Qué cubre este post (y por qué importa)
Snowflake popularizó una idea simple pero de gran alcance en los data warehouses en la nube: mantener el almacenamiento de datos y el cómputo de consultas separados. Esa separación cambia dos puntos críticos del día a día de los equipos de datos: cómo escalan los almacenes y cómo los pagas.
En lugar de tratar el warehouse como una única “caja” fija (donde más usuarios, más datos o consultas más complejas compiten por los mismos recursos), el modelo de Snowflake te permite almacenar los datos una vez y arrancar la cantidad de cómputo adecuada cuando la necesitas. El resultado suele ser tiempos de respuesta más rápidos, menos cuellos de botella en picos de uso y un control más claro sobre qué genera coste (y cuándo).
Tema #1: rendimiento y escalado sin los compromisos habituales
Este post explica, en lenguaje claro, qué significa realmente separar almacenamiento y cómputo—y cómo eso afecta a:
- Concurrencia (muchas personas ejecutando consultas al mismo tiempo)
- Escalado elástico (subir y bajar el cómputo)
- Comportamiento de costes (pagar por el cómputo solo mientras funciona, más almacenamiento continuo)
También señalaremos dónde el modelo no lo soluciona todo mágicamente—porque algunas sorpresas en coste y rendimiento vienen del diseño de las cargas de trabajo, no de la plataforma.
Tema #2: por qué el ecosistema puede importar tanto como la velocidad bruta
Una plataforma rápida no es toda la historia. Para muchos equipos, el time-to-value depende de si puedes conectar el warehouse fácilmente con las herramientas que ya usas: pipelines ETL/ELT, paneles BI, herramientas de catálogo/gobernanza, controles de seguridad y fuentes de datos de socios.
El ecosistema de Snowflake (incluyendo patrones de intercambio de datos y distribución tipo marketplace) puede acortar los plazos de implementación y reducir la ingeniería personalizada. Este post cubre cómo se ve la “profundidad del ecosistema” en la práctica y cómo evaluarla para tu organización.
Para quién es esto
Esta guía está escrita para líderes de datos, analistas y responsables no especialistas—cualquiera que necesite entender las compensaciones detrás de la arquitectura de Snowflake, el escalado, los costes y las elecciones de integración sin enterrarse en la jerga del proveedor.
Antes de la separación: por qué los warehouses tradicionales tenían límites
Los almacenes tradicionales se construyeron sobre una suposición simple: compras (o alquilas) una cantidad fija de hardware y ejecutas todo en esa misma caja o clúster. Eso funcionaba cuando las cargas eran previsibles y el crecimiento era gradual, pero generaba límites estructurales cuando los volúmenes de datos y el número de usuarios se aceleraron.
El modelo clásico: clústeres fijos y planificación de capacidad cuidadosa
Los sistemas on‑prem y las primeras migraciones “lift-and-shift” a la nube solían verse así:
- Un único clúster MPP (procesamiento masivamente paralelo) manejaba almacenamiento, CPU y memoria juntos.
- Dimensionabas el clúster para la demanda pico, porque redimensionar era lento, arriesgado o requería downtime.
- La planificación de capacidad se convirtió en un proyecto recurrente: prever crecimiento, justificar presupuesto, pedir hardware, instalar, migrar.
Aunque los proveedores ofrecían “nodos”, el patrón central seguía igual: escalar significaba añadir nodos más grandes o más numerosos a un entorno compartido.
Puntos dolorosos: escalado lento, gasto desperdiciado y colas
Ese diseño genera varios problemas comunes:
- Escalado lento: Si una carga de cierre trimestral necesita más potencia, no siempre puedes añadirla rápidamente. O esperas, o sobredimensionas “por si acaso”.
- Capacidad ociosa: Los clústeres dimensionados para picos están infrautilizados la mayor parte del tiempo—y aun así los pagas (coste de hardware, licencias, tiempo de ops).
- Colas bajo carga: Cuando varios equipos ejecutan consultas a la vez, compiten por los mismos recursos. Trabajos pesados pueden bloquear dashboards interactivos, causando timeouts, usuarios frustrados y reglas tipo “no ejecutes esa consulta en horario laboral”.
Porque estos warehouses estaban fuertemente acoplados a su entorno, las integraciones crecían de forma orgánica: scripts ETL personalizados, conectores hechos a mano y pipelines puntuales. Funcionaban—hasta que cambió un esquema, se movió un sistema upstream o se introdujo una nueva herramienta. Mantener todo en marcha podía parecer mantenimiento constante en lugar de progreso sostenido.
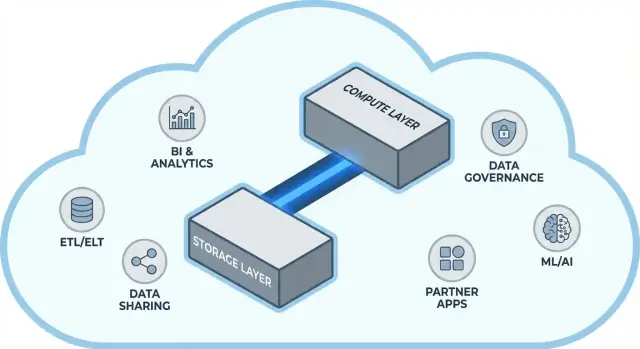
La idea central: separar almacenamiento y cómputo
Los data warehouses tradicionales suelen unir dos trabajos muy distintos: almacenamiento (donde viven tus datos) y cómputo (la potencia que lee, une, agrega y escribe esos datos).
Almacenamiento vs. cómputo (en términos sencillos)
Almacenamiento es como una despensa a largo plazo: tablas, ficheros y metadatos se guardan de forma segura y barata, diseñados para ser duraderos y siempre accesibles.
Cómputo es como el equipo de cocina: es el conjunto de CPUs y memoria que realmente “cocina” tus consultas—ejecuta SQL, ordena, escanea, genera resultados y atiende a múltiples usuarios a la vez.
Snowflake separa estos dos para que puedas ajustar cada uno sin forzar al otro a cambiar.
- Si crece el volumen de datos, añades más almacenamiento (normalmente incremental y predecible).
- Si sube el tráfico de informes, añades más cómputo (redimensionando o añadiendo almacenes virtuales) sin mover o duplicar los datos.
En la práctica, esto cambia las operaciones diarias: no tienes que “comprar de más” cómputo solo porque el almacenamiento crece, y puedes aislar cargas (por ejemplo, analistas frente a ETL) para que no se ralenticen entre sí.
Qué no es
Esta separación es poderosa, pero no es mágica.
- No es escalado gratuito. Más o mayores almacenes generalmente implican mayor gasto en cómputo.
- No es ahorro automático. Consultas mal escritas, horarios de refresco innecesarios o almacenes siempre encendidos pueden seguir elevando los costes.
- No es una excusa para no planificar. Aun necesitas elegir tamaños de almacén, reglas de auto-suspend y alinear el cómputo con patrones de uso del negocio.
El valor es control: pagar por almacenamiento y cómputo por separado, y alinear cada uno con lo que tus equipos realmente necesitan.
Arquitectura de Snowflake en términos sencillos
Snowflake es más fácil de entender como tres capas que trabajan juntas, pero que pueden escalar de forma independiente.
1) Almacenamiento: object storage de la nube
Tus tablas finalmente existen como ficheros en el object storage de tu proveedor en la nube (piensa S3, Azure Blob o GCS). Snowflake gestiona los formatos de fichero, compresión y organización por ti. No “adjuntas discos” ni dimensionas volúmenes: el almacenamiento crece a medida que crecen los datos.
2) Cómputo: almacenes virtuales
El cómputo se empaqueta como almacenes virtuales: clústeres independientes de CPU/memoria que ejecutan consultas. Puedes ejecutar múltiples almacenes contra los mismos datos al mismo tiempo. Esa es la diferencia clave con sistemas antiguos donde cargas pesadas tendían a competir por la misma piscina de recursos.
Una capa de servicios separada maneja el “cerebro” del sistema: autenticación, parsing y optimización de consultas, gestión de transacciones/metadatos y coordinación. Esta capa decide cómo ejecutar una consulta de forma eficiente antes de que el cómputo toque los datos.
Cómo fluye una consulta
Cuando envías SQL, la capa de servicios de Snowflake lo parsea, construye un plan de ejecución y entrega ese plan a un almacén virtual elegido. El almacén lee solo los ficheros de datos necesarios desde el object storage (y se beneficia del cache cuando es posible), los procesa y devuelve resultados—sin mover permanentemente tus datos base al almacén.
Concurrencia y aislamiento (sin jerga)
Si muchas personas ejecutan consultas a la vez, puedes:
- usar almacenes separados para distintos equipos/cargas (aislamiento de workloads), o
- habilitar almacenes multi-clúster para que Snowflake agregue clústeres de cómputo cuando la demanda sube y luego reduzca.
Esa es la base arquitectónica detrás del rendimiento de Snowflake y del control sobre “vecinos ruidosos”.
Escalado y concurrencia: lo que realmente cambia
El gran cambio práctico de Snowflake es que escalas cómputo independientemente de los datos. En lugar de “el warehouse se hace más grande”, obtienes la capacidad de ajustar recursos por carga—sin copiar tablas, reordenar discos o programar downtime.
Elasticidad: redimensionar cómputo sin mover datos
En Snowflake, un almacén virtual es el motor de cómputo que ejecuta consultas. Puedes redimensionarlo (por ejemplo, de Small a Large) en segundos, y los datos permanecen en el almacenamiento compartido. Eso hace que afinar el rendimiento sea a menudo una pregunta simple: “¿Necesita esta carga más potencia ahora mismo?”
Esto también permite ráfagas temporales: escala para un cierre de mes, y vuelve a reducir cuando termina el pico.
Concurrencia: menos peleas por la cola
Los sistemas tradicionales a menudo obligan a distintos equipos a compartir el mismo cómputo, lo que convierte las horas de mayor carga en una fila. Snowflake te permite ejecutar almacenes separados por equipo o por carga—por ejemplo, uno para analistas, otro para dashboards y otro para ETL. Como estos almacenes leen los mismos datos subyacentes, reduces el problema de “mi dashboard ralentizó tu informe” y haces el rendimiento más predecible.
Compromisos que notarás
El cómputo elástico no es éxito automático. Fallos comunes incluyen:
- Arranques en frío: los almacenes suspendidos pueden tardar un momento en reanudar, lo que añade latencia en trabajos infrecuentes.
- Elección de tamaño correcta: sobredimensionar desperdicia dinero; subdimensionar provoca consultas lentas y frustración.
- Necesidad de límites: usa auto-suspend/auto-resume, monitores de recurso y una propiedad clara para que los almacenes no queden encendidos o se descontrolen.
El cambio neto: el escalado y la concurrencia pasan de proyectos de infraestructura a decisiones operativas diarias.
Modelo de costes: dónde se producen ahorros (y dónde no)
Controla el gasto del almacén de datos
Construye un centro ligero de costos y uso que ayude a los equipos a identificar los factores que generan el gasto en cómputo.
Cómo funciona la facturación en Snowflake
El “paga por lo que usas” de Snowflake es básicamente dos contadores corriendo en paralelo:
- Cómputo: facturado por el tiempo que tu almacén virtual está en ejecución (en créditos).
- Almacenamiento: facturado por la cantidad de datos almacenados (más almacenamiento adicional por features como Time Travel/Fail-safe).
Ese split es donde pueden ocurrir ahorros: puedes mantener muchos datos de forma relativamente barata mientras enciendes el cómputo solo cuando lo necesitas.
Dónde se disparan los costes
La mayoría del gasto “inesperado” proviene de comportamientos de cómputo más que del almacenamiento. Los impulsores comunes incluyen:
- Almacenes sobredimensionados (escoger un tamaño mayor del necesario)
- Workloads siempre encendidos (almacenes que quedan funcionando por la noche o fines de semana)
- Consultas ineficientes (escaneos sin filtros, joins innecesarios, transformaciones pesadas que se ejecutan repetidamente)
- Patrones de alta concurrencia (muchos dashboards pequeños refrescándose constantemente)
Separar almacenamiento y cómputo no hace las consultas eficientes automáticamente—un SQL pobre aún puede consumir créditos rápidamente.
Controles prácticos que funcionan en el mundo real
No necesitas al departamento financiero para gestionar esto—solo unos pocos límites:
- Auto-suspend / auto-resume para dejar de pagar por tiempo ocioso
- Monitores de recurso para alertar o limitar consumo de créditos por almacén/equipo
- Programación (ejecutar jobs batch en ventanas definidas; pausar dev/test fuera del horario laboral)
- Right-sizing y probar tamaños más pequeños antes de escalar
Usado bien, el modelo premia la disciplina: cómputo de corta duración y tamaño correcto emparejado con un crecimiento de almacenamiento predecible.
Intercambio de datos y colaboración como característica de primera clase
Snowflake trata el intercambio como algo diseñado en la plataforma—no como un parche añadido con exportaciones, drops de ficheros y ETL puntuales.
Compartir sin copiar (en muchos casos)
En lugar de enviar extractos, Snowflake puede permitir que otra cuenta consulte los mismos datos subyacentes mediante un “share” seguro. En muchos escenarios, los datos no necesitan duplicarse en un segundo warehouse ni enviarse a object storage para descargar. El consumidor ve la base de datos/tabla compartida como si fuera local, mientras el proveedor mantiene el control de lo expuesto.
Este enfoque desacoplado es valioso porque reduce la proliferación de datos, acelera el acceso y disminuye la cantidad de pipelines que hay que construir y mantener.
Patrones comunes de colaboración
Compartir con socios y clientes: Un proveedor puede publicar datasets curados para clientes (por ejemplo, analítica de uso o datos de referencia) con límites claros—solo esquemas, tablas o vistas permitidas.
Compartir interno por dominios: Equipos centrales pueden exponer datasets certificados a producto, finanzas y operaciones sin obligar a cada equipo a crear sus propias copias. Eso favorece una cultura de “un único conjunto de cifras” y permite que los equipos ejecuten su propio cómputo.
Colaboración gobernada: Proyectos conjuntos (p. ej., con una agencia, proveedor o subsidiaria) pueden trabajar sobre un dataset compartido mientras columnas sensibles están enmascaradas y el acceso queda auditado.
Limitaciones que planear
Compartir no es “configúralo y olvídalo”. Aún necesitas:
- Gobernanza: propiedad clara, revisiones de acceso y políticas para PII/datos regulados.
- Contratos y expectativas: quién paga el cómputo, SLAs, retención y qué ocurre cuando cambian las definiciones.
- Descubribilidad: sin catálogo y buen nombrado, la gente no encontrará (o confiará en) los datos compartidos. Alinea los shares con documentación y tu catálogo de datos si tienes uno.
Por qué los ecosistemas pueden importar tanto como el rendimiento
Un warehouse rápido es valioso, pero la velocidad rara vez determina si un proyecto se entrega a tiempo. Lo que suele marcar la diferencia es el ecosistema alrededor de la plataforma: las conexiones listas para usar, herramientas y conocimientos que reducen trabajo personalizado.
En la práctica, un ecosistema incluye:
- Conectores a orígenes y destinos (apps SaaS, bases de datos, herramientas de streaming)
- Herramientas de socios para ingestión, transformación, BI, calidad de datos y observabilidad
- Apps e integraciones nativas que corren cerca de los datos
- Plantillas y arquitecturas de referencia (modelos comunes, patrones, guías de despliegue)
- Conocimiento comunitario: ejemplos, foros, meetups y disponibilidad para contratar
Por qué el ecosistema puede vencer a los benchmarks para la velocidad de entrega
Los benchmarks miden una porción estrecha del rendimiento bajo condiciones controladas. Los proyectos reales pasan la mayor parte del tiempo en:
- Hacer que los datos entren de forma fiable e incremental
- Modelar, probar y documentar datasets
- Tareas operativas (monitorización, alertas, control de costes)
- Revisiones de seguridad, controles de acceso y auditorías
Si tu plataforma tiene integraciones maduras para estos pasos, evitas construir y mantener código pegamento. Eso normalmente acorta los tiempos de implementación, mejora la fiabilidad y facilita cambiar de equipos o proveedores sin reescribirlo todo.
Un criterio simple para evaluar: cobertura, calidad, mantenibilidad
Al evaluar un ecosistema, busca:
- Cobertura: ¿soporta tus fuentes clave, herramientas BI, orquestación y necesidades de gobernanza?
- Calidad: ¿los conectores se mantienen activamente, están bien documentados y probados a tu escala?
- Mantenibilidad: ¿cuánto esfuerzo continuo requiere—actualizaciones, cambios incompatibles, depuración y soporte?
El rendimiento te da capacidad; el ecosistema suele determinar qué tan rápido conviertes esa capacidad en resultados de negocio.
Ecosistema de integración: meter datos, sacarlos y hacerlos útiles
Convierte SQL en una app
Genera una interfaz React y un esqueleto de API en Go para tus consultas del almacén de datos en minutos.
Snowflake puede ejecutar consultas rápidas, pero el valor aparece cuando los datos se mueven de forma fiable por tu stack: desde las fuentes, dentro de Snowflake y de vuelta a las herramientas que usan las personas a diario. La “última milla” suele determinar si una plataforma se siente sin esfuerzo o constantemente frágil.
Categorías principales de integración a planear
La mayoría de equipos necesitan una mezcla de:
- ELT/ETL para ingerir desde bases de datos, apps SaaS, ficheros y object storage.
- BI y analítica para dashboards, exploración self-serve y capas semánticas.
- Reverse ETL para empujar datos curados de vuelta a CRM, marketing y sistemas de soporte.
- Orquestación para programación, dependencias, backfills y promoción entre entornos.
- Streaming para eventos casi en tiempo real y captura de cambio (CDC).
- Herramientas de ML para pipelines de features, entrenamientos y monitorización de modelos.
Preguntas a hacer antes de elegir conectores
No todas las herramientas “compatibles con Snowflake” se comportan igual. En la evaluación, céntrate en detalles prácticos:
- ¿El conector está certificado/soportado (y por quién)? ¿Cuál es la vía de escalado?
- ¿Puede manejar cargas incrementales limpiamente (CDC, timestamps, high-water marks)?
- ¿Cómo trata la deriva de esquemas—nuevas columnas, cambios de tipo, campos eliminados?
- ¿Qué garantías hay sobre reintentos, deduplicación y exactly-once vs at-least-once?
No ignores las operaciones
Las integraciones también necesitan estar listas para el día 2: monitorización y alertas, hooks de lineage/catalog y flujos de respuesta a incidentes (ticketing, on-call, runbooks). Un ecosistema fuerte no son solo más logos—son menos sorpresas cuando los pipelines fallan a las 2 a.m.
Gobernanza, seguridad y confianza a escala
A medida que los equipos crecen, la parte más difícil de la analítica suele dejar de ser la velocidad: es asegurarse de que las personas correctas acceden a los datos correctos, con propósito correcto y con pruebas de que los controles funcionan. Las funcionalidades de gobernanza de Snowflake están pensadas para esa realidad: muchos usuarios, muchos productos de datos y compartición frecuente.
Fundamentos de gobernanza que realmente aguantan
Empieza por roles claros y una mentalidad de mínimos privilegios. En lugar de dar acceso directamente a individuos, define roles como ANALYST_FINANCE o ETL_MARKETING, y luego otórgales acceso a bases de datos, esquemas, tablas y (cuando haga falta) vistas.
Para campos sensibles (PII, identificadores financieros), usa políticas de enmascaramiento para que la gente pueda consultar datasets sin ver los valores crudos a menos que su rol lo permita. Combínalo con auditoría: registra quién consultó qué y cuándo, para que seguridad y cumplimiento respondan sin conjeturas.
Por qué la gobernanza cambia el sharing y la autoservicio
Una buena gobernanza hace que el intercambio sea más seguro y escalable. Cuando tu modelo de compartición se basa en roles, políticas y accesos auditados, puedes habilitar autoservicio (más usuarios explorando datos) con confianza, sin abrir la puerta a exposiciones accidentales.
También reduce fricción en esfuerzos de cumplimiento: las políticas se vuelven controles repetibles en lugar de excepciones puntuales. Eso importa cuando los datasets se reutilizan entre proyectos, departamentos o socios externos.
Consejos prácticos que evitan dolor futuro
- Convenciones de nombres: estandariza nombres para bases/esquemas que indiquen propósito y sensibilidad (p. ej.,
PROD_FINANCE, DEV_MARKETING, SHARED_PARTNER_X). La consistencia acelera revisiones y reduce errores.
- Separación de entornos: mantiene DEV/TEST/PROD separados lógicamente, con controles más estrictos en PROD. Trata los datos de producción como excepción, no por defecto.
- Revisiones de acceso: fija una cadencia (mensual para datos de alto riesgo, trimestral para el resto). Revisa membresías de roles, usuarios inactivos y roles privilegiados.
Confiar a escala es menos una cuestión de un “control perfecto” y más un sistema de hábitos pequeños y fiables que mantienen el acceso intencional y explicable.
Cargas de trabajo y patrones de buenas prácticas
Dimensiona con salvaguardas
Crea rápidamente una herramienta de administración para decisiones de dimensionamiento del almacén de datos y reglas de aislamiento de cargas.
Snowflake suele brillar cuando muchas personas y herramientas necesitan consultar los mismos datos por diferentes razones. Como el cómputo se empaqueta en “almacenes” independientes, puedes mapear cada carga a una forma y horario que encaje.
Mapeo común de cargas
Analítica y dashboards: Pon las herramientas BI en un almacén dedicado dimensionado para un volumen de consultas estable y predecible. Esto evita que las actualizaciones de dashboards se ralenticen por la exploración ad hoc.
Análisis ad hoc: Da a los analistas un almacén separado (a menudo más pequeño) con auto-suspend habilitado. Obtienes iteración rápida sin pagar por tiempo ocioso.
Ciencia de datos y experimentación: Usa un almacén dimensionado para escaneos más pesados y ráfagas ocasionales. Si los experimentos disparan la carga, aumenta temporalmente este almacén sin afectar a usuarios de BI.
Aplicaciones de datos y analytics embebidos: Trata el tráfico de la app como un servicio en producción—almacén separado, timeouts conservadores y monitores de recurso para evitar gastos sorpresa.
Si construyes apps internas ligeras (por ejemplo, un portal ops que consulta Snowflake y muestra KPIs), un camino rápido es generar un esqueleto React + API funcional e iterar con stakeholders. Plataformas como Koder.ai (una plataforma de vibe-coding que construye apps web/servidor/móviles desde chat) pueden ayudar a los equipos a prototipar estas apps respaldadas por Snowflake rápidamente y luego exportar el código fuente cuando estés listo para operacionalizar.
Patrones de buenas prácticas que se mantienen
Una regla simple: separa los almacenes por audiencia y propósito (BI, ELT, ad hoc, ML, app). Combina eso con buenas prácticas de consulta—evita SELECT * amplio, filtra pronto y vigila joins ineficientes. En modelado, prioriza estructuras que coincidan con cómo la gente consulta (a menudo una capa semántica limpia o marts bien definidos), en lugar de sobre-optimizar diseños físicos.
Cuándo considerar alternativas o complementos
Snowflake no es sustituto de todo. Para cargas transaccionales de muy alto rendimiento y baja latencia (OLTP típico), una base de datos especializada suele ser mejor; Snowflake se usa para analítica, reporting, sharing y productos de datos downstream. Las configuraciones híbridas son comunes y a menudo las más prácticas.
Consideraciones de migración: qué planear antes de moverte
Una migración a Snowflake rara vez es un “lift and shift”. La separación almacenamiento/cómputo cambia cómo dimensionas, ajustas y pagas cargas—así que planificar de antemano evita sorpresas.
Secuencia de migración práctica
Empieza con un inventario: qué fuentes alimentan el warehouse, qué pipelines las transforman, qué dashboards dependen de ello y quién es dueño de cada pieza. Luego prioriza por impacto de negocio y complejidad (p. ej., reporting financiero crítico primero, sandboxes experimentales después).
A continuación, convierte la lógica SQL y ETL. Mucho del SQL estándar se transfiere, pero detalles como funciones, manejo de fechas, código procedimental y patrones de tablas temporales suelen requerir reescrituras. Valida resultados temprano: ejecuta salidas en paralelo, compara conteos de filas y agregados, y confirma casos límite (nulos, zonas horarias, lógica de deduplicación). Finalmente, planifica el corte: ventana de freeze, ruta de rollback y una “definición de hecho” clara para cada dataset e informe.
Riesgos típicos a vigilar
Las dependencias ocultas son lo más común: un extracto de hoja de cálculo, una cadena de conexión hardcodeada, un job downstream que nadie recuerda. Sorpresas de rendimiento pueden aparecer cuando supuestos de tuning antiguos no aplican (p. ej., sobredimensionar tiny warehouses, o ejecutar muchas consultas pequeñas sin considerar concurrencia). Picos de coste suelen venir de dejar almacenes encendidos, reintentos incontrolados o duplicación de entornos dev/test. Gaps de permisos aparecen al migrar de roles toscos a gobernanza más granular—las pruebas deberían incluir ejecuciones con el principio de “least privilege”.
Gestión del cambio (no la omitas)
Define un modelo de propiedad (quién posee datos, pipelines y costes), ofrece formación por roles para analistas e ingenieros y define un plan de soporte para las primeras semanas tras el corte (rotación on-call, runbook de incidentes y un lugar para reportar problemas).
Elegir una plataforma de datos moderna no es solo velocidad máxima en benchmarks. Es si la plataforma encaja con tus cargas reales, la forma de trabajar de tu equipo y las herramientas que ya usas.
Lista de verificación práctica
Usa estas preguntas para guiar tu preselección y conversaciones con proveedores:
- Cargas de trabajo: ¿Ejecutas principalmente dashboards programados, análisis ad-hoc, ciencia de datos, ELT/ETL o apps orientadas al cliente? ¿Necesitas ventanas batch previsibles o capacidad elástica para ráfagas?
- Necesidades de concurrencia: ¿Cuántas personas (o aplicaciones) consultarán a la vez y cuán “picos” son los usos en horario laboral?
- Requisitos de intercambio de datos: ¿Necesitas compartir datos en vivo con socios, unidades de negocio o clientes sin enviar ficheros? ¿Esperas consumir datasets de terceros?
- Ajuste de herramientas: ¿Tus herramientas BI, orquestación, catálogo y CI/CD se integrarán limpiamente? ¿Qué se rompe si te mueves?
- Gobernanza y seguridad: ¿Necesitas control de acceso fino, trails de auditoría, enmascaramiento, políticas de retención y separación clara de funciones?
- Restricciones de coste: ¿Qué costes importan más—gasto en estado estable, gasto en horas pico o la capacidad de apagar cómputo? ¿Cómo evitarás desperdicio por “always-on"?
Plan piloto corto (2–4 semanas)
Elige dos o tres datasets representativos (no muestras pequeñas): una gran tabla de hechos, una fuente semi-estructurada desordenada y un dominio crítico.
Luego ejecuta consultas de usuarios reales: dashboards en el pico matutino, exploración de analistas, cargas programadas y algunos joins en el peor de los casos. Mide: tiempo de consulta, comportamiento en concurrencia, tiempo de ingestión, esfuerzo operativo y coste por carga.
Si parte de tu evaluación incluye “¿qué tan rápido podemos entregar algo que la gente use?”, considera añadir un pequeño entregable al piloto—como una app interna de métricas o un flujo gobernado de peticiones de datos que consulte Snowflake. Construir esa capa fina suele revelar realidades de integración y seguridad más rápido que los benchmarks, y herramientas como Koder.ai pueden acelerar del prototipo a producción generando la estructura de la app vía chat y permitiendo exportar el código.
Siguientes pasos sugeridos
Si quieres ayuda estimando gasto y comparando opciones, empieza por /pricing.
Para guía sobre migración y gobernanza, revisa artículos relacionados en /blog.