2025년 7월 20일·8분
AI 백엔드에서의 API 진화와 하위 호환성
AI로 생성된 백엔드가 API를 안전하게 진화시키는 방법: 버전 관리, 호환 가능한 변경, 마이그레이션, 사용 중단 절차, 그리고 클라이언트 파손을 방지하는 테스트를 배웁니다.
AI로 생성된 백엔드가 API를 안전하게 진화시키는 방법: 버전 관리, 호환 가능한 변경, 마이그레이션, 사용 중단 절차, 그리고 클라이언트 파손을 방지하는 테스트를 배웁니다.
API 진화는 이미 실제 클라이언트가 사용 중인 API를 변경해 가는 지속적 과정입니다. 필드를 추가하거나 검증 규칙을 조정하거나 성능을 개선하거나 새 엔드포인트를 도입하는 식의 변화가 포함됩니다. 이는 클라이언트가 프로덕션에 배포된 이후에 특히 중요합니다. 작은 변경도 모바일 앱 릴리스, 통합 스크립트, 파트너 워크플로를 깨트릴 수 있기 때문입니다.
변경이 하위 호환성을 가지려면 기존 클라이언트가 업데이트 없이 계속 동작해야 합니다.
예를 들어, API가 다음을 반환한다고 합시다:
{ "id": "123", "status": "processing" }
새로운 선택적 필드를 추가하는 것은 일반적으로 하위 호환성입니다:
{ "id": "123", "status": "processing", "estimatedSeconds": 12 }
알 수 없는 필드를 무시하는 오래된 클라이언트는 계속 작동합니다. 반면 status를 state로 이름을 바꾸거나 필드 타입(문자열 → 숫자)을 바꾸거나 선택적 필드를 필수로 만드는 것은 흔한 브레이킹 변경입니다.
AI 생성 백엔드는 단순한 코드 스니펫이 아닙니다. 실제로는 다음을 포함합니다:
AI는 시스템의 일부를 빠르게 재생성할 수 있기 때문에 변경이 의도치 않게 '드리프트'할 수 있습니다.
채팅 기반 워크플로에서 전체 앱을 생성하는 경우가 특히 그렇습니다. 예를 들어 Koder.ai 같은 플랫폼은 간단한 채팅에서 웹, 서버, 모바일 애플리케이션을 생성할 수 있습니다(웹은 React, 백엔드는 Go + PostgreSQL, 모바일은 Flutter 등). 이러한 속도는 훌륭하지만, 재생성된 릴리스가 클라이언트가 의존하던 동작을 실수로 바꾸지 않도록 계약 규율(그리고 자동화된 diff/테스트)이 훨씬 더 중요해집니다.
AI는 OpenAPI 스펙 생성, 보일러플레이트 코드 업데이트, 안전한 기본값 제안, 마이그레이션 단계 초안 작성 등 많은 것을 자동화할 수 있습니다. 그러나 클라이언트 계약에 영향을 주는 결정—허용되는 변경, 안정적인 필드, 엣지 케이스와 비즈니스 규칙 처리 방법—은 여전히 인간 검토가 필수적입니다. 목표는 예측 가능한 동작을 유지하는 속도이지, 놀라움을 대가로 한 속도가 아닙니다.
API는 거의 단일 "클라이언트"만을 위한 것이 아닙니다. 작은 제품이라도 동일한 엔드포인트에 의존하는 여러 소비자가 있을 수 있습니다:
API가 깨지면 비용은 단순히 개발자 시간만이 아닙니다. 모바일 사용자는 수주간 오래된 앱 버전으로 묶일 수 있고, 파트너는 다운타임을 겪거나 데이터 누락, 중요한 워크플로 중단을 경험할 수 있습니다. 내부 서비스는 조용히 실패하여 지저분한 백로그를 만들 수 있습니다(예: 이벤트 누락, 불완전한 레코드).
AI 생성 백엔드는 코드가 빠르게 자주 변경될 수 있다는 점에서 추가적인 위험을 가집니다. 생성은 작동하는 코드를 생산하는 데 최적화되므로 동작을 시간에 걸쳐 보존하는 데 최적화되어 있지 않을 수 있습니다. 그 속도는 가치가 있지만, 실수로 브레이킹 변경이 발생할 위험도 증가합니다(필드 이름 변경, 다른 기본값, 더 엄격한 검증, 새로운 인증 요구 등).
따라서 하위 호환성은 노력이 아니라 제품 결정이어야 합니다. 실천적 접근은 API를 제품 인터페이스처럼 취급하는 예측 가능한 변경 프로세스를 정의하는 것입니다: 기능은 추가할 수 있지만 기존 클라이언트를 놀라게 해서는 안 됩니다.
유용한 멘탈 모델은 API 계약(예: OpenAPI 스펙)을 클라이언트가 의존할 수 있는 "진실의 원천(source of truth)"으로 취급하는 것입니다. 그러면 생성은 구현의 세부사항일 뿐입니다: 백엔드를 재생성할 수는 있지만, 계약과 그 약속은 의도적으로 버전 관리하고 커뮤니케이션하지 않는 한 안정적으로 유지됩니다.
AI 시스템이 백엔드 코드를 빠르게 생성하거나 수정할 수 있을 때, 신뢰할 수 있는 닻(anchor)은 바로 API 계약입니다: 클라이언트가 호출할 수 있는 것, 보내야 하는 것, 기대할 수 있는 것을 서술한 문서입니다.
계약은 기계가 읽을 수 있는 스펙입니다:
이 계약은 구현이 바뀌더라도 외부 소비자에게 약속하는 바입니다.
계약 우선(contract-first) 워크플로에서는 OpenAPI/GraphQL 스키마를 먼저 설계하거나 업데이트한 뒤 서버 스텁을 생성하고 로직을 채웁니다. 이는 변경이 의도적이고 검토 가능하므로 호환성에 더 안전합니다.
코드 우선(code-first) 워크플로드는 코드 주석이나 런타임 탐색에서 스펙을 생성합니다. AI 생성 백엔드는 기본적으로 코드 우선에 기울기 쉽지만, 생성된 계약을 검토 대상 산출물로 취급하는 한 괜찮습니다.
실용적인 하이브리드는: AI에게 코드 변경을 제안하게 하되, 스펙도 업데이트(또는 재생성)하게 하고, 계약의 diff를 주요 변경 신호로 삼는 것입니다.
API 스펙을 백엔드와 동일한 레포에 저장하고 풀 리퀘스트로 검토하세요. 간단한 규칙: 계약 변경이 이해되고 승인되지 않으면 병합하지 마세요. 이렇게 하면 하위 호환성을 깨는 편집이 프로덕션에 도달하기 전에 노출됩니다.
드리프트를 줄이려면 같은 계약에서 서버 스텁과 클라이언트 SDK를 생성하세요. 계약이 업데이트되면 양쪽이 함께 업데이트되어 AI가 구현에서 클라이언트가 기대하지 않는 동작을 실수로 만들어내기 어려워집니다.
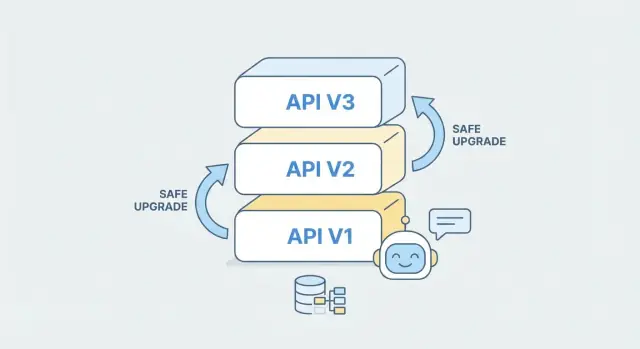
API 버전 관리는 모든 미래 변경을 예측하는 것이 아니라, 백엔드를 개선하는 동안 클라이언트가 안정적으로 계속 작동할 수 있는 명확한 방법을 제공하는 것입니다. 실제로 "최고의" 전략은 소비자가 즉시 이해하고 팀이 일관되게 적용할 수 있는 전략입니다.
URL 버전 관리는 경로에 버전을 넣습니다(예: /v1/orders, /v2/orders). 모든 요청에서 볼 수 있고 디버깅이 쉬우며 캐싱과 라우팅에 잘 맞습니다.
헤더 버전 관리는 URL을 깔끔하게 유지하고 버전을 헤더로 옮깁니다(예: Accept: application/vnd.myapi.v2+json). 우아할 수 있지만 트러블슈팅에서 덜 명확하고 복사-붙여넣 예제에서 누락되기 쉽습니다.
쿼리 파라미터 버전 관리는 /orders?version=2 같은 형태입니다. 직접적이지만 프록시나 클라이언트가 쿼리 문자열을 제거/변경할 수 있고, 사람이 실수로 다른 버전을 섞기 쉬워 지저분해질 수 있습니다.
대부분의 팀에게—특히 클라이언트 이해를 단순하게 하고 싶다면—URL 버전 관리를 기본으로 권장합니다. 가장 놀랍지 않고 문서화하기 쉬우며 어떤 SDK나 모바일 앱 또는 파트너 통합이 어느 버전을 호출하는지 명확합니다.
AI로 백엔드를 생성하거나 확장할 때 각 버전을 별도의 "계약 + 구현" 단위로 취급하세요. 업데이트된 OpenAPI 스펙에서 /v2를 스캐폴딩하고 /v1을 그대로 유지하면서 가능한 한 비즈니스 로직을 공유하세요. 이렇게 하면 기존 클라이언트는 계속 작동하고 새로운 클라이언트만 의도적으로 v2를 채택합니다.
버전 관리는 문서가 따라올 때만 작동합니다. 버전별 API 문서를 유지하고, 각 버전별 예제를 일관되게 유지하며, 무엇이 변경되었는지, 무엇이 더 이상 권장되지 않는지, 마이그레이션 노트를 명확히 적은 체인지로그를 게시하세요(이상적으로는 요청/응답 예제를 나란히 제시).
AI 생성 백엔드가 업데이트될 때, 호환성을 생각하는 가장 안전한 방식은: "기존 클라이언트가 아무 변경 없이 계속 작동할 것인가?"입니다. 아래 체크리스트를 사용해 변경사항을 분류하세요.
이 변경들은 기존 클라이언트가 이미 보내거나 기대하는 것을 무효화하지 않기 때문에 보통 깨지지 않습니다:
middleName 또는 metadata) — 기존 클라이언트가 알 수 없는 필드를 무시하면 계속 작동합니다.다음은 증거가 없는 한 브레이킹으로 간주하세요:
클라이언트가 관용적 수신자가 되도록 권장하세요: 알 수 없는 필드는 무시하고 예상치 못한 enum 값은 우아하게 처리하세요. 이렇게 하면 백엔드가 필드를 추가하여 진화할 수 있으며 클라이언트 업데이트를 강제하지 않습니다.
생성기는 정책으로 실수로 브레이킹 변경을 막을 수 있습니다:
API 변경은 클라이언트가 보는 것입니다: 요청/응답 형태, 필드 이름, 검증 규칙, 에러 동작 등. 데이터베이스 변경은 백엔드가 저장하는 것들입니다: 테이블, 컬럼, 인덱스, 제약, 데이터 포맷. 이 둘은 관련되어 있지만 동일하지 않습니다.
흔한 실수는 데이터베이스 마이그레이션을 "내부적 변경"으로 취급하는 것입니다. AI 생성 백엔드에서는 API 레이어가 스키마에서 생성되거나 밀접하게 결합된 경우가 많아 스키마 변경이 조용히 API 변경으로 이어질 수 있습니다. 그래서 오래된 클라이언트가 의도치 않게 깨질 수 있습니다.
롤링 업그레이드 동안 구/신 코드 경로가 모두 동작하도록 다단계 접근을 사용하세요:
이 패턴은 빅뱅 릴리스를 피하고 롤백 옵션을 제공합니다.
오래된 클라이언트는 종종 필드가 선택적이거나 안정적 의미를 가진다고 가정합니다. 새로운 non-null 컬럼을 추가할 때는:
주의: DB 기본값이 항상 도움이 되는 것은 아닙니다. API 직렬화기가 여전히 null을 내보내거나 검증 규칙을 바꾸면 문제가 생길 수 있습니다.
AI 도구는 마이그레이션 스크립트를 초안하고 백필을 제안할 수 있지만 인간 검증이 필요합니다: 제약 조건 확인, 성능(락, 인덱스 생성) 점검, 스테이징 데이터로 마이그레이션 실행하여 오래된 클라이언트가 계속 동작하는지 확인하세요.
기능 플래그는 엔드포인트 형태를 변경하지 않고 동작을 바꿀 수 있게 해줍니다. AI 생성 백엔드에서는 내부 로직이 자주 재생성되거나 최적화될 수 있지만 클라이언트는 일관된 요청/응답을 기대하기 때문에 특히 유용합니다.
큰 스위치를 내리는 대신 새 코드 경로를 기본적으로 비활성화한 채로 제공하고 점진적으로 활성화하세요. 문제가 생기면 플래그를 끄면 되므로 긴급 재배포를 서두를 필요가 없습니다.
실용적인 롤아웃 계획은 보통 세 가지 기술을 결합합니다:
API의 경우 핵심은 내부 실험을 하는 동안에도 응답을 안정적으로 유지하는 것입니다. 동일한 상태 코드, 필드 이름, 에러 포맷을 반환하면서도 구현을 바꿀 수 있습니다. 새 데이터를 추가할 필요가 있으면 클라이언트가 무시할 수 있는 추가 필드를 선호하세요.
POST /orders 엔드포인트가 현재 여러 형식의 phone을 허용한다고 가정하고, E.164 형식만 허용하도록 엄격히 하려면:
strict_phone_validation 같은 플래그 뒤에 더 엄격한 검증 도입이 패턴은 데이터 품질을 높이면서도 호환성 있는 API를 깨뜨리지 않습니다.
디프리케이션은 오래된 API 동작에 대한 "정중한 퇴출"입니다: 더 이상 권장하지 않음을 알리고, 조기 경고를 주며 클라이언트가 예측 가능한 경로로 이동할 수 있도록 합니다. 썬셋은 최종 단계로, 게시된 날짜에 오래된 버전을 종료합니다. AI 생성 백엔드에서는 엔드포인트와 스키마가 빠르게 진화할 수 있기 때문에 엄격한 퇴출 프로세스가 업데이트를 안전하고 신뢰성 있게 만듭니다.
API 계약 수준에서 시맨틱 버전링을 사용하세요:
이 정의를 문서에 한 번 적고 일관되게 적용하세요. 그래야 AI 보조 변경이 작아 보여도 실제로는 클라이언트를 깨트리는 "조용한 메이저"를 막을 수 있습니다.
기본 정책을 정하고 지키세요. 흔한 접근:
확실하지 않다면 약간 더 긴 창을 선택하세요. 버전을 잠깐 더 유지하는 비용은 긴급 클라이언트 마이그레이션의 비용보다 보통 낮습니다.
모든 채널을 활용하세요:
Deprecation: true, Sunset: Wed, 31 Jul 2026 00:00:00 GMT, Link로 마이그레이션 문서 연결(/docs/api/v2/migration)체인지로그와 상태 업데이트에도 디프리케이션 공지를 포함해 구매/운영팀에게도 보이게 하세요.
썬셧 날짜까지 구버전을 실행한 뒤 확실하게 비활성화하세요. 그 과정은 점진적으로 사고 나도록 방치하는 것이 아니라 계획된 변경이어야 합니다.
썬셋 시:
410 Gone)을 반환하고 최신 버전과 마이그레이션 페이지를 안내/docs/deprecations/v1)를 일정 기간 유지무엇보다도 썬셋을 소유자, 모니터링, 롤백 계획과 함께 일정 변경으로 취급하세요. 이런 규율이 잦은 진화를 클라이언트에 놀라움을 주지 않고 가능하게 합니다.
AI 생성 코드는 빠르게 바뀔 수 있고 때로는 놀라운 곳에서 변화가 발생합니다. 클라이언트를 계속 작동시키는 가장 안전한 방법은 구현이 아니라 계약을 테스트하는 것입니다.
기본 실무는 이전 OpenAPI 스펙과 새로 생성된 스펙을 비교하는 계약 테스트입니다. "전후 비교" 검사처럼 동작합니다:
많은 팀이 CI에서 OpenAPI diff를 자동화하여 생성된 변경이 검토 없이 배포되지 않도록 합니다. 이는 프롬프트, 템플릿, 모델 버전이 바뀔 때 특히 유용합니다.
소비자 주도 계약 테스트는 관점을 뒤집습니다: 백엔드 팀이 API를 어떻게 사용하는지 추측하는 대신 각 클라이언트는 자신이 보내는 요청과 의존하는 응답을 작은 기대치로 공유합니다. 배포 전에 백엔드는 여전히 그 기대를 만족한다는 것을 증명해야 합니다.
이 방식은 웹 앱, 모바일 앱, 파트너 등 여러 소비자가 있을 때 조정 없이도 업데이트를 가능하게 합니다.
다음 항목들을 고정하는 회귀 테스트를 추가하세요:
에러 스키마를 게시하는 경우 명시적으로 테스트하세요—클라이언트는 종종 우리가 원하지 않는 만큼 에러를 파싱합니다.
OpenAPI diff 검사, 소비자 계약, 형태/에러 회귀 테스트를 CI 게이트로 결합하세요. 생성된 변경이 실패하면 보통 프롬프트나 생성 규칙, 혹은 호환성 레이어를 조정해 사용자에게 노출되기 전에 수정합니다.
클라이언트는 보통 에러 메시지를 "읽는" 대신 에러의 형태와 코드에 반응합니다. 사람 친화적 문구의 오탈자는 짜증스럽지만 회복 가능한 반면, 상태 코드 변경, 필드 누락, 에러 식별자 이름 변경은 결제 실패, 동기화 실패, 무한 재시도 루프 등 치명적 문제를 일으킬 수 있습니다.
일관된 에러 엔벨로프(예: { code, message, details, request_id })와 클라이언트가 의존할 수 있는 식별자 집합을 유지하세요. message는 자유롭게 문구를 개선할 수 있지만 code의 의미는 안정적으로 문서화하고 유지해야 합니다.
이미 여러 포맷이 돌아다니는 경우 인플레이스 정리를 시도하지 마세요. 대신 새 포맷을 버전 경계나 협상 메커니즘(예: Accept 헤더) 뒤에 추가하고 오래된 포맷을 계속 지원하세요.
새 에러 코드는 때때로 필요하지만 기존 통합을 놀라게 하지 않도록 추가해야 합니다:
VALIDATION_ERROR를 처리한다면 이를 바로 INVALID_FIELD로 교체하지 마세요.code를 반환하되, 구버전에 대한 호환 힌트를 details에 포함시키거나 구분된 일반 코드로 매핑 유지message는 표시하라고 안내기본 원칙: 기존 코드의 의미를 절대 변경하지 마세요. 예컨대 NOT_FOUND가 "리소스가 없음"을 의미했다면 이를 "접근 거부"로 바꾸지 마세요(그건 403이어야 합니다).
하위 호환성은 또한 "같은 요청 → 같은 결과" 입니다. 사소한 기본값 변경도 클라이언트를 깨트릴 수 있습니다.
페이지네이션: 기본 limit, page_size 또는 커서 동작을 버전 없이 바꾸지 마세요. 페이지 기반에서 커서 기반으로 전환하면 버전 없이 바꾸면 브레이킹입니다.
정렬: 기본 정렬 순서는 안정적이어야 합니다. 예: created_at desc에서 relevance desc로 바꾸면 목록 재정렬로 UI 가정이나 증분 동기화가 깨질 수 있습니다.
필터링: 암묵적 필터(예: 기본적으로 "비활성" 항목 제외)를 변경하지 마세요. 새 동작이 필요하면 include_inactive=true 같은 명시적 플래그나 status=all을 추가하세요.
일부 호환성 문제는 엔드포인트가 아니라 해석의 문제입니다.
"9.99"를 9.99로 바꾸거나 그 반대로 바꾸지 마세요.include_deleted=false나 send_email=true 같은 기본값을 뒤집지 마세요. 기본값을 바꿔야 한다면 새 파라미터로 클라이언트가 옵트인하도록 하세요.AI 생성 백엔드에서는 모델이 "응답을 개선"하려고 할 수 있으므로 이러한 동작을 명시적 계약과 테스트로 고정하세요.
하위 호환성은 한 번 확인하고 끝나는 것이 아닙니다. AI 생성 백엔드는 동작이 수동 빌드보다 더 빠르게 바뀔 수 있으므로 누가 무엇을 사용하고 있는지, 업데이트가 클라이언트에 해를 끼치고 있는지를 보여주는 피드백 루프가 필요합니다.
모든 요청에 명시적 API 버전(경로 /v1/..., 헤더 X-Api-Version 또는 협상된 스키마 버전)을 태그하고 버전별로 분리된 지표를 수집하세요:
이렇게 하면 예를 들어 /v1/orders가 트래픽의 5%지만 롤아웃 이후 오류의 70%를 차지한다는 사실을 알아차릴 수 있습니다.
API 게이트웨이 또는 애플리케이션에서 클라이언트가 실제로 보내는 것과 호출하는 경로를 로깅하세요:
/v1/legacy-search)SDK를 통제한다면 가벼운 클라이언트 식별자 + SDK 버전 헤더를 추가해 오래된 통합을 식별하세요.
오류가 급증하면 “어떤 배포가 동작을 바꿨는가?”를 알아야 합니다. 다음을 상관관계하세요:
항상 이전 생성 아티팩트(컨테이너/이미지)를 재배포하고 라우터를 통해 트래픽을 되돌릴 수 있게 하세요. 스키마 변경이 포함된 경우 데이터 되돌리기를 요구하는 롤백은 피하세요. 대신 스키마 변경은 추가 방식으로 수행하여 이전 버전이 계속 작동하도록 하세요.
플랫폼이 환경 스냅샷과 빠른 롤백을 지원하면 활용하세요. 예: Koder.ai는 스냅샷과 롤백을 워크플로 일부로 제공하여 "확장 → 마이그레이트 → 수축" 패턴과 점진적 API 롤아웃에 자연스럽게 맞습니다.
AI 생성 백엔드는 빠르게 변할 수 있습니다—새 엔드포인트가 생기고, 모델이 바뀌고, 검증이 강화됩니다. 클라이언트를 안정적으로 유지하는 가장 안전한 방법은 API 변경을 한 번성 편집이 아니라 작고 반복 가능한 릴리스 프로세스로 다루는 것입니다.
왜 하는지, 의도된 동작, 계약 영향(필드, 타입, 필수/선택, 에러 코드)을 문서화하세요.
변경을 호환 가능(안전) 또는 브레이킹(클라이언트 변경 필요)으로 표시하세요. 불확실하면 브레이킹으로 가정하고 호환 경로를 설계하세요.
구 클라이언트를 어떻게 지원할지 결정하세요: 별칭, 이중 쓰기/읽기, 기본값, 관용적 파싱, 또는 새 버전.
기능 플래그나 설정으로 변경을 추가해 점진적 롤아웃과 빠른 롤백이 가능하게 하세요.
자동화된 계약 검사(OpenAPI diff 규칙) 및 알려진 클라이언트의 골든 요청/응답 테스트를 실행해 동작 드리프트를 잡으세요.
각 릴리스는 /docs에 업데이트된 참조 문서, 관련 시나리오의 짧은 마이그레이션 노트, 변경사항의 호환성을 명시한 체인지로그 항목을 포함해야 합니다.
디프리케이션을 날짜와 함께 공지하고, 남은 사용량을 측정한 뒤 썬셋 기간 이후 제거하세요.
last_name을 family_name으로 바꾸려면:
family_name 우선)family_name을 반환하고 last_name은 별칭으로 유지)last_name 사용중단으로 표시, 제거 날짜 명시플랜 기반 지원이나 장기 버전 지원을 제공한다면 /pricing에 분명히 표기하세요.
하위 호환성은 기존 클라이언트가 아무런 변경 없이도 계속 동작하는 것을 의미합니다. 실제로 보통 다음은 허용됩니다:
일반적으로는 필드 이름 변경, 필드 제거, 타입 변경, 검증 강화 등은 누군가를 깨트릴 수 있으므로 허용되지 않습니다.
배포된 어떤 클라이언트라도 업데이트해야 하는 변경은 브레이킹(호환성 깨짐)으로 취급하세요. 흔한 브레이킹 변경에는:
status → state)앵커로서 API 계약을 사용하세요. 일반적으로:
그리고 다음을 따르세요:
이렇게 하면 AI가 재생성해도 클라이언트에게 보이는 동작이 몰래 바뀌는 것을 막을 수 있습니다.
Contract-first는 먼저 스펙을 업데이트하고 서버 코드/스텁을 생성하는 방식입니다. Code-first는 코드에서 스펙을 생성합니다.
AI 워크플로에는 현실적으로 하이브리드가 좋습니다:
CI에서 OpenAPI diff 검사를 자동화하고, 다음과 같은 경우 빌드를 실패시키세요:
병합은 (a) 변경이 호환된다고 확인되었거나, (b) 새로운 메이저 버전을 올리는 경우에만 허용하세요.
일반적으로 가장 직관적이고 디버깅하기 쉬운 방법은 URL 버전 관리(예: /v1/orders, /v2/orders)입니다:
헤더나 쿼리 버전도 가능하지만, 트러블슈팅 시 누락될 위험이 있습니다.
클라이언트가 엄격할 수 있다는 가정을 하세요. 안전한 패턴:
의미 변경이나 값 제거가 필요하면 새 버전에서 하세요.
“expand → migrate → contract” 패턴을 사용하세요:
이렇게 하면 다운타임을 줄이고 롤백 가능성을 확보할 수 있습니다.
기능 플래그를 사용하면 엔드포인트 형태는 그대로 두면서 내부 동작만 바꿀 수 있습니다. 권장 배포 방식:
검증 강화처럼 클라이언트 호환성 위험이 있는 변경에 특히 유용합니다.
사용자가 놓치기 어렵게 하고 시간표를 정하세요:
응답 헤더(Deprecation: true, Sunset: <date>, Link: </docs/api/v2/migration>)와 문서 배너, SDK 경고 등을 통해 알리세요. 썬셋 시에는 명확한 오류()와 마이그레이션 가이드를 제공하세요.
410 Gone