de implementar
A menudo se describe Redis como un “almacén clave-valor”, pero es más útil pensar en él como un servidor muy rápido que puede almacenar y manipular pequeñas piezas de datos por nombre (la clave). Ese modelo fomenta patrones de acceso previsibles: típicamente sabes exactamente lo que quieres (una sesión, una página cacheada, un contador) y Redis puede obtenerlo o actualizarlo en un solo viaje de ida y vuelta.
Por qué es rápido: memoria primero
Redis guarda datos en RAM, por eso puede responder en microsegundos a milisegundos bajos. El trade-off es que la RAM es limitada y más cara que el disco.
Decide desde temprano si Redis es:
- Solo una capa de rendimiento (cache puro), o
- Parte de la ruta de estado (sesiones, colas), donde el comportamiento al reiniciar y la configuración de persistencia importan
Redis puede persistir datos a disco (snapshots RDB y/o AOF append-only logs), pero la persistencia añade sobrecarga de escritura y obliga a elegir niveles de durabilidad (por ejemplo, “rápido pero puede perder un segundo” vs “más lento pero más seguro”). Trata la persistencia como una perilla que ajustas según el impacto en el negocio, no como una casilla que marcas automáticamente.
Monohilo no significa lento
Redis ejecuta comandos mayoritariamente en un único hilo, lo que suena limitante hasta que recuerdas dos cosas: las operaciones suelen ser pequeñas y no hay overhead de locking entre múltiples hilos de trabajo. Siempre que evites comandos costosos y cargas útiles sobredimensionadas, este modelo puede ser extremadamente eficiente bajo alta concurrencia.
Clientes, conexiones y patrones de petición
Tu app habla con Redis por TCP usando bibliotecas cliente. Usa pooling de conexiones, mantén las peticiones pequeñas y prefiere batching/pipelining cuando necesites múltiples operaciones.
Planifica timeouts y reintentos: Redis es rápido, pero las redes no lo son, y tu aplicación debe degradarse con gracia cuando Redis esté ocupado o temporalmente inaccesible.
Si estás construyendo un nuevo servicio y quieres estandarizar estos básicos rápido, una plataforma como Koder.ai puede ayudarte a esbozar una aplicación React + Go + PostgreSQL y luego añadir funciones respaldadas por Redis (caché, sesiones, limitación de tasa) mediante un flujo guiado por chat—mientras te permite exportar el código fuente y ejecutarlo donde necesites.
Patrones de caché que funcionan en aplicaciones reales
La caché solo ayuda cuando tiene una propiedad clara: quién la llena, quién la invalida y qué significa “suficientemente fresco”.
El patrón cache-aside (el predeterminado para la mayoría de apps)
Cache-aside significa que tu aplicación—no Redis—controla lecturas y escrituras.
Flujo típico:
- Leer: buscar el ítem en Redis.
- Hit: devolverlo inmediatamente.
- Miss: obtenerlo de la fuente de datos primaria (DB, API, servicio).
- Poblar: almacenar el resultado en Redis con un TTL.
- Devolver: responder al solicitante.
Redis es un almacén rápido clave-valor; tu app decide cómo serializar, versionar y expirar entradas.
TTLs: elegir expiraciones sin sorprender a los usuarios
Un TTL es tanto una decisión de producto como técnica. TTLs cortos reducen la obsolescencia pero aumentan la carga en la DB; TTLs largos ahorran trabajo pero arriesgan resultados desactualizados.
Consejos prácticos:
- Ajusta al ritmo natural de actualización de los datos (por ejemplo, precios vs foto de perfil).
- Usa claves versionadas para “cambios de esquema” (p. ej.,
user:v3:123) para que formas cacheadas antiguas no rompan el código nuevo.
- Maneja la obsolescencia intencionalmente: para algunas vistas, contenido ligeramente obsoleto está bien; para otras (inventario, auth), no.
Evitar la avalancha de caché (cache stampede)
Cuando una clave caliente expira, muchas peticiones pueden fallar a la vez.
Defensas comunes:
- Coalescencia de peticiones: permitir que solo una petición reconstruya el valor mientras las demás esperan o sirven el valor previo.
- Jitter en TTL: añadir aleatoriedad para que muchas claves no expiren simultáneamente.
- TTL suave: tratar un valor como “obsoleto pero usable” brevemente mientras un refresco en background actualiza Redis.
Qué cachear (y qué evitar)
Candidatos buenos incluyen respuestas de API, resultados de consultas costosas y objetos computados (recomendaciones, agregaciones). Cachear páginas HTML completas puede funcionar, pero ten cuidado con la personalización y permisos: cachea fragmentos cuando hay lógica específica por usuario.
Almacenamiento de sesiones y flujos de autenticación
Redis es un lugar práctico para mantener estado de login de corta duración: IDs de sesión, metadatos de refresh-token y flags de “recordar este dispositivo”. El objetivo es hacer la autenticación rápida manteniendo la vida de la sesión y la revocación bajo control estricto.
Usar Redis para sesiones de usuario
Un patrón común: tu app emite un session ID aleatorio, almacena un registro compacto en Redis y devuelve el ID al navegador como cookie HTTP-only. En cada petición, buscas la clave de sesión y adjuntas la identidad y permisos al contexto de la solicitud.
Redis funciona bien aquí porque las lecturas de sesión son frecuentes y la expiración está incorporada.
Diseño de claves y gestión de TTL
Diseña claves para que sean fáciles de escanear y revocar:
sess:{sessionId} → payload de la sesión (userId, issuedAt, deviceId)user:sessions:{userId} → un Set de session IDs activos (opcional, para “cerrar sesión en todos”)
Usa un TTL en sess:{sessionId} que coincida con la vida de la sesión. Si rotas sesiones (recomendado), crea un nuevo session ID y elimina el anterior inmediatamente.
Ten cuidado con la “expiración deslizante” (extender TTL en cada petición): puede mantener sesiones vivas indefinidamente para usuarios muy activos. Un compromiso más seguro es extender el TTL solo cuando esté cerca de expirar.
Revocación y cierre de sesión en múltiples dispositivos
Para cerrar la sesión de un solo dispositivo, elimina sess:{sessionId}.
Para cerrar en todos los dispositivos, o bien:
- elimina todos los session IDs encontrados en
user:sessions:{userId}, o
- mantén un timestamp
user:revoked_after:{userId} y trata cualquier sesión emitida antes como inválida
El método del timestamp evita borrados con fan-out grande.
Privacidad y seguridad
Almacena lo mínimo necesario en Redis—prefiere IDs sobre datos personales. Nunca almacenes contraseñas en claro ni secretos de larga duración. Si debes almacenar datos relacionados con tokens, guarda hashes y usa TTLs estrictos.
Limita quién puede conectar a Redis, exige autenticación y mantén los session IDs con alta entropía para prevenir adivinanzas.
Limitación de tasa y prevención de abuso
La limitación de tasa es donde Redis brilla: es rápido, compartido entre instancias de app y ofrece operaciones atómicas que mantienen contadores consistentes bajo tráfico intenso. Es útil para proteger endpoints de login, búsquedas costosas, flujos de restablecimiento de contraseña y cualquier API que pueda ser scrapeada o atacada por fuerza bruta.
Modelos comunes de limitación de tasa
Ventana fija es lo más simple: “100 peticiones por minuto.” Cuentas peticiones en el bucket del minuto actual. Es fácil, pero puede permitir ráfagas en los límites de borde (p. ej., 100 a las 12:00:59 y 100 a las 12:01:00).
Ventana deslizante suaviza los límites mirando los últimos N segundos/minutos en vez del bucket actual. Es más equitativa, pero suele costar más (puede requerir sorted sets o más contabilidad).
Token bucket es excelente para manejar ráfagas. Los usuarios “ganan” tokens con el tiempo hasta un tope; cada petición consume un token. Esto permite picos cortos mientras se aplica una tasa promedio.
Bloques base seguros: INCR/EXPIRE y atomicidad
Un patrón de ventana fija común es:
INCR key para incrementar un contadorEXPIRE key window_seconds para fijar/resetear el TTL
El truco es hacerlo de forma segura. Si ejecutas INCR y EXPIRE como llamadas separadas, un fallo entre ellas puede crear claves que nunca expiren.
Enfoques más seguros incluyen:
- Usar un script Lua para realizar
INCR y setear EXPIRE solo cuando el contador se crea por primera vez.
- O usar
SET key 1 EX <ttl> NX para inicializar, luego INCR después (a menudo envuelto en un script para evitar carreras).
Las operaciones atómicas importan especialmente cuando hay picos de tráfico: sin ellas, dos peticiones pueden “ver” la misma cuota restante y ambas pasar.
Ámbito: por usuario, por IP, por ruta (y ráfagas)
La mayoría de apps necesita múltiples capas:
- Por usuario límites para llamadas autenticadas (p. ej.,
rl:user:{userId}:{route})
- Por IP límites para endpoints anónimos o pre-auth (p. ej., intentos de sign-in)
- Por ruta límites para proteger puntos calientes (search, exports, reporting)
Para endpoints con ráfagas, token bucket (o una ventana fija generosa más una ventana corta de “burst”) ayuda a no penalizar picos legítimos como cargas de página o reconexiones móviles.
Cuando Redis no está disponible: fail-open vs fail-closed
Decide desde el inicio qué significa “seguro”:
- Fail-open: permitir peticiones si Redis no se alcanza. Mejor uptime y experiencia, pero protección de abuso más débil.
- Fail-closed: denegar peticiones cuando Redis falla. Protección más fuerte, pero riesgo de dejar tu app parcialmente offline.
Un compromiso común es fail-open para rutas de bajo riesgo y fail-closed para las sensibles (login, restablecimiento de contraseña, OTP), con monitorización para notar el momento en que la limitación deja de funcionar.
Colas y Jobs en background con Redis
Construye y gana créditos
Obtén créditos compartiendo lo que creaste en Koder.ai o refiriendo a un compañero.
Redis puede alimentar trabajos en background cuando necesitas una cola ligera para enviar emails, redimensionar imágenes, sincronizar datos o ejecutar tareas periódicas. La clave es elegir la estructura de datos adecuada y tener reglas claras para reintentos y manejo de fallos.
Lists, sorted sets y streams: cuál usar y por qué
Lists son la cola más simple: los productores hacen LPUSH, los workers BRPOP. Son sencillas, pero necesitarás lógica adicional para jobs “en vuelo”, reintentos y visibility timeouts.
Sorted sets brillan cuando la programación importa. Usa el score como timestamp (o prioridad) y los workers obtienen el siguiente job debido. Esto encaja con jobs retrasados y colas con prioridad.
Streams suelen ser la mejor opción por defecto para distribución de trabajo durable. Soportan consumer groups, mantienen un historial y permiten que múltiples workers coordinen sin inventar tu propia lista de “procesamiento”.
Acknowledgements, reintentos y manejo de dead-letter
Con Streams y consumer groups, un worker lee un mensaje y luego lo ACKea. Si un worker cae, el mensaje queda pendiente y otro worker puede reclamarlo.
Para reintentos, lleva un conteo de intentos (en el payload del mensaje o en una clave lateral) y aplica backoff exponencial (a menudo vía un sorted set de “programación de reintentos”). Tras un máximo de intentos, mueve el job a una dead-letter queue (otra stream o lista) para revisión manual.
Estrategias de idempotencia para workers
Asume que los jobs pueden ejecutarse dos veces. Haz handlers idempotentes mediante:
- Usar una clave de idempotencia (p. ej.,
job:{id}:done) con SET ... NX antes de efectos secundarios
- Diseñar operaciones como upserts, no como “crear a ciegas”
- Registrar IDs de petición externos al llamar APIs de terceros
Mantener jobs pequeños y usar backpressure
Mantén payloads pequeños (almacena datos grandes en otro lado y pasa referencias). Añade backpressure limitando la longitud de la cola, ralentizando productores cuando el lag crece y escalando workers según profundidad pendiente y tiempo de procesamiento.
Pub/Sub y distribución de eventos
Redis Pub/Sub es la forma más simple de difundir eventos: los publishers envían un mensaje a un canal y cada suscriptor conectado lo recibe inmediatamente. No hay polling—solo un “push” ligero que funciona bien para actualizaciones en tiempo real.
Usos comunes adecuados para Pub/Sub
Pub/Sub funciona cuando te importa la velocidad y el fan-out más que la entrega garantizada:
- Notificaciones para el usuario ("tu informe está listo")
- Actualizaciones de UI en vivo (presencia, indicadores de escritura, dashboards)
- Fan-out de eventos internos (un evento dispara múltiples servicios)
Una buena metáfora: Pub/Sub es como una emisora de radio. Cualquiera que esté sintonizado oye la transmisión, pero nadie obtiene automáticamente una grabación.
Límites clave a planear
Pub/Sub tiene trade-offs importantes:
- Sin persistencia: si nadie está suscrito en el momento de publicar, el mensaje se pierde.
- Fiabilidad del suscriptor: si un suscriptor se desconecta o se sobrecarga, puede perder mensajes.
- Sin replay ni acknowledgements: no puedes pedir a Redis que “entregue hasta confirmar”.
Por esto, Pub/Sub es mala opción para flujos donde cada evento debe ser procesado (exactly-once o incluso at-least-once).
Cuándo preferir Redis Streams
Si necesitas durabilidad, reintentos, consumer groups o manejo de backpressure, Redis Streams suelen ser la mejor opción. Streams te permiten almacenar eventos, procesarlos con acknowledgements y recuperarte tras reinicios—más cercano a una cola ligera.
Patrones para apps multi-instancia
En despliegues reales tendrás varias instancias suscribiéndose. Algunos consejos prácticos:
- Namespacea los canales para evitar colisiones:
app:{env}:{domain}:{event} (p. ej., shop:prod:orders:created).
- Separa canales de broadcast vs dirigidos: transmite a
notifications:global y apunta a usuarios con notifications:user:{id}.
- Mantén payloads pequeños y autocontenidos: incluye un ID y metadata mínima; busca detalles en otro lado solo si hace falta.
Usado así, Pub/Sub es una señal de evento rápida, mientras que Streams (u otra cola) gestiona los eventos que no puedes permitir perder.
Elegir las estructuras de datos correctas en Redis
De la idea al despliegue
Despliega y hospeda tu app tras añadir funciones de Redis, todo en un mismo flujo.
Escoger una estructura de Redis no es solo “lo que funciona”—afecta uso de memoria, velocidad de consulta y la simplicidad del código a largo plazo. Una buena regla es elegir la estructura que coincida con las preguntas que harás después (patrones de lectura), no solo con cómo almacenas hoy.
Guía rápida de selección (strings, hashes, sets, sorted sets)
- Strings: mejor para valores únicos (blob JSON, feature flag, HTML cacheado). También genial para contadores atómicos con
INCR/DECR.
- Hashes: mejor para “un objeto con campos” (campos de perfil de usuario, totales de carrito). Ideal cuando actualizas propiedades individuales frecuentemente.
- Sets: mejor para unicidad y verificaciones de membresía (¿el usuario ya reclamó el cupón X?). Rápido
SISMEMBER y fáciles operaciones de conjunto.
- Sorted sets (ZSETs): mejor para datos rankeados y queries “top N” (leaderboards, listas de prioridad, puntuación por tiempo).
Actualizaciones atómicas, contadores y leaderboards
Las operaciones de Redis son atómicas a nivel de comando, así que puedes incrementar contadores sin condiciones de carrera. Vistas de página y contadores de rate limit típicamente usan strings con INCR más un expiry.
Los leaderboards son donde sorted sets brillan: puedes actualizar scores (ZINCRBY) y obtener los mejores (ZREVRANGE) eficientemente, sin escanear todas las entradas.
Usar hashes para reducir cantidad de claves y mejorar organización
Si creas muchas claves como user:123:name, user:123:email, user:123:plan, multiplicas overhead por clave y complicas la gestión. Un hash como user:123 con campos (name, email, plan) mantiene datos relacionados juntos y suele reducir el número de claves. También facilita actualizaciones parciales (actualizar un campo en lugar de reescribir un JSON entero).
Consideraciones de memoria que afectan el coste
- Muchas claves pequeñas pueden costar más memoria de lo esperado por el overhead por clave.
- Hashes suelen ser más eficientes en memoria para objetos pequeños-medianos bajo una misma clave.
- Sorted sets son potentes pero pueden ser más pesados que sets/strings—úsalos cuando realmente necesites ranking o consultas basadas en score.
Cuando dudes, modela una muestra pequeña y mide uso de memoria antes de comprometerte con una estructura para datos de alto volumen.
Persistencia, replicación y seguridad de datos
Redis a menudo se describe como “en memoria”, pero aún tienes elecciones sobre qué ocurre cuando un nodo reinicia, un disco se llena o un servidor desaparece. La configuración correcta depende de cuánto datos puedas permitir perder y cuán rápido necesitas recuperarte.
RDB vs AOF: qué ofrece cada uno
RDB (snapshots) guarda un volcado punto-en-el-tiempo de tu dataset. Son compactos y rápidos de cargar en el arranque, lo que puede acelerar reinicios. El trade-off es que puedes perder las escrituras más recientes desde el último snapshot.
AOF (append-only file) registra operaciones de escritura a medida que ocurren. Esto típicamente reduce la pérdida potencial de datos porque los cambios se registran más continuamente. Los archivos AOF pueden crecer más y las reproducciones al arrancar pueden tardar más—aunque Redis puede reescribir/compactar el AOF para mantenerlo manejable.
Muchos equipos ejecutan ambos: snapshots para reinicios más rápidos y AOF para mejor durabilidad de escrituras.
Cómo la persistencia afecta latencia y reinicios
La persistencia no es gratis. Escrituras en disco, políticas de fsync de AOF y operaciones de rewrite en background pueden añadir picos de latencia si tu almacenamiento es lento o está saturado. Por otro lado, la persistencia hace que los reinicios sean menos aterradores: sin persistencia, un reinicio inesperado significa un Redis vacío.
Replicación y objetivos de failover
La replicación mantiene una copia (o copias) de los datos en réplicas para poder hacer failover cuando la primaria cae. El objetivo suele ser disponibilidad primero, no consistencia perfecta. En fallo, las réplicas pueden quedarse ligeramente atrás y un failover puede perder las últimas escrituras en algunos escenarios.
Define tu pérdida de datos aceptable y tiempo de recuperación
Antes de ajustar nada, escribe dos números:
- Pérdida de datos aceptable (RPO): “Podemos perder hasta X segundos/minutos de datos.”
- Tiempo de recuperación (RTO): “Debemos estar de vuelta en Y segundos/minutos.”
Usa esos objetivos para elegir la frecuencia de RDB, la configuración de AOF y si necesitas réplicas (y failover automatizado) según el rol de Redis—caché, store de sesiones, cola o datastore primario.
Escalar Redis: de una instancia a un cluster
Un solo nodo Redis puede llevarte sorprendentemente lejos: es simple de operar, fácil de razonar y a menudo lo bastante rápido para muchos workloads de caché, sesión o cola.
Escalar se vuelve necesario cuando alcanzas límites duros—normalmente techo de memoria, saturación de CPU o un único nodo que se convierte en punto único de fallo inaceptable.
Cuándo pasar de una instancia a varias
Considera añadir nodos cuando se cumpla una (o más) de estas condiciones:
- Tu dataset ya no cabe en RAM con margen seguro.
- Picos de latencia en tráfico pico porque el nodo está limitado por CPU.
- Necesitas mayor disponibilidad que “reiniciar y recuperar”.
- Tienes múltiples cargas compitiendo (p. ej., caché + colas) y quieres aislamiento.
Un paso práctico inicial suele ser separar cargas (dos instancias Redis independientes) antes de saltar a un cluster.
Sharding y Redis Cluster en términos simples
Sharding significa dividir tus claves entre varios nodos Redis para que cada nodo almacene solo una porción de los datos. Redis Cluster es la forma integrada de Redis para hacerlo automáticamente: el espacio de claves se divide en slots y cada nodo posee parte de esos slots.
La ventaja es más memoria total y mayor throughput agregado. El trade-off es complejidad añadida: operaciones multi-key se vuelven restringidas (las claves deben estar en el mismo shard) y el troubleshooting implica más partes móviles.
Hot keys y distribución desigual de tráfico
Incluso con sharding “parejo”, el tráfico real puede ser desigual. Una clave popular (una “hot key”) puede saturar un nodo mientras otros están ociosos.
Mitigaciones incluyen añadir TTLs cortos con jitter, dividir el valor entre múltiples claves (hashing de clave) o rediseñar patrones de acceso para distribuir lecturas.
Consideraciones para clientes: drivers aware de cluster y enrutamiento
Un Redis Cluster requiere un cliente aware del cluster que pueda descubrir la topología, enrutar peticiones al nodo correcto y seguir redirecciones cuando los slots se mueven.
Antes de migrar, confirma:
- Tu driver en el lenguaje soporta Redis Cluster.
- Tu estrategia de pooling funciona con múltiples nodos.
- Tu código evita comandos multi-key a través de shards diferentes (o usa hash tags para mantener claves relacionadas juntas).
Escalar funciona mejor cuando es una evolución planificada: valida con pruebas de carga, instrumenta latencia por clave y migra tráfico gradualmente en lugar de hacer un cambio brusco.
Esenciales de seguridad para despliegues Redis
Prueba sin miedo
Experimenta con patrones de Redis y revierte con seguridad si un cambio causa problemas.
Redis se trata a menudo como “plomería interna”, y por eso es un objetivo frecuente: un puerto expuesto puede convertirse en una fuga completa de datos o en un cache controlado por un atacante. Asume que Redis es infraestructura sensible, aunque solo almacenes datos “temporales”.
Autenticación y control de acceso
Empieza habilitando autenticación y usando ACLs (Redis 6+). Las ACLs te permiten:
- crear usuarios separados para apps, workers y admins
- restringir comandos (p. ej., permitir GET/SET pero denegar CONFIG)
- limitar claves por prefijo (útil en setups multi-tenant)
Evita compartir una sola contraseña entre todos los componentes. En su lugar, emite credenciales por servicio y mantén permisos estrechos.
Aislamiento de red y TLS
El control más efectivo es no ser accesible. Bind Redis a una interfaz privada, colócalo en una subred privada y restringe tráfico entrante con security groups/firewalls solo a los servicios que lo necesiten.
Usa TLS cuando el tráfico de Redis cruce límites de hosts que no controlas totalmente (multi-AZ, redes compartidas, nodos de Kubernetes o entornos híbridos). TLS evita sniffing y robo de credenciales; vale la pena la pequeña sobrecarga para sesiones, tokens o cualquier dato relacionado con usuarios.
Comandos peligrosos y mala configuración
Bloquea comandos que pueden causar daño mayor si se abusan. Ejemplos comunes a restringir vía ACLs: FLUSHALL, FLUSHDB, CONFIG, SAVE, DEBUG y EVAL (o al menos controla cuidadosamente el uso de scripting). También protege el enfoque de rename-command con cuidado—las ACLs suelen ser más claras y fáciles de auditar.
Manejo y rotación de secretos
Almacena credenciales de Redis en tu gestor de secretos (no en código ni imágenes de contenedor) y planifica la rotación. La rotación es más sencilla cuando los clientes pueden recargar credenciales sin redeploy o cuando soportas dos credenciales válidas durante la transición.
Si quieres una checklist práctica, guárdala en tus runbooks junto a /blog/monitoring-troubleshooting-redis.
Monitorización, troubleshooting e higiene operativa
Redis a menudo “se siente bien”… hasta que cambia el tráfico, la memoria crece o un comando lento lo bloquea todo. Una rutina ligera de monitorización y una checklist de incidentes clara previenen la mayoría de sorpresas.
Métricas que realmente importan
Empieza con un conjunto pequeño que cualquiera del equipo pueda explicar:
- Memoria usada vs maxmemory: observa tendencias, no solo el uso actual.
- Cache hit rate (si usas caché): hits bajos suelen indicar mal diseño de claves, TTLs cortos o lecturas que bypassan la caché.
- Latencia: monitorea p95/p99 de latencia de comandos; los picos importan más que los promedios.
- Evictions: evictions sostenidas suelen indicar infra-provisionamiento o TTLs incorrectos.
- Lag de replicación (si usas réplicas): el lag creciente puede romper scaling de lectura y confianza en failover.
Troubleshooting rápido: slowlog y estadísticas de comandos
Cuando algo está “lento”, confírmalo con las propias herramientas de Redis:
- SLOWLOG ayuda a identificar comandos costosos (a menudo queries de rango grandes, fetches de valores enormes o scans completos accidentales).
- Command stats (via INFO) muestran qué comandos dominan. Un salto en
KEYS, SMEMBERS o LRANGE grande es una bandera roja común.
Si la latencia sube mientras la CPU parece bien, considera saturación de red, payloads sobredimensionados o clientes bloqueados.
Planificación de capacidad y margen
Planifica crecimiento manteniendo headroom (comúnmente 20–30% de memoria libre) y revisando suposiciones tras lanzamientos o flags. Trata las “evictions continuas” como un outage, no como una advertencia.
Un runbook simple de incidentes
Durante un incidente, comprueba (en orden): memoria/evictions, latencia, conexiones cliente, slowlog, lag de replicación y deploys recientes. Escribe las causas recurrentes y arréglalas permanentemente—las alertas solas no bastan.
Si tu equipo itera rápido, ayuda incorporar estas expectativas operativas en el flujo de desarrollo. Por ejemplo, con el modo planning y snapshots/rollback de Koder.ai puedes prototipar características respaldadas por Redis (como caché o rate limiting), probarlas bajo carga y revertir cambios con seguridad—mientras mantienes la implementación en tu codebase mediante export de código fuente.