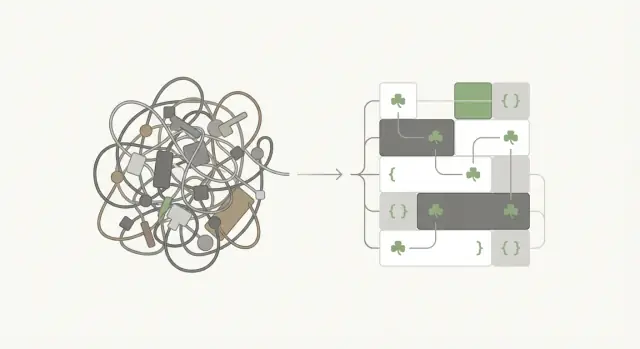
Por qué la complejidad sigue ganando en proyectos reales
El software rara vez se complica de golpe. Llega allí una decisión “razonable” a la vez: un cache rápido para cumplir un plazo, un objeto mutable compartido para evitar copiar, una excepción a las reglas porque “esto es especial”. Cada elección parece pequeña, pero juntas crean un sistema donde los cambios se sienten riesgosos, los bugs son difíciles de reproducir y añadir funcionalidades tarda más que construirlas.
La complejidad gana porque ofrece comodidad a corto plazo. Suele ser más rápido enchufar una nueva dependencia que simplificar una existente. Es más fácil parchear estado que preguntar por qué el estado está repartido en cinco servicios. Y resulta tentador apoyarse en convenciones y conocimiento tribal cuando el sistema crece más rápido que la documentación.
Qué es (y qué no es) este artículo
Esto no es un tutorial de Clojure, y no necesitas conocer Clojure para obtener valor. El objetivo es tomar prestadas un conjunto de ideas prácticas a menudo asociadas al trabajo de Rich Hickey—ideas que puedes aplicar a decisiones cotidianas de ingeniería, independientemente del lenguaje.
Por qué los predeterminados importan más de lo que crees
La mayor parte de la complejidad no la crea el código que escribes deliberadamente; la crean los caminos que tus herramientas facilitan por defecto. Si el predeterminado es “objetos mutables por todas partes”, terminarás con acoplamiento oculto. Si el predeterminado es “el estado vive en memoria”, lucharás con depuración y trazabilidad. Los predeterminados moldean hábitos, y los hábitos moldean sistemas.
Nos centraremos en tres temas:
- Simplicidad: no menos funcionalidades, sino menos piezas móviles y menos casos especiales.
- Inmutabilidad: tratar los datos como valores que no cambian, para poder razonar sobre ellos.
- Mejores predeterminados: elegir patrones que hagan que la opción segura y predecible sea la más fácil.
Estas ideas no eliminan la complejidad del dominio, pero pueden evitar que tu software la multiplique.
Rich Hickey y lo que Clojure intentó arreglar
Rich Hickey es un desarrollador y diseñador de software conocido por crear Clojure y por charlas que cuestionan hábitos comunes de programación. Su enfoque no persigue modas: apunta a las razones recurrentes por las que los sistemas se vuelven difíciles de cambiar, de razonar y de confiar cuando crecen.
Qué es Clojure (alto nivel, sin jerga)
Clojure es un lenguaje moderno que corre sobre plataformas bien conocidas como la JVM (el runtime de Java) y JavaScript. Está diseñado para trabajar con ecosistemas existentes fomentando un estilo: representar la información como datos sencillos, preferir valores que no cambian y mantener “lo que pasó” separado de “lo que se muestra en pantalla”.
Puedes pensar en él como un lenguaje que te empuja hacia bloques de construcción más claros y lejos de efectos laterales ocultos.
Los problemas que buscaba reducir
Clojure no se creó para acortar scripts simples. Apuntaba a dolores recurrentes de proyecto:
- Complejidad creciente por estado compartido: cuando muchas partes del sistema pueden modificar los mismos datos, los bugs dependen del tiempo y son difíciles de reproducir.
- Acoplamiento fuerte entre datos y comportamiento: cuando la información está encerrada en objetos o clases, la reutilización se complica y los cambios reverberan por todo el código.
- Dolores de concurrencia: a medida que los sistemas añaden trabajos en segundo plano, colas y trabajo paralelo, “¿quién cambió qué y cuándo?” se vuelve una preocupación diaria.
Los predeterminados de Clojure empujan hacia menos piezas móviles: estructuras de datos estables, actualizaciones explícitas y herramientas que hacen la coordinación más segura.
Útil aunque nunca adoptes Clojure
El valor no se limita a cambiar de lenguaje. Las ideas centrales de Hickey—simplificar eliminando interdependencias innecesarias, tratar los datos como hechos duraderos y minimizar el estado mutable—pueden mejorar sistemas en Java, Python, JavaScript y más.
Simplicidad: no “fácil”, sino menos piezas móviles
Rich Hickey dibuja una línea clara entre simple y fácil—y es una línea que la mayoría de proyectos cruza sin notar.
Simple vs. fácil (con ejemplos cotidianos)
Fácil trata de cómo se siente algo ahora. Simple trata de cuántas partes tiene y qué tan entrelazadas están.
- Los fideos instantáneos son fáciles. Un guiso básico puede ser simple: pocos ingredientes, una sola olla, nada oculto.
- Un mando a distancia con 60 botones puede hacer una función “fácil” (está ahí), pero no es simple. Un mando con 6 controles claros es más simple, aunque tarde un minuto en aprender.
En software, “fácil” suele significar “rápido de escribir hoy”, mientras que “simple” significa “más difícil de romper el mes que viene”.
Cómo lo “fácil ahora” crea complejidad futura
Los equipos suelen elegir atajos que reducen la fricción inmediata pero añaden estructura invisible que hay que mantener:
- “Vamos a añadir solo un flag.” Ahora cada feature debe considerar ese flag.
- “Guardamos el valor calculado para ahorrar tiempo.” Ahora debes mantenerlo sincronizado en varios caminos.
- “Lo parcheamos en la UI.” Ahora la misma regla de negocio existe en varios lugares.
Cada elección puede parecer velocidad, pero aumenta el número de piezas móviles, casos especiales y dependencias cruzadas. Así los sistemas se vuelven frágiles sin un único error dramático.
Velocidad no es lo mismo que simplicidad
Lanzar rápido puede ser estupendo—pero velocidad sin simplificar suele significar que estás pidiendo prestado contra el futuro. El interés aparece como bugs difíciles de reproducir, incorporación lenta de nuevos miembros y cambios que requieren “coordinación cuidadosa”.
Una lista rápida para detectar complejidad accidental
Haz estas preguntas al revisar un diseño o un PR:
- ¿Introdujimos nuevos modos, flags o ramas de configuración?
- ¿Estamos cacheando o duplicando datos que deben mantenerse consistentes?
- ¿Deben cambiar varios módulos juntos para un solo comportamiento?
- ¿La regla está implementada en más de un lugar?
- ¿Un nuevo compañero predeciría cómo funciona esto sin explicación adicional?
Estado: el multiplicador silencioso de la complejidad
“Estado” es simplemente lo que en tu sistema puede cambiar: el carrito de un usuario, el saldo de una cuenta, la configuración actual, en qué paso está un flujo de trabajo. Lo complicado no es que exista el cambio—es que cada cambio crea una nueva oportunidad para que las cosas no coincidan.
Cuando la gente dice “el estado causa bugs”, normalmente se refieren a esto: si la misma pieza de información puede ser diferente en distintos momentos (o lugares), tu código debe responder constantemente a “¿Cuál versión es la real ahora?” Equivocarse produce errores que parecen aleatorios.
Mutabilidad: cambio que no puedes “desver”
Mutabilidad significa que un objeto se edita en el lugar: lo “mismo” se vuelve distinto con el tiempo. Suena eficiente, pero dificulta razonar porque no puedes fiarte de lo que viste hace un momento.
Un ejemplo relatable es una hoja de cálculo compartida. Si varias personas pueden editar las mismas celdas a la vez, tu entendimiento puede quedar invalidado al instante: totales cambian, fórmulas se rompen o una fila desaparece porque alguien reorganizó. Aunque nadie actúe maliciosamente, la naturaleza compartida y editable es lo que crea confusión.
El estado del software se comporta igual. Si dos partes leen el mismo valor mutable, una puede cambiarlo silenciosamente mientras la otra sigue con una suposición obsoleta.
Por qué la depuración se vuelve dolorosa
El estado mutable convierte la depuración en arqueología. Un informe de bug raramente dice “los datos se cambiaron mal a las 10:14:03”. Solo ves el resultado final: un número incorrecto, un estado inesperado, una petición que falla solo a veces.
Porque el estado cambia con el tiempo, la pregunta más importante se vuelve: ¿qué secuencia de ediciones llevó hasta aquí? Si no puedes reconstruir esa historia, el comportamiento se vuelve impredecible:
- La misma acción produce resultados distintos según el timing.
- Las correcciones “funcionan en mi máquina” pero no en producción.
- Añadir logging cambia el timing y el bug desaparece.
Por eso Hickey trata el estado como un multiplicador de complejidad: una vez que los datos son compartidos y mutables, el número de interacciones posibles crece más rápido que tu capacidad para seguirlas.
Inmutabilidad explicada sin jerga
La inmutabilidad simplemente significa datos que no cambian después de creados. En vez de tomar una información existente y editarla en el lugar, creas una nueva información que refleja la actualización.
Piensa en un recibo: una vez impreso, no borras líneas y reescribes totales. Si algo cambia, emites un recibo corregido. El viejo sigue existiendo y el nuevo es claramente “la versión más reciente”.
Por qué reduce sorpresas
Cuando los datos no se pueden modificar en secreto, dejas de preocuparte por ediciones invisibles que ocurren a tus espaldas. Eso facilita el razonamiento diario:
- Si tienes un valor, puedes confiar en que permanecerá así.
- Los bugs son más fáciles de reproducir porque la misma entrada sigue siendo la misma.
- Compartir datos entre partes del sistema es más seguro porque nadie puede “estropearlo” accidentalmente para otro.
Esto es gran parte de por qué Hickey habla de simplicidad: menos efectos laterales ocultos significa menos ramas mentales que llevar.
“Nuevas versiones” vs. “editar en el lugar”
Crear nuevas versiones puede sonar derrochador hasta que lo comparas con la alternativa. Editar en el lugar te deja preguntando: “¿Quién lo cambió? ¿Cuándo? ¿Qué era antes?” Con datos inmutables, los cambios son explícitos: existe una nueva versión y la antigua queda disponible para depuración, auditoría o rollback.
Clojure apuesta por esto haciendo natural tratar actualizaciones como producción de nuevos valores, no mutaciones de los antiguos.
Tradeoffs, seamos honestos
La inmutabilidad no es gratis. Puedes alocar más objetos y los equipos acostumbrados a “simplemente actualizar” necesitarán tiempo para adaptarse. La buena noticia es que las implementaciones modernas comparten estructura internamente para reducir el coste de memoria, y el beneficio suele ser sistemas más tranquilos con menos incidentes difíciles de explicar.
La concurrencia es más fácil cuando los datos no cambian
Prototipa el camino más sencillo
Convierte tu próxima idea de refactor en un prototipo funcional conversándola hasta hacerla realidad.
Concurrencia es simplemente “muchas cosas pasando a la vez”. Una app web manejando miles de peticiones, un sistema de pagos actualizando saldos mientras genera recibos, o una app móvil sincronizando en segundo plano: todo eso es concurrencia.
Lo complicado no es que ocurran muchas cosas. Es que a menudo tocan los mismos datos.
Por qué los datos compartidos y mutables crean condiciones de carrera
Cuando dos workers pueden leer y luego modificar el mismo valor, el resultado final puede depender del timing. Eso es una condición de carrera: un bug difícil de reproducir que aparece cuando el sistema está ocupado.
Ejemplo: dos peticiones intentan actualizar un total de pedido.
- Petición A lee total = 100
- Petición B lee total = 100
- A suma 20 y escribe 120
- B suma 10 y escribe 110
Nada “se estrelló”, pero perdiste una actualización. Bajo carga, estas ventanas de tiempo son más comunes.
Las soluciones tradicionales—locks, bloques sincronizados, orden cuidadoso—funcionan, pero obligan a todos a coordinarse. La coordinación es cara: reduce el rendimiento y se vuelve frágil a medida que crece la base de código.
Cómo la inmutabilidad reduce la necesidad de coordinación
Con datos inmutables, un valor no se edita en el lugar. En su lugar, creas un nuevo valor que representa el cambio.
Ese único cambio elimina toda una categoría de problemas:
- Los lectores no tienen que preocuparse de que lo que miran cambie a mitad de lectura.
- Los escritores no “pelean” por la misma memoria; producen nuevas versiones.
- El sistema puede elegir formas seguras de publicar la versión más reciente (a menudo con primitivas simples y bien probadas).
Resultado: comportamiento predecible bajo carga
La inmutabilidad no hace gratuita la concurrencia—todavía necesitas reglas sobre qué versión es la válida. Pero hace que los programas concurrentes sean mucho más predecibles, porque los datos en sí dejan de ser un objetivo móvil. Cuando el tráfico sube o se acumulan jobs en segundo plano, es menos probable que veas fallos misteriosos dependientes del timing.
Qué significa “mejores predeterminados” en la práctica
“Mejores predeterminados” significa que la opción más segura ocurre automáticamente y solo asumes el riesgo extra cuando optas explícitamente por ello.
Parece pequeño, pero los predeterminados guían en silencio lo que la gente escribe un lunes por la mañana, lo que los revisores aceptan un viernes por la tarde y lo que un nuevo miembro aprende del primer código que toca.
Predeterminados que reducen riesgo
Un “mejor predeterminado” no pretende decidirlo todo por ti. Pretende que el camino común sea menos propenso a errores.
Por ejemplo:
- Datos inmutables por defecto: en vez de “cambiar la cosa”, creas una nueva versión. Así es más difícil afectar accidentalmente a otras partes del programa que dependían del valor antiguo.
- Funciones puras como estilo normal: una función toma entradas y devuelve una salida, sin cambiar datos compartidos o depender de estado global oculto. Eso hace el comportamiento más predecible y testeable.
- Cambios de estado explícitos: cuando algo debe cambiar, ocurre mediante mecanismos claros y bien definidos (en lugar de permitir que cualquier parte mute cualquier cosa).
Ninguno de estos elimina la complejidad, pero impiden que se propague.
Cómo moldean los predeterminados a equipos y revisiones
Los equipos no solo siguen la documentación: siguen lo que el código “quiere” que hagas.
Cuando mutar estado compartido es fácil, se convierte en un atajo normal y los revisores discuten la intención: “¿Es seguro aquí?” Cuando la inmutabilidad y las funciones puras son el predeterminado, los revisores pueden centrarse en la lógica y la corrección, porque los movimientos arriesgados destacan.
En otras palabras, mejores predeterminados crean una línea base más saludable: la mayoría de cambios lucen consistentes y los patrones inusuales son lo bastante obvios como para cuestionarlos.
Mantenimiento y onboarding
El mantenimiento a largo plazo consiste sobre todo en leer y cambiar código existente de forma segura.
Los mejores predeterminados ayudan a los nuevos miembros a incorporarse porque hay menos reglas ocultas (“cuidado, esta función actualiza un mapa global en secreto”). El sistema es más fácil de razonar, lo que reduce el coste de cada futura feature, fix y refactor.
Separar hechos de vistas: tiempo, historial y trazabilidad
Un cambio mental útil en las charlas de Hickey es separar hechos (lo que pasó) de vistas (lo que actualmente creemos). La mayoría de sistemas mezcla ambos guardando solo el valor más reciente—sobrescribiendo ayer con hoy—y eso hace que el tiempo desaparezca.
Los hechos son append-only; las vistas se derivan
Un hecho es un registro inmutable: “Pedido #4821 creado a las 10:14”, “Pago exitoso”, “Dirección cambiada”. No se editan; añades hechos cuando la realidad cambia.
Una vista es lo que tu app necesita ahora: “¿Cuál es la dirección de envío actual?” o “¿Cuál es el balance del cliente?” Las vistas pueden recomputarse desde hechos, cachearse, indexarse o materializarse para velocidad.
Por qué conservar el historial vale la pena
Cuando retienes hechos, ganas:
- Auditabilidad: puedes explicar por qué el valor actual es así.
- Depuración: puedes reproducir la secuencia y encontrar el momento en que las cosas divergen.
- Trazabilidad: “¿Quién lo cambió, cuándo y qué era antes?” deja de ser un misterio y pasa a ser una pregunta de datos.
Un ejemplo accesible: sobrescribir vs añadir
Sobrescribir registros es como actualizar una celda de hoja de cálculo: solo ves el número más reciente.
Un log append-only es como un registro de cheques: cada entrada es un hecho y el “balance actual” es una vista calculada a partir de las entradas.
No todos los sistemas necesitan event sourcing completo
No tienes que adoptar una arquitectura event-sourced completa para beneficiarte. Muchos equipos comienzan más pequeño: mantener una tabla de auditoría append-only para cambios críticos, almacenar eventos inmutables de cambio para flujos de alto riesgo o retener snapshots más una ventana de historial corta. La clave es el hábito: trata los hechos como duraderos y el estado actual como una proyección conveniente.
Planifica los límites primero
Mapea las estructuras de datos y la propiedad del estado en el modo de planificación para reducir banderas y casos especiales.
Una de las ideas más prácticas de Hickey es data first: trata la información del sistema como valores sencillos (hechos) y trata el comportamiento como algo que ejecutas contra esos valores.
Los datos son duraderos. Si guardas información clara y autocontenida, puedes reinterpretarla más tarde, moverla entre servicios, reindexarla, auditarla o usarla en nuevas features. El comportamiento es menos duradero: el código cambia, las suposiciones cambian, las dependencias cambian.
Valores vs acciones (sin jerga)
- Datos (valores): “¿Qué es verdad?” El email de un cliente, un total de pedido, una marca temporal, un estado.
- Comportamiento (acciones): “¿Qué hacemos?” Validar, calcular descuentos, enviar notificaciones, decidir qué significa un estado.
Cuando mezclas esto, los sistemas se vuelven pegajosos: no puedes reutilizar datos sin arrastrar el comportamiento que los creó.
Menos acoplamiento, más reutilización
Separar hechos de acciones reduce el acoplamiento porque los componentes pueden acordar una forma de datos sin acordar un camino compartido de ejecución.
Un job de reporting, una herramienta de soporte y un servicio de facturación pueden consumir los mismos datos de pedido, aplicando cada uno su propia lógica. Si incrustas lógica en la representación almacenada, cada consumidor depende de esa lógica y cambiarla es arriesgado.
Ejemplo: almacenar datos limpios vs mini-programas
Datos limpios (fáciles de evolucionar):
{
"type": "discount",
"code": "WELCOME10",
"percent": 10,
"valid_until": "2026-01-31"
}
Mini-programas en almacenamiento (difíciles de evolucionar):
{
"type": "discount",
"rule": "if (customer.orders == 0) return total * 0.9; else return total;"
}
La segunda versión parece flexible, pero empuja la complejidad a la capa de datos: ahora necesitas un evaluador seguro, reglas de versionado, límites de seguridad, herramientas de depuración y un plan de migración cuando el lenguaje de reglas cambie.
Por qué esto hace los sistemas evolutivos
Cuando la información almacenada se mantiene simple y explícita, puedes cambiar el comportamiento con el tiempo sin reescribir la historia. Los registros antiguos siguen siendo legibles. Se pueden añadir servicios nuevos sin “entender” reglas de ejecución heredadas. Y puedes introducir nuevas interpretaciones—nuevas vistas UI, nuevas estrategias de precios, nuevos análisis—escribiendo nuevo código, no mutando lo que tus datos significan.
Aplicar estas ideas a sistemas complejos (sin reescribir todo)
La mayoría de sistemas empresariales no fallan porque un módulo sea “malo”. Fallan porque todo está conectado con todo.
Modos de fallo a vigilar
El acoplamiento fuerte aparece como cambios “pequeños” que desencadenan semanas de retesting. Añadir un campo en un servicio rompe tres consumidores downstream. Un esquema de base de datos compartida se convierte en cuello de botella de coordinación. Un cache mutable único o un objeto singleton de “config” se vuelve dependencia de la mitad del código.
El cambio en cascada es la consecuencia natural: muchas partes comparten lo mismo que cambia y el radio de impacto se expande. Los equipos responden añadiendo más procesos, más reglas y más handoffs—a menudo haciendo las entregas aún más lentas.
Reducir el radio de impacto con límites más simples
Puedes aplicar las ideas de Hickey sin cambiar de lenguaje ni reescribir todo:
- Prefiere datos inmutables en los límites. Trata mensajes, eventos y entradas API como “hechos” que no se editan en el lugar. Si algo cambia, crea una nueva versión.
- Mueve el estado a los bordes. Mantén la lógica central como transformaciones puras: datos de entrada → datos de salida. Deja que bases de datos, caches y UIs manejen el “estado actual”.
- Deja de compartir estructuras mutables. Si dos módulos escriben el mismo objeto, están acoplados. Pasa valores, no referencias que planeas mutar.
Cuando los datos no cambian bajo tus pies, pasas menos tiempo depurando “¿cómo llegó a este estado?” y más tiempo razonando sobre lo que hace el código.
“Mejores predeterminados” entre equipos
Los predeterminados son donde se cuela la inconsistencia: cada equipo inventa su propio formato de timestamp, forma de error, política de reintentos y enfoque de concurrencia.
Mejores predeterminados se ven como: esquemas de eventos versionados, DTOs inmutables estándar, propiedad clara de escrituras y un pequeño conjunto de bibliotecas aprobadas para serialización, validación y trazado. El resultado es menos integraciones sorpresa y menos arreglos puntuales.
Adopción incremental que funciona en bases de código existentes
Empieza donde ya hay cambio:
- Envuelve módulos existentes con una API que acepte/devuelva datos inmutables.
- Convierte un flujo de trabajo de mucho cambio a registros append-only estilo evento.
- Reemplaza caches mutables compartidos con vistas recomputables desde hechos duraderos.
Este enfoque mejora la fiabilidad y la coordinación del equipo manteniendo el sistema en funcionamiento—y mantiene el alcance lo bastante pequeño para terminar.
Posee tu código fuente
Exporta el código fuente para revisarlo, refactorizarlo y aplicar inmutabilidad en los límites.
Es más fácil aplicar estas ideas cuando tu flujo de trabajo soporta iteración rápida y de bajo riesgo. Por ejemplo, si construyes nuevas features en Koder.ai (una plataforma de vibe-coding basada en chat para web, backend y apps móviles), dos características se mapean directamente al mindset de “mejores predeterminados”:
- Modo de planificación te anima a hacer límites y formas de datos explícitos antes de implementar—frecuentemente la diferencia entre un flujo de datos simple y un acoplamiento accidental.
- Instantáneas y reversión hacen que los cambios sean más seguros para desplegar, porque puedes revertir rápidamente cuando un atajo “fácil” se convierte en un pico de complejidad.
Aunque tu stack sea React + Go + PostgreSQL (o Flutter en móvil), el punto central sigue: las herramientas que usas a diario enseñan silenciosamente una forma de trabajo. Elegir herramientas que hagan la trazabilidad, el rollback y la planificación explícita algo rutinario reduce la presión por “parchear en caliente”.
Tradeoffs, límites y evitar la ideología
La simplicidad y la inmutabilidad son predeterminados poderosos, no reglas morales. Reducen el número de cosas que pueden cambiar inesperadamente, lo cual ayuda cuando los sistemas crecen. Pero los proyectos reales tienen presupuestos, plazos y restricciones—y a veces la mutabilidad es la herramienta correcta.
Cuando la mutabilidad es aceptable
La mutabilidad puede ser una elección práctica en hotspots de rendimiento (bucles apretados, parsing de alto rendimiento, trabajo numérico) donde las asignaciones dominan. También puede estar bien cuando el alcance está controlado: variables locales dentro de una función, un cache privado detrás de una interfaz, o un componente single-threaded con límites claros.
La clave es contención. Si la “cosa mutable” no se filtra, no puede propagar complejidad por toda la base de código.
Limita la complejidad con propiedad e interfaces
Incluso en un estilo mayormente funcional, los equipos necesitan propiedad clara:
- Un módulo posee una pieza de estado y expone una API pequeña.
- Los datos cruzan límites como valores simples (no objetos vivos con comportamiento secreto).
- Los efectos laterales se empujan a los bordes (I/O, bases de datos, tiempo).
Aquí es donde la inclinación de Clojure hacia datos y límites explícitos ayuda, pero la disciplina es arquitectónica, no específica del lenguaje.
Lo que Clojure no va a arreglar
Ningún lenguaje arregla requisitos pobres, un modelo de dominio confuso o un equipo que no se pone de acuerdo en qué significa “hecho”. La inmutabilidad no hará comprensible un flujo confuso, y el código “funcional” todavía puede codificar reglas de negocio incorrectas—solo que más ordenadamente.
Evita el dogma: reduce el riesgo con el cambio más pequeño
Si tu sistema ya está en producción, no tomes estas ideas como un todo-o-nada. Busca el movimiento más pequeño que reduzca riesgo:
- Reemplaza estructuras mutables compartidas por datos inmutables en límites de módulo.
- Añade logs de eventos o historial append-only donde importe la auditabilidad.
- Envuelve el estado legado detrás de una interfaz estrecha y evita que se propague.
El objetivo no es la pureza—es menos sorpresas por cambio.
Una lista práctica para moverte hacia software más simple
Esta es una lista para un sprint que puedes aplicar sin cambiar lenguajes, frameworks o la estructura del equipo.
3–5 cosas para intentar el siguiente sprint
- Haz tus “formas de datos” inmutables por defecto. Trata objetos de request/response, eventos y mensajes como valores que creas una vez y nunca modificas. Si algo debe cambiar, crea una nueva versión.
- Prefiere funciones puras en el medio de los flujos. Empieza con un flujo (p. ej., pricing, permisos, checkout) y refactoriza el núcleo en funciones que tomen datos y devuelvan datos—sin lecturas/escrituras ocultas.
- Mueve el estado a menos y más claros lugares. Elige una fuente de verdad por concepto (estado del cliente, feature flags, inventario). Si múltiples módulos mantienen copias, haz que sea una decisión explícita con una estrategia de sincronización.
- Añade un log append-only para hechos clave. Para un área de dominio, registra “qué pasó” como eventos duraderos (aunque sigas almacenando estado actual). Esto mejora la trazabilidad y reduce la suposición.
- Define predeterminados más seguros en APIs. Los predeterminados deberían minimizar comportamientos sorprendentes: zonas horarias explícitas, manejo explícito de nulls, reintentos explícitos, garantías de orden explícitas.
Preguntas para revisión de diseño (úsalas tal cual)
- ¿Cuáles son las partes mutables aquí y quién está autorizado a cambiarlas?
- ¿Podemos modelar esto como “hechos” más una vista derivada en vez de sobrescribir campos?
- Si dos requests se ejecutan al mismo tiempo, ¿qué falla?
- ¿En qué predeterminados confiamos (tiempo, orden, reintentos, caching) y están documentados?
- ¿Qué necesitaríamos para depurar esto dentro de tres meses?
Temas recomendados para revisar de las charlas de Hickey
Busca material sobre simplicidad vs facilidad, gestión del estado, diseño orientado a valores, inmutabilidad y cómo el “historial” (hechos en el tiempo) ayuda a la depuración y operaciones.
La simplicidad no es una característica que añades después: es una estrategia que practicas en elecciones pequeñas y repetibles.