Qué significa “Distributed SQL” (sin la exageración)
“Distributed SQL” es una base de datos que se parece y se siente como una base de datos relacional tradicional—tablas, filas, joins, transacciones y SQL—pero está diseñada para ejecutarse como un clúster en muchas máquinas (y a menudo en varias regiones) mientras sigue comportándose como una sola base de datos lógica.
Esa combinación importa porque intenta ofrecer tres cosas a la vez:
- SQL y modelado relacional: esquemas familiares, restricciones y herramientas de consulta.
- Escalado horizontal: añadir nodos para aumentar la capacidad, en lugar de “comprar un servidor más grande”.
- Consistencia fuerte: lecturas y escrituras siguen reglas transaccionales claras, incluso cuando los datos están repartidos.
Entre el RDBMS clásico y NoSQL
Un RDBMS clásico (como PostgreSQL o MySQL) suele ser más fácil de operar cuando todo vive en un nodo primario. Puedes escalar lecturas con réplicas, pero escalar escrituras y sobrevivir a fallos regionales normalmente requiere arquitectura adicional (sharding, failover manual y lógica de aplicación cuidadosa).
Muchos sistemas NoSQL tomaron el enfoque opuesto: escalado y alta disponibilidad primero, a veces relajando garantías de consistencia o ofreciendo modelos de consulta más simples.
Distributed SQL aspira a un camino intermedio: mantener el modelo relacional y las transacciones ACID, pero distribuir los datos automáticamente para manejar crecimiento y fallos.
Qué intenta resolver
Las bases de datos Distributed SQL están hechas para problemas como:
- Aplicaciones globales con usuarios en varias regiones, donde la latencia y la disponibilidad importan.
- Alta disponibilidad sin procedimientos de failover manuales y complejos.
- Crecimiento a lo largo del tiempo, donde quieres aumentar capacidad de forma incremental y mantener una única interfaz de base de datos.
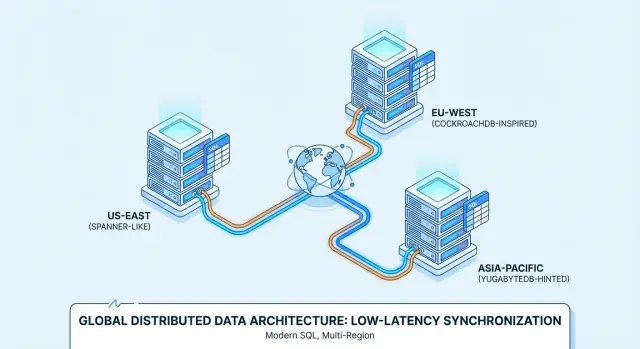
Por eso productos como Google Spanner, CockroachDB y YugabyteDB se evalúan a menudo para despliegues multirregión y servicios siempre activos.
Ajusta expectativas (no es la opción por defecto)
Distributed SQL no es automáticamente “mejor”. Aceptas más piezas en movimiento y diferentes realidades de rendimiento (saltos de red, consenso, latencia entre regiones) a cambio de resiliencia y escalado.
Si tu carga cabe en una sola base de datos bien gestionada con una réplica y una configuración de replicación sencilla, un RDBMS convencional puede ser más simple y barato. Distributed SQL justifica su uso cuando la alternativa es sharding personalizado, failover complejo o requisitos de negocio que exigen consistencia y disponibilidad multirregión.
Cómo funciona Distributed SQL por dentro
Distributed SQL pretende sentirse como una base de datos SQL familiar mientras almacena datos en múltiples máquinas (y a menudo en varias regiones). Lo difícil es coordinar muchos ordenadores para que se comporten como un sistema único y fiable.
Replicación + consenso: cómo se ponen de acuerdo los nodos
Cada fragmento de datos suele copiarse en varios nodos (replicación). Si un nodo falla, otra copia puede seguir sirviendo lecturas y aceptar escrituras.
Para evitar que las réplicas diverjan, los sistemas Distributed SQL usan protocolos de consenso—más comúnmente Raft (CockroachDB, YugabyteDB) o Paxos (Spanner). A alto nivel, consenso significa:
- Una réplica actúa como “líder” para un grupo de réplicas.
- Las escrituras van al líder.
- El líder confirma la escritura solo después de que la mayoría de réplicas la reconozcan.
Esa “votación por mayoría” es lo que te da consistencia fuerte: una vez que una transacción se confirma, otros clientes no verán una versión más antigua de los datos.
Sharding/particionado: dónde vive cada dato
Ninguna máquina puede contenerlo todo, así que las tablas se dividen en trozos más pequeños llamados shards/particiones (Spanner los llama splits; CockroachDB los llama ranges; YugabyteDB los llama tablets).
Cada partición se replica (usando consenso) y se coloca en nodos específicos. La colocación no es aleatoria: puedes influirla mediante políticas (por ejemplo, mantener registros de clientes de la UE en regiones de la UE, o mantener particiones calientes en nodos más rápidos). Una buena colocación reduce los viajes por la red y hace el rendimiento más predecible.
Transacciones entre nodos (y por qué añaden latencia)
Con una base de datos de un solo nodo, una transacción a menudo puede confirmar con trabajo de disco local. En Distributed SQL, una transacción puede tocar múltiples particiones—potencialmente en distintos nodos.
Confirmar de forma segura suele requerir coordinación extra:
- Bloquear o validar datos en las particiones involucradas
- Replicar escrituras vía consenso (confirmaciones de la mayoría)
- Finalizar una decisión de commit para que todos los participantes estén de acuerdo
Esos pasos introducen viajes de red, por eso las transacciones distribuidas suelen añadir latencia—especialmente cuando los datos abarcan regiones.
Comportamiento multirregión: lecturas y escrituras con conciencia de localidad
Cuando los despliegues abarcan regiones, los sistemas intentan mantener las operaciones “cerca” de los usuarios:
- Lecturas con conciencia de localidad pueden servirse desde réplicas cercanas cuando es seguro.
- Escrituras con conciencia de localidad pueden enrutarse a líderes en una región elegida, o colocar líderes cerca de los principales escritores.
Este es el equilibrio central multirregión: puedes optimizar la capacidad de respuesta local, pero la consistencia fuerte a través de largas distancias seguirá teniendo un coste de red.
Cuándo lo necesitas realmente (y cuándo no)
Antes de recurrir a distributed SQL, verifica tus necesidades básicas. Si tienes una sola región principal, carga predecible y un equipo de operaciones pequeño, una base de datos relacional convencional (o Postgres/MySQL gestionado) suele ser la forma más simple de lanzar funciones rápido. A menudo puedes estirar una configuración de una sola región mucho con réplicas de lectura, caching y buen diseño de esquemas/índices.
Disparadores claros: cuando Distributed SQL merece la pena
Distributed SQL merece consideración seria cuando se cumple una (o más) de estas condiciones:
- Tienes usuarios reales en múltiples regiones y quieres que la base de datos esté cerca de ellos sin construir sharding complejo a nivel de aplicación.
- Los requisitos de uptime son altos (p. ej., debes sobrevivir a fallos de zona/región) y una única región primaria es un riesgo inaceptable.
- El volumen de datos o el throughput de escrituras supera el escalado vertical, y quieres escalado horizontal manteniendo la semántica SQL.
- Necesitas consistencia fuerte entre nodos/regiones para transacciones críticas (pedidos, saldos, reservas) sin coser varios sistemas.
- El cumplimiento exige colocación geográfica (residencia de datos) manteniendo una base de datos lógica única.
Anti-disparadores: cuando normalmente no es la opción correcta
Los sistemas distribuidos añaden complejidad y coste. Ten cuidado si:
- Tu equipo es pequeño y no tiene tiempo para aprender nuevos modos de fallo y patrones operativos.
- El tráfico es bajo o esporádico y no es probable que superes una base de datos mono-región pronto.
- Tienes presupuestos de latencia muy estrictos para escrituras de clave única y no puedes tolerar la sobrecarga de coordinación que introduce la consistencia fuerte.
- Tu carga es intensiva en analítica (grandes scans, informes complejos). Puede ser mejor separar OLTP de analítica.
Lista de comprobación rápida
Si puedes responder “sí” a dos o más, probablemente valga la pena evaluar Distributed SQL:
- ¿Necesitas multirregión con datos consistentes?
- ¿Necesitas failover automático entre zonas/regiones?
- ¿El escalado es una crisis recurrente?
- ¿El sharding añadiría más trabajo de ingeniería que la propia base de datos?
- ¿Necesitas aplicar residencia de datos con un único modelo operativo?
Consistencia, disponibilidad y latencia: los compromisos centrales
Distributed SQL suena a “tenerlo todo”, pero los sistemas reales fuerzan elecciones—especialmente cuando las regiones no pueden hablarse de forma fiable.
CAP, explicado para decisiones de producto
Piensa en una partición de red como “el enlace entre regiones está inestable o caído”. En ese momento, una base de datos puede priorizar:
- Consistencia: todos ven la misma respuesta actualizada (o la operación falla).
- Disponibilidad: la app sigue aceptando lecturas/escrituras en cada región (aunque las respuestas diverjan temporalmente).
Los sistemas Distributed SQL suelen construirse favoreciendo la consistencia para transacciones. Eso es lo que muchos equipos desean—hasta que una partición hace que ciertas operaciones deban esperar o fallen.
Consistencia fuerte (y por qué importa en dinero e inventario)
Consistencia fuerte significa que, una vez que una transacción se confirma, cualquier lectura posterior devuelve ese valor confirmado—no “funcionó en una región pero no en otra”. Esto es crítico para:
- Pagos y saldos (evita doble gasto o totales incorrectos)
- Inventario / reservas (previene sobreventa del último artículo)
Si la promesa de tu producto es “cuando lo confirmamos, es real”, la consistencia fuerte es una característica, no un lujo.
Read-your-writes e aislamiento en aplicaciones reales
Dos comportamientos prácticos importan:
- Read-your-writes: después de que un usuario actualice su perfil (o haga un pedido), la siguiente pantalla debe mostrar el nuevo estado, no una réplica más antigua.
- Aislamiento de transacciones: define cómo interactúan acciones concurrentes. Con aislamiento más fuerte evitas errores sutiles como dos clientes reservando la misma plaza.
El coste de latencia del consenso cross-region
La consistencia fuerte entre regiones normalmente requiere consenso (múltiples réplicas deben estar de acuerdo antes del commit). Si las réplicas están en continentes distintos, la velocidad de la luz se convierte en una limitación: cada escritura cross-region puede añadir decenas o cientos de milisegundos.
El tradeoff es simple: más seguridad geográfica y corrección suele significar mayor latencia de escritura a menos que elijas cuidadosamente dónde residen los datos y dónde se permiten commits.
Spanner vs CockroachDB vs YugabyteDB: visión práctica
Google Spanner es una base de datos Distributed SQL ofrecida principalmente como servicio gestionado en Google Cloud. Está diseñada para despliegues multirregión donde quieres una sola base lógica con datos replicados entre nodos y regiones. Spanner soporta dos opciones de dialecto SQL—GoogleSQL (su dialecto nativo) y un dialecto compatible con PostgreSQL—así que la portabilidad varía según el que elijas y de las funciones de tu aplicación.
CockroachDB es una base de datos Distributed SQL que busca resultar familiar a equipos acostumbrados a PostgreSQL. Usa el protocolo wire de PostgreSQL y soporta un gran subconjunto del estilo SQL de Postgres, pero no es un reemplazo byte a byte de Postgres (algunas extensiones y comportamientos en casos límite difieren). Puedes usarlo como servicio gestionado (CockroachDB Cloud) o autoalojarlo.
YugabyteDB es una base de datos distribuida con una API SQL compatible con PostgreSQL (YSQL) y una API adicional compatible con Cassandra (YCQL). Al igual que CockroachDB, se evalúa por equipos que quieren ergonomía parecida a Postgres mientras escalan en nodos y regiones. Está disponible autoalojado y gestionado (YugabyteDB Managed), con despliegues habituales desde HA en una sola región hasta configuraciones multirregión.
Gestionado vs autoalojado: qué cambia
Los servicios gestionados reducen típicamente el trabajo operativo (upgrades, backups, integraciones de monitorización), mientras que el autoalojamiento ofrece más control sobre redes, tipos de instancia y dónde se ejecutan físicamente los datos. Spanner se consume más comúnmente como servicio gestionado en GCP; CockroachDB y YugabyteDB se usan tanto gestionados como autoalojados, incluyendo multi-cloud y on-prem.
Compatibilidad SQL en la práctica
Los tres hablan “SQL”, pero la compatibilidad diaria depende de la elección de dialecto (Spanner), la cobertura de características de Postgres (CockroachDB/YugabyteDB) y de si tu app depende de extensiones, funciones o semánticas transaccionales específicas de Postgres.
Invertir tiempo en pruebas paga: testa tus consultas, migraciones y comportamiento del ORM temprano en lugar de asumir equivalencia plug-and-play.
Caso de uso: SaaS global con usuarios regionales
Experimenta sin miedo
Prueba cambios de esquema arriesgados con snapshots y revierte cuando fallen las pruebas.
Un encaje clásico para Distributed SQL es un producto SaaS B2B con clientes en Norteamérica, Europa y APAC—piensa en herramientas de soporte, plataformas de RRHH, dashboards analíticos o marketplaces.
El requisito de negocio es simple: los usuarios quieren una app “local”, mientras la empresa quiere una base de datos lógica única que esté siempre disponible.
Residencia de datos y colocación por cliente
Muchos equipos SaaS acaban con una mezcla de requisitos:
- Los clientes de la UE esperan que sus datos permanezcan en la UE (GDPR, compromisos contractuales).
- Algunos clientes requieren almacenamiento en el país (p. ej., Alemania, Australia, Singapur).
- Otros no se preocupan, pero sí quieren baja latencia.
Distributed SQL puede modelar esto de forma limpia con localidad por inquilino: coloca los datos primarios de cada inquilino en una región específica (o conjunto de regiones) mientras mantienes el esquema y el modelo de consultas consistente en todo el sistema. Así evitas la proliferación de “una base de datos por región” y cumples requisitos de residencia.
Minimizar la latencia: lecturas regionales y colocación de escrituras
Para mantener la app rápida, normalmente buscas:
- Lecturas regionales: servir consultas mayormente de lectura desde réplicas cercanas.
- Colocación de escrituras: poner el líder de escritura (o el conjunto primario de réplicas) en la región donde el inquilino escribe más.
Esto importa porque los viajes cross-region dominan la latencia percibida por el usuario. Incluso con consistencia fuerte, un buen diseño de localidad asegura que la mayoría de peticiones no paguen el coste de una red intercontinental.
Realidades operativas
Los beneficios técnicos solo importan si las operaciones siguen siendo manejables. Para SaaS global planifica:
- Cambios de esquema online que no bloqueen tablas a través de regiones.
- Migraciones de inquilinos (mover un inquilino de una región a otra con downtime mínimo).
- Monitorización y alertas para lag de replicación, hotspots, consultas lentas e incidentes a nivel regional.
Hecho bien, Distributed SQL te da una experiencia de producto única que sigue sintiéndose local—sin dividir el equipo de ingeniería en “la pila EU” y “la pila APAC”.
Caso de uso: flujos financieros y libros contables
Los sistemas financieros son donde “eventual consistency” puede transformarse en dinero perdido. Si un cliente hace un pedido, se autoriza un pago y se actualiza un saldo, esos pasos deben coincidir en una única verdad—ahora.
La consistencia fuerte importa porque evita que dos regiones (o servicios) tomen cada uno una decisión “razonable” que resulte en un libro contable incorrecto.
Por qué la consistencia fuerte es no negociable
En un flujo típico—crear pedido → reservar fondos → capturar pago → actualizar saldo/libro—quieres garantías como:
- Un pedido no puede marcarse como “pagado” si la captura de pago no ocurrió.
- Un saldo no puede volverse negativo porque dos transacciones compitieron.
- Un reembolso no puede aplicarse dos veces porque dos workers reintentaron el mismo job.
Distributed SQL encaja aquí porque te da transacciones ACID y restricciones a través de nodos (y a menudo regiones), de modo que las invariantes del libro se mantienen incluso durante fallos.
Idempotencia y patrones “no cobrar doble”
La mayoría de integraciones de pago son propensas a reintentos: timeouts, reenvíos de webhooks y reprocesado de jobs son normales. La base de datos debe ayudarte a hacer reintentos seguros.
Un enfoque práctico es combinar claves de idempotencia a nivel aplicación con unicidad impuesta por la base de datos:
- Almacena una
idempotency_key por cliente/intento de pago.
- Añade una restricción única en
(account_id, idempotency_key).
- Envuelve “crear registro de pago + aplicar entradas de ledger” en una sola transacción.
De ese modo, el segundo intento se convierte en un no-op inocuo en lugar de un doble cargo.
Manejar picos sin romper la corrección
Eventos de ventas y nóminas pueden generar ráfagas de escrituras (autorizaciones, capturas, transferencias). Con Distributed SQL puedes escalar añadiendo nodos para aumentar el throughput de escrituras manteniendo el mismo modelo de consistencia.
La clave es planificar para hot keys (p. ej., una cuenta de comerciante que recibe todo el tráfico) y usar patrones de esquema que distribuyan la carga.
Cumplimiento, auditorías y retención
Los flujos financieros suelen requerir trazabilidad inmutable, auditabilidad (quién/qué/cuándo) y políticas de retención predecibles. Incluso sin nombrar regulaciones específicas, asume que necesitarás: entradas de ledger append-only, registros con timestamp, control de acceso y reglas de retención/archivado que no comprometan la auditabilidad.
Caso de uso: inventario, reservas y bookings
Mantén el control de tu stack
Mantén el código fuente para poder continuar en tu repositorio cuando el prototipo esté listo.
Inventario y reservas parecen sencillos hasta que tienes múltiples regiones sirviendo el mismo recurso escaso: el último asiento, un lanzamiento limitado o una habitación de hotel para una noche específica.
Lo difícil no es leer la disponibilidad—es evitar que dos personas reclamen el mismo artículo al mismo tiempo.
De dónde vienen los conflictos
En una configuración multirregión sin consistencia fuerte, cada región puede creer temporalmente que tiene inventario disponible basándose en datos ligeramente desactualizados. Si dos usuarios hacen checkout en regiones distintas durante esa ventana, ambos pueden aceptarse localmente y luego entrar en conflicto durante la reconciliación.
Así ocurre la sobreventa cross-region: no porque el sistema “esté mal”, sino porque permitió verdades divergentes por un momento.
Distributed SQL suele elegirse aquí porque puede imponer un resultado autoritativo único para asignaciones de escritura—así el “último asiento” realmente queda asignado una sola vez, aunque las peticiones lleguen desde diferentes continentes.
Ejemplos concretos
- Reserva de asiento: dos usuarios hacen clic en el mismo asiento. Con consistencia fuerte, solo una transacción confirma; la otra falla inmediatamente y la UI puede pedir una actualización.
- Lanzamientos limitados: 500 unidades salen a la venta y miles intentan checkout. Quieres decremento y asignación atómica, no un “mejor esfuerzo” con reembolsos posteriores.
- Reservas hotel: la unidad de inventario no es solo la habitación, sino la noche de habitación. Doble reserva de un rango de fechas es costosa y difícil de deshacer.
Patrones comunes que funcionan bien con Distributed SQL
Hold + confirm: coloca una retención temporal (registro de reserva) en una transacción, luego confirma el pago en un segundo paso.
Expiraciones: las retenciones deben expirar automáticamente (p. ej., 10 minutos) para evitar que el inventario quede bloqueado si un usuario abandona el checkout.
Outbox transaccional: cuando una reserva se confirma, escribe una fila “evento a enviar” en la misma transacción y luego entregala de forma asíncrona (email, fulfillment, analytics o un bus de mensajes)—sin arriesgar un gap de “reservado pero no se envió confirmación”.
La conclusión: si tu negocio no tolera la doble asignación entre regiones, las garantías transaccionales fuertes dejan de ser una cuestión técnica y pasan a ser una característica de producto.
Caso de uso: alta disponibilidad y recuperación ante desastres
La alta disponibilidad (HA) encaja bien con Distributed SQL cuando el downtime es costoso, las caídas impredecibles son inaceptables y necesitas que el mantenimiento sea rutinario.
El objetivo no es “nunca fallar”—es cumplir SLOs claros (por ejemplo, 99.9% o 99.99% uptime) incluso cuando nodos mueren, zonas quedan fuera o aplicas upgrades.
“Always-on” en la práctica: SLOs, mantenimiento, fallos
Empieza por traducir “always-on” en expectativas medibles: tiempo máximo mensual de caída, RTO y RPO.
Los sistemas Distributed SQL pueden seguir sirviendo lecturas/escrituras durante muchos fallos comunes, pero solo si tu topología coincide con tu SLO y tu aplicación maneja errores transitorios (reintentos, idempotencia) limpiamente.
El mantenimiento planificado también importa. Las actualizaciones rolling y el reemplazo de instancias son más sencillos cuando la base de datos puede mover liderazgo/ réplicas lejos de nodos impactados sin dejar offline todo el clúster.
Redundancia multi-zona vs multi-región
Despliegues multi-zona te protegen de la caída de una sola AZ/zone y de muchas fallas de hardware, usualmente con menor latencia y coste. A menudo son suficientes si el cumplimiento y la base de usuarios están mayoritariamente en una región.
Despliegues multi-región te protegen de la caída completa de una región y soportan failover regional. El tradeoff es mayor latencia de escritura para transacciones fuertemente consistentes que abarcan regiones, además de planificación de capacidad más compleja.
Expectativas de failover (y pruebas con game days)
No asumas que el failover es instantáneo o invisible. Define qué significa “failover” para tu servicio: ¿picos breves de errores? ¿periodos de solo lectura? ¿unos segundos de latencia elevada?
Haz “game days” para probarlo:
- Mata un nodo, luego una zona; verifica tus dashboards SLO y presupuestos de error.
- Simula particiones de red y verifica el comportamiento de líderes/ réplicas.
- Practica evacuación de región y mide el RTO real.
La replicación no es copia de seguridad
Incluso con replicación síncrona, mantén backups y ensaya restauración. Los backups protegen contra errores humanos (migraciones malas, borrados accidentales), bugs de aplicación y corrupción que pueda replicarse.
Valida la recuperación a un punto en el tiempo (si está disponible), la velocidad de restauración y la capacidad de recuperar a un entorno limpio sin tocar producción.
Caso de uso: residencia de datos y arquitecturas impulsadas por cumplimiento
Los requisitos de residencia aparecen cuando regulaciones, contratos o políticas internas dicen que ciertos registros deben almacenarse (y a veces procesarse) dentro de un país o región específica.
Esto puede aplicar a datos personales, información sanitaria, datos de pago, cargas gubernamentales o datasets “propiedad del cliente” donde el contrato dicta dónde deben residir sus datos.
Distributed SQL se considera aquí porque puede mantener una sola base lógica mientras coloca físicamente datos en regiones distintas—sin obligarte a ejecutar una pila de aplicación por geografía.
Por qué las reglas de residencia cambian el diseño de la base de datos
Si un regulador o cliente exige “los datos se quedan en la región”, no basta con réplicas cercanas de baja latencia. Puede que necesites garantizar que:
- La copia primaria (o todas las copias) de datos específicos se almacenen solo en regiones aprobadas
- Backups y snapshots sigan las mismas reglas
- Operadores y servicios fuera de la región no puedan acceder a los datos en bruto
Esto empuja a los equipos hacia arquitecturas donde la localización es una preocupación de primera clase, no un detalle posterior.
Colocación por cliente y controles de acceso (a alto nivel)
Un patrón común en SaaS es la colocación por tenant. Por ejemplo: filas/particiones de clientes EU ancladas a regiones EU, US a US.
A alto nivel suele combinarse:
- Reglas de colocación de datos (dónde puede residir un tenant)
- Controles de identidad y acceso (qué servicios y personas pueden leerlo)
- Cifrado y gestión de claves (a veces con claves ligadas a una región)
El objetivo es dificultar que se viole la residencia por accidente mediante acceso operativo, restauraciones de backup o replicación cross-region.
Los requisitos legales varían—consulta a legal
Las obligaciones de residencia y cumplimiento difieren mucho por país, industria y contrato. Además cambian con el tiempo.
Trata la topología de base de datos como parte de tu programa de cumplimiento y valida suposiciones con asesoría legal calificada (y, cuando corresponda, con tus auditores).
Cómo la topología multirregión afecta reporting y analítica
Las topologías compatibles con residencia pueden complicar la visión “global” del negocio. Si los datos de clientes se mantienen intencionadamente en regiones distintas, la analítica e informes pueden:
- Necesitar pipelines de reporting regionales (el cómputo se ejecuta donde están los datos)
- Usar exportaciones agregadas (solo las métricas permitidas salen de la región)
- Aceptar mayor latencia para dashboards cross-region, porque las consultas globales pueden abarcar regiones o depender de datasets replicados/derivados
En la práctica, muchos equipos separan cargas operacionales (consistencia fuerte, conciencia de residencia) de analítica (warehouses regionales o datasets agregados gobernados) para mantener el cumplimiento sin ralentizar el reporting diario.
Planificación de coste y rendimiento para Distributed SQL
Crea un PoC rápido
Levanta una app inicial con React + Go y convierte tu PoC de SQL distribuido en un producto funcional.
Distributed SQL puede salvarte de outages dolorosos y limitaciones regionales, pero rara vez ahorra dinero por defecto. Planear de antemano ayuda a evitar pagar por un “seguro” que no necesitas.
Los principales drivers de coste
La mayoría de presupuestos se dividen en cuatro partidas:
- Nodos (compute): pagas por mantener múltiples réplicas online—a menudo 3+ por región—más capacidad extra para failover. Los diseños multirregión requieren más margen que Postgres en una sola región.
- Almacenamiento: la replicación multiplica el tamaño de datos. 2 TB con tres réplicas son ~6 TB antes de backups, índices y overhead.
- Tráfico inter-región: la replicación cross-region, las lecturas y el tráfico de clientes pueden ser una partida material. Suele ser la primera sorpresa.
- Tiempo de operaciones: incluso las ofertas gestionadas requieren trabajo: tuning de esquema y consultas, respuesta a incidentes, planificación de capacidad, pruebas de upgrades y gobernanza (especialmente en residencia/cumplimiento).
Estimando el impacto de latencia en recorridos reales de usuario
Los sistemas Distributed SQL añaden coordinación—especialmente para escrituras fuertemente consistentes que deben confirmarse por quórum.
Una forma práctica de estimar impacto:
- Elige 2–3 recorridos clave (checkout, reserva, “guardar cambios”).
- Cuenta cuántos writes y pasos de read-after-write hay en la ruta crítica.
- Para cada paso, asume un viaje cross-region donde se requiere coordinación. Si el RTT cross-region es 80–120 ms, dos pasos de escritura secuenciales pueden añadir 160–240 ms al tiempo de la aplicación.
Esto no significa “no lo hagas”, pero sí que debes diseñar los recorridos para reducir escrituras secuenciales (agrupar, reintentos idempotentes, menos transacciones charlatanas).
Complejidad vs alternativas más simples
Si tus usuarios están mayoritariamente en una región, un Postgres en una sola región con réplicas de lectura, buenos backups y un plan de failover probado puede ser más barato y sencillo—y rápido.
Distributed SQL justifica su coste cuando realmente necesitas escrituras multirregión, RPO/RTO estrictos o colocación por residencia.
Un framing simple de ROI
Trata el gasto como un intercambio:
- Riesgo evitado: menos outages que impactan ingresos, menos pérdida de datos, menos fines de semana de incidentes globales.
- Ingresos protegidos: mayor conversión por menor latencia en usuarios regionales, mejor postura enterprise (SLA, cumplimiento).
- Gasto: clúster base + overhead de replicación + tráfico + tiempo de ingeniería.
Si la pérdida evitada (tiempo de inactividad + churn + riesgo de cumplimiento) supera la prima recurrente, el diseño multirregión está justificado. Si no, empieza más simple—y mantén una ruta clara para evolucionar después.
Lista de adopción y próximos pasos
Adoptar distributed SQL es menos “levantar y mover” una base de datos y más probar que tu carga específica se comporta bien cuando los datos y el consenso se reparten entre nodos (y posiblemente regiones). Un plan ligero ayuda a evitar sorpresas.
Prueba de concepto (PoC) enfocada
Elige una carga que represente un dolor real: p. ej., checkout/reserva, aprovisionamiento de cuenta o posting en ledger.
Define métricas de éxito por adelantado:
- Correctitud: sin doble reservas, sin updates perdidos, comportamiento transaccional predecible
- SLO de latencia: p50/p95 para las 3 consultas principales (incluye objetivos cross-region si procede)
- Throughput: QPS sostenida en pico + margen de seguridad (a menudo 2–3×)
- Resiliencia: comportamiento durante pérdida de nodo y (si aplica) pérdida de región
- Esfuerzo operativo: tiempo para detectar, diagnosticar y recuperarse de un incidente simulado
Si quieres moverte más rápido en la fase PoC, ayuda construir una pequeña app “realista” (API + UI) en lugar de solo benchmarks sintéticos. Por ejemplo, equipos usan Koder.ai para levantar una app React + Go + PostgreSQL base vía chat y luego cambiar la capa de base de datos a CockroachDB/YugabyteDB (o conectar a Spanner) para probar patrones de transacción, reintentos y fallos de extremo a extremo. El objetivo no es la stack inicial—es acortar el ciclo de “idea” a “carga que puedes medir”.
Checklist de diseño (los temas que muerden más tarde)
- Esquema: elige claves primarias que distribuyan escrituras; evita claves secuenciales “hot”
- Índices: conserva solo lo necesario; entiende la amplificación de escritura por índices secundarios
- Particionado/colocación: decide claves de partición y reglas de geo/zone basadas en patrones de acceso
- Hot spots: identifica “filas celebridad” (counters globales, tablas mono-tenant) y rediseña temprano
- Migraciones: planifica cambios de esquema online y backfills; prueba caminos de rollback
Básicos operativos para tener desde el día uno
La monitorización y los runbooks importan tanto como el SQL:
- Dashboards para latencia, reintentos, contención, salud de replicación/consenso, disco y compactaciones
- Runbooks de incidente: consultas lentas, reinicio de nodos, réplicas fallando, carga desigual
- Pruebas de carga que imiten producción (mix lectura/escritura, picos, transacciones largas)
- Backups + ejercicios de restauración (incluida recuperación punto-en-tiempo si está soportada)
Próximos pasos
Empieza con un sprint PoC, luego presupuesta una revisión de readiness para producción y un corte gradual (writes duales o lecturas en sombra cuando sea posible).
Si necesitas ayuda para dimensionar costos o niveles, consulta /pricing. Para walkthroughs prácticos y patrones de migración, revisa /blog.
Si finalmente documentas los hallazgos del PoC, los tradeoffs arquitectónicos o las lecciones de migración, considera compartirlos con tu equipo (y públicamente si puedes): plataformas como Koder.ai incluso ofrecen formas de ganar créditos por crear contenido educativo o referir a otros constructores, lo que puede compensar los costes de experimentación mientras evalúas opciones.