30 dic 2025·8 min
Triage de errores con Claude Code: un bucle práctico para correcciones rápidas
Triage de errores con Claude Code usando un bucle repetible: reproducir, minimizar, identificar causas probables, añadir una prueba de regresión y desplegar una corrección limitada con comprobaciones.
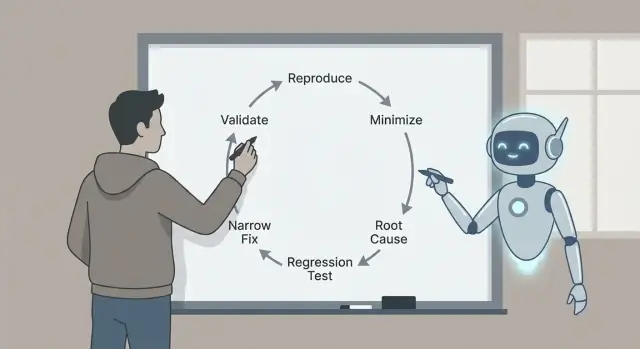
Qué es el triage de errores y por qué el bucle importa
Los errores parecen aleatorios cuando cada reporte se convierte en un misterio único. Hurgas en el código, pruebas algunas ideas y esperas que el problema desaparezca. A veces lo hace, pero no aprendes mucho y el mismo problema vuelve a aparecer con otra cara.
El triage de errores es lo contrario. Es una forma rápida de reducir la incertidumbre. El objetivo no es arreglar todo de inmediato. El objetivo es convertir una queja vaga en una afirmación clara y comprobable, y luego hacer el cambio más pequeño que demuestre que esa afirmación ya no es cierta.
Por eso el bucle importa: reproducir, minimizar, identificar causas probables con evidencia, añadir una prueba de regresión, implementar una corrección limitada y validar. Cada paso elimina un tipo específico de conjetura. Si saltas pasos, normalmente lo pagarás después con arreglos más grandes, efectos secundarios o “correcciones” que nunca lo fueron realmente.
Aquí hay un ejemplo realista. Un usuario dice: “El botón Guardar a veces no hace nada.” Sin un bucle, podrías hurgar en el código de la UI y cambiar sincronizaciones, estado o llamadas de red. Con el bucle, primero conviertes “a veces” en “siempre, bajo estas condiciones exactas”, por ejemplo: “Después de editar un título y cambiar de pestaña rápidamente, Guardar permanece deshabilitado.” Esa sola frase ya es progreso.
Claude Code puede acelerar la parte de pensamiento: convertir reportes en hipótesis precisas, sugerir dónde mirar y proponer una prueba mínima que debería fallar. Es especialmente útil para escanear código, logs y difs recientes y generar explicaciones plausibles con rapidez.
Aun así tienes que verificar lo que importa. Confirma que el bug es real en tu entorno. Prefiere evidencia (logs, trazas, pruebas fallidas) antes que una historia bien sonante. Mantén la corrección lo más pequeña posible, demuéstrala con una prueba de regresión y valídala con comprobaciones claras para no cambiar un error por otro.
La recompensa es una corrección pequeña y segura que puedes explicar, defender y evitar que regrese.
Prepara el espacio de trabajo de triage (antes de tocar el código)
Las buenas correcciones empiezan con un espacio de trabajo limpio y una única declaración de problema clara. Antes de pedir nada a Claude, elige un reporte y reescríbelo así:
“Cuando hago X, espero Y, pero obtengo Z.”
Si no puedes escribir esa frase, todavía no tienes un bug. Tienes un misterio.
Recoge lo básico desde el principio para no estar dando vueltas. Estos detalles son lo que hace que las sugerencias sean comprobables en lugar de vagas: versión de la app o commit (y si es local, staging o producción), detalles del entorno (SO, navegador/dispositivo, feature flags, región), entradas exactas (campos de formulario, payload de la API, acciones de usuario), quién lo ve (todos, un rol, una cuenta/tenant) y qué significa “esperado” (texto, estado UI, código de estado, regla de negocio).
Luego conserva la evidencia mientras esté fresca. Un solo timestamp puede ahorrarte horas. Captura logs alrededor del evento (cliente y servidor si es posible), una captura de pantalla o un corto vídeo, IDs de petición o de traza, timestamps exactos (con zona horaria) y el fragmento de datos más pequeño que dispara el problema.
Ejemplo: una app React generada por Koder.ai muestra “Pago realizado” pero la orden queda en “Pendiente”. Anota el rol del usuario, el ID exacto de la orden, el cuerpo de la respuesta de la API y las líneas de log del servidor para ese request ID. Ahora puedes pedir a Claude que se concentre en un flujo en vez de andar con generalidades.
Finalmente, fija una regla de parada. Decide qué contará como arreglado antes de empezar a codificar: una prueba específica que pase, un estado UI que cambie, un error que deje de aparecer en logs, más una corta lista de comprobaciones que ejecutarás cada vez. Esto te evita “arreglar” el síntoma y lanzar un nuevo bug.
Convierte el reporte en una pregunta precisa para Claude
Un reporte desordenado suele mezclar hechos, conjeturas y frustración. Antes de pedir ayuda, conviértelo en una pregunta nítida que Claude pueda responder con evidencia.
Empieza con un resumen de una frase que nombre la funcionalidad y la falla. Bueno: “Guardar un borrador a veces borra el título en móvil.” Malo: “Los borradores están rotos.” Esa frase será el ancla para todo el hilo de triage.
Luego separa lo que viste de lo que esperabas. Manténlo aburrido y concreto: el botón exacto que clicaste, el mensaje en pantalla, la línea de log, el timestamp, el dispositivo, el navegador, la rama, el commit. Si no tienes eso aún, dilo.
Una estructura simple que puedes pegar:
- Resumen (una frase)
- Comportamiento observado (qué pasó, incluyendo texto de error)
- Comportamiento esperado (qué debería pasar)
- Pasos de reproducción (numerados, el conjunto más pequeño que conozcas)
- Entorno (versión/app, dispositivo, SO, navegador, flags)
Si faltan detalles, pídelos como preguntas sí/no para que la gente responda rápido: ¿Ocurre en una cuenta nueva? ¿Solo en móvil? ¿Solo después de un refresh? ¿Empezó después del último release? ¿Se reproduce en incógnito?
Claude también es útil como “limpiador de reportes”. Pega el reporte original (incluyendo texto copiado de capturas, logs y chats) y pide:
“Reescribe esto como una checklist estructurada. Señala contradicciones. Enumera las 5 preguntas faltantes más importantes como sí/no. No adivies causas aún.”
Si un compañero dice “Falla aleatoriamente”, empuja hacia algo comprobable: “Falla 2/10 veces en iPhone 14, iOS 17.2, al pulsar Guardar dos veces rápido.” Ahora puedes reproducirlo a propósito.
Paso 1 - Reproducir el bug de forma fiable
Si no puedes hacer que el bug ocurra bajo demanda, cada siguiente paso es conjetura.
Empieza reproduciéndolo en el entorno más pequeño que aún muestre el problema: una build local, una rama mínima, un dataset pequeño y el menor número de servicios encendidos posible.
Escribe los pasos exactos para que otra persona los pueda seguir sin preguntar. Hazlo copy‑paste friendly: comandos, IDs y payloads de ejemplo deben incluirse exactamente como se usan.
Un template simple:
- Setup: rama/commit, flags de configuración, estado de la DB (vacía, seed, copia de producción)
- Pasos: acciones numeradas con entradas exactas
- Esperado vs real: qué pensabas que pasaría y qué pasó en su lugar
- Evidencia: texto de error, capturas, timestamps, request IDs
- Frecuencia: siempre, a veces, solo la primera vez, solo tras un refresh
La frecuencia cambia tu estrategia. Los bugs que ocurren “siempre” son ideales para iterar rápido. Los “a veces” suelen apuntar a temporizaciones, cachés, condiciones de carrera o estado oculto.
Una vez tengas notas de reproducción, pide a Claude sondas rápidas que reduzcan la incertidumbre sin reescribir la app. Buenas sondas son pequeñas: una línea de log dirigida alrededor del límite que falla (entradas, salidas, estado clave), una flag de depuración para un componente, una forma de forzar comportamiento determinista (semilla fija, tiempo fijo, un solo worker), un dataset mínimo que active el problema o una única petición/respuesta fallida para reproducir.
Ejemplo: un flujo de signup falla “a veces”. Claude puede sugerir loguear el ID de usuario generado, el resultado de normalización del email y detalles de error por constraint de unicidad, y luego reintentar el mismo payload 10 veces. Si la falla solo ocurre en la primera ejecución tras el deploy, es una pista fuerte para revisar migraciones, warmup de caché o datos seed faltantes.
Paso 2 - Minimizar a un caso de prueba pequeño y repetible
Planifica la corrección primero
Delimita hipótesis, pruebas y comprobaciones antes de tocar el código.
Una buena reproducción es útil. Una reproducción mínima es poderosa. Hace que el bug sea más rápido de entender, más fácil de depurar y menos probable de “arreglarse” por accidente.
Elimina todo lo que no sea imprescindible. Si el bug aparece después de un flujo UI largo, encuentra la ruta más corta que todavía lo desencadene. Quita pantallas opcionales, feature flags e integraciones no relacionadas hasta que el bug desaparezca (quitaste algo esencial) o se mantenga (encontraste ruido).
Luego reduce los datos. Si el bug necesita un payload grande, intenta el payload más pequeño que todavía falle. Si necesita una lista de 500 ítems, comprueba si 5 fallan, luego 2, luego 1. Quita campos uno por uno. La meta es la menor cantidad de piezas móviles que aún reproduzcan el bug.
Un método práctico es “quitar la mitad y retestear”:
- Corta los pasos a la mitad y mira si el bug sigue ocurriendo.
- Si sí, conserva la mitad restante y córtala otra vez.
- Si no, restaura la mitad quitada y corta de otra forma.
- Repite hasta que no puedas quitar nada sin perder el bug.
Ejemplo: una página de checkout se cae “a veces” al aplicar un cupón. Descubres que solo falla cuando el carrito tiene al menos un artículo con descuento, el cupón está en minúsculas y el envío está en “recogida”. Ese es tu caso mínimo: un artículo con descuento, un cupón en minúsculas y opción de recogida.
Una vez claro el caso mínimo, pide a Claude que lo convierta en un scaffold de reproducción pequeño: una prueba mínima que llame a la función fallida con las entradas más pequeñas, un script corto que golpee un endpoint con un payload reducido o una pequeña prueba UI que visite una ruta y haga una acción.
Paso 3 - Identificar causas raíz probables (con evidencia)
Cuando puedas reproducir el problema y tengas un caso pequeño, deja de adivinar. Tu objetivo es llegar a una lista corta de causas plausibles y luego probar o refutar cada una.
Una regla útil es quedarte con tres hipótesis. Si tienes más, tu caso de reproducción probablemente sigue siendo demasiado grande o tus observaciones son vagas.
Mapea síntomas a componentes
Traduce lo que ves a dónde podría estar pasando. Un síntoma en la UI no siempre significa un bug en la UI.
Ejemplo: una página React muestra un toast “Guardado”, pero más tarde el registro falta. Eso puede apuntar a (1) estado UI, (2) comportamiento del API o (3) la ruta de escritura en la base de datos.
Construye evidencia para cada hipótesis
Pide a Claude que explique modos de falla probables en lenguaje llano y luego qué prueba confirmaría cada uno. La meta es convertir un “quizá” en “comprueba esto exacto”.
Tres hipótesis comunes y la evidencia a recoger:
- Desajuste UI/estado: el cliente actualiza estado local antes de que el servidor confirme. Prueba: captura del estado antes y después de la acción y comparación con la respuesta real de la API.
- Caso límite de API: el handler devuelve 200 pero descarta trabajo silenciosamente (validación, parsing de ID, feature flag). Prueba: añade logs de request/response con IDs de correlación y verifica que el handler llegue a la llamada de escritura con las entradas esperadas.
- Problema de DB o temporización: una transacción hace rollback, hay un conflict error o un “read after write” se sirve desde una réplica/caché. Prueba: inspecciona la consulta SQL, filas afectadas y códigos de error; loguea límites de transacción y comportamiento de retry.
Mantén notas concisas: síntoma, hipótesis, evidencia, veredicto. Cuando una hipótesis encaje con los hechos, estás listo para fijar una prueba de regresión y arreglar solo lo necesario.
Paso 4 - Añadir una prueba de regresión que falle por la razón correcta
Una buena prueba de regresión es el cinturón de seguridad. Prueba que el bug existe y te dice cuándo realmente lo arreglaste.
Empieza eligiendo la prueba más pequeña que coincida con la falla real. Si el bug solo aparece cuando varias partes cooperan, una unit test puede fallar en no verlo.
Elige el nivel de prueba que corresponda
Usa una prueba unitaria cuando una sola función devuelva el valor incorrecto. Usa una de integración cuando el límite entre partes sea el problema (handler + DB, UI + API). Usa end-to-end solo si la falla depende del flujo completo.
Antes de pedir a Claude que escriba nada, reexpresa el caso minimizado como un comportamiento esperado estricto. Ejemplo: “Cuando el usuario guarda un título vacío, la API debe devolver 400 con el mensaje ‘title required’.” Así la prueba tiene un objetivo claro.
Luego pide a Claude que redacte una prueba que primero falle. Mantén el setup mínimo y copia solo los datos que disparan el bug. Nombra la prueba según lo que vive el usuario, no la función interna.
Verifica el borrador (no lo confíes ciegamente)
Haz una revisión rápida:
- Confirma que falla en el código actual por la razón prevista (no por un fixture ausente o un import mal puesto).
- Revisa que las aserciones sean específicas (código de estado exacto, mensaje, texto renderizado).
- Asegúrate de que la prueba cubra un bug, no un conjunto de comportamientos.
- Mantén el nombre centrado en el usuario, como “rechaza título vacío al guardar” en vez de “maneja validación”.
Cuando la prueba falle por la razón correcta, estás listo para implementar una corrección limitada con confianza.
Paso 5 - Implementar una corrección limitada
Corrígelo y luego exporta el código
Mantén ownership total mientras iteras rápido con desarrollo guiado por chat.
Con una reproducción pequeña y una prueba de regresión fallida, resiste la tentación de “limpiar cosas”. El objetivo es detener el bug con el menor cambio que haga pasar la prueba por la razón correcta.
Una buena corrección limitada cambia la mínima superficie posible. Si la falla está en una función, arregla esa función, no todo el módulo. Si falta una comprobación en un límite, añádela en ese límite, no a lo largo de toda la cadena de llamadas.
Si usas Claude para ayudar, pide dos opciones de arreglo y compáralas por alcance y riesgo. Ejemplo: si un formulario React se rompe cuando un campo está vacío, podrías tener:
- Opción A: añadir una protección en el handler de submit que bloquee input vacío y muestre un error.
- Opción B: refactorizar el manejo de estado para que el campo nunca quede vacío.
La Opción A suele ser la elección de triage: más pequeña, más fácil de revisar y menos propensa a romper otra cosa.
Para mantener la corrección limitada, toca los menos archivos posibles, prefiere arreglos locales sobre refactors, añade guards/validaciones donde entra el valor malo y deja el cambio de comportamiento explícito con un claro antes/después. Deja comentarios solo cuando la razón no sea obvia.
Ejemplo concreto: un endpoint Go hace panic cuando falta un query param opcional. La corrección limitada es manejar la cadena vacía en el handler (parsear con un default o devolver 400 con un mensaje claro). Evita cambiar utilidades compartidas salvo que la prueba de regresión demuestre que el bug está en ese código compartido.
Después del cambio, vuelve a ejecutar la prueba que fallaba y una o dos pruebas cercanas. Si tu arreglo implica actualizar muchas pruebas no relacionadas, es señal de que el cambio es demasiado amplio.
Paso 6 - Validar la corrección con comprobaciones claras
La validación es donde detectas problemas pequeños y fáciles de pasar por alto: una corrección que hace pasar una prueba pero rompe una ruta cercana, cambia un mensaje de error o añade una consulta lenta.
Primero, vuelve a ejecutar la prueba de regresión que añadiste. Si pasa, ejecuta las pruebas más cercanas: las del mismo archivo, del mismo módulo y cualquier cosa que cubra las mismas entradas. Los bugs suelen esconderse en helpers compartidos, parsing, comprobaciones de límite o caché, así que las fallas relevantes suelen aparecer cerca.
Luego haz una comprobación manual rápida usando los pasos del reporte original. Manténlo corto y específico: mismo entorno, mismos datos, misma secuencia de clicks o llamadas a la API. Si el reporte era vago, prueba el escenario exacto que usaste para reproducirlo.
Una lista de validación simple
- La prueba de regresión pasa, más pruebas relacionadas en la misma área.
- Los pasos manuales de reproducción ya no desencadenan el bug.
- El manejo de errores sigue teniendo sentido (mensajes, códigos, reintentos).
- Los casos límite siguen comportándose (input vacío, tamaños máximos, caracteres inusuales).
- No hay un impacto de rendimiento obvio (bucles extra, llamadas adicionales, consultas lentas).
Si quieres ayuda para mantenerte enfocado, pide a Claude un plan corto de validación basado en tu cambio y el escenario que fallaba. Comparte qué archivo cambiaste, qué comportamiento pretendías y qué podría verse afectado plausiblemente. Los mejores planes son cortos y ejecutables: 5 a 8 comprobaciones que puedas terminar en minutos, cada una con un claro pasa/falla.
Finalmente, captura lo que validaste en el PR o en las notas: qué pruebas ejecutaste, qué pasos manuales probaste y cualquier limitación (por ejemplo, “no se probó móvil”). Esto hace que la corrección sea más fácil de confiar y revisar más tarde.
Errores comunes y trampas (y cómo evitarlas)
Haz los reportes accionables
Pasa de reportes vagos a sentencias claras X‑Y‑Z y pasos reproducibles.
La forma más rápida de perder tiempo es aceptar una “corrección” antes de poder reproducir el problema bajo demanda. Si no puedes hacerlo fallar de forma fiable, no puedes saber qué mejoró realmente.
Una regla práctica: no pidas arreglos hasta que puedas describir un setup repetible (pasos exactos, entradas, entorno y qué se considera “malo”). Si el reporte es vago, pasa tus primeros minutos convirtiéndolo en una checklist que puedas ejecutar dos veces y obtener el mismo resultado.
Trampas que ralentizan
Arreglar sin un caso reproducible. Requiere un script mínimo “falla siempre” o un conjunto de pasos. Si solo falla “a veces”, captura temporización, tamaño de datos, flags y logs hasta que deje de ser aleatorio.
Minimizar demasiado pronto. Si recortas el caso antes de confirmar la reproducción original, puedes perder la señal. Primero fija la reproducción base, luego reduce un cambio a la vez.
Dejar que Claude adivine. Claude puede proponer causas probables, pero tú necesitas evidencia. Pide 2–3 hipótesis y las observaciones exactas que confirmarían o refutarían cada una (una línea de log, un breakpoint, un resultado de consulta).
Pruebas de regresión que pasan por la razón equivocada. Una prueba puede “pasar” porque nunca alcanza la ruta que falla. Asegúrate de que falle antes del arreglo y que falle con el mensaje o la aserción esperada.
Tratar síntomas en vez del desencadenante. Si añades un null check pero el problema real es “ese valor nunca debería ser null”, puedes ocultar un bug más profundo. Prefiere arreglar la condición que crea el estado malo.
Una comprobación rápida antes de darlo por hecho
Ejecuta la nueva prueba de regresión y los pasos de reproducción originales antes y después del cambio. Si un bug de checkout solo ocurre cuando se aplica un código promocional después de cambiar el envío, conserva esa secuencia completa como tu “verdad”, aunque tu prueba minimizada sea más pequeña.
Si tu validación depende de “ahora parece bien”, añade una comprobación concreta (un log, una métrica o una salida específica) para que la siguiente persona pueda verificarlo con rapidez.
Una lista rápida, plantillas de prompt y siguientes pasos
Cuando tienes prisa, un pequeño bucle repetible gana a una depuración heroica.
Checklist de triage en una página
- Reproducir: consigue una reproducción fiable y anota entradas exactas, entorno y esperado vs real.
- Minimizar: reduce a los pasos o la prueba más pequeña que sigue fallando.
- Explicar: enumera 2–3 causas raíz probables y la evidencia para cada una.
- Asegurar: añade una prueba de regresión que falle por la razón correcta.
- Corregir + validar: haz el cambio más limitado y luego ejecuta una lista corta de validación.
Escribe la decisión final en unas pocas líneas para que la próxima persona (a menudo el tú del futuro) pueda confiar en ella. Un formato útil es: “Causa raíz: X. Desencadenante: Y. Corrección: Z. Por qué es segura: W. Lo que no cambiamos: Q.”
Plantillas de prompt que puedes pegar
- “Dado este reporte y estos logs, pregúntame solo las preguntas faltantes necesarias para reproducirlo de forma fiable.”
- “Ayúdame a minimizar: propone un caso de prueba más pequeño y dime qué eliminar primero, un cambio a la vez.”
- “Ordena las causas probables y cita los archivos, funciones o condiciones que soportan cada afirmación.”
- “Escribe una prueba de regresión que falle solo por este bug. Explica por qué falla por la razón correcta.”
- “Sugiere la corrección más limitada, más una lista de validación (unit, integración y manual) que demuestre que no rompimos comportamiento cercano.”
Siguientes pasos: automatiza lo que puedas (un script de repro guardado, un comando de test estándar, una plantilla para notas de causa raíz).
Si construyes apps con Koder.ai (koder.ai), Planning Mode puede ayudarte a esbozar el cambio antes de tocar el código, y las snapshots/rollback facilitan experimentar de forma segura mientras trabajas en una reproducción complicada. Una vez validada la corrección, puedes exportar el código fuente o desplegar y alojar la app actualizada, incluso con un dominio personalizado cuando haga falta.
Preguntas frecuentes
What is bug triage, in plain terms?
El triage de errores es el hábito de convertir un reporte vago en una afirmación clara y comprobable, y luego hacer el cambio más pequeño que demuestre que esa afirmación ya no es verdad.
Se trata menos de "arreglarlo todo" y más de reducir la incertidumbre paso a paso: reproducir, minimizar, formular hipótesis basadas en evidencia, añadir una prueba de regresión, corregir de forma limitada y validar.
Why does the reproduce → minimize → test → fix loop matter so much?
Porque cada paso elimina un tipo distinto de incertidumbre.
- Reproducir: demuestra que es real y reproducible
- Minimizar: elimina ruido para que no persigas comportamientos no relacionados
- Hipótesis con evidencia: evita que cambies la cosa equivocada
- Prueba de regresión: demuestra que el bug existía y sigue corregido
- Corrección limitada + validación: reduce efectos secundarios y nuevas roturas
How do I turn a messy bug report into something actionable?
Reescríbelo como: “Cuando hago X, espero Y, pero obtengo Z.”
Después recoge solo el contexto necesario para que sea comprobable:
- versión/commit + dónde ocurre (local/staging/prod)
- entorno (dispositivo, SO, navegador, flags, región)
- entradas/acciones exactas
- quién está afectado (todos, un rol, un tenant)
- evidencia (timestamps, texto de error, request/trace IDs, logs)
What should I do first if I can’t reproduce the bug?
Empieza por confirmar que puedes reproducirlo en el entorno más pequeño que aun lo muestre (a menudo local con un dataset pequeño).
Si es “a veces”, intenta hacerlo determinista controlando variables:
- vuelve a ejecutar la misma petición 10 veces
- fija tiempo/aleatoriedad si es posible
- reduce concurrencia (un solo worker/hilo)
- añade un log dirigido en el límite que probablemente falle
No sigas hasta que puedas hacerlo fallar a voluntad, si no solo estarás adivinando.
How do I minimize a bug to a small test case?
Minimizar significa quitar todo lo que no sea necesario manteniendo el fallo.
Un método práctico es “quitar la mitad y volver a probar”:
- corta pasos/datos a la mitad
- si sigue fallando, corta otra vez
- si deja de fallar, restaura la mitad y corta de otra forma
Reduce tanto pasos (flujo de usuario) como datos (payload más pequeño, menos campos/ítems) hasta tener el desencadenante repetible más pequeño.
How can Claude Code help without turning into guesswork?
Usa a Claude Code para acelerar el análisis, no para reemplazar la verificación.
Buenos pedidos son, por ejemplo:
- “Aquí están los pasos de reproducción + logs. Enumera 2–3 hipótesis y qué evidencia confirmaría cada una.”
- “Dado este diff y este stack trace, ¿dónde están los límites de falla más probables?”
- “Redacta una prueba mínima que falle para este escenario exacto.”
Luego valida: reproduce localmente, revisa logs/trazas y confirma que cualquier prueba falle por la razón correcta.
How many root-cause hypotheses should I consider at once?
Mantenlo en tres. Más que eso suele indicar que tu caso reproducible sigue siendo demasiado grande o tus observaciones son vagas.
Para cada hipótesis escribe:
- síntoma (lo que observas)
- hipótesis (qué podría causarlo)
What makes a good regression test for a bug?
Elige el nivel de prueba más pequeño que coincida con la falla:
- Prueba unitaria: una función devuelve lo incorrecto
- Prueba de integración: límites entre partes (handler + DB, cliente + API)
- End-to-end: solo si hace falta todo el flujo
Una buena prueba de regresión:
How do I keep a fix narrow and low-risk?
Haz el cambio más pequeño que haga pasar la prueba de regresión que falla.
Reglas prácticas:
- toca el mínimo número de archivos posible
- arregla en el límite donde entra el valor malo
- prefiere una validación/barrera en vez de una refactorización durante el triage
- evita “limpieza” a menos que la prueba demuestre que es necesaria
Si tu arreglo obliga a modificar muchas pruebas no relacionadas, probablemente es demasiado amplio.
How do I validate the fix so the bug doesn’t come back?
Usa una lista corta que puedas ejecutar rápido:
- la prueba de regresión pasa
- unas pruebas vecinas pasan (módulo/entradas similares)
- los pasos manuales originales ya no desencadenan el bug
- el manejo de errores sigue teniendo sentido (mensajes, códigos)
- casos límite rápidos (input vacío, tamaño máximo, caracteres raros)
- sin regresiones de rendimiento evidentes
Anota qué ejecutaste y qué no probaste para que el resultado sea confiable.