Por qué el REST de Roy Fielding sigue importando
Roy Fielding no es solo un nombre ligado a una palabra de moda de APIs. Fue uno de los autores clave de las especificaciones HTTP y URI y, en su tesis doctoral, describió un estilo arquitectónico llamado REST (Transferencia de Estado por Representación) para explicar por qué la Web funciona tan bien.
Ese origen importa porque REST no se inventó para crear “endpoints bonitos”. Fue una manera de describir las restricciones que permiten que una red global y desordenada aún escale: muchos clientes, muchos servidores, intermediarios, cacheo, fallos parciales y cambio continuo.
Qué obtendrás de este post
Si alguna vez te has preguntado por qué dos “APIs REST” se sienten completamente diferentes, o por qué una pequeña decisión de diseño se convierte después en problemas de paginación, confusión de cacheo o cambios incompatibles, esta guía está pensada para reducir esas sorpresas.
Te llevarás:
- mejor claridad al tomar decisiones al diseñar o evaluar una API
- un vocabulario más útil para discutir trade-offs con tu equipo
- un sentido práctico de qué ideas de REST importan más en proyectos reales
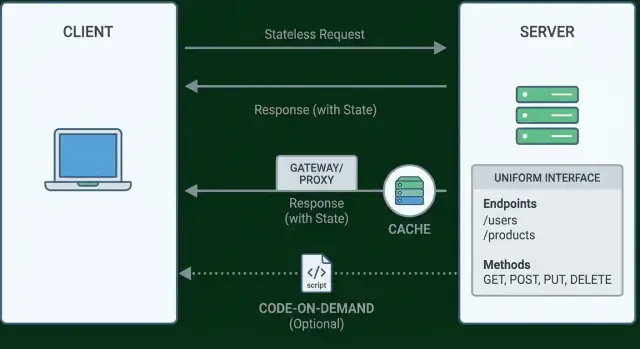
REST en una página: estilo, no estándar
REST no es una lista de verificación, ni un protocolo, ni una certificación. Fielding lo describió como un estilo arquitectónico: un conjunto de restricciones que, aplicadas en conjunto, producen sistemas que escalan como la Web: simples de usar, capaces de evolucionar con el tiempo y amigables con intermediarios (proxies, caches, gateways) sin coordinación constante.
El problema que REST estaba resolviendo
La Web temprana necesitaba funcionar entre muchas organizaciones, servidores, redes y tipos de cliente. Tenía que crecer sin control central, sobrevivir a fallos parciales y permitir que aparecieran nuevas funcionalidades sin romper las antiguas. REST aborda eso favoreciendo un pequeño número de conceptos ampliamente compartidos (como identificadores, representaciones y operaciones estándar) frente a contratos personalizados y fuertemente acoplados.
“Restricciones arquitectónicas” en términos sencillos
Una restricción es una regla que limita la libertad de diseño a cambio de beneficios. Por ejemplo, puedes renunciar al estado de sesión en el servidor para que cualquier nodo pueda manejar las peticiones, lo que mejora la fiabilidad y el escalado. Cada restricción REST hace un trade-off similar: menos flexibilidad ad-hoc, más predictibilidad y capacidad de evolución.
REST vs. APIs “estilo REST”
Muchas APIs HTTP toman ideas de REST (JSON sobre HTTP, endpoints en URLs, quizá códigos de estado) pero no aplican el conjunto completo de restricciones. Eso no es “incorrecto”: a menudo refleja plazos de producto o necesidades internas. Simplemente es útil nombrar la diferencia: una API puede ser orientada a recursos sin ser completamente REST.
Un modelo mental en un párrafo
Piensa en un sistema REST como recursos (cosas que puedes nombrar con URLs) con los que los clientes interactúan mediante representaciones (la vista actual de un recurso, como JSON o HTML), guiados por enlaces (siguientes acciones y recursos relacionados). El cliente no necesita reglas secretas fuera de banda; sigue semánticas estándar y navega usando enlaces, igual que un navegador recorre la Web.
Recursos y representaciones: el vocabulario central
Antes de perderse en restricciones y detalles de HTTP, REST empieza con un cambio de vocabulario simple: piensa en recursos, no en acciones.
Recurso = un sustantivo que puedes identificar
Un recurso es una “cosa” direccionable en tu sistema: un usuario, una factura, una categoría de producto, un carrito de compras. Lo importante es que es un sustantivo con identidad.
Por eso /users/123 se lee de forma natural: identifica al usuario con ID 123. Compáralo con URLs con forma de acción como /getUser o /updateUserPassword. Esas describen verbos —operaciones—, no la cosa sobre la que operas.
REST no dice que no puedas realizar acciones. Dice que las acciones deben expresarse a través de la interfaz uniforme (para APIs HTTP, eso suele significar métodos como GET/POST/PUT/PATCH/DELETE) actuando sobre identificadores de recursos.
Representación = una vista del recurso
Una representación es lo que envías por la red como instantánea o vista de ese recurso en un momento dado. El mismo recurso puede tener múltiples representaciones.
Por ejemplo, el recurso /users/123 podría representarse como JSON para una app o como HTML para un navegador.
GET /users/123
Accept: application/json
Podría devolver:
{
"id": 123,
"name": "Asha",
"email": "[email protected]"
}
Mientras que:
GET /users/123
Accept: text/html
Podría devolver una página HTML que muestre los mismos datos del usuario.
La idea clave: el recurso no es el JSON y tampoco es el HTML. Esos son solo formatos usados para representarlo.
Por qué este enfoque cambia el diseño de APIs
Una vez que modelas tu API alrededor de recursos y representaciones, varias decisiones prácticas se vuelven más sencillas:
- Los nombres permanecen estables.
/users/123 sigue siendo válido aunque tu UI, flujos o modelo de datos evolucionen.
- Los endpoints se simplifican. En lugar de inventar una URL nueva para cada operación, reutilizas las URLs de recursos y varías el método o la representación.
- El código cliente se desacopla. Los clientes se enfocan en “obtener al usuario” o “actualizar campos del usuario” en lugar de memorizar un catálogo de endpoints de acción.
Esta mentalidad orientada a recursos es la base sobre la que se construyen las restricciones REST. Sin ella, “REST” suele colapsar en “JSON sobre HTTP con algunos patrones de URL agradables”.
Restricción 1: Separación cliente–servidor
La separación cliente–servidor es la forma en que REST impone una división limpia de responsabilidades. El cliente se centra en la experiencia de usuario (qué ven y hacen las personas), mientras que el servidor se ocupa de los datos, reglas y persistencia (qué es cierto y qué está permitido). Si mantienes esas preocupaciones separadas, cada lado puede cambiar sin obligar a reescribir el otro.
Qué vive en el cliente vs. el servidor
En términos cotidianos, el cliente es la “capa de presentación”: pantallas, navegación, validación local para retroalimentación rápida y comportamiento optimista de la UI (como mostrar un comentario nuevo inmediatamente). El servidor es la “fuente de la verdad”: autenticación, autorización, reglas de negocio, almacenamiento, auditoría y cualquier cosa que deba mantenerse consistente entre dispositivos.
Una regla práctica: si una decisión afecta a seguridad, dinero, permisos o coherencia de datos compartidos, pertenece al servidor. Si afecta solo a cómo se siente la experiencia (diseño, pistas de entrada locales, estados de carga), pertenece al cliente.
Por qué encaja con patrones modernos de apps
Esta restricción mapea directamente a configuraciones comunes:
- SPA + API: una app web (React/Vue/etc.) itera en la UI mientras la API sigue sirviendo recursos.
- Apps móviles: clientes iOS y Android pueden compartir las mismas reglas y endpoints del servidor.
- Integraciones de terceros: partners consumen las mismas capacidades del servidor sin necesitar tu UI.
La separación cliente–servidor es lo que hace realista “un backend, muchas frontends”.
Error común: filtrar estado de UI en sesiones del servidor
Un error frecuente es almacenar el estado del flujo de UI en el servidor (por ejemplo: “en qué paso del checkout está el usuario”) en una sesión del lado del servidor. Eso acopla el backend a un flujo de pantalla particular y dificulta el escalado.
Prefiere enviar el contexto necesario con cada petición (o derivarlo de recursos almacenados), de modo que el servidor se mantenga centrado en recursos y reglas, no en recordar cómo progresa una UI específica.
Restricción 2: Interacciones sin estado
La ausencia de estado (statelessness) significa que el servidor no necesita recordar nada sobre un cliente entre peticiones. Cada petición lleva toda la información necesaria para entenderla y responder correctamente: quién llama, qué quiere y cualquier contexto necesario para procesarla.
Por qué esto importa
Cuando las peticiones son independientes, puedes añadir o quitar servidores detrás de un balanceador sin preocuparte por “qué servidor conoce mi sesión”. Eso mejora el escalado y la resiliencia: cualquier instancia puede manejar cualquier petición.
Además simplifica las operaciones. Depurar suele ser más fácil porque el contexto completo es visible en la petición (y en los logs), en lugar de estar oculto en memoria de sesión del servidor.
Los trade-offs que verás en APIs reales
Las APIs sin estado típicamente envían un poco más de datos por llamada. En lugar de depender de una sesión almacenada en el servidor, los clientes incluyen credenciales y contexto en cada petición.
También hay que ser explícito sobre experiencias de usuario “con estado” (como paginación o checkouts multi-paso). REST no prohíbe experiencias multi-paso: empuja el estado al cliente o a recursos del servidor que estén identificados y recuperables.
Patrones prácticos (y lo que resuelven)
- Tokens de auth (p. ej., JWT Bearer): cada petición incluye un
Authorization: Bearer … para que cualquier servidor pueda autenticarla.
- Claves de idempotencia: para operaciones como “crear pago”, los clientes envían un
Idempotency-Key para que reintentos no dupliquen trabajo.
- IDs de correlación: un header como
X-Correlation-Id te permite trazar una acción de usuario a través de servicios y logs, incluso en un sistema distribuido.
Para la paginación, evita “el servidor recuerda la página 3.” Prefiere parámetros explícitos como ?cursor=abc o un enlace next que el cliente pueda seguir, manteniendo el estado de navegación en las respuestas en lugar de en memoria del servidor.
Restricción 3: Respuestas cacheables
El cacheo trata de reutilizar una respuesta previa de forma segura para que el cliente (o algo intermedio) no tenga que pedir al servidor el mismo trabajo otra vez. Bien hecho, reduce latencia para usuarios y carga para ti, sin cambiar el significado de la API.
Qué significa “cacheable” en la práctica
Una respuesta es cacheable cuando es seguro que otra petición reciba el mismo payload durante un periodo de tiempo. En HTTP, comunicas esa intención con headers de cacheo:
Cache-Control: el conmutador principal (cuánto tiempo guardarlo, si puede almacenarlo un cache compartido, etc.)ETag y Last-Modified: validadores que permiten a clientes preguntar “¿ha cambiado esto?” y recibir una respuesta barata de “no modificado”Expires: una forma más antigua de expresar frescura, aún vista en la naturaleza
Esto es más que “cache del navegador.” Proxies, CDNs, gateways de API e incluso apps móviles pueden reutilizar respuestas cuando las reglas son claras.
Qué suele ser seguro cachear (y qué no)
Buenos candidatos:
- Datos públicos idénticos para todos (catálogos de producto, documentación, flags de característica no específicos de usuario)
- Recursos de solo lectura que cambian poco (configuración estática, datos de referencia)
- Respuestas GET que no dependen de cookies o autorización
Usualmente malos candidatos:
- Datos personales ligados a una cuenta (perfiles, órdenes, mensajes)
- Respuestas relacionadas con auth (intercambio de tokens, estado de sesión)
- Cualquier cosa que varíe por usuario a menos que lo manejes explícitamente (p. ej., con reglas
private)
Resultados prácticos que notarás
- Páginas más rápidas y apps más reactivas (menos espera en la red)
- Menores costes en servidor y base de datos (menos cálculos repetidos)
- Menos incidentes por límites de tasa (las lecturas cacheadas reducen el volumen de peticiones)
La idea clave: el cacheo no es un detalle secundario. Es una restricción REST que premia a las APIs que comunican claramente frescura y validación.
La interfaz uniforme a menudo se malinterpreta como “usa GET para leer y POST para crear.” Eso es solo una parte. La idea de Fielding es más amplia: las APIs deberían sentirse consistentes de modo que los clientes no necesiten conocimiento especial, endpoint por endpoint, para usarlas.
-
Identificación de recursos: Nombras cosas (recursos) con identificadores estables (típicamente URLs), no acciones. Piensa /orders/123, no /createOrder.
-
Manipulación mediante representaciones: Los clientes cambian un recurso enviando una representación (JSON, HTML, etc.). El servidor controla el recurso; el cliente intercambia representaciones del mismo.
-
Mensajes autodescriptivos: Cada request/response debe llevar suficiente información para entender cómo procesarlo: método, código de estado, headers, tipo de medio y un cuerpo claro. Si el significado está escondido en docs fuera de banda, los clientes quedan fuertemente acoplados.
-
Hipermedia (HATEOAS): Las respuestas deberían incluir enlaces y acciones permitidas para que los clientes puedan seguir el flujo sin codificar cada patrón de URL.
Por qué reduce el acoplamiento
Una interfaz consistente hace que los clientes dependan menos de detalles internos del servidor. Con el tiempo eso significa menos cambios rompientes, menos “casos especiales” y menos retrabajo cuando los equipos evolucionan endpoints.
Heurísticas prácticas que puedes aplicar
- Usa códigos de estado de forma coherente: p. ej.,
200 para lecturas exitosas, 201 para recursos creados (con Location), 400 para validaciones, 401/403 para auth, 404 cuando un recurso no existe.
- Estandariza tu formato de errores a lo largo de la API. Campos de ejemplo:
code, message, details, requestId.
- Mantén tipos de medios y headers significativos (
Content-Type, headers de cacheo), para que los mensajes se expliquen por sí mismos.
La interfaz uniforme trata de predictibilidad y capacidad de evolución, no solo de “verbos correctos”.
Mensajes autodescriptivos: diseñar para comprensión
Un mensaje “autodescriptivo” es aquel que dice al receptor cómo interpretarlo, sin requerir conocimiento tribal fuera de banda. Si un cliente (o intermediario) no puede entender qué significa una respuesta solo mirando los headers HTTP y el cuerpo, has creado un protocolo privado sobre HTTP.
Usa tipos de medios para explicar el payload
La victoria más sencilla es ser explícito con Content-Type (qué estás enviando) y, a menudo, Accept (qué quieres recibir). Una respuesta con Content-Type: application/json le dice al cliente las reglas básicas de parseo, pero puedes ir más allá con tipos de medios vendor o perfiles cuando el significado importa.
Enfoques ejemplos:
- Tipo genérico + campos estables:
application/json con un esquema cuidadosamente mantenido. Lo más fácil para la mayoría de equipos.
- Tipos vendor:
application/vnd.acme.invoice+json para señalar una representación específica.
- Perfiles: mantener
application/json, añadir un parámetro profile o un enlace a un perfil que defina la semántica.
Versionado y compatibilidad (sin romper clientes)
El versionado debe proteger a clientes existentes. Opciones populares incluyen:
- Versionado en la URL (
/v1/orders): obvio, pero puede incentivar “forkear” representaciones en vez de evolucionarlas.
- Versionado por header o tipo de medio (vía
Accept): mantiene URLs estables y hace que “qué significa” sea parte del mensaje.
- Evolución aditiva: prefiere añadir campos nuevos y mantener los antiguos; depreca gradualmente.
Sea lo que sea que elijas, apunta a compatibilidad hacia atrás por defecto: no renombres campos a la ligera, no cambies significado sin aviso y trata las eliminaciones como cambios rompientes.
Errores consistentes y nombres claros
Los clientes aprenden más rápido cuando los errores lucen igual en todas partes. Elige una forma de error (por ejemplo, code, message, details, traceId) y úsala en todos los endpoints. Emplea nombres de campo claros y predecibles (createdAt vs. created_at) y mantén una convención.
La documentación ayuda—pero la claridad debe vivir en el mensaje
La buena documentación acelera la adopción, pero no puede ser el único lugar donde existe el significado. Si un cliente necesita leer una wiki para saber si status: 2 significa “pagado” o “pendiente”, el mensaje no es autodescriptivo. Headers bien diseñados, tipos de medios y payloads legibles reducen esa dependencia y hacen los sistemas más fáciles de evolucionar.
La hipermedia (resumida como HATEOAS: Hypermedia As The Engine Of Application State) significa que un cliente no tiene que “conocer” de antemano las siguientes URLs de la API. En su lugar, cada respuesta incluye pasos siguientes descubribles como enlaces: a dónde ir después, qué acciones son posibles y, a veces, qué método HTTP usar.
Cómo se ve en la práctica
En lugar de codificar rutas como /orders/{id}/cancel, el cliente sigue enlaces proporcionados por el servidor. El servidor dice, en efecto: “Dado el estado actual de este recurso, estos son los movimientos válidos.”
{
"id": "ord_123",
"status": "pending",
"total": 49.90,
"_links": {
"self": { "href": "/orders/ord_123" },
"payment":{ "href": "/orders/ord_123/payment", "method": "POST" },
"cancel": { "href": "/orders/ord_123", "method": "DELETE" }
}
}
Si la orden pasa a paid, el servidor podría dejar de incluir cancel y añadir refund—sin romper a un cliente bien comportado.
La hipermedia brilla cuando los flujos evolucionan: onboarding, checkout, aprobaciones, suscripciones o cualquier proceso donde “lo que está permitido después” cambia según estado, permisos o reglas de negocio.
También reduce URLs codificadas a fuego y supuestos frágiles en el cliente. Puedes reorganizar rutas, introducir nuevas acciones o deprecar otras mientras mantienes a los clientes funcionales siempre que preserves el significado de las relaciones de enlace.
Por qué los equipos la evitan (y qué pierden)
Los equipos suelen omitir HATEOAS porque supone trabajo adicional: definir formatos de enlace, acordar nombres de relaciones y enseñar a los desarrolladores clientes a seguir enlaces en lugar de construir URLs.
Lo que se pierde es un beneficio clave de REST: desacoplamiento. Sin hipermedia, muchas APIs se convierten en “RPC sobre HTTP”: pueden usar HTTP, pero los clientes siguen dependiendo en gran medida de documentación fuera de banda y plantillas URL fijas.
Restricción 5: Sistema en capas
Un sistema en capas significa que un cliente no tiene que saber (y a menudo no puede saber) si está hablando con el servidor de origen real o con intermediarios en el camino. Esas capas pueden incluir gateways de API, proxies inversos, CDNs, servicios de autenticación, WAFs, mallas de servicio e incluso ruteo interno entre microservicios.
Por qué las capas son útiles
Las capas crean límites limpios. Los equipos de seguridad pueden aplicar TLS, límites de tasa, autenticación y validación en el borde sin tocar cada servicio backend. Las operaciones pueden escalar horizontalmente detrás de un gateway, añadir cacheo en una CDN o desviar tráfico durante incidentes. Para los clientes, puede simplificar: un endpoint de API estable, headers consistentes y formatos de error previsibles.
Los trade-offs que sentirás en la práctica
Los intermediarios pueden introducir latencia oculta (saltos extra, handshakes extra) y complicar la depuración: el bug puede estar en las reglas del gateway, en la caché del CDN o en el código de origen. El cacheo también puede volverse confuso cuando distintas capas cachean de formas diferentes o cuando un gateway reescribe headers que afectan las claves de caché.
Consejos prácticos para que las capas no te perjudiquen
- Usa IDs de trazado end-to-end: acepta un ID de petición (o genera uno) y propágalo en cada salto; inclúyelo en respuestas y logs.
- Haz explícita la propagación de errores: estandariza cuerpos de error y mapea fallos upstream claramente (no conviertas todo en un 500 genérico).
- Alinea timeouts por salto: timeouts de gateway, upstream y cliente deben estar coordinados para evitar desconexiones misteriosas.
- Documenta el comportamiento de cacheo: deja claro qué respuestas son cacheables y qué headers deben preservar los intermediarios.
Las capas son poderosas—cuando el sistema sigue siendo observable y predecible.
Restricción 6 (opcional): Código bajo demanda
El código bajo demanda es la única restricción REST que es explícitamente opcional. Significa que un servidor puede extender un cliente enviando código ejecutable que corre en el lado del cliente. En lugar de empaquetar todo el comportamiento en el cliente por adelantado, el cliente puede descargar lógica nueva según sea necesario.
El ejemplo familiar en la web: JavaScript
Si alguna vez cargaste una página que luego se volvió interactiva—validando un formulario, renderizando un gráfico, filtrando una tabla—ya usaste código bajo demanda. El servidor entrega HTML y datos, más JavaScript que se ejecuta en el navegador para proporcionar comportamiento.
Esto es una gran razón por la que la web puede evolucionar rápido: un navegador puede seguir siendo un cliente de propósito general, mientras los sitios entregan nueva funcionalidad sin requerir que el usuario instale una app nueva.
Por qué es opcional (y por qué muchas APIs lo evitan)
REST funciona perfectamente sin código bajo demanda porque las otras restricciones ya permiten escalabilidad, simplicidad e interoperabilidad. Una API puede ser puramente orientada a recursos—sirviendo representaciones como JSON—mientras los clientes implementan su propio comportamiento.
De hecho, muchas APIs modernas evitan enviar código ejecutable porque complica:
- Seguridad: el código ejecutable amplía la superficie de ataque (inyección, cadena de suministro, scripts maliciosos).
- Políticas de contenido: los navegadores aplican Content Security Policy (CSP) y organizaciones pueden bloquear scripts inline u orígenes desconocidos.
- Auditoría y cumplimiento: es más difícil probar qué código se ejecutó en un cliente en un momento dado si se descarga dinámicamente.
Cuándo puede tener sentido el código bajo demanda
El código bajo demanda puede ser útil cuando controlas el entorno del cliente y necesitas desplegar comportamiento de UI rápidamente, o cuando quieres un cliente delgado que descargue “plugins” o reglas desde el servidor. Pero debe considerarse una herramienta adicional, no un requisito.
Conclusión clave: puedes seguir REST sin código bajo demanda—y muchas APIs en producción lo hacen—porque la restricción es sobre extensibilidad opcional, no la base de la interacción orientada a recursos.
Aplicar REST hoy: elecciones prácticas y errores comunes
La mayoría de equipos no rechazan REST: adoptan un estilo “REST-ish” que mantiene HTTP como transporte mientras descartan silenciosamente restricciones clave. Eso puede estar bien, siempre que sea un trade-off consciente y no un accidente que aparezca luego como clientes frágiles y reescrituras costosas.
Atajos comunes estilo REST (y por qué ocurren)
Algunos patrones aparecen una y otra vez:
- Endpoints RPC:
/doThing, /runReport, /users/activate—fáciles de nombrar y de conectar.
- URLs con verbos:
/createOrder, /updateProfile, /deleteItem—los métodos HTTP se vuelven un detalle.
- Sesiones ocultas: APIs “sin estado” que aún dependen de sesiones sticky, memoria del servidor o estado de flujo implícito.
Estas elecciones suelen parecer productivas al principio porque reflejan nombres de funciones internas y operaciones de negocio.
Consecuencias que notarás más adelante
- Clientes frágiles: si los clientes dependen de formas de endpoint específicas y comportamientos ad-hoc, pequeños refactors del servidor se convierten en cambios rompientes.
- Versionado difícil: cuando las URLs codifican acciones en lugar de recursos estables, terminas versionando comportamiento en vez de evolucionar representaciones.
- Fallos de cacheo (y mayor latencia): ignorar headers de cacheo o usar POST para todo impide que intermediarios (y navegadores) te ayuden.
- Problemas de escalado: el estado de sesión oculto en servidor complica el escalado horizontal y hace que las recuperaciones de fallos sean más difíciles.
Lista de comprobación pragmática
Úsala como un repaso de “qué tan REST somos, realmente?”:
- Nombra recursos, no acciones: prefiere
/orders/{id} sobre /createOrder.
- Usa métodos HTTP intencionalmente: GET para lectura, POST para creación, PUT/PATCH para actualizaciones, DELETE para borrado.
- Haz las peticiones independientes: no se requiere memoria del servidor para entender “en qué paso está el cliente.”
- Aprovecha el cacheo donde sea seguro: define
Cache-Control, ETag y Vary para respuestas GET.
- Estandariza errores y tipos de medios: códigos de estado coherentes y formas de respuesta consistentes reducen casos especiales.
Dónde se nota cuando estás construyendo
Las restricciones REST no son solo teoría: son guías que sientes al enviar. Cuando generas una API rápidamente (por ejemplo, scaffolding de un frontend React con un backend en Go + PostgreSQL), el error más fácil es dejar que “lo que sea más rápido de conectar” dicte tu interfaz.
Si usas una plataforma de desarrollo rápido como Koder.ai para construir una web desde chat, ayuda traer estas restricciones REST a la conversación temprano: nombrar recursos primero, permanecer sin estado, definir formas de error consistentes y decidir dónde es seguro cachear. Así, incluso la iteración rápida produce APIs previsibles para clientes y más fáciles de evolucionar. (Y porque Koder.ai soporta exportación de código fuente, puedes ir refinando el contrato y la implementación de la API conforme maduran los requisitos.)
Conclusiones para equipos de API y apps web
Define primero tus recursos clave y luego elige restricciones conscientemente: si vas a omitir cacheo o hipermedia, documenta por qué y qué usas en su lugar. El objetivo no es pureza, sino claridad: identificadores de recursos estables, semántica predecible y trade-offs explícitos que mantienen a los clientes resistentes a medida que tu sistema evoluciona.