Por qué los equipos llegan a un límite con las integraciones tradicionales
La mayoría de los productos empiezan con integraciones punto a punto simples: el Sistema A llama al Sistema B, o un pequeño script copia datos de un lugar a otro. Funciona hasta que el producto crece, los equipos se separan y el número de conexiones se multiplica. Pronto cada cambio necesita coordinación entre varios servicios, porque un pequeño campo o actualización de estado puede propagarse por una cadena de dependencias.
La velocidad suele ser lo primero que se resiente. Añadir una nueva función significa actualizar varias integraciones, redeployar varios servicios y esperar que nada más dependiera del comportamiento anterior.
Luego la depuración se vuelve dolorosa. Cuando algo se ve mal en la UI, resulta difícil responder preguntas básicas: ¿qué pasó, en qué orden y qué sistema escribió el valor que ves?
Lo que falta a menudo es una pista de auditoría. Si los datos se empujan directamente de una base a otra (o se transforman por el camino), pierdes la historia. Puedes ver el estado final, pero no la secuencia de eventos que llevó hasta allí. Las revisiones de incidentes y la atención al cliente sufren porque no puedes reproducir el pasado para confirmar qué cambió y por qué.
Aquí también aparece la discusión de “quién posee la verdad”. Un equipo dice: “el servicio de facturación es la fuente de la verdad”. Otro dice: “el servicio de pedidos lo es”. En realidad, cada sistema tiene una vista parcial, y las integraciones punto a punto convierten ese desacuerdo en fricción diaria.
Un ejemplo simple: se crea un pedido, luego se paga, luego se reembolsa. Si tres sistemas se actualizan entre sí directamente, cada uno puede terminar con una historia diferente cuando hay reintentos, timeouts o arreglos manuales.
Eso lleva a la pregunta de diseño central detrás del streaming de eventos con Kafka: ¿solo necesitas mover trabajo de un lugar a otro (una cola), o necesitas un registro compartido y duradero de lo que pasó que muchos sistemas puedan leer, rebobinar y confiar (un registro)? La respuesta cambia cómo construyes, depuras y haces crecer tu sistema.
Jay Kreps, Kafka y la idea del registro
Jay Kreps ayudó a dar forma a Kafka y, más importante, a la forma en que muchos equipos piensan sobre el movimiento de datos. El cambio útil es de mentalidad: deja de tratar los mensajes como entregas puntuales y empieza a ver la actividad del sistema como un registro.
La idea central es simple. Modela los cambios importantes como un flujo de hechos inmutables:
- Se creó un pedido.
- Se autorizó un pago.
- Un usuario cambió su correo.
Cada evento es un hecho que no debería editarse después. Si algo cambia más tarde, añades un nuevo evento que establece la nueva verdad. Con el tiempo, esos hechos forman un registro: un historial de append-only de tu sistema.
Aquí es donde el streaming de eventos con Kafka difiere de muchas configuraciones de mensajería básicas. Muchas colas se construyen alrededor de “envíalo, procésalo, elimínalo”. Eso está bien cuando el trabajo es puramente un traspaso. La visión de registro dice: “mantén la historia para que muchos consumidores la usen, ahora y después”.
Reproducir la historia es el superpoder práctico.
Si un informe está mal, puedes volver a ejecutar la misma historia de eventos a través de un job de analytics corregido y ver dónde cambiaron los números. Si un bug provocó correos erróneos, puedes reproducir eventos en un entorno de prueba y recrear la línea de tiempo exacta. Si una nueva función necesita datos pasados, puedes construir un nuevo consumidor que empiece desde el inicio y se ponga al día a su propio ritmo.
Aquí hay un ejemplo concreto. Imagina que añades controles de fraude después de haber procesado meses de pagos. Con un registro de eventos de pagos y cuentas, puedes reproducir el pasado para entrenar o calibrar reglas con secuencias reales, calcular puntajes de riesgo para transacciones antiguas y rellenar eventos “fraud_review_requested” sin reescribir tu base de datos.
Fíjate en lo que esto te obliga a hacer. Un enfoque basado en registro te empuja a nombrar eventos claramente, mantenerlos estables y aceptar que múltiples equipos y servicios dependerán de ellos. También obliga preguntas útiles: ¿Cuál es la fuente de la verdad? ¿Qué significa este evento a largo plazo? ¿Qué hacemos cuando cometimos un error?
El valor no es la personalidad. Es darse cuenta de que un registro compartido puede convertirse en la memoria de tu sistema, y la memoria es lo que permite que los sistemas crezcan sin romperse cada vez que añades un nuevo consumidor.
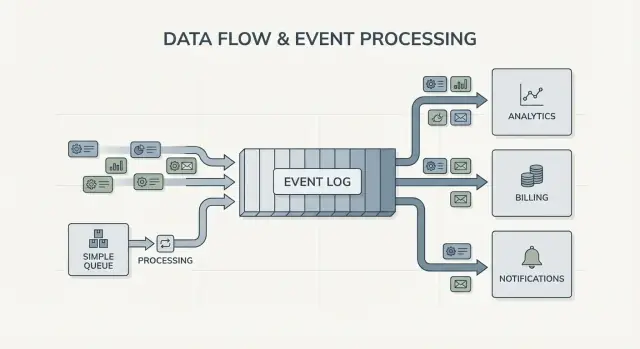
Cola vs registro: el modelo mental más simple
Una cola de mensajes es como una fila de tareas para tu software. Los productores colocan trabajo en la fila, los consumidores toman el siguiente ítem, hacen el trabajo y el ítem desaparece. El sistema se centra en que cada tarea se atienda una vez, lo antes posible.
Un registro es distinto. Es un registro ordenado de hechos que ocurrieron, guardado en una secuencia durable. Los consumidores no “se llevan” los eventos. Los leen a su propio ritmo y pueden volver a leerlos después. En el streaming de eventos con Kafka, ese registro es la idea central.
Una forma práctica de recordar la diferencia:
- Cola = trabajo por hacer. Cuando un worker confirma, desaparece.
- Registro = historial de lo que pasó. Los eventos permanecen durante un periodo de retención.
La retención cambia el diseño. Con una cola, si más tarde necesitas una función que dependa de mensajes antiguos (analytics, controles de fraude, replays tras un bug), a menudo tienes que añadir una base de datos separada o empezar a capturar copias adicionales en otro sitio. Con un registro, el replay es normal: puedes reconstruir una vista derivada leyendo desde el principio (o desde un checkpoint conocido).
El fan-out es otra gran diferencia. Imagina que un servicio de checkout emite OrderPlaced. Con una cola, normalmente eliges un grupo de workers para procesarlo o duplicas trabajo en múltiples colas. Con un registro, facturación, correo, inventario, indexado de búsqueda y analytics pueden leer el mismo flujo de eventos de forma independiente. Cada equipo puede avanzar a su propio ritmo y añadir un nuevo consumidor no requiere cambiar al productor.
Así que el modelo mental es directo: usa una cola cuando mueves tareas; usa un registro cuando registras eventos que muchas partes de la empresa pueden querer leer, ahora o en el futuro.
Qué cambia el streaming de eventos en el diseño del sistema
El streaming de eventos cambia la pregunta por defecto. En lugar de preguntar “¿a quién le envío este mensaje?”, empiezas por registrar “¿qué acaba de pasar?” Suena pequeño, pero cambia cómo modelas tu sistema.
Publicas hechos como OrderPlaced o PaymentFailed, y otras partes del sistema deciden si, cuándo y cómo reaccionan.
Con el streaming de eventos con Kafka, los productores dejan de necesitar una lista de integraciones directas. Un servicio de checkout puede publicar un evento y no tiene que saber si analytics, correo, controles de fraude o un futuro servicio de recomendaciones lo usarán. Pueden aparecer consumidores nuevos más tarde, los antiguos pueden pausar y el productor se comporta igual.
Esto también cambia cómo te recuperas de errores. En un mundo solo de mensajes, cuando un consumidor se pierde algo o tiene un bug, los datos suelen “desaparecer” a menos que construyeras backups personalizados. Con un registro, puedes corregir el código y reproducir la historia para reconstruir el estado correcto. Eso suele ser mejor que edits manuales en la base de datos o scripts puntuales que nadie confía.
En la práctica, el cambio se manifiesta en algunas formas fiables: tratas eventos como un registro durable, añades funciones suscribiéndote en vez de modificar productores, puedes reconstruir modelos de lectura (índices de búsqueda, dashboards) desde cero y obtienes líneas de tiempo más claras de lo que pasó entre servicios.
La observabilidad mejora porque el registro de eventos se convierte en una referencia compartida. Cuando algo va mal, puedes seguir una secuencia de negocio: pedido creado, inventario reservado, pago reintentado, envío programado. Esa línea de tiempo suele ser más fácil de entender que logs de aplicación dispersos porque se centra en hechos de negocio.
Un ejemplo concreto: si un bug en un descuento ajustó mal los precios durante dos horas, puedes desplegar un arreglo y reproducir los eventos afectados para recalcular totales, actualizar facturas y refrescar analytics. Estás corrigiendo resultados re-derivando datos, no adivinando qué tablas parchear a mano.
Cuándo una cola simple es suficiente
Una cola simple es la herramienta adecuada cuando mueves trabajo, no cuando construyes un registro a largo plazo. El objetivo es pasar una tarea a un worker, ejecutarla y luego olvidarla. Si nadie necesita reproducir el pasado, inspeccionar eventos antiguos o añadir consumidores nuevos más tarde, una cola mantiene las cosas más simples.
Las colas brillan para trabajos en segundo plano: enviar correos de bienvenida, redimensionar imágenes tras una subida, generar un informe nocturno o llamar a una API externa lenta. En esos casos el mensaje es solo un ticket de trabajo. Cuando un worker termina, el ticket ya hizo su trabajo.
Una cola también encaja con el modelo de propiedad habitual: un grupo de consumidores es responsable de hacer el trabajo y no se espera que otros servicios lean ese mismo mensaje de forma independiente.
Una cola suele ser suficiente cuando la mayoría de estas condiciones se cumplen:
- Los datos tienen valor de corta duración.
- Un equipo o servicio posee el trabajo de extremo a extremo.
- Las relecturas y retenciones largas no son requisitos.
- Depurar no depende de re-ejecutar la historia.
Ejemplo: un producto permite subir fotos de usuario. La app escribe una tarea “resize image” en una cola. El Worker A la toma, crea miniaturas, las almacena y marca la tarea como hecha. Si la tarea corre dos veces, la salida es la misma (idempotente), así que una entrega al menos-una-vez está bien. Ningún otro servicio necesita leer esa tarea más tarde.
Si tus necesidades empiezan a inclinarse hacia hechos compartidos (muchos consumidores), replay, auditoría o “¿qué creía el sistema la semana pasada?”, ahí es donde el streaming de eventos con Kafka y un enfoque basado en registro empiezan a resultar rentables.
Cuándo compensa un enfoque basado en registro
Un sistema basado en registro compensa cuando los eventos dejan de ser mensajes puntuales y pasan a ser historia compartida. En lugar de “envíalo y olvídalo”, mantienes un registro ordenado que muchos equipos pueden leer, ahora o más adelante, a su propio ritmo.
La señal más clara son múltiples consumidores. Un evento como OrderPlaced puede alimentar facturación, correo, controles de fraude, indexado de búsqueda y analytics. Con un registro, cada consumidor lee la misma secuencia independientemente. No tienes que construir una tubería de fan-out personalizada ni coordinar quién recibe el mensaje primero.
Otra ventaja es poder responder “¿qué sabíamos entonces?”. Si un cliente disputa un cargo o una recomendación falló, un historial append-only hace posible reproducir los hechos tal como llegaron. Esa pista de auditoría es difícil de añadir a una cola simple después.
También obtienes una forma práctica de añadir funciones sin reescribir las antiguas. Si añades una nueva página de “estado de envío” meses después, un servicio nuevo puede suscribirse y rellenar su estado desde la historia existente, en lugar de pedir exportaciones a otros sistemas.
Un enfoque basado en registro suele valer la pena cuando reconoces una o más de estas necesidades:
- Los mismos eventos deben alimentar varios sistemas (analytics, búsqueda, facturación, herramientas de soporte).
- Necesitas replay, auditoría o investigaciones basadas en hechos pasados.
- Servicios nuevos deben hacer backfill desde la historia sin jobs puntuales.
- El orden importa por entidad (por pedido, por usuario).
- Los formatos de evento evolucionarán y necesitas una manera controlada de manejar versionado.
Un patrón común es un producto que empieza con pedidos y correos. Más tarde, finanzas quiere reportes de ingresos, producto quiere funnels y ops quiere un dashboard en tiempo real. Si cada nueva necesidad te obliga a copiar datos por una nueva tubería, los costes aparecen rápido. Un registro de eventos compartido permite que los equipos construyan sobre la misma fuente de verdad, incluso cuando el sistema crece y las formas de evento cambian.
Cómo decidir, paso a paso
Elegir entre una cola simple y un enfoque basado en registros es más fácil si lo tratas como una decisión de producto. Empieza por lo que necesitas que sea verdad dentro de un año, no solo por lo que funciona esta semana.
Un 5 pasos práctico para decidir
-
Mapea los publicadores y lectores. Anota quién crea eventos y quién los lee hoy, y añade consumidores probables futuros (analytics, indexado de búsqueda, controles de fraude, notificaciones). Si esperas que muchos equipos lean los mismos eventos de forma independiente, un registro empieza a tener sentido.
-
Pregunta si necesitarás volver a leer la historia. Sé específico sobre por qué: replay tras un bug, backfills o consumidores que leen a velocidades distintas. Las colas son geniales para pasar trabajo una vez. Los registros son mejores cuando quieres un historial que puedas reproducir.
-
Define qué significa “hecho”. Para algunos flujos, hecho significa “el job se ejecutó” (enviar un correo, redimensionar una imagen). Para otros, hecho significa “el evento es un hecho duradero” (se realizó un pedido, se autorizó un pago). Los hechos duraderos te empujan hacia un registro.
-
Elige expectativas de entrega y decide cómo manejarás duplicados. La entrega al menos-una-vez es común, lo que significa que pueden ocurrir duplicados. Si un duplicado puede hacer daño (cobrar dos veces una tarjeta), planifica idempotencia: almacena un ID de evento procesado, usa constraints únicos o haz actualizaciones seguras para repetir.
-
Empieza con una sola capa delgada. Escoge un flujo de eventos fácil de razonar y crece desde ahí. Si optas por streaming con Kafka, mantén el primer topic enfocado, nombra eventos claramente y evita mezclar tipos de evento no relacionados.
Un ejemplo concreto: si OrderPlaced más adelante alimentará envío, facturación, soporte y analytics, un registro permite a cada equipo leer a su propio ritmo y reproducir errores. Si solo necesitas un worker en segundo plano para enviar un recibo, una cola simple suele ser suficiente.
Ejemplo: eventos de pedido en un producto en crecimiento
Imagina una pequeña tienda online. Al principio solo necesita tomar pedidos, cobrar una tarjeta y crear una solicitud de envío. La versión más sencilla es un job en segundo plano que corre tras el checkout: “procesar pedido”. Habla con la API de pagos, actualiza la fila de pedidos en la base de datos y luego llama al servicio de envíos.
Ese estilo de cola funciona bien cuando hay un flujo claro, solo un consumidor (el worker) y los reintentos y dead letters cubren la mayoría de fallos.
Empieza a doler cuando la tienda crece. Soporte quiere actualizaciones automáticas de “¿dónde está mi pedido?”. Finanzas quiere números diarios de ingresos. Producto quiere correos al cliente. Debe ocurrir una verificación de fraude antes de enviar. Con un único job “procesar pedido”, terminas editando ese worker una y otra vez, añadiendo ramas y arriesgando nuevos bugs en el flujo principal.
Con un enfoque basado en registro, el checkout produce pequeños hechos como eventos y cada equipo puede construir sobre ellos. Eventos típicos podrían ser:
OrderPlacedPaymentConfirmedItemShippedRefundIssued
El cambio clave es la propiedad. El servicio de checkout posee OrderPlaced. El servicio de pagos posee PaymentConfirmed. Envíos posee ItemShipped. Más tarde, pueden aparecer consumidores nuevos sin cambiar al productor: un servicio de fraude lee OrderPlaced y PaymentConfirmed para puntuar riesgo, un servicio de correo envía recibos, analytics construye funnels y herramientas de soporte mantienen una línea de tiempo de lo ocurrido.
Aquí es donde el streaming de eventos con Kafka resulta útil: el registro conserva el historial, de modo que los consumidores nuevos pueden rebobinar y ponerse al día desde el principio (o desde un punto conocido) en lugar de pedir a cada equipo upstream que agregue otro webhook.
El registro no reemplaza tu base de datos. Aún necesitas una base para el estado actual: el último estado del pedido, el registro del cliente, los conteos de inventario y reglas transaccionales (como “no enviar a menos que el pago esté confirmado”). Piensa en el registro como el registro de cambios y en la base de datos como el lugar para consultar “qué es verdadero ahora”.
Errores comunes y trampas
El streaming de eventos puede hacer que los sistemas parezcan más limpios, pero algunos errores comunes pueden borrar los beneficios rápidamente. La mayoría vienen de tratar el registro de eventos como un control remoto en lugar de un registro.
Una trampa frecuente es escribir eventos como comandos, por ejemplo “SendWelcomeEmail” o “ChargeCardNow”. Eso hace que los consumidores estén fuertemente acoplados a tu intención. Los eventos funcionan mejor como hechos: “UserSignedUp” o “PaymentAuthorized”. Los hechos envejecen bien. Los equipos nuevos pueden reutilizarlos sin adivinar qué quisiste decir.
Duplicados y reintentos son la siguiente gran fuente de dolor. En sistemas reales, los productores reintentan y los consumidores reprocesan. Si no lo planificas, obtienes cargos dobles, correos duplicados y tickets de soporte enfadados. La solución no es exótica, pero debe ser deliberada: handlers idempotentes, IDs de evento estables y reglas de negocio que detecten “ya aplicado”.
Errores comunes:
- Usar eventos estilo comando que indican qué hacer en lugar de registrar lo que pasó.
- Construir consumidores que se rompen si ven el mismo evento dos veces.
- Fragmentar streams demasiado pronto, de modo que un único flujo de negocio queda repartido en demasiados topics.
- Ignorar reglas de esquema hasta que un pequeño cambio rompe consumidores antiguos.
- Tratar el streaming como sustituto de un buen diseño de base de datos.
Esquema y versionado merecen atención especial. Aunque empieces con JSON, necesitas un contrato claro: campos requeridos, campos opcionales y cómo se despliegan los cambios. Un pequeño cambio como renombrar un campo puede romper silenciosamente analytics, facturación o apps móviles que actualizan más despacio.
Otra trampa es sobre-fragmentar. Los equipos a veces crean un nuevo stream por cada feature. Un mes después, nadie puede responder “¿cuál es el estado actual de un pedido?” porque la historia está repartida por demasiados sitios.
El streaming de eventos no elimina la necesidad de modelos de datos sólidos. Aún necesitas una base de datos que represente la verdad actual. El registro es historia, no toda tu aplicación.
Lista rápida y siguientes pasos
Si estás indeciso entre una cola y el streaming de eventos con Kafka, empieza con algunas comprobaciones rápidas. Te dirán si necesitas un simple traspaso entre workers o un registro que puedas reutilizar durante años.
Comprobaciones rápidas
- ¿Necesitas replay (para backfills, arreglar bugs o nuevas funciones) y hasta qué punto en el pasado?
- ¿Más de un consumidor necesitará los mismos eventos ahora o pronto (analytics, búsqueda, correos, fraude, facturación)?
- ¿Necesitas retención para que los equipos puedan releer la historia sin pedir al productor que reenvíe?
- ¿Qué tan importante es el orden y a qué nivel: por entidad (por pedido, por usuario) o verdaderamente global?
- ¿Pueden los consumidores ser idempotentes (seguros para reintentar el mismo evento sin cobrar dos veces, enviar doble correo o duplicar actualizaciones)?
Si respondiste “no” a replay, “un solo consumidor” y “mensajes de corta vida”, una cola básica suele ser suficiente. Si respondiste “sí” a replay, consumidores múltiples o retención larga, un enfoque basado en registro suele compensar porque convierte una secuencia de hechos en una fuente compartida sobre la que otros sistemas pueden construir.
Siguientes pasos
Convierte las respuestas en un plan pequeño y testeable.
- Lista 5–10 eventos clave en lenguaje sencillo (ejemplo: OrderPlaced, PaymentAuthorized, OrderShipped) y anota quién publica y quién consume cada uno.
- Decide la clave de ordenación (a menudo por entidad, como orderId) y documenta qué significa “orden correcto”.
- Define una regla de idempotencia por consumidor (por ejemplo: almacenar el último ID de evento procesado por pedido).
- Elige un objetivo de retención que se ajuste a tus necesidades (días para flujos tipo cola, semanas/meses cuando el replay importa).
- Ejecuta una sola capa de extremo a extremo en un sandbox antes de comprometer todo el sistema.
Si estás prototipando rápido, puedes esbozar el flujo de eventos en el modo de planificación de Koder.ai e iterar en el diseño antes de fijar nombres de eventos y reglas de reintento. Como Koder.ai soporta export de código fuente, snapshots y rollback, también es una forma práctica de probar un productor-consumidor y ajustar las formas de evento sin convertir experimentos tempranos en deuda de producción.