23 sept 2025·8 min
ZSTD vs Brotli vs GZIP: elegir la compresión de la API
Compara ZSTD, Brotli y GZIP para APIs: velocidad, ratio, coste CPU y valores prácticos por defecto para payloads JSON y binarios en producción.
Compara ZSTD, Brotli y GZIP para APIs: velocidad, ratio, coste CPU y valores prácticos por defecto para payloads JSON y binarios en producción.
La compresión de respuestas de una API significa que tu servidor codifica el cuerpo de la respuesta (a menudo JSON) en un flujo de bytes más pequeño antes de enviarlo por la red. El cliente (navegador, app móvil, SDK u otro servicio) luego lo descomprime. Sobre HTTP, esto se negocia mediante encabezados como Accept-Encoding (qué soporta el cliente) y Content-Encoding (qué eligió el servidor).
La compresión te da principalmente tres cosas:
El intercambio es directo: la compresión ahorra ancho de banda pero cuesta CPU (comprimir/descomprimir) y a veces memoria (buffers). Si merece la pena depende de cuál sea tu cuello de botella.
La compresión brilla cuando las respuestas son:
Si devuelves grandes listas JSON (catálogos, resultados de búsqueda, analítica), la compresión suele ser una de las mejoras más sencillas.
La compresión suele ser un uso pobre de CPU cuando las respuestas son:
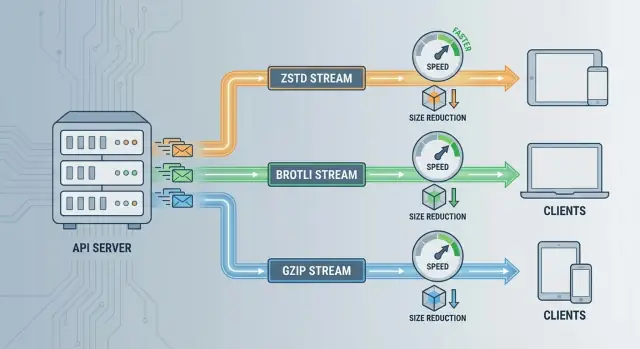
Al elegir entre ZSTD vs Brotli vs GZIP para la compresión de APIs, la decisión práctica suele reducirse a:
Todo lo demás en este artículo trata de equilibrar esos tres factores para tu API y patrones de tráfico particulares.
Los tres reducen el tamaño del payload, pero optimizan para distintas restricciones: velocidad, ratio y compatibilidad.
Velocidad de ZSTD: Excelente cuando tu API es sensible a la latencia en cola o tus servidores están limitados por CPU. Puede comprimir lo bastante rápido como para que el overhead sea despreciable frente al tiempo de red—sobre todo en respuestas JSON medianas a grandes.
Ratio de Brotli: Ideal cuando el ancho de banda es la principal limitación (clientes móviles, egreso caro, entrega vía CDN) y las respuestas son mayormente texto. Los payloads más pequeños a menudo justifican el coste extra de CPU.
Compatibilidad de GZIP: Mejor cuando necesitas soporte máximo de clientes sin riesgo de negociación (SDKs antiguos, clientes embebidos, proxies legacy). Es una base segura aunque no sea la mejor en rendimiento.
Los “niveles” de compresión son presets que intercambian tiempo de CPU por salida más pequeña:
La descompresión suele ser mucho más barata que la compresión en los tres, pero niveles muy altos pueden aumentar la CPU/batería del cliente—importante en móvil.
La compresión suele venderse como “respuestas más pequeñas = APIs más rápidas”. Eso es frecuentemente cierto en redes lentas o caras—pero no es automático. Si la compresión añade suficiente tiempo de CPU, puedes acabar con peticiones más lentas pese a menos bytes en la red.
Conviene separar dos costes:
Un alto ratio puede reducir el tiempo de transferencia, pero si la compresión añade (por ejemplo) 15–30 ms de CPU por respuesta, puede que pierdas más tiempo del que ahorras—especialmente en conexiones rápidas.
Bajo carga, la compresión puede perjudicar la latencia p95/p99 más que la p50. Cuando el uso de CPU sube, las peticiones se encolan. El encolamiento amplifica pequeños costes por petición en grandes retardos: la latencia media puede parecer bien, pero los usuarios más lentos sufren.
No adivines. Haz pruebas A/B o despliegues graduados y compara:
Prueba con patrones de tráfico y payloads realistas. El mejor nivel es el que reduce el tiempo total, no solo los bytes.
La compresión no es “gratis”—traslada trabajo de la red a CPU y memoria en ambos extremos. En APIs, eso se traduce en más tiempo de manejo de peticiones, mayor uso de memoria y a veces ralentización en clientes.
La mayor parte de la CPU se gasta en comprimir respuestas. La compresión identifica patrones, construye estados/diccionarios y escribe la salida codificada.
La descompresión suele ser más barata, pero sigue siendo relevante:
Si tu API ya está limitada por CPU (servidores de aplicaciones ocupados, auth pesado, consultas costosas), activar un nivel alto de compresión puede aumentar la latencia en cola aunque los payloads sean más pequeños.
La compresión puede aumentar el uso de memoria en varios aspectos:
En entornos conteinerizados, picos de memoria mayores pueden traducirse en OOM kills o límites más estrictos que reduzcan densidad.
La compresión añade ciclos de CPU por respuesta, reduciendo el throughput por instancia. Eso puede disparar el autoscaling antes y aumentar costes. Un patrón común: el ancho de banda baja, pero el gasto en CPU sube—la elección correcta depende de cuál recurso sea escaso para ti.
En móvil o dispositivos de baja potencia, la descompresión compite con renderizado, ejecución de JavaScript y batería. Un formato que ahorre unos KB pero tarde más en descomprimirse puede sentirse más lento, particularmente cuando importa el “tiempo hasta datos utilizables”.
Zstandard (ZSTD) es un formato moderno pensado para ofrecer buen ratio sin ralentizar tu API. Para muchas APIs con mucho JSON, es un fuerte “por defecto”: respuestas notoriamente más pequeñas que GZIP con latencia similar o menor, además de descompresión muy rápida en clientes.
ZSTD es más valioso cuando te importa el tiempo de extremo a extremo, no solo bytes mínimos. Suele comprimir rápido y descomprimir extremadamente rápido—útil en APIs donde cada milisegundo de CPU compite con el manejo de peticiones.
Funciona bien en una amplia gama de tamaños: JSON pequeño a mediano suele ver ganancias, y las respuestas grandes incluso más.
Para la mayoría de APIs, empieza con niveles bajos (comúnmente 1–3). A menudo ofrecen el mejor equilibrio latencia/tamaño.
Usa niveles más altos solo cuando:
Un enfoque pragmático: un valor bajo global, y aumentar selectivamente el nivel en endpoints con respuestas grandes.
ZSTD soporta streaming, lo que reduce la memoria pico y permite empezar a enviar antes para respuestas grandes.
El modo diccionario puede ser una gran mejora para APIs que devuelven muchos objetos similares (claves repetidas, esquemas estables). Es más efectivo cuando:
El soporte servidor es sencillo en muchas pilas, pero la compatibilidad cliente puede decidir la elección. Algunos clientes HTTP, proxies y gateways aún no anuncian o aceptan Content-Encoding: zstd por defecto.
Si sirves a consumidores terceros, mantén un fallback (normalmente GZIP) y habilita ZSTD solo cuando Accept-Encoding lo incluya claramente.
Brotli está diseñado para exprimir texto al máximo. En JSON, HTML y otros payloads “verbales”, suele superar a GZIP en ratio—especialmente con niveles altos.
Las respuestas ricas en texto son el punto fuerte de Brotli. Si tu API envía JSON grandes (catálogos, resultados de búsqueda, blobs de configuración), Brotli puede reducir bytes notablemente, lo que ayuda en redes lentas y puede reducir costes de egreso.
Brotli también es fuerte cuando puedes comprimir una vez y servir muchas veces (respuestas cacheables, recursos versionados). En esos casos, Brotli a alto nivel suele merecer la pena porque el coste de CPU se amortiza.
Para respuestas dinámicas (generadas por petición), los mejores ratios de Brotli suelen requerir niveles altos que son caros en CPU y añaden latencia. Contando el tiempo de compresión, la ganancia real frente a ZSTD (o incluso GZIP bien afinado) puede ser menor de lo esperado.
Tampoco resulta atractivo para payloads que no se comprimen bien (datos ya comprimidos, muchos binarios). Ahí solo consumes CPU.
Los navegadores suelen soportar bien Brotli sobre HTTPS, por eso es popular en tráfico web. Para clientes no navegador (SDKs móviles, IoT, stacks HTTP antiguos), el soporte puede ser inconsistente—negocia correctamente vía Accept-Encoding y mantén fallback (normalmente GZIP).
GZIP sigue siendo la respuesta por defecto para compresión de APIs porque es la opción más universalmente soportada. Casi todo cliente HTTP, navegador, proxy y gateway entiende Content-Encoding: gzip, y esa predictibilidad importa cuando no controlas lo que hay entre tu servidor y los usuarios.
La ventaja no es que GZIP sea “el mejor”, sino que raramente es la elección equivocada. Muchas organizaciones tienen años de experiencia operando con él, defaults sensatos en servidores web y menos sorpresas con intermediarios que podrían manejar mal códecs nuevos.
Para payloads de API (a menudo JSON), niveles medios a bajos suelen ser el punto óptimo. Niveles como 1–6 entregan la mayor parte de la reducción de tamaño manteniendo la CPU razonable.
Niveles muy altos (8–9) exprimen un poco más, pero el CPU adicional raramente compensa en tráfico dinámico donde la latencia importa.
En hardware moderno, GZIP suele ser más lento que ZSTD para ratios comparables, y a menudo no alcanza los mejores ratios de Brotli en texto. En cargas reales de API, eso normalmente significa:
Si debes soportar clientes antiguos, dispositivos embebidos, proxies corporativos estrictos o gateways legacy, GZIP es la apuesta más segura. Algunos intermediarios pueden eliminar codificaciones desconocidas, no reenviarlas o romper la negociación—problemas menos comunes con GZIP.
Si tu entorno es mixto o incierto, empezar con GZIP (añadiendo ZSTD/Brotli solo donde controlas toda la ruta) suele ser la estrategia más fiable.
Las ganancias de compresión no dependen solo del algoritmo; el mayor determinante es el tipo de datos que envías. Algunos payloads se reducen mucho con ZSTD, Brotli o GZIP; otros apenas cambian y solo consumen CPU.
Las respuestas ricas en texto suelen comprimirse extremadamente bien por las claves repetidas, espacios y patrones predecibles.
Como regla, cuanta más repetición y estructura, mejor el ratio.
Formatos binarios como Protocol Buffers y MessagePack son más compactos que JSON, pero no son aleatorios. Pueden contener etiquetas repetidas, layouts de registro similares y secuencias predecibles.
Eso significa que con frecuencia son todavía comprimibles, especialmente en respuestas grandes o endpoints con listas. La única respuesta fiable es probar con tráfico real: mismo endpoint, mismos datos, compresión on/off y comparar tamaño y latencia.
Muchos formatos ya usan compresión interna. Aplicar compresión HTTP encima suele aportar ahorros minúsculos y puede aumentar tiempos.
Para estos es común desactivar compresión por tipo de contenido.
Un enfoque sencillo: comprimir solo si la respuesta supera un tamaño mínimo.
Content-Encoding.Esto mantiene la CPU enfocada en payloads donde la compresión realmente reduce ancho de banda y mejora el tiempo de extremo a extremo.
La compresión solo funciona suavemente cuando cliente y servidor acuerdan una codificación. Ese acuerdo sucede mediante Accept-Encoding (envíalo el cliente) y Content-Encoding (lo envía el servidor).
Accept-Encoding y Content-Encoding (ejemplos simples)Un cliente anuncia lo que puede decodificar:
GET /v1/orders HTTP/1.1
Host: api.example
Accept-Encoding: zstd, br, gzip
El servidor elige uno y declara lo que usó:
HTTP/1.1 200 OK
Content-Type: application/json
Content-Encoding: zstd
Si el cliente envía Accept-Encoding: gzip y respondes con Content-Encoding: br, ese cliente podría fallar al parsear el cuerpo. Si el cliente no envía Accept-Encoding, lo más seguro suele ser enviar sin compresión.
Un orden práctico para APIs suele ser:
zstd primero (buen equilibrio velocidad/ratio)br (a menudo más pequeño, a veces más lento)gzip (máxima compatibilidad)En otras palabras: zstd > br > gzip.
No lo trates como universal: si tu tráfico es mayormente navegadores, br puede merecer prioridad; si tienes clientes móviles antiguos, gzip puede ser la opción más segura.
Vary: Accept-Encoding y cachingSi una respuesta puede servirse en varias codificaciones, añade:
Vary: Accept-Encoding
Sin esto, un CDN o proxy podría cachear la variante gzip (o zstd) y servirla a un cliente que no pidió (o no puede manejar) esa codificación.
Algunos clientes anuncian soporte pero tienen decodificadores defectuosos. Para ser resiliente:
zstd, cae temporalmente a gzip.La negociación se trata menos de exprimir cada byte y más de no romper un cliente.
La compresión de API no ocurre en el vacío. Tu protocolo de transporte, overhead TLS y cualquier CDN o gateway entre medias pueden cambiar el resultado real—o incluso romper cosas si hay mala configuración.
Con HTTP/2, múltiples peticiones comparten una conexión TCP. Eso reduce overhead de conexión, pero la pérdida de paquetes puede bloquear todos los streams por head-of-line a nivel TCP. La compresión puede ayudar al reducir cuerpos de respuesta, disminuyendo la cantidad de datos “atascados” tras un evento de pérdida.
HTTP/3 usa QUIC (UDP) y evita el head-of-line a nivel TCP entre streams. El tamaño del payload sigue importando, pero la penalización por pérdida suele ser menor por conexión. En la práctica, la compresión sigue siendo valiosa—espera beneficios más en ahorro de ancho de banda y en “time to last byte” que en drops dramáticos de latencia.
TLS ya consume CPU (handshakes, cifrado/descifrado). Añadir compresión (especialmente en niveles altos) puede llevarte por encima del límite de CPU en picos. Por eso las configuraciones de “compresión rápida con ratio decente” suelen superar a las de “ratio máximo” en producción.
Algunos CDNs/gateways comprimen automáticamente ciertos MIME types, otros pasan lo que origina el servidor. Algunos incluso normalizan o eliminan Content-Encoding si están mal configurados.
Verifica comportamiento por ruta y asegúrate de que Vary: Accept-Encoding se preserve para que las caches no sirvan una variante comprimida incorrectamente.
Si cacheas en el edge, considera almacenar variantes separadas por codificación (gzip/br/zstd) en lugar de recomprimir en cada hit. Si cacheas en el origen, quizá quieras que el edge negocie y cachee múltiples codificaciones.
La clave es consistencia: Content-Encoding correcto, Vary correcto y claridad sobre dónde ocurre la compresión.
Para APIs orientadas a navegadores, prefiere Brotli cuando el cliente lo anuncia (Accept-Encoding: br). Los navegadores decodifican Brotli eficientemente y suele dar mejor reducción en texto.
Para APIs internas servicio-a-servicio, prefiere ZSTD cuando controlas ambos extremos. Suele ser más rápido a ratio similar que GZIP y la negociación es directa.
Para APIs públicas usadas por SDKs diversos, mantén GZIP como baseline universal y añade ZSTD opcionalmente para clientes que lo soporten explícitamente. Así evitas romper stacks HTTP antiguos.
Empieza con niveles que sean fáciles de medir y poco propensos a sorpresas:
Si necesitas mayor ratio, valida con muestras de payload en entorno parecido a producción y sigue p95/p99 antes de subir niveles.
Comprimir respuestas diminutas puede costar más CPU que el ahorro en la red. Un punto de partida práctico:
Ajusta comparando: (1) bytes ahorrados, (2) tiempo servidor añadido, (3) cambio en latencia end-to-end.
Despliega la compresión detrás de un feature flag, luego añade config por ruta (habilitar para /v1/search, deshabilitar para endpoints ya pequeños). Proporciona una opt-out del cliente usando Accept-Encoding: identity para depuración y clientes en el edge. Siempre incluye Vary: Accept-Encoding para mantener caches correctas.
Si generas APIs rápidamente (por ejemplo, frontends React con backends Go + PostgreSQL y depuras con tráfico real), la compresión es uno de esos "pequeños ajustes con gran impacto". En Koder.ai, los equipos suelen llegar a este punto temprano porque prototipan y despliegan full‑stack rápido, y afinan comportamiento en producción (compresión, cache headers) una vez que los endpoints y shapes de payload se estabilizan. La conclusión práctica: trata la compresión como una característica de rendimiento, lánzala detrás de una flag y mide p95/p99 antes de darla por buena.
Los cambios de compresión son fáciles de desplegar y sorprendentemente fáciles de romper. Trátalos como una característica de producción: despliega gradualmente, mide impacto y mantén rollback sencillo.
Empieza con un canary: habilita el nuevo Content-Encoding (por ejemplo, zstd) para una pequeña porción de tráfico o un solo cliente interno.
Luego rampa progresivamente (ej.: 1% → 5% → 25% → 50% → 100%), pausando si las métricas clave se mueven en la dirección equivocada.
Mantén una ruta de rollback rápida:
gzip).Controla la compresión tanto como feature de rendimiento como de fiabilidad:
4xx/5xx, errores de decodificación cliente y timeouts.Cuando algo falla, los culpables habituales son:
Content-Encoding indica compresión pero el cuerpo no lo está (o al revés).Accept-Encoding o devolver una codificación no anunciada.Content-Length incorrecto o interferencia de proxy/CDN.Explica en la documentación los códecs soportados, incluyendo ejemplos:
Accept-Encoding: zstd, br, gzipContent-Encoding: zstd (o fallback)Si publicas SDKs, añade ejemplos copiable para decodificar y declara claramente las versiones mínimas que soportan Brotli o Zstandard.
Usa la compresión de respuestas cuando las respuestas son ricas en texto (JSON/GraphQL/XML/HTML), de tamaño medio a grande y tus usuarios están en redes lentas/caras o pagas costes de egreso relevantes. Evítala (o usa un umbral alto) para respuestas pequeñas, medios ya comprimidos (JPEG/MP4/ZIP/PDF) y servicios limitados por CPU donde trabajo adicional por petición perjudicaría p95/p99.
Porque intercambia ancho de banda por CPU (y a veces memoria). El tiempo de compresión puede retrasar el inicio del envío de bytes (TTFB) y, bajo carga, amplificar la cola de peticiones—lo que suele perjudicar la latencia en la cola alta (tail latency) aunque la latencia media mejore. La configuración “óptima” es la que reduce el tiempo de extremo a extremo, no solo el tamaño de los paquetes.
Un orden práctico por defecto para muchas APIs es:
zstd primero (rápido y buen ratio)br (a menudo más pequeño para texto, puede costar más CPU)gzip (máxima compatibilidad)Basar la elección final en lo que el cliente anuncie en , y mantener un fallback seguro (normalmente o ).
Empieza con niveles bajos y mide.
Usa un umbral mínimo de tamaño para no gastar CPU en cargas diminutas.
Ajusta por endpoint comparando bytes ahorrados vs tiempo servidor añadido y el impacto en p50/p95/p99.
Concéntrate en tipos de contenido estructurados y repetitivos:
La compresión debe seguir la negociación HTTP:
Accept-Encoding (por ejemplo, zstd, br, gzip)Content-Encoding soportadoSi el cliente no envía , la respuesta más segura suele ser . Nunca devuelvas un que el cliente no haya anunciado, ya que podrías provocar fallos de parsing.
Añade:
Vary: Accept-Encoding
Esto evita que CDNs/proxies cacheen (por ejemplo) una respuesta gzip y la sirvan a un cliente que no pidió o no puede decodificar gzip (o zstd/br). Si soportas múltiples codificaciones, este encabezado es esencial para un cache correcto.
Los fallos comunes incluyen:
Despliega como una funcionalidad de rendimiento:
Accept-EncodinggzipidentityLos niveles más altos suelen dar rendimientos decrecientes en tamaño pero pueden disparar CPU y empeorar p95/p99.
Una práctica común es habilitar compresión solo para valores Content-Type de tipo texto y desactivarla para formatos ya comprimidos.
Accept-EncodingContent-EncodingContent-Encoding indica gzip pero el cuerpo no está comprimido)Accept-Encoding)Content-Length incorrecto al hacer streaming/comprimirAl depurar, captura encabezados de respuesta crudos y verifica la descompresión con una herramienta/cliente conocido como correcto.
Si la latencia tail sube bajo carga, baja el nivel, incrementa el umbral, o cambia a un códec más rápido (a menudo ZSTD).