2025년 9월 01일·7분
하나의 AI 지원 워크플로우로 아이디어에서 배포된 앱까지
앱 아이디어에서 배포된 제품까지 하나의 AI 지원 워크플로우로 이동하는 실무적 종단 간 내러티브 — 단계, 프롬프트, 점검사항을 제공합니다.
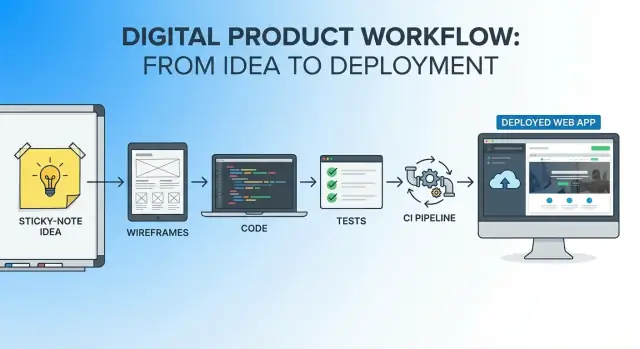
앱 아이디어에서 배포된 제품까지 하나의 AI 지원 워크플로우로 이동하는 실무적 종단 간 내러티브 — 단계, 프롬프트, 점검사항을 제공합니다.
작고 유용한 앱 아이디어를 상상해보세요: 카페 직원이 버튼 하나로 고객을 대기자 명단에 추가하고 테이블이 준비되면 자동으로 문자 알림을 보내는 “큐 버디(Queue Buddy)”. 성공 지표는 단순하고 측정 가능해야 합니다: 2주 내 평균 대기 혼선 관련 전화 수를 50% 줄이고, 직원 온보딩은 10분 이내로 유지.
이 글의 정신은 이렇습니다: 명확하고 범위가 한정된 아이디어를 선택하고, 무엇이 “잘한 것”인지를 정의한 뒤, 도구와 문서, 사고 방식을 불필요하게 전환하지 않고 개념에서 라이브 배포까지 이동합니다.
단일 워크플로우는 아이디어의 첫 문장부터 첫 프로덕션 릴리스까지의 하나의 연속된 실타래입니다:
여전히 여러 도구(에디터, 리포, CI, 호스팅)를 사용할 수 있지만, 각 단계에서 프로젝트를 “다시 시작”하지 않습니다. 같은 내러티브와 제약이 계속 이어집니다.
AI가 가장 가치 있는 순간은:
하지만 제품 결정권은 당신에게 있습니다. 워크플로우는 항상 검증하도록 설계됩니다: 이 변경이 지표를 움직이는가? 배포해도 안전한가?
다음 섹션들에서 단계별로 진행합니다:
이 과정을 따르면 “아이디어”에서 “라이브 앱”으로 이동하는 반복 가능한 방식을 갖추되, 범위, 품질, 학습을 촘촘히 연결할 수 있습니다.
AI에게 화면, API, 데이터베이스 구조를 요청하기 전에 목표가 분명해야 합니다. 여기서 약간의 명확성은 나중에 수시간의 “거의 맞음” 출력을 절약합니다.
당신이 앱을 만드는 이유는 특정 그룹이 반복적으로 동일한 마찰을 겪기 때문입니다: 그들이 가진 도구로 중요한 작업을 빠르고 신뢰성 있게, 또는 확신을 가지고 완료하지 못한다는 것. 버전1의 목표는 모든 것을 자동화하려 하지 않고 그 워크플로우에서 하나의 고통스러운 단계를 제거하는 것입니다—그래서 사용자는 “X를 해야 한다”에서 “X가 완료되었다”까지 몇 분 안에 도달하고 무슨 일이 있었는지 명확한 기록을 갖게 됩니다.
하나의 주요 사용자를 선택하세요. 보조 사용자는 나중으로 미룹니다.
가정은 좋은 아이디어가 조용히 실패하는 지점입니다—이를 가시화하세요.
버전1은 출시 가능한 작은 승리여야 합니다.
경량 요구문서(한 페이지 짜리)를 통해 “멋진 아이디어”에서 “구현 가능한 계획”으로 이어집니다. 이 문서는 초점을 유지시키고 AI 조수를 올바른 맥락에서 작동하게 해주며, 첫 버전이 몇 달짜리 프로젝트로 확장되는 것을 막습니다.
간결하고 훑어보기 쉬운 형태를 유지하세요. 간단한 템플릿:
결과로 표현된 5–10개의 기능만 쓰고 순위를 매기세요:
이 순위는 AI에게 “먼저 Must만 구현하라”는 지침으로도 사용됩니다.
상위 3–5개 기능마다 2–4개의 수락 기준을 적습니다. 평이한 언어로 테스트 가능한 진술을 쓰세요.
예시:
마지막으로 “열린 질문” 목록을 적습니다—챗 하나, 고객 통화 하나, 또는 짧은 검색으로 답할 수 있는 것들입니다.
예: “사용자에게 구글 로그인 필요?” “우리가 저장해야 하는 최소 데이터는?” “관리자 승인 필요?”
이 문서는 관료적 문서가 아니라 공유된 진실의 원천이며, 빌드가 진행되면서 계속 업데이트됩니다.
AI에게 화면을 생성해 달라고 요청하기 전에 제품의 스토리를 먼저 정리하세요. 빠른 여정 스케치는 모두를 정렬시켜줍니다: 사용자가 무엇을 하려는지, 성공이 어떤 모습인지, 어디서 실패할 수 있는지.
해피 패스부터 시작하세요: 주요 가치를 제공하는 가장 단순한 순서입니다.
예시 흐름(일반):
다음으로 처리하지 않으면 비용이 큰 몇 가지 엣지 케이스를 추가합니다:
큰 다이어그램은 필요 없습니다. 번호 매긴 목록과 메모면 프로토타이핑과 코드 생성에 충분합니다.
각 화면에 대해 짧은 “해야 할 일(job to be done)”을 작성하세요. UI 중심이 아니라 결과 중심으로 유지합니다.
AI와 작업할 경우 이 목록은 훌륭한 프롬프트 자료가 됩니다: “X, Y, Z를 지원하고 빈/로딩/오류 상태를 포함한 대시보드 생성.”
화면과 플로우를 지원할 충분한 ‘냅킨 스키마’ 수준으로 유지하세요.
관계(User → Projects → Tasks)와 권한에 영향을 주는 항목을 메모하세요.
실수가 신뢰를 무너뜨리는 지점을 표시하세요:
이는 과도한 엔지니어링이 아니라, 작동 데모가 출시 후 지원 악몽으로 변하는 걸 막는 조치입니다.
버전1 아키텍처의 역할은 단 하나입니다: 가장 작은 유용한 제품을 무리 없이 출시할 수 있게 해주기. 좋은 규칙은 “하나의 리포, 하나의 배포 가능한 백엔드, 하나의 배포 가능한 프런트엔드, 하나의 데이터베이스” — 필요할 때만 추가하세요.
일반적인 웹앱이라면 합리적 기본값은:
서비스 수를 적게 유지하세요. v1에는 잘 조직된 ‘모듈형 모놀리식’이 마이크로서비스보다 보통 더 쉽습니다.
AI 우선 환경에서 아키텍처, 작업, 생성된 코드가 밀접하게 연결되길 원한다면 Koder.ai 같은 플랫폼이 유용할 수 있습니다: v1 범위를 채팅으로 설명하고 “계획 모드”에서 반복한 뒤 React 프런트엔드와 Go + PostgreSQL 백엔드를 생성할 수 있습니다—그러면서 리뷰와 제어는 유지됩니다.
코드를 생성하기 전에 작은 API 테이블을 작성해 AI와 같은 목표를 보게 하세요. 예시 형태:
GET /api/projects → { items: Project[] }POST /api/projects → { project: Project }GET /api/projects/:id → { project: Project, tasks: Task[] }POST /api/projects/:id/tasks → { task: Task }상태 코드, 오류 형식(예: { error: { code, message } }), 페이지네이션 등에 대한 메모를 추가하세요.
v1을 공개 또는 단일 사용자로 운영할 수 있다면 인증을 건너뛰어 빠르게 출시하세요. 계정이 필요하면 매니지드 제공자(이메일 매직링크나 OAuth)를 사용하고 권한을 단순하게 유지하세요: “사용자는 자신의 레코드를 소유한다.” 실사용이 늘어나기 전까지 복잡한 역할은 피하세요.
몇 가지 실용적 제약을 문서화하세요:
이 메모들은 AI가 단지 동작하는 코드가 아니라 배포 가능한 코드를 생성하도록 안내합니다.
모멘텀을 죽이는 가장 빠른 방법은 일주일 동안 도구를 토론하고도 실행 가능한 코드가 없는 것입니다. 목표는 “앱이 로컬에서 시작되고 화면이 보이며 요청을 받을 수 있는” 헬로앱에 빨리 도달하는 것입니다—변경을 검토하기 쉬울 정도로 작게 유지하세요.
AI에 tight한 프롬프트를 주세요: 선택한 프레임워크, 기본 페이지, 스텁 API, 원하는 파일들. 예측 가능한 관습을 원하고, 기발함은 피하세요.
좋은 첫 구조는 다음과 같습니다:
/README.md
/.env.example
/apps/web/
/apps/api/
/package.json
단일 리포를 쓰는 경우 기본 라우트(/ 및 /settings)와 하나의 API 엔드포인트(GET /health 또는 GET /api/status)를 요청하세요. 배관이 작동하는지 증명하기엔 충분합니다.
Koder.ai를 사용한다면 이 단계에서 “web + api + database-ready” 스켈레톤을 요청하고 구조와 관습에 만족하면 소스를 내보내는 것이 자연스러운 흐름입니다.
UI는 의도적으로 단순하게 유지하세요: 한 페이지, 한 버튼, 한 요청.
예시 동작:
이렇게 하면 피드백 루프가 즉시 생깁니다: UI가 로드되지만 호출이 실패하면 CORS, 포트, 라우팅, 네트워크 오류 중 어디를 봐야 할지 알 수 있습니다. 여기서는 인증, DB, 복잡한 상태를 추가하지 마세요—스켈레톤이 안정된 뒤에 추가합니다.
첫날 .env.example을 만들면 “내 환경에서만 동작” 문제를 방지하고 온보딩을 수월하게 합니다.
예시:
WEB_PORT=3000
API_PORT=4000
API_URL=http://localhost:4000
그런 다음 README가 1분 내에 실행되도록 만드세요:
.env.example을 .env로 복사이 단계를 깨끗한 기반선(laying clean foundation lines)으로 다루세요. 작은 성공마다 커밋하세요: “init repo”, “add web shell”, “add api health endpoint”, “wire web to api”. 작은 커밋은 AI 지원 반복에서 안전합니다: 생성된 변경이 엇나가면 되돌려도 하루를 잃지 않습니다.
스켈레톤이 엔드투엔드로 돌아간 뒤에는 ‘모두 끝내기’ 충동을 억누르세요. 대신 DB, API, UI를 건드리는 얇은 수직 슬라이스를 만들어 반복하세요. 얇은 슬라이스는 리뷰를 빠르게 하고 버그를 작게 하며 AI 지원 검증을 쉽게 만듭니다.
앱이 없으면 안 되는 모델 하나를 선택하세요—대개 사용자가 생성하거나 관리하는 ‘무언가’. 필드를 평이하게 정의(필수 vs 선택, 기본값)하고 관계형 DB를 쓰면 마이그레이션을 추가하세요. 첫 버전은 지루하게 유지하세요: 조기 정규화나 과도한 유연성은 피합니다.
AI로 모델을 초안할 경우, 각 필드와 기본값을 한 문장으로 정당화해 달라고 요청하세요. 설명할 수 없는 항목은 v1에 적합하지 않을 가능성이 큽니다.
첫 사용자 여정에 필요한 엔드포인트만 만드세요: 보통 생성, 조회, 최소한의 업데이트. 경계 근처(요청 DTO/스키마)에 검증을 두고 규칙을 명시하세요:
검증은 다듬기 단계가 아니라 기능의 일부입니다—나중에 당신을 느려지게 하는 지저분한 데이터를 막아줍니다.
오류 메시지를 디버깅과 지원을 위한 UX로 다루세요. 클라이언트 응답에는 무엇이 실패했는지와 어떻게 고칠지 명확히 적되 민감한 세부는 포함하지 마세요. 서버측 로그에는 요청 ID와 함께 기술적 맥락을 남겨 추적 가능하게 하세요.
AI에게는 PR 크기 단위의 점진적 변경을 요청하세요: 하나의 마이그레이션 + 하나의 엔드포인트 + 하나의 테스트. 동료의 코드를 리뷰하듯 변경사항을 검토하세요: 명명, 엣지케이스, 보안 가정, 사용자가 ‘작은 승리’에 도달하는지 확인하세요. 여분의 기능을 추가하면 잘라내고 계속 진행하세요.
v1은 엔터프라이즈 수준의 보안이 필요하지 않지만, 유망한 앱을 지원 악몽으로 만드는 예측 가능한 실패는 피해야 합니다. 목표는 “충분히 안전”: 잘못된 입력을 막고, 기본적으로 접근을 제한하며, 문제가 생겼을 때 유용한 증거를 남기는 것입니다.
모든 경계(폼, API 페이로드, 쿼리 파라미터, 내부 웹훅)를 신뢰하지 마세요. 타입, 길이, 허용값을 검증하고 저장 전에 데이터를 정규화(문자열 트림, 케이스 변환)하세요.
실용적 기본값:
AI로 핸들러를 생성할 때는 “입력 검증을 포함”이라고 하지 말고 명시적 규칙(예: “최대 140자” 또는 “다음 중 하나여야 함: …”)을 포함하도록 요청하세요.
단순한 권한 모델이면 v1에 충분합니다:
소유권 검사는 미들웨어/정책 함수로 중앙화해 코드베이스 곳곳에 if userId == …를 흩뿌리지 마세요.
좋은 로그는 *무슨 일이, 누구에게, 어디서 일어났는가?*를 답합니다. 포함 항목:
update_project, project_id)이벤트를 기록하되 비밀번호, 토큰, 결제 세부정보 같은 비밀은 절대 기록하지 마세요.
앱을 ‘충분히 안전’하다고 부르기 전에 확인하세요:
테스트는 완벽한 커버리지를 목표로 하는 것이 아니라, 사용자에게 피해를 주거나 신뢰를 깨는 실패를 예방하는 것입니다. AI 지원 워크플로우에서 테스트는 생성된 코드가 의도와 일치하도록 하는 "계약" 역할도 합니다.
테스트를 많이 추가하기 전에 실수의 비용이 큰 지점을 식별하세요. 전형적인 고위험 영역은 금전/크레딧, 권한, 데이터 변환, 엣지 케이스 검증입니다.
이 부분에 대한 단위 테스트를 먼저 작성하세요. 테스트는 작고 구체적으로 유지하세요: 입력 X가 주어지면 출력 Y(또는 오류)를 기대합니다. 하나의 함수에 분기가 너무 많으면 깔끔하게 테스트하기 어렵다는 신호이며, 그 함수는 단순화돼야 합니다.
단위 테스트는 로직 버그를 잡고, 통합 테스트는 라우트, DB 호출, 인증 검사, UI 흐름 등 “연결” 문제를 잡습니다.
핵심 여정(해피 패스)을 선택하고 자동화하세요:
몇 개의 탄탄한 통합 테스트가 수십 개의 작은 테스트보다 더 많은 사고를 예방합니다.
AI는 테스트 스캐폴딩과 놓치기 쉬운 엣지 케이스 열거에 능합니다. 요청하세요:
생성된 어서션을 모두 검토하세요. 테스트는 동작(behavior)을 검증해야지 구현 세부를 검증하면 안 됩니다. 버그가 발생해도 테스트가 통과한다면 그 테스트는 제 역할을 못 합니다.
겸손한 목표(예: 핵심 모듈 60–70%)를 정하고 이를 가드레일로 사용하세요. 안정적이고 반복 가능한 테스트에 집중해 CI에서 빠르게 실행되도록 하세요. 플래키한 테스트는 신뢰를 떨어뜨립니다—신뢰를 잃으면 테스트 스위트는 더 이상 보호 기능을 제공하지 않습니다.
자동화는 AI 지원 워크플로우가 “내 랩탑에서 동작하는 프로젝트”에서 “신뢰하고 배포할 수 있는 것”으로 바뀌는 지점입니다. 목표는 화려한 도구가 아니라 재현성입니다.
로컬과 CI에서 같은 결과를 만드는 단일 명령을 선택하세요. Node라면 npm run build, Python이면 make build, 모바일이면 특정 Gradle/Xcode 빌드 단계 등이 될 수 있습니다.
개발 설정과 프로덕션 설정을 일찍 분리하세요. 규칙: 개발 기본값은 편리하게, 프로덕션 기본값은 안전하게.
{
"scripts": {
"lint": "eslint .",
"format": "prettier -w .",
"test": "vitest run",
"build": "vite build"
}
}
린터는 위험한 패턴(사용하지 않는 변수, 안전하지 않은 비동기 호출)을 잡고 포매터는 스타일 논쟁을 줄입니다. v1 규칙은 온건하게 유지하되 일관되게 적용하세요.
실용적 게이트 순서:
첫 CI 워크플로우는 작게 시작하세요: 의존성 설치, 게이트 실행, 빠르게 실패. 이것만으로도 깨진 코드가 은밀히 머지되는 걸 막습니다.
name: ci
on: [push, pull_request]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: 20
- run: npm ci
- run: npm run format -- --check
- run: npm run lint
- run: npm test
- run: npm run build
비밀이 어디에 저장될지 결정하세요: CI 시크릿 스토어, 패스워드 매니저, 배포 플랫폼의 환경 설정 등. 절대 git에 커밋하지 마세요—.env는 .gitignore에 추가하고 안전한 플레이스홀더가 있는 .env.example를 포함하세요.
다음 단계로 깔끔하게 연결하고 싶다면, 이 게이트들을 배포 프로세스와 연결해 “CI 성공만 프로덕션으로” 가는 경로를 만드세요.
배포는 단 한 번의 버튼 클릭이 아니라 반복 가능한 루틴입니다. v1의 목표는 단순합니다: 스택에 맞는 배포 대상을 선택하고, 작은 증분으로 배포하며 항상 되돌릴 방법을 마련하세요.
앱 실행 방식에 맞는 플랫폼을 고르세요:
“쉽게 재배포 가능한지”를 최우선으로 선택하는 것이 이 단계에서는 “최대한의 제어”보다 낫습니다.
도구 전환을 최소화하는 것이 우선이라면 빌드+호스팅+롤백 프리미티브를 묶어주는 플랫폼을 고려하세요. 예: Koder.ai는 배포 및 호스팅을 스냅샷과 롤백 기능과 함께 지원하므로 릴리스를 되돌릴 수 있는 단계로 다룰 수 있습니다.
배포 체크리스트를 한 번 작성해 매번 재사용하세요. 실제로 따를 수 있을 만큼 짧게 유지하세요:
레포에 /docs/deploy.md로 저장하면 코드와 가까이 유지됩니다.
의존성을 조회할 수 있는 경량 엔드포인트를 만드세요: “앱이 올라와 있고 종속성에 연결 가능한가?” 일반 패턴:
GET /health(로드 밸런서와 업타임 모니터용)GET /status(앱 버전 + 종속성 체크를 반환)응답은 빠르고 캐시 없음, 그리고 안전해야 합니다(비밀/내부 상세 금지).
롤백 계획은 명확해야 합니다:
배포가 되돌릴 수 있을 때 릴리스는 일상적이고 스트레스가 적은 과정이 됩니다.
런칭은 가장 유용한 단계의 시작입니다: 실제 사용자가 무엇을 하는지, 어디서 앱이 깨지는지, 작은 변경이 성공 지표를 어떻게 움직이는지 학습하는 시기입니다. 목표는 빌드할 때 사용한 AI 지원 워크플로우를 그대로 유지하되, 이제 가정 대신 증거를 향하게 하는 것입니다.
최소 모니터링 스택으로 세 가지 질문에 답하세요: 올라와 있는가? 실패하고 있는가? 느린가?
업타임 체크는 헬스 엔드포인트 주기 호출이면 충분합니다. 오류 추적은 스택트레이스와 요청 컨텍스트를(민감 데이터는 제외) 캡처해야 합니다. 성능 모니터링은 키 엔드포인트 응답시간과 프런트엔드 페이지 로드 지표부터 시작하세요.
AI에게 다음을 생성하도록 도움을 요청하세요:
무엇이든 다 추적하지 마세요—앱이 작동한다는 것을 입증하는 항목만 추적하세요. 하나의 주요 성공 지표를 정의한 뒤(예: “체크아웃 완료”, “첫 프로젝트 생성”, “팀원 초대”), 간단한 퍼널을 계측하세요: 진입 → 주요 행동 → 성공.
AI에게 이벤트 이름과 속성을 제안하게 한 뒤 개인정보 및 명확성 측면을 검토하세요. 이벤트 이름을 자주 바꾸면 추세 분석이 무의미해지므로 이벤트는 안정적으로 유지하세요.
간단한 피드백 수단을 만드세요: 인앱 피드백 버튼, 짧은 이메일 별칭, 가벼운 버그 템플릿. 주간으로 우선순위를 매기세요: 피드백을 주제별로 그룹화하고 분석과 연결한 뒤 다음 1–2개의 개선사항을 결정합니다.
모니터링 알림, 분석 하락, 피드백 주제를 새로운 “요구사항”으로 처리하세요. 같은 프로세스에 투입합니다: 문서 업데이트 → 작은 변경 제안 생성 → 얇은 슬라이스로 구현 → 타깃 테스트 추가 → 동일한 되돌릴 수 있는 릴리스 프로세스로 배포. 팀의 경우 공유된 “학습 로그” 페이지(레포의 /docs 또는 내부 문서에 링크)를 만들어 결정사항을 가시화하고 재현 가능하게 유지하세요.
“단일 워크플로우”는 아이디어에서 프로덕션까지 하나의 연속된 흐름을 의미합니다. 구체적으로는 다음과 같습니다:
여러 도구를 사용할 수는 있지만, 각 단계마다 프로젝트를 ‘다시 시작’하지 않습니다.
AI는 옵션과 초안을 빠르게 생성하는 도구로 사용하고, 최종 결정과 검증은 사람이 합니다:
명확한 결정 규칙을 유지하세요: 이 변경이 성공 지표를 움직이는가? 배포해도 안전한가?
측정 가능한 성공 지표와 엄격한 v1 ‘완료 정의’로 범위를 통제하세요. 예시:
해당 결과를 지원하지 않는 기능은 v1의 비목표로 둡니다.
한 페이지 분량의 간결한 PRD(요구문서)를 권장합니다. 포함 항목:
이후 핵심 기능 5–10개를 작성하고 Must/Should/Nice로 우선순위화하세요. 이 우선순위가 AI에게 ‘먼저 무엇을 구현할지’ 안내합니다.
상위 3–5개 기능마다 2–4개의 검증 가능한 수락 기준을 적습니다. 좋은 수락 기준은:
예시 패턴: 검증 규칙, 기대 리디렉션, 오류 메시지, 권한 동작(예: “권한 없는 사용자는 명확한 오류를 보고 데이터가 유출되지 않는다”).
먼저 행복 경로(happy path)를 번호로 적고, 이어서 확률이 높거나 비용이 큰 실패 케이스를 몇 가지 추가하세요:
간단한 목록만으로도 UI 상태, API 응답, 테스트를 안내하기에 충분합니다.
v1에는 ‘모듈형 모놀리식’이 합리적입니다:
요구사항이 강제하지 않는 한 서비스를 늘리지 마세요. 이렇게 하면 조정 오버헤드가 줄고 AI로 생성한 변경을 검토/롤백하기 쉬워집니다.
코드 생성 전에 작은 ‘API 계약’을 작성하세요:
{ error: { code, message } })이 표가 있으면 프런트엔드, 백엔드, 테스트가 같은 목표를 바라보게 됩니다.
플러밍을 증명하는 ‘헬로 앱’을 목표로 하세요:
/health)를 호출하는 버튼 하나.env.example와 1분 내 실행 가능한 README 포함작은 마일스톤을 자주 커밋하면 AI가 생성한 변경이 문제를 일으켜도 안전하게 되돌릴 수 있습니다.
AI 지원 워크플로우에서 가장 중요한 테스트/CI 게이트는 다음과 같습니다:
CI에서는 간단한 게이트를 이 순서로 강제하세요:
테스트는 안정적이고 빠르게 유지하세요. 플래키한 테스트는 신뢰를 갉아먹습니다.