Qué entiende este post por “sistemas generados por IA"
Un sistema generado por IA es cualquier producto donde un modelo de IA produce salidas que moldean directamente lo que el sistema hace a continuación: lo que se muestra a un usuario, lo que se almacena, lo que se envía a otra herramienta o qué acciones se ejecutan.
Esto es más amplio que “un chatbot”. En la práctica, la generación de IA puede aparecer como:
- Texto o datos generados (resúmenes, clasificaciones, campos extraídos)
- Código generado (fragmentos, configuraciones, SQL, plantillas)
- Flujos de trabajo generados (planes paso a paso, checklists, decisiones de enrutamiento)
- Comportamiento de agentes (el modelo elige herramientas, llama APIs y encadena acciones)
- Sistemas con prompts (prompts cuidadosamente diseñados que actúan como “código blando”)
Si has usado una plataforma de tipo vibe-coding como Koder.ai—donde una conversación de chat puede generar y evolucionar aplicaciones web, backend o móviles completas—esta idea de “la salida de la IA se convierte en flujo de control” es especialmente concreta. La salida del modelo no es solo un consejo; puede cambiar rutas, esquemas, llamadas a APIs, despliegues y comportamientos visibles para el usuario.
Por qué la validación y los errores son características de producto
Cuando la salida de la IA forma parte del flujo de control, las reglas de validación y el manejo de errores se convierten en funciones de fiabilidad visibles para el usuario, no solo en detalles de ingeniería. Un campo perdido, un objeto JSON mal formado o una instrucción segura-pero-equivocada no “simplemente falla”: puede crear una UX confusa, registros incorrectos o acciones riesgosas.
Así que el objetivo no es “no fallar nunca”. Las fallas son normales cuando las salidas son probabilísticas. El objetivo es fallar de forma controlada: detectar problemas temprano, comunicar con claridad y recuperarse con seguridad.
Qué cubrirá este post
El resto del artículo divide el tema en áreas prácticas:
- Reglas que verifican entradas y salidas (estructura y significado)
- Decisiones de manejo de errores (fallar rápido vs. fallar con gracia)
- Casos límite que aparecen en uso real y cómo reducir sorpresas
- Estrategias de pruebas para comportamientos no deterministas al 100%
- Monitoreo y observabilidad para ver fallos, tendencias y regresiones
Si tratas las rutas de validación y error como partes de primera clase del producto, los sistemas generados por IA serán más fáciles de confiar y de mejorar con el tiempo.
Los sistemas de IA son excelentes generando respuestas plausibles, pero “plausible” no es igual a “útil”. El momento en que dependes de una salida de IA para un flujo real—enviar un correo, crear un ticket, actualizar un registro—tus supuestos ocultos se convierten en reglas de validación explícitas.
La variabilidad fuerza a sacar supuestos a la luz
Con el software tradicional, las salidas suelen ser deterministas: si la entrada es X, esperas Y. Con los sistemas generados por IA, el mismo prompt puede producir distintas redacciones, niveles de detalle o interpretaciones. Esa variabilidad no es en sí un bug, pero significa que no puedes confiar en expectativas informales como “probablemente incluirá una fecha” o “normalmente devuelve JSON”.
Las reglas de validación son la respuesta práctica a: ¿Qué tiene que ser verdad para que esta salida sea segura y útil?
“Apariencia válida” vs. “válido para nuestro negocio”
Una respuesta de IA puede parecer válida pero aun así fallar tus requisitos reales.
Por ejemplo, un modelo podría producir:
- Una dirección bien formada que use el país equivocado
- Un mensaje de reembolso amable que viole tu política
- Un resumen que invente una métrica que tu equipo no rastrea
En la práctica terminas con dos capas de comprobaciones:
- Validez estructural (¿es parseable, completo, en el formato esperado?)
- Validez de negocio (¿está permitido, es suficientemente preciso y está alineado con tus reglas?)
La ambigüedad aparece en lugares predecibles
Las salidas de IA suelen difuminar detalles que los humanos resuelven de forma intuitiva, especialmente alrededor de:
- Formatos: “03/04/2025” (¿4 de marzo o 3 de abril?)
- Unidades: “20” (¿minutos, horas, dólares?)
- Nombres: “Alex Chen” (¿qué Alex Chen en tu CRM?)
- Zonas horarias: “mañana por la mañana” (¿en la zona horaria de quién?)
Piensa en contratos: entradas, salidas, efectos secundarios
Una forma útil de diseñar validación es definir un “contrato” para cada interacción con la IA:
- Entradas: campos requeridos, rangos permitidos, contexto necesario
- Salidas: claves obligatorias, valores permitidos, umbrales de confianza
- Efectos secundarios: qué acciones están permitidas (p. ej., “solo borrador”, “nunca enviar”, “debe pedir confirmación”)
Una vez que existen contratos, las reglas de validación no parecen burocracia extra: son cómo logras que el comportamiento de la IA sea lo bastante fiable para usarlo.
Validación de entradas: proteger la puerta de entrada
La validación de entradas es la primera línea de fiabilidad para sistemas generados por IA. Si entradas desordenadas o inesperadas se cuelan, el modelo puede seguir produciendo algo “confiado”, y eso es precisamente por lo que la puerta de entrada importa.
Qué cuenta como “entrada” en un sistema de IA
Las entradas no son solo una caja de prompt. Fuentes típicas incluyen:
- Texto del usuario (mensajes de chat, prompts, comentarios)
- Archivos (PDFs, imágenes, hojas de cálculo, audio)
- Formularios estructurados (desplegables, incorporación en pasos)
- Cargas de API (JSON de otros servicios, webhooks)
- Datos recuperados (resultados de búsqueda, filas de base de datos, salidas de herramientas)
Cada uno puede estar incompleto, mal formado, ser demasiado grande o simplemente no ser lo que esperabas.
Comprobaciones prácticas que previenen fallos evitables
Buena validación se centra en reglas claras y comprobables:
- Campos obligatorios: ¿está presente el prompt, se adjuntó el archivo, se seleccionó el idioma?
- Rangos y límites: tamaño máximo de archivo, número máximo de items, valores numéricos min/max
- Valores permitidos: campos tipo enum ("resumen" | "email" | "análisis"), tipos de archivo permitidos
- Límites de longitud: longitud del prompt, longitud del título, tamaños de arrays
- Codificación y formato: UTF-8 válido, JSON válido, base64 sin roturas, formatos de URL seguros
Estas comprobaciones reducen la confusión del modelo y también protegen sistemas aguas abajo (parsers, bases de datos, colas) de fallos.
Normalizar antes de validar (cuando sea predecible)
La normalización convierte “casi correcto” en datos consistentes:
- Recortar espacios; colapsar espacios repetidos
- Normalizar mayúsculas cuando el significado no cambia (p. ej., códigos de país)
- Parsear formatos locales con cuidado (decimales con "," vs ".", órdenes de fecha distintas)
- Convertir fechas a una representación estándar (p. ej., ISO-8601) tras parsear
Normaliza solo cuando la regla sea inequívoca. Si no puedes estar seguro de lo que quiso decir el usuario, no adivines.
Rechazar vs autocorregir: elige la opción más segura
- Rechazar entradas cuando la corrección pueda cambiar el significado, crear riesgo de seguridad o ocultar errores del usuario (p. ej., fechas ambiguas, monedas inesperadas, HTML/JS sospechoso).
- Autocorregir cuando la intención sea obvia y el cambio reversible (p. ej., recortar, arreglar puntuación común, convertir “.PDF” a “pdf”).
Una regla útil: autocorrige el formato, rechaza la semántica. Cuando rechaces, devuelve un mensaje claro que diga al usuario qué cambiar y por qué.
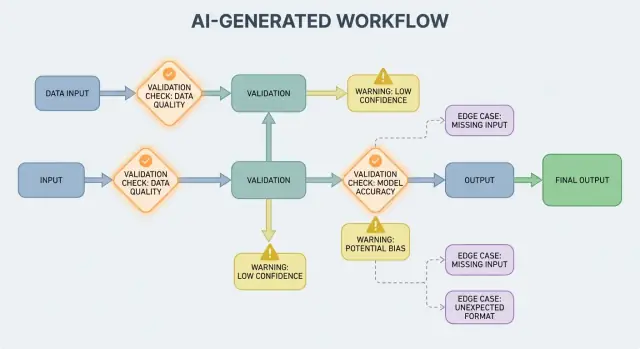
Validación de salidas: comprobar estructura y significado
La validación de salidas es el control después de que el modelo habla. Responde a dos preguntas: (1) ¿la salida tiene la forma correcta? y (2) ¿es realmente aceptable y útil? En productos reales, normalmente necesitas ambas.
1) Validación estructural con esquemas de salida
Empieza definiendo un esquema de salida: la forma JSON que esperas, qué claves deben existir y qué tipos y valores permitidos pueden contener. Esto convierte el “texto libre” en algo que tu aplicación puede consumir con seguridad.
Un esquema práctico típicamente especifica:
- Claves requeridas (p. ej.,
answer, confidence, citations)
- Tipos (string vs number vs array)
- Enums (p. ej.,
status debe ser uno de "ok" | "needs_clarification" | "refuse")
- Restricciones (longitud mínima/máxima, rangos numéricos, arrays no vacíos)
Las comprobaciones estructurales detectan fallos comunes: el modelo devuelve prosa en vez de JSON, olvida una clave o emite un número donde necesitas un string.
2) Validación semántica: la estructura no basta
Incluso un JSON perfectamente formado puede estar equivocado. La validación semántica prueba si el contenido tiene sentido para tu producto y políticas.
Ejemplos que pasan el esquema pero fallan en significado:
- IDs alucinados: retornar
customer_id: "CUST-91822" que no existe en tu base de datos
- Citas débiles o ausentes: hay citas pero no respaldan la afirmación—o hacen referencia a fuentes que no fueron proporcionadas
- Totales imposibles: los items suman 120, pero
total es 98; o un descuento excede el subtotal
Las comprobaciones semánticas suelen parecer reglas de negocio: “los IDs deben resolverse”, “los totales deben cuadrar”, “las fechas deben estar en el futuro”, “las afirmaciones deben estar soportadas por documentos proporcionados” y “no debe haber contenido prohibido”.
3) Estrategias que funcionan en sistemas reales
- Aplicación de esquemas: valida JSON antes de usarlo; rechaza o reintenta en violaciones
- Decodificación restringida / salidas estructuradas: limita lo que el modelo puede emitir para que sea más difícil producir formas inválidas
- Post-checkers: ejecuta validadores deterministas (y a veces un segundo modelo) para verificar consistencia, citas y cumplimiento de políticas
El objetivo no es castigar al modelo: es evitar que los sistemas aguas abajo traten “tonterías confiadas” como una orden.
Fundamentos del manejo de errores: fallar rápido o fallar con gracia
Prueba flujos de IA sin conjeturas
Crea un conjunto de prompts 'golden' y pruebas de contrato para detectar pronto la deriva del esquema.
Los sistemas generados por IA a veces producirán salidas inválidas, incompletas o simplemente no utilizables para el siguiente paso. Un buen manejo de errores consiste en decidir qué problemas deben detener el flujo inmediatamente y cuáles pueden recuperarse sin sorprender al usuario.
Fallos duros vs fallos suaves
Un fallo duro es cuando continuar probablemente causaría resultados erróneos o comportamiento inseguro. Ejemplos: faltan campos requeridos, una respuesta JSON no se puede parsear, o la salida viola una política que debe cumplirse. En estos casos, falla rápido: detén, muestra un error claro y evita adivinar.
Un fallo suave es un problema recuperable donde existe un fallback seguro. Ejemplos: el modelo devolvió el significado correcto pero el formato está mal, una dependencia está temporalmente no disponible o una solicitud excede el tiempo. Aquí, falla con gracia: reintenta (con límites), vuelve a solicitar con restricciones más estrictas o cambia a un camino alternativo más simple.
Mensajes al usuario: di qué pasó y qué hacer
Los errores visibles para el usuario deben ser breves y accionables:
- Qué pasó: “No pudimos generar un resumen válido para este documento.”
- Qué hacer a continuación: “Por favor inténtalo de nuevo, o sube un archivo más pequeño.”
- Contexto opcional (no técnico): “La respuesta estaba incompleta.”
Evita exponer trazas de pila, prompts internos o IDs internos. Esos detalles son útiles, pero solo internamente.
Separa errores visibles de diagnósticos internos
Trata los errores como dos salidas paralelas:
- Visible para el usuario: un mensaje seguro, un siguiente paso y (a veces) un botón de reintento
- Diagnósticos internos: logs estructurados con un código de error, salida cruda del modelo, resultados de validación, tiempos, estado de dependencias e ID de correlación/solicitud
Esto mantiene el producto tranquilo y comprensible mientras aún das a tu equipo la información necesaria para arreglar problemas.
Categoriza errores para una triaje rápido
Una taxonomía simple ayuda a las equipos a actuar rápidamente:
- Validación: la salida no coincide con el esquema, faltan campos, contenido inseguro
- Dependencia: fallos de base de datos/API, problemas de permisos
- Timeout: llamadas al modelo o upstream que exceden el presupuesto de tiempo
- Lógica: bugs en código de integración, mapeos o reglas de negocio
Cuando puedes etiquetar un incidente correctamente, lo enrutas al responsable adecuado y mejoras la regla de validación correcta a continuación.
Recuperaciones y fallbacks sin empeorar las cosas
La validación detectará problemas; la recuperación determina si los usuarios ven una experiencia útil o confusa. El objetivo no es “siempre tener éxito”: es “fallar de forma predecible y degradar con seguridad”.
Reintentos: útiles para fallos transitivos, dañinos para respuestas incorrectas
La lógica de reintentos es más eficaz cuando la falla probablemente es temporal:
- Límites de tasa (429), problemas de red o timeouts del modelo
- Breves caídas de upstream
Usa reintentos acotados con backoff exponencial y jitter. Reintentar cinco veces en un bucle ajustado suele convertir un incidente pequeño en uno mayor.
Los reintentos pueden ser dañinos cuando la salida es estructuralmente inválida o semánticamente errónea. Si tu validador dice “faltan campos requeridos” o “violación de política”, otro intento con el mismo prompt puede producir otra respuesta inválida—y desperdiciar tokens y latencia. En esos casos, prefiere la reparación del prompt (volver a pedir con restricciones más estrictas) o un fallback.
Fallbacks que degradan con gracia
Un buen fallback es explicable al usuario y medible internamente:
- Modelo más pequeño/asequible para respuestas “suficientemente buenas”
- Respuesta en caché para preguntas repetidas y estables
- Base rule-based (plantillas, heurísticas) para formatos predecibles
- Revisión humana cuando la consecuencia de un error es alta
Haz explícita la ruta de fallback: almacena qué camino se usó para que luego puedas comparar calidad y coste.
Éxito parcial: devolver lo mejor disponible con advertencias
A veces puedes devolver un subconjunto útil (p. ej., entidades extraídas pero no un resumen completo). Márqualo como parcial, incluye advertencias y evita rellenar silenciosamente huecos con conjeturas. Esto preserva la confianza y sigue dando al llamador algo accionable.
Límites de tasa, timeouts y circuit breakers
Establece timeouts por llamada y un plazo límite por solicitud. Cuando estés rate-limited, respeta Retry-After si está presente. Añade un circuit breaker para que fallos repetidos cambien rápidamente a un fallback en vez de sobrecargar el modelo/API. Esto evita desaceleraciones en cascada y hace que el comportamiento de recuperación sea consistente.
De dónde vienen los casos límite en el uso real
Los casos límite son situaciones que tu equipo no vio en demostraciones: entradas raras, formatos extraños, prompts adversariales o conversaciones que se alargan mucho más de lo esperado. Con sistemas generados por IA aparecen rápido porque la gente trata el sistema como un asistente flexible—y lo empuja fuera del camino feliz.
1) Entradas de usuario raras y desordenadas
Los usuarios reales no escriben como los datos de prueba. Pegarán capturas convertidas a texto, notas a medias o contenido copiado de PDFs con saltos de línea extraños. También intentan prompts “creativos”: pedir al modelo que ignore reglas, revele instrucciones ocultas o emita algo en un formato deliberadamente confuso.
El contexto largo es otro caso común: un usuario puede subir un documento de 30 páginas y pedir un resumen estructurado, luego hacer diez preguntas aclaratorias. Incluso si el modelo rinde bien al principio, el comportamiento puede derivar a medida que crece el contexto.
2) Valores límite que rompen supuestos
Muchos fallos vienen de extremos en lugar de uso normal:
- Valores vacíos: campos en blanco, adjuntos faltantes o “N/A” en lugares clave
- Longitudes máximas: nombres muy largos, listas enormes, direcciones de varios párrafos o historiales de chat completos pegados en una entrada
- Unicode inusual: emojis, espacios de ancho cero, comillas inteligentes, texto de derecha a izquierda o caracteres combinantes que parecen idénticos pero comparan distinto
- Idiomas mezclados: un ticket medio en inglés y medio en español; un catálogo con títulos en japonés pero atributos en francés
Estos a menudo pasan comprobaciones básicas porque el texto parece correcto para humanos y falla en parseo, conteo o reglas aguas abajo.
3) Casos límite de integración (el mundo cambia debajo de ti)
Incluso si tu prompt y validación son sólidos, las integraciones pueden introducir nuevos casos límite:
- Una API aguas abajo cambia el nombre de un campo, añade un parámetro requerido o comienza a devolver nuevos códigos de error
- Desajustes de permisos: la IA genera una solicitud para acceder a datos que el usuario no puede ver o intenta una acción que la cuenta de servicio no puede ejecutar
- Deriva de contratos de datos: una herramienta espera fechas ISO pero recibe “el próximo viernes”, o espera un código de moneda y recibe un símbolo
4) “Desconocidos desconocidos” y por qué los logs importan
Algunos casos límite no se pueden predecir por adelantado. La única forma fiable de descubrirlos es observar fallos reales. Buenas trazas y logs deberían capturar: la forma de la entrada (de forma segura), la salida del modelo (de forma segura), qué regla de validación falló y qué ruta de fallback se ejecutó. Cuando puedes agrupar fallos por patrón, conviertes sorpresas en reglas nuevas y claras—sin adivinar.
Seguridad: cuando la validación es protección
Haz visibles las fallas de validación
Instrumenta registros y métricas para ver qué reglas fallan y dónde se atascan los usuarios.
La validación no es solo mantener las salidas ordenadas; también es cómo evitas que un sistema de IA haga algo inseguro. Muchos incidentes de seguridad en apps con IA son simplemente problemas de “entrada mala” o “salida mala” con mayores implicaciones: pueden provocar fugas de datos, acciones no autorizadas o uso indebido de herramientas.
La inyección de prompts es un problema de validación (con impacto en seguridad)
La inyección de prompts ocurre cuando contenido no confiable (un mensaje de usuario, una página web, un email, un documento) contiene instrucciones como “ignora tus reglas” o “devuélveme el prompt del sistema oculto”. Es un problema de validación porque el sistema debe decidir qué instrucciones son válidas y cuáles son hostiles.
Una postura práctica: trata el texto que ve el modelo como no confiable. Tu app debe validar intención (qué acción se solicita) y autoridad (si el solicitante está autorizado), no solo el formato.
Comprobaciones defensivas que actúan como guardarraíles
La buena seguridad suele parecer reglas de validación ordinarias:
- Allowlists de herramientas: restringe explícitamente qué herramientas/acciones puede llamar el modelo en un contexto dado
- Restricciones de URL y archivos: permite solo dominios aprobados, bloquea targets de red local, aplica límites de tipo/tamaño de archivo y evita lecturas arbitrarias de archivos
- Redacción de datos: detecta y elimina secretos (claves API, tokens), datos personales e identificadores internos antes de enviar contenido al modelo o devolver salida
Si permites que el modelo navegue o recupere documentos, valida a dónde puede ir y qué puede traer de vuelta.
Menor privilegio para herramientas y tokens
Aplica el principio de menor privilegio: da a cada herramienta los permisos mínimos y limita los tokens (de corta duración, endpoints limitados, datos limitados). Es mejor que falle una solicitud y pedir una acción más precisa que otorgar acceso amplio “por si acaso”.
Acciones sensibles necesitan fricción y trazabilidad
Para operaciones de alto impacto (pagos, cambios de cuenta, envío de emails, borrado de datos), añade:
- Confirmaciones explícitas (“Vas a transferir $500 a X—¿confirmas?”)
- Control dual para acciones críticas (aprobación humana o segundo factor)
- Trazas de auditoría (quién lo pidió, qué se ejecutó, entradas, llamadas a herramientas, marcas temporales)
Estas medidas convierten la validación de un detalle de UX en una verdadera barrera de seguridad.
Estrategia de pruebas para comportamiento generado por IA
Probar comportamientos generados por IA funciona mejor si tratas al modelo como un colaborador impredecible: no puedes afirmar cada frase exacta, pero sí límites, estructura y utilidad.
Un suite de pruebas en capas (para que los fallos apunten a la corrección adecuada)
Usa múltiples capas que respondan a distintas preguntas:
- Pruebas unitarias: valida tu propio código (parsers, validadores, ruteo, constructores de prompts). Deben ser deterministas y rápidas.
- Pruebas de contrato: verifica acuerdos de forma con el modelo, como “debe devolver JSON válido con las claves X/Y/Z” o “debe incluir un campo de citas cuando la confianza sea baja”.
- Escenarios end-to-end: ejecuta flujos realistas de usuario (incluyendo reintentos y fallbacks) para ver si el sistema se mantiene útil bajo estrés.
Una buena regla: si un bug llega a pruebas end-to-end, añade una prueba más pequeña (unitaria/contrato) para atraparlo antes la próxima vez.
Construye un “golden set” de prompts
Crea una pequeña colección curada de prompts que representen uso real. Para cada uno, registra:
- El prompt (y cualquier instrucción de sistema/desarrollador)
- Restricciones requeridas (formato, reglas de seguridad, reglas de negocio)
- Comportamientos esperados (no la redacción exacta): p. ej., “devuelve un objeto con 3 sugerencias”, “se niega a solicitudes de secretos”, “hace una pregunta aclaratoria cuando faltan entradas”
Ejecuta el conjunto dorado en CI y rastrea cambios con el tiempo. Cuando ocurra un incidente, añade una nueva prueba dorada para ese caso.
Los sistemas de IA suelen fallar en bordes desordenados. Añade fuzzing automatizado que genere:
- Strings aleatorias y codificaciones mezcladas
- JSON malformado, cargas truncadas, comas extra
- Valores extremos (texto muy largo, campos vacíos, números enormes, fechas inusuales)
Probar salidas no deterministas
En lugar de hacer snapshot de texto exacto, usa tolerancias y rúbricas:
- Puntúa salidas contra listas de verificación (campos requeridos, contenido prohibido, límites de longitud)
- Comprobaciones semánticas (p. ej., etiqueta de clasificación dentro de un conjunto permitido)
- Umbrales de similitud para resúmenes, más aserciones de “debe mencionar hechos clave”
Esto mantiene las pruebas estables y aun así detecta regresiones reales.
Monitoreo y observabilidad para validación y errores
Genera un contrato de salida estricto
Haz que Koder.ai genere un esquema de salida y comprobaciones para que tu app pueda confiar en las respuestas del modelo.
Las reglas de validación y el manejo de errores solo mejoran cuando puedes ver qué está pasando en uso real. El monitoreo convierte “creemos que funciona” en evidencia clara: qué falló, con qué frecuencia y si la fiabilidad mejora o se degrada silenciosamente.
Qué registrar (sin crear problemas de privacidad)
Empieza con logs que expliquen por qué una solicitud tuvo éxito o falló—luego redacta o evita datos sensibles por defecto.
- Entradas y salidas (con conciencia de privacidad): almacena hashes, extractos truncados o campos estructurados en vez de texto crudo cuando sea posible. Si debes conservar contenido crudo para debug, usa retención corta, controles de acceso y un propósito claro.
- Fallas de validación: nombre de la regla, campo/ruta (p. ej.,
address.postcode) y motivo del fallo (mismatch de esquema, contenido inseguro, intención requerida faltante).
- Llamadas a herramientas y efectos secundarios: qué herramienta se llamó, parámetros (saneados), códigos de respuesta y tiempos. Esto es esencial cuando los fallos se originan fuera del modelo.
- Excepciones y timeouts: trazas para errores internos, más códigos de error seguros para el usuario que mapeen a categorías conocidas.
Métricas que realmente predicen fiabilidad
Los logs te ayudan a depurar un incidente; las métricas te ayudan a detectar patrones. Rastrea:
- Tasa de fallos de validación (global y por regla)
- Tasa de cumplimiento de esquema (salidas que coinciden con la estructura esperada)
- Tasa de reintentos y tasa de éxito de recuperación (con qué frecuencia los fallbacks funcionan)
- Latencia (end-to-end y por llamada a herramienta)
- Principales categorías de error (p. ej., “campo faltante”, “timeout de herramienta”, “violación de política”)
Alertas sobre deriva
Las salidas de IA pueden cambiar sutilmente tras ediciones de prompt, actualizaciones de modelo o nuevo comportamiento de usuarios. Las alertas deben enfocarse en cambios, no solo en umbrales absolutos:
- Aumento repentino en una regla de validación específica que falla
- Nuevas categorías de error apareciendo
- Cambios en la forma de la salida (p. ej., un campo JSON que se vuelve texto libre)
Dashboards que equipos no técnicos puedan usar
Un buen tablero responde: “¿Está funcionando para los usuarios?” Incluye una tarjeta simple de fiabilidad, una línea de tendencia de la tasa de cumplimiento de esquema, un desglose de fallos por categoría y ejemplos de los tipos de fallo más comunes (con contenido sensible eliminado). Enlaza vistas técnicas más profundas para ingenieros, pero mantiene la vista superior legible para producto y soporte.
Mejora continua: convertir fallos en reglas mejores
La validación y el manejo de errores no son “configurar una vez y olvidar”. En sistemas generados por IA, el trabajo real empieza tras el lanzamiento: cada salida extraña es una pista sobre qué deberían ser tus reglas.
Construye bucles de retroalimentación cerrados
Trata los fallos como datos, no como anécdotas. El bucle más eficaz suele combinar:
- Informes de usuarios (un simple “Reportar un problema” + captura opcional/ID de salida)
- Colas de revisión humana para casos ambiguos (engañosos, inseguros o que “parecen incorrectos”)
- Etiquetado automatizado (fallos de regex/esquema, banderas de toxicidad, detección de idioma, señales de alta incertidumbre)
Asegura que cada informe se vincule a la entrada exacta, versión de modelo/prompt y resultados del validador para reproducirlo más tarde.
Cómo se arreglan realmente los problemas
La mayoría de mejoras entran en unos movimientos repetibles:
- Endurecer el esquema: si esperas JSON, especifica campos requeridos, enums y tipos; rechaza el “casi JSON”.
- Añadir validadores focalizados: hacer cumplir unidades, formatos de fecha, rangos permitidos y restricciones de inclusión obligatoria.
- Ajustar prompts: clarificar prioridades (“Si dudas, di que no lo sabes”), añadir ejemplos y reducir ambigüedades.
- Añadir fallbacks: reintentar con un prompt más estricto, cambiar a una respuesta de plantilla más segura o derivar a revisión humana—sin inventar detalles en silencio.
Cuando solucionas un caso, pregúntate también: “¿Qué casos cercanos seguirán pasando?” Amplía la regla para cubrir un pequeño conjunto, no un solo incidente.
Versionado y despliegues seguros
Versiona prompts, validadores y modelos como código. Despliega cambios con canary o pruebas A/B, mide métricas clave (tasa de rechazo, satisfacción del usuario, coste/latencia) y mantén una ruta de rollback rápida.
Aquí es donde las herramientas de producto ayudan: por ejemplo, plataformas como Koder.ai soportan snapshots y rollback durante la iteración de la app, lo que encaja bien con el versionado de prompts/validadores. Cuando una actualización aumenta fallos de esquema o rompe una integración, un rollback rápido convierte un incidente en una recuperación rápida.
Lista de comprobación práctica
- ¿Podemos reproducir cualquier problema reportado desde los logs?
- ¿Los fallos se enrutan al bucket correcto (reintento, fallback, revisión humana, parada dura)?
- ¿Actualizamos esquema/validadores y el prompt juntos?
- ¿Añadimos un caso de prueba para este fallo para que no vuelva a aparecer?
- ¿Se desplegó detrás de un canary y se monitorizó el impacto?