Definir objetivos y alcance para el seguimiento de fiabilidad
Antes de elegir métricas o construir dashboards, decide de qué se encargará tu app de fiabilidad y de qué no. Un alcance claro evita que la herramienta se convierta en un “portal de ops” para todo que nadie confíe.
Define qué vas a monitorizar
Empieza listando las herramientas internas que cubrirá la app (p. ej., ticketing, nóminas, integraciones CRM, pipelines de datos) y los equipos que las poseen o dependen de ellas. Sé explícito sobre los límites: “sitio web orientado al cliente” puede estar fuera de alcance, mientras que “consola de administración interna” está dentro.
Acordar qué significa “fiabilidad” aquí
Diferentes organizaciones usan esta palabra de formas distintas. Escribe tu definición operativa en lenguaje claro: típicamente una mezcla de:
- Disponibilidad: ¿pueden acceder las personas cuando lo necesitan?
- Latencia: ¿es suficientemente rápido para ser usable?
- Errores: ¿falla de formas que los usuarios notan (timeouts, fallos de jobs, respuestas erróneas)?
Si los equipos no están de acuerdo, tu app acabará comparando peras con manzanas.
Decide los resultados que quieres
Elige 1–3 resultados principales, como:
- Detección más rápida de problemas (reducir el “time to notice”)
- Informes más claros para managers y stakeholders
- Menos incidentes repetidos mediante seguimiento efectivo
Esos resultados guiarán qué medir y cómo presentarlo.
Identifica usuarios y roles
Lista quién usará la app y qué decisiones toman: ingenieros investigando incidentes, soporte escalando problemas, managers revisando tendencias y stakeholders que necesitan actualizaciones de estado. Esto moldeará la terminología, permisos y el nivel de detalle de cada vista.
Elige las métricas de fiabilidad que importan (SLIs/SLOs)
El seguimiento funciona solo si todos están de acuerdo en qué significa “bien”. Empieza separando tres términos que suenan parecido.
SLIs vs SLOs vs SLAs (en lenguaje llano)
Un SLI (Service Level Indicator) es una medición: “¿qué porcentaje de peticiones tuvo éxito?” o “¿cuánto tardan en cargar las páginas?”
Un SLO (Service Level Objective) es la meta para esa medición: “99.9% de éxito durante 30 días”.
Un SLA (Service Level Agreement) es una promesa con consecuencias, normalmente externa (créditos, penalizaciones). Para herramientas internas, a menudo establecerás SLOs sin SLAs formales—suficiente para alinear expectativas sin convertir la fiabilidad en derecho contractual.
Elige un conjunto pequeño y consistente de SLIs por herramienta
Manténlo comparable entre herramientas y fácil de explicar. Una línea base práctica es:
- Uptime/disponibilidad: ¿era accesible la herramienta?
- Tiempo de respuesta: ¿qué tan rápido respondían páginas o endpoints clave?
- Tasa de errores: ¿qué proporción de checks o peticiones fallaron (5xx, timeouts, estados de fallo conocidos)?
Evita añadir más hasta poder responder: “¿qué decisión impulsará esta métrica?”
Elige ventanas temporales que coincidan con cómo piensa la gente
Usa ventanas móviles para que los scorecards se actualicen continuamente:
- 7 días: detecta regresiones rápidamente
- 30 días: informes y tendencias mensuales
- 90 días: estabilidad a nivel trimestral
Define incidentes con niveles de severidad claros
Tu app debe convertir métricas en acción. Define niveles de severidad (p. ej., Sev1–Sev3) y desencadenantes explícitos como:
- Sev1: herramienta caída o flujo crítico bloqueado durante X minutos
- Sev2: degradación mayor (p. ej., tasa de error por encima de Y% durante Z minutos)
- Sev3: problemas menores o intermitentes
Estas definiciones hacen que el alertado, las líneas de tiempo de incidentes y el seguimiento de presupuesto de errores sean consistentes entre equipos.
Planifica las fuentes de datos y el enfoque de ingestión
Una app de seguimiento de fiabilidad solo es tan creíble como sus datos. Antes de construir pipelines de ingestión, mapea cada señal que tratarás como “verdad” y escribe qué pregunta responde (disponibilidad, latencia, errores, impacto de despliegues, respuesta a incidentes).
Mapea las fuentes de datos que ya tienes
La mayoría de equipos puede cubrir lo básico usando una mezcla de:
- Cheques de estado / probes sintéticos (uptime y tiempo de respuesta básico)
- Métricas (percentiles de latencia, tasas de error, saturación)
- Logs (conteos de errores, endpoints con más fallos)
- Traces (dónde se consume la latencia entre dependencias)
- Herramientas de ticketing/incidentes (inicio/fin de incidentes, severidad, propietario, enlaces a postmortems)
Sé explícito sobre qué sistemas son autoritativos. Por ejemplo, tu “SLI de uptime” podría provenir solo de probes sintéticos, no de logs de servidor.
Decide push vs. pull (y con qué frecuencia)
- Pull funciona bien para APIs (Prometheus, monitorización cloud, ticketing): tu app consulta en un horario.
- Push es mejor para eventos de alto volumen (despliegues, incidentes, alertas): los sistemas envían webhooks/eventos a tu app.
Establece la frecuencia según el caso de uso: dashboards pueden refrescar cada 1–5 minutos, mientras que los scorecards se calculan cada hora o día.
Normaliza identificadores y ownership
Crea IDs consistentes para herramientas/servicios, entornos (prod/stage) y propietarios. Acordad reglas de naming temprano para que “Payments-API”, “payments_api” y “payments” no sean tres entidades distintas.
Retención y privacidad
Planifica qué conservar y por cuánto tiempo (p. ej., eventos raw 30–90 días, agregados diarios 12–24 meses). Evita ingerir payloads sensibles; guarda solo metadatos necesarios para análisis de fiabilidad (timestamps, códigos de estado, buckets de latencia, etiquetas de incidente).
Diseña el modelo de datos y el esquema de base
Tu esquema debe facilitar dos cosas: responder preguntas del día a día (“¿esta herramienta está sana?”) y reconstruir qué pasó durante un incidente (“¿cuándo empezaron los síntomas, quién cambió qué, qué alertas saltaron?”). Empieza con un conjunto pequeño de entidades core y haz explícitas las relaciones.
Entidades principales (arranca mínimo)
- Tool/Service: la herramienta interna a monitorizar (nombre, descripción, entorno, criticidad).
- Check: un chequeo sintético o uptime ligado a una herramienta (tipo, URL objetivo, schedule, habilitado).
- Metric: datapoints de series temporales (latencia, tasa de éxito, conteo de errores) asociados a una tool o check.
- SLO: objetivo y ventana de evaluación (p. ej., 99.9% en 30 días) y configuración de presupuesto de errores.
- Incident: un evento que impacta la fiabilidad (severidad, estado, inicio/fin, resumen).
- Event: un registro de línea de tiempo para incidentes (cambios de estado, notas, alerta recibida, mitigación aplicada).
- Owner: equipo o individuo responsable de la herramienta.
Relaciones que mantienen simples las consultas
Una base práctica sería:
- Tool tiene muchos Checks (y puede tener muchos SLOs).
- Check tiene muchas Metrics (o streams de métricas).
- Incident pertenece a Tool, y Incident tiene muchos Events para la línea de tiempo.
- Tool pertenece a Owner (o muchos-a-muchos si la propiedad compartida es común).
Esta estructura soporta dashboards (“tool → estado actual → incidentes recientes”) y drill-downs (“incident → events → checks y métricas relacionadas”).
Campos de auditoría y etiquetado
Añade campos de auditoría donde necesites responsabilidad e historial:
created_by, created_at, updated_atstatus más seguimiento de cambios de estado (en la tabla Event o en una tabla history dedicada)
Finalmente, incluye tags flexibles para filtrado e informes (p. ej., equipo, criticidad, sistema, cumplimiento). Una tabla tool_tags (tool_id, key, value) mantiene el etiquetado consistente y facilita rollups y scorecards.
Selecciona stack tecnológico y modelo de despliegue
Tu tracker de fiabilidad debería ser “aburrido” en el mejor sentido: fácil de ejecutar, de cambiar y de dar soporte. El stack “correcto” suele ser el que tu equipo puede mantener sin heroicidades.
Empieza con lo que el equipo ya maneja
Elige un framework web mainstream que conozca el equipo—Node/Express, Django o Rails son opciones sólidas. Prioriza:
- Convenciones claras (para que nuevos contribuyentes no se pierdan)
- Buenas librerías para auth, jobs en background y gráficas
- Rutas de actualización previsibles
Si integras con sistemas internos (SSO, ticketing, chat), escoge el ecosistema donde esas integraciones sean más sencillas.
Si quieres acelerar la primera iteración, una plataforma de vibe-coding como Koder.ai puede ser un punto de partida práctico: describes entidades (tools, checks, SLOs, incidents), flujos (alerta → incidente → postmortem) y dashboards en chat, y generas rápidamente un scaffold de app funcional. Koder.ai suele orientar hacia React en frontend y Go + PostgreSQL en backend, lo que encaja con el stack “aburrido y mantenible” que muchos equipos prefieren—y puedes exportar el código si luego migras a un pipeline manual.
Base de datos primero, luego piezas de apoyo
Para la mayoría de apps internas, PostgreSQL es la opción por defecto: maneja bien consultas relacionales, consultas temporales y auditoría.
Añade componentes extra solo cuando resuelvan un problema real:
- Cache (p. ej., Redis) si los dashboards van lentos o estás limitado por APIs upstream
- Cola/trabajos background (Redis + worker, Sidekiq, Celery, BullMQ) para polling de uptime, envío de notificaciones y generación de informes
Modelo de hosting y despliegue
Decide entre:
- Cloud interno / Kubernetes cuando necesitas acceso de red más estricto a servicios internos
- PaaS cuando quieres operaciones más simples y iteración rápida
Estandariza dev/staging/prod y automatiza despliegues (CI/CD) para que los cambios no alteren silenciosamente los números de fiabilidad. Si usas una plataforma (incluyendo Koder.ai), busca separación de entornos, hosting/despliegue y rollback rápido (snapshots) para iterar sin romper el tracker.
Gestión de configuración confiable
Documenta la configuración en un lugar: variables de entorno, secretos y feature flags. Mantén una guía “cómo ejecutar localmente” y un runbook mínimo (qué hacer si la ingestión para, la cola se acumula o la base alcanza límites). Una página corta en /docs suele ser suficiente.
Diseña la UX: dashboards, drill-downs y flujos
Itera con reversión segura
Usa instantáneas y reversión para iterar en la ingesta y las alertas sin perder una versión estable.
Una app de seguimiento triunfa cuando la gente puede responder en segundos: “¿Estamos bien?” y “¿Qué hago después?” Diseña pantallas alrededor de esas decisiones, con navegación clara de overview → herramienta específica → incidente.
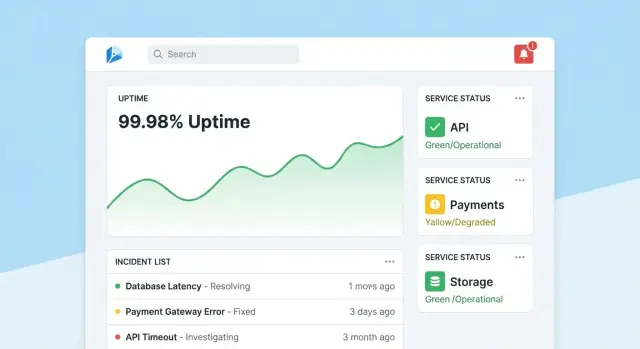
Página principal: lectura rápida de salud
Haz de la página principal un centro de mando compacto. Lidera con un resumen global de salud (p. ej., número de herramientas cumpliendo SLOs, incidentes activos, mayores riesgos actuales), luego muestra incidentes y alertas recientes con badges de estado.
Mantén la vista por defecto tranquila: resalta solo lo que necesita atención. Cada tarjeta debe permitir drill-down directo al servicio o incidente afectado.
Página de la herramienta: del estado a la acción
Cada página de herramienta debe responder “¿esta herramienta es suficientemente fiable?” y “¿por qué / por qué no?” Incluye:
- Estado actual del SLO con un simple aprobado/reprobado y presupuesto de errores restante
- Gráficas de uptime, latencia o tasa de errores en rangos temporales seleccionables
- Cambios recientes (despliegues, ajustes de configuración, updates de checks) para identificar patrones
- Runbooks y owners: una sección prominente “Qué hacer” con enlaces y contactos
Diseña gráficas para no expertos: etiqueta unidades, marca umbrales SLO y añade pequeñas explicaciones (tooltips) en vez de controles densos.
Página de incidente: contexto compartido y línea de tiempo
Una página de incidente es un registro vivo. Incluye una línea de tiempo (eventos auto-capturados como alerta disparada, reconocida, mitigada), actualizaciones humanas, usuarios impactados y acciones tomadas.
Facilita publicar actualizaciones: una caja de texto, estatus predefinidos (Investigating/Identified/Monitoring/Resolved) y notas internas opcionales. Al cerrar el incidente, la acción “Iniciar postmortem” debería autocompletar hechos desde la línea de tiempo.
Páginas admin: ownership y consistencia
Los admins necesitan pantallas sencillas para gestionar tools, checks, objetivos SLO y owners. Optimiza para corrección: valores por defecto sensatos, validación y advertencias cuando los cambios afectan reportes. Añade un rastro visible de “última edición” para que la gente confíe en los números.
Implementa autenticación, permisos y trazas de auditoría
Los datos de fiabilidad solo permanecen útiles si la gente confía en ellos. Eso significa vincular cada cambio a una identidad, limitar quién puede hacer ediciones de alto impacto y mantener un historial claro para revisar.
Autenticación: usa lo que la empresa ya usa
Para una herramienta interna, por defecto usa SSO (SAML) u OAuth/OIDC vía tu IdP (Okta, Azure AD, Google Workspace). Reduce la gestión de contraseñas y automatiza onboarding/offboarding.
Detalles prácticos:
- Exigir MFA vía el IdP (no lo reimplementes)
- Mapear grupos del IdP a roles de la app al iniciar sesión
- Sesiones cortas y soporte para sign-out manual
Permisos: acceso por roles con “acciones protegidas”
Empieza con roles simples y añade reglas más finas solo cuando haga falta:
- Viewer: dashboards y scorecards en solo lectura
- Editor: crear/actualizar checks, incidentes y notas
- Admin: gestionar definiciones SLO, umbrales, integraciones y mappings de usuarios/roles
Protege acciones que cambian resultados o narrativas de reporte:
- Solo Admins pueden cambiar objetivos SLO, umbrales de alertas o mappings de fuentes de datos
- Restringe quién puede cerrar incidentes o marcarlos como “resueltos”, y exige un resumen de resolución
Trazas de auditoría: historial inmutable de cambios
Loguea cada edición de SLOs, checks y campos de incidentes con:
- quién lo hizo (usuario + rol)
- cuándo ocurrió (timestamp)
- qué cambió (valores antes/después)
- de dónde vino (UI, API, automatización)
Haz los logs de auditoría buscables y visibles desde las páginas relevantes (p. ej., la página de un incidente muestra su historia completa). Esto mantiene las revisiones basadas en hechos y reduce discusiones durante postmortems.
Construye cheques de monitorización y recolección de uptime
La monitorización es la “capa sensor” de tu app: convierte el comportamiento real en datos confiables. Para herramientas internas, los checks sintéticos son a menudo la vía más rápida porque controlas qué significa “healthy”.
Define checks sintéticos por herramienta
Arranca con un conjunto pequeño de tipos de checks que cubren la mayoría de apps internas:
- HTTP ping: confirmar que el servicio responde (código de estado, TLS, cabeceras básicas)
- Validación de endpoint: llamar a una URL conocida y validar algo significativo (forma JSON esperada, una cadena clave en HTML o payload del endpoint /health)
- Ruta “smoke” sin login: si es posible, probar un flujo de solo lectura que refleje la experiencia de usuario (p. ej., cargar la página del dashboard y verificar que renderiza)
Mantén las validaciones determinísticas. Si una validación puede fallar por contenido cambiante, generarás ruido y erosionarás la confianza.
Recoge uptime y latencia (y almacénalo con criterio)
Por cada ejecución de check captura:
- Timestamp (inicio y fin)
- Resultado: up/down/unknown
- Latencia: duración total (y opcionalmente DNS/connect/TTFB si lo mides)
- Razón: código de error, timeout, fallo de validación o mensaje de excepción
Almacena datos como eventos de series temporales (una fila por ejecución) o como agregados por intervalo (rollups por minuto con cuentas y p95 de latencia). Los eventos raw son excelentes para depuración; los rollups son mejores para dashboards rápidos. Muchas equipos mantienen ambos: raw por 7–30 días y rollups para reportes a largo plazo.
Trata explícitamente outages vs. datos faltantes
Un resultado faltante no debe ser automáticamente “down”. Añade un estado unknown para casos como:
- el worker de checker está parado
- partición de red entre checker y objetivo
- configuración eliminada a mitad de ejecución
Esto evita inflar el downtime y hace las “brechas de monitoreo” visibles como su propio problema operativo.
Ejecuta checks programados con jobs en background
Usa workers en background (scheduling tipo cron, colas) para ejecutar checks en intervalos fijos (p. ej., 30–60 segundos para herramientas críticas). Implementa timeouts, reintentos con backoff y límites de concurrencia para que el checker no sobrecargue servicios internos. Persiste cada resultado—incluso fallos—para que el dashboard de uptime muestre estado actual y un historial fiable.
Crea flujos de alertado y notificaciones
Añade vistas de estado móviles
Crea ahora una app web y extiéndela a pantallas móviles con Flutter cuando los equipos necesiten estado en movimiento.
Las alertas convierten el seguimiento en acción. El objetivo es simple: notificar a las personas correctas, con el contexto adecuado, en el momento justo—sin inundar a nadie.
Vincula alertas a SLOs (no solo a umbrales)
Define reglas de alerta que mapeen directamente a tus SLIs/SLOs. Dos patrones prácticos:
- Alertas por burn-rate: notificar cuando el presupuesto de errores se consume a ritmo que hará imposible cumplir el SLO a menos que cambie algo.
- Incumplimientos por umbral: avisar cuando una métrica cruza un límite claro (p. ej., disponibilidad < 99.5% en 15 minutos).
Para cada regla, almacena el “por qué” junto al “qué”: qué SLO impacta, la ventana de evaluación y la severidad prevista.
Haz las notificaciones accionables
Envía notificaciones por los canales que los equipos ya usan (email, Slack, Microsoft Teams). Cada mensaje debe incluir:
- Un resumen en una línea (servicio + síntoma + severidad)
- Un enlace directo a la vista de dashboard relevante (p. ej., /services/payments?window=1h)
- Un enlace a la página de incidente si se creó (p. ej., /incidents/123)
Evita volcar métricas raw. Ofrece un “siguiente paso” corto como “Revisa despliegues recientes” o “Abre logs”.
Reduce ruido con dedupe, agrupamiento y horas de silencio
Implementa:
- Deduplificación (mismo fingerprint de alerta → actualizar el hilo existente)
- Agrupamiento (un incidente puede coleccionar múltiples alertas relacionadas)
- Horas de silencio y reglas de enrutamiento para que alertas de baja severidad no despierten al on-call
Soporta escalado y routing on-call
Aunque sea una herramienta interna, la gente necesita control. Añade escalado manual (botón en la página de alerta/incidente) e integra con tooling de on-call si existe (PagerDuty/Opsgenie) o, al menos, una rotación configurable almacenada en la app.
Añade gestión de incidentes y funcionalidades de postmortem
La gestión de incidentes convierte “vimos una alerta” en una respuesta compartida y trazable. Incorpora esto en la app para que la gente vaya de señal a coordinación sin saltar entre herramientas.
Creación de incidente con un clic
Permite crear un incidente directamente desde una alerta, una página de servicio o una gráfica de uptime. Prefill campos clave (servicio, entorno, fuente de la alerta, primer visto) y asigna un ID único.
Un conjunto por defecto de campos mantiene esto ligero: severidad, impacto en clientes (equipos internos afectados), owner actual y enlaces a la alerta desencadenante.
Ciclo de vida y colaboración
Usa un ciclo simple que refleje cómo trabajan los equipos:
- Open → Investigating → Mitigated → Resolved
Cada cambio de estado debe capturar quién lo hizo y cuándo. Añade actualizaciones en la línea de tiempo (notas cortas con timestamp), y soporte para adjuntos y enlaces a runbooks y tickets (p. ej., /runbooks/payments-retries o /tickets/INC-1234). Esto se convierte en el hilo único de “qué pasó y qué hicimos”.
Postmortems con acciones
Los postmortems deben ser rápidos de iniciar y consistentes para revisar. Proporciona plantillas con:
- Resumen, impacto, detección y causa raíz
- Factores contribuyentes (incluyendo fallos de proceso)
- Qué funcionó / qué no
- Acciones de seguimiento con responsables y fechas de vencimiento
Vincula los ítems de acción al incidente, haz seguimiento de su cumplimiento y muestra elementos atrasados en dashboards de equipo. Si soportas “learning reviews”, permite un modo sin culpas que se centre en sistemas y procesos en vez de errores individuales.
Inicia un piloto enfocado
Despliega un rastreador ligero para 2-3 herramientas para validar SLIs, alertas y responsabilidades.
El reporting es donde el seguimiento de fiabilidad se vuelve toma de decisiones. Los dashboards ayudan a los operadores; los scorecards ayudan a líderes a entender si las herramientas internas mejoran, qué áreas necesitan inversión y qué significa “bueno”.
Qué incluir en un scorecard
Construye una vista consistente por herramienta (y opcionalmente por equipo) que responda rápido:
- Cumplimiento de SLO a lo largo del tiempo: periodo actual (semana/mes/trimestre) y línea de tendencia frente al objetivo
- Herramientas menos fiables: rankeadas por SLO fallado, minutos de downtime o mayor burn del presupuesto de errores
- MTTR: median y p90 de time-to-restore, para que un incidente largo no oculte un patrón
- Conteo de incidentes: total y desglose por severidad (Sev1–Sev3) comparado con el periodo anterior
Cuando sea posible, añade contexto ligero: “SLO fallado por 2 despliegues” o “Mayor downtime por dependencia X”, sin convertir el informe en un review completo del incidente.
Los líderes rara vez quieren “todo”. Añade filtros por equipo, criticidad de la herramienta (Tier 0–3) y ventana temporal. Asegura que la misma herramienta pueda aparecer en múltiples rollups (equipo platform la posee, finanzas la usa).
Resúmenes y exportaciones
Proporciona resúmenes semanales y mensuales para compartir fuera de la app:
- Export CSV con un clic para hojas de cálculo
- Export PDF limpio para revisiones de estado
Mantén la narrativa consistente (“¿Qué cambió desde el periodo anterior?” “¿Dónde estamos sobre presupuesto?”). Si necesitas un primer texto para stakeholders, enlaza a una guía corta como /blog/sli-slo-basics.
Seguridad, calidad de datos y hardening operativo
Un tracker de fiabilidad se vuelve una fuente de verdad. Trátalo como un sistema productivo: seguro por defecto, resistente a datos erróneos y fácil de recuperar cuando algo falla.
Protege la superficie de la app
Restringe cada endpoint—incluso los “solo internos”.
- Valida inputs en el boundary (tipos, rangos, enums permitidos, tamaños máximos) y rechaza campos desconocidos
- Añade rate limiting por usuario/token para evitar clientes ruidosos que saturen ingestión o dashboards
- Usa consultas parametrizadas y patrones ORM seguros para evitar inyección
Secretos y control de acceso
Mantén credenciales fuera del código y de logs.
Almacena secretos en un gestor y rótalos. Da a la web app acceso a la base con el mínimo privilegio: roles separados de lectura/escritura, restringe acceso solo a las tablas necesarias y usa credenciales de corta duración cuando sea posible. Encripta en tránsito (TLS) entre navegador↔app y app↔base.
Guardarraíles de calidad de datos
Las métricas de fiabilidad solo sirven si los eventos subyacentes son confiables.
Añade comprobaciones server-side para timestamps (desfase de reloj/zonas), campos obligatorios y claves de idempotencia para deduplicar reintentos. Registra errores de ingestión en una dead-letter queue o tabla de “cuarentena” para que eventos malos no envenenen los dashboards.
Fundamentos operativos (no los omitas)
Automatiza migraciones de base y pruebas de rollback. Programa backups, restaura y pruébalos periódicamente, y documenta un plan mínimo de recuperación ante desastres (quién, qué, cuánto tiempo).
Por último, haz la propia app de fiabilidad fiable: añade health checks, monitorización básica de lag en colas y latencia DB, y alerta cuando la ingestión cae silenciosamente a cero.
Plan de despliegue y roadmap de iteración
Una app de seguimiento tiene éxito cuando la gente confía y la usa. Trata el primer lanzamiento como un bucle de aprendizaje, no como un "big bang".
Comienza con un piloto focalizado
Elige 2–3 herramientas internas muy usadas y con owners claros. Implementa un conjunto pequeño de checks (por ejemplo: disponibilidad del homepage, éxito de login y un endpoint API clave) y publica un dashboard que responda: “¿Está arriba? Si no, ¿qué cambió y quién lo posee?”
Mantén el piloto visible pero contenido: un equipo o un pequeño grupo de power users basta para validar el flujo.
Recoge feedback donde duela
En las primeras 1–2 semanas, recopila activamente feedback sobre:
- Qué confunde (nombres de métricas, gráficas, filtros, definiciones)
- Qué es ruido (alertas que no mapean al impacto usuario)
- Qué falta (propiedad, runbooks, enlaces a incidentes)
Convierte el feedback en tareas concretas. Un botón “Reporta un problema con esta métrica” en cada gráfica suele sacar las ideas más rápidas.
Itera con integraciones y automatización
Añade valor por capas: conecta a tu herramienta de chat para notificaciones, luego a tu herramienta de incidentes para creación automática de tickets, luego a CI/CD para marcas de despliegue. Cada integración debe reducir trabajo manual o acortar el tiempo de diagnóstico—si no, solo añade complejidad.
Si prototipas rápido, considera usar el modo de planificación de Koder.ai para mapear el scope inicial (entidades, roles y flujos) antes de generar la primera build. Es una forma sencilla de mantener el MVP ajustado—y como puedes snapshotear y hacer rollback, iteras en dashboards e ingestión conforme los equipos afinan definiciones.
Define métricas de éxito y expande
Antes de desplegar a más equipos, define métricas de éxito como usuarios activos semanales del dashboard, reducción del time-to-detect, menos alertas duplicadas o revisiones SLO consistentes. Publica un roadmap ligero en /blog/reliability-tracking-roadmap y expande herramienta por herramienta con owners claros y sesiones de capacitación.