2025년 8월 24일·7분
다단계 사용자 온보딩을 위한 웹 앱 구축 방법
명확한 단계, 데이터 모델, 테스트 계획으로 다단계 사용자 온보딩 흐름을 설계하고 구현하는 방법을 배우세요.
명확한 단계, 데이터 모델, 테스트 계획으로 다단계 사용자 온보딩 흐름을 설계하고 구현하는 방법을 배우세요.
다단계 온보딩 흐름은 신규 사용자가 “가입됨” 상태에서 제품을 사용할 준비가 된 상태로 이동하도록 안내하는 화면들의 연속입니다. 한 번에 모든 것을 묻는 대신, 설정을 더 작은 단계로 나누어 한 번에 끝내거나 시간이 지나면서 완료할 수 있게 합니다.
설정이 단일 폼을 넘을 때—특히 선택지, 선행 조건, 규정 준수 확인 등이 포함될 때—다단계 온보딩이 필요합니다. 제품이 맥락(업종, 역할, 선호), 검증(이메일/전화/신원 확인), 또는 초기 구성(워크스페이스, 결제, 통합)을 필요로 한다면 단계 기반 흐름은 이해하기 쉽고 오류를 줄입니다.
다단계 온보딩은 단계적으로 발생하는 작업을 지원하기 때문에 널리 사용됩니다. 예시:
좋은 온보딩은 단순히 화면을 끝내는 것이 아니라 사용자가 빠르게 가치를 얻는 것입니다. 제품에 맞게 성공을 정의하세요:
흐름은 또한 재개와 연속성을 지원해야 합니다: 사용자는 떠났다가 돌아와도 진행을 잃지 않아야 하고, 다음 논리적 단계로 바로 들어가야 합니다.
다단계 온보딩은 예측 가능한 방식으로 실패합니다:
목표는 온보딩을 시험처럼 느끼게 하지 않는 것입니다: 각 단계의 명확한 목적, 신뢰할 수 있는 진행 추적, 사용자가 남긴 곳에서 쉽게 재개할 수 있는 방법을 제공하세요.
화면을 그리거나 코드를 작성하기 전에 온보딩이 무엇을 달성하려 하는지—그리고 누구를 위해—결정하세요. 다단계 흐름은 올바른 사람들을 혼란을 최소화하며 올바른 상태로 데려갈 때만 “좋다”고 할 수 있습니다.
다른 사용자는 서로 다른 맥락, 권한, 긴급성을 가지고 옵니다. 주요 진입 페르소나를 이름 붙이고 이미 알려진 사항을 정리하세요:
각 유형에 대해 제약(예: “회사 이름 수정 불가”), 필수 데이터(예: “워크스페이스 선택 필수”), 잠재적 단축(예: “SSO로 이미 검증됨”)을 나열하세요.
온보딩의 종료 상태는 명확하고 측정 가능해야 합니다. “완료”는 모든 화면을 본 것이 아니라 비즈니스 준비가 된 상태입니다. 예:
완료 기준을 백엔드에서 평가할 수 있는 체크리스트로 작성하세요. 모호한 목표가 아니라 서버가 판단할 수 있는 조건이어야 합니다.
어떤 단계가 필수인지, 어떤 것이 선택적인지, 그리고 단계 간 의존성을 매핑하세요(예: 워크스페이스가 있어야 팀원을 초대할 수 있음).
마지막으로 스킵 규칙을 정밀하게 정의하세요: 어떤 사용자가 어떤 조건에서 어떤 단계를 건너뛸 수 있는지(예: “SSO로 인증된 경우 이메일 검증 건너뛰기”), 그리고 건너뛴 단계가 설정에서 나중에 다시 방문 가능한지 여부를 명확히 하세요.
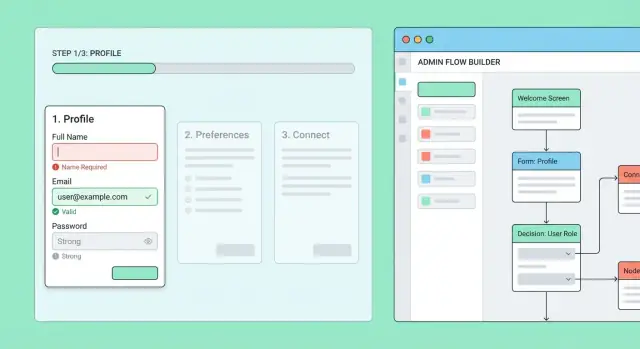
스크린이나 API를 만들기 전에 온보딩을 흐름 맵으로 그리세요: 모든 단계, 사용자가 다음에 갈 수 있는 경로, 나중에 돌아올 수 있는 방법을 보여주는 작은 다이어그램입니다.
단계를 짧고 행동 중심의 이름(동사가 도움됨)으로 작성하세요: “비밀번호 생성”, “이메일 확인”, “회사 정보 추가”, “팀원 초대”, “결제 연결”, “완료”. 초안은 단순하게 시작하고, 그다음 필수 필드와 의존성(예: 요금제 선택 전에는 결제 단계 불가) 같은 세부를 추가하세요.
유용한 점검: 각 단계는 하나의 질문에 답해야 합니다—“당신은 누구인가?”, “무엇이 필요한가?”, 혹은 “제품을 어떻게 구성할 것인가?” 하나의 단계가 세 가지를 모두 하려 하면 분리하세요.
대부분의 제품은 대부분 선형 백본을 두고 경험이 실제로 달라질 때만 조건부 분기를 둡니다. 일반적인 분기 규칙:
이 규칙들을 맵에 “if/then”으로 문서화하세요(예: “If region = EU → show VAT step”). 이렇게 하면 흐름을 이해하기 쉽고 미로 같은 구조를 피할 수 있습니다.
사용자가 흐름에 진입할 수 있는 모든 지점을 나열하세요:
/settings/onboarding)각 진입은 항상 올바른 다음 단계로 사용자를 데려가야 합니다. 무조건 1단계로 보내지 마세요.
사용자가 중간에 떠날 것을 가정하세요. 돌아왔을 때 어떻게 할지 결정하세요:
맵에 명확한 “재개” 경로를 표시해 경험이 신뢰할 수 있고 부서지지 않은 느낌을 주게 하세요.
좋은 온보딩은 안내하는 길처럼 느껴져야지 시험처럼 느껴지면 안 됩니다. 목표는 결정 피로를 줄이고 기대를 명확히 하며 문제가 생겼을 때 빠르게 회복할 수 있게 하는 것입니다.
**마법사(Wizard)**는 단계가 반드시 순서대로 완료되어야 할 때 적합합니다(예: 신원 → 결제 → 권한). 체크리스트는 순서에 상관없이 완료할 수 있는 작업에 적합합니다(예: “로고 추가”, “팀원 초대”, “캘린더 연결”). 제품 내부에 팁과 콜아웃을 넣어 사용하면서 배우는 방식에는 가이드형 작업이 좋습니다.
불확실하면 체크리스트 + 각 작업으로 가는 딥링크로 시작하고, 정말 필수인 단계만 게이트하세요.
진행 피드백은 “얼마나 남았나?”에 답해야 합니다. 사용 예시:
또한 더 긴 흐름인 경우 “나중에 저장하고 마치기” 같은 표시를 추가하세요.
명확한 라벨을 사용하세요(예: “회사명”, “엔터티 식별자” 같은 모호한 표현은 피함). “왜 묻는가”를 설명하는 마이크로카피를 추가하세요(예: “청구서에 사용할 이름입니다”). 가능한 기존 데이터로 미리 채우고 안전한 기본값을 선택하세요.
오류는 해결의 길로 디자인하세요: 필드를 강조하고 무엇을 해야 하는지 설명하며 입력값을 유지하고 첫 번째 잘못된 필드로 포커스를 이동시키세요. 서버 측 오류의 경우 재시도 옵션을 보여주고 완료된 단계를 반복 입력하지 않게 진행을 보존하세요.
터치 대상은 크고 멀티컬럼 폼을 피하세요. 주요 액션은 항상 보이게 하고 전체 키보드 네비게이션, 가시적인 포커스 상태, 라벨이 있는 입력, 스크린리더 친화적인 진행 텍스트(단순 시각적 바만으로는 안 됨)를 보장하세요.
원활한 다단계 온보딩은 “사용자에게 다음에 무엇을 보여줄지”, “사용자가 이미 무엇을 제공했는지”, “어떤 버전의 흐름을 따르는지”를 신뢰성 있게 답할 수 있는 데이터 모델에 달려 있습니다.
초기에는 작은 테이블/컬렉션 세트로 시작하세요:
구성(Flow/Step)과 사용자 데이터(StepResponse/Progress)를 분리해 두면 관리가 쉬워집니다.
흐름을 버전 관리할지 일찍 결정하세요. 대부분의 제품에서는 관리하는 편이 안전합니다.
단계를 편집(이름 변경, 재정렬, 필수 필드 추가)할 때 진행 중인 사용자가 갑자기 검증에 실패하거나 위치를 잃지 않도록 간단한 접근법:
id와 version(또는 불변의 flow_version_id)을 가짐flow_version_id를 영구 참조진행 저장 방식은 자동저장(사용자가 입력하는 대로 저장)과 명시적 Next 저장 중 선택할 수 있습니다. 많은 팀은 둘을 결합: 초안은 자동저장하고 단계 ‘완료’는 Next에서 표시합니다.
보고 및 문제해결을 위해 started_at, completed_at, last_seen_at(및 단계별 saved_at) 같은 타임스탬프를 추적하세요. 이 필드들은 온보딩 분석과 고객지원의 이해를 돕습니다.
다단계 온보딩은 사용자의 온보딩 세션이 항상 하나의 “상태”(현재 단계 + 상태)에 있고 허용된 전이만 가능하다고 보면 이해하기 쉽습니다.
프론트엔드가 임의 URL로 점프하는 대신 각 단계에 대해 작은 상태 집합(예: not_started → in_progress → completed)과 명확한 전이 집합(예: start_step, save_draft, submit_step, go_back, reset_step)을 정의하세요.
이 접근법의 이점:
단계는 클라이언트 검증과 서버 검사라는 두 조건을 모두 만족할 때만 “완료”로 표시하세요. 서버 검사는 예: “이 이메일은 이미 사용 중인지”, “세금 ID가 국가와 일치하는지”, “회사명이 허용되는지” 등입니다.
서버 결정은 단계와 함께 저장하고 오류 코드를 포함시키세요. 이렇게 하면 UI가 완료되었다고 생각하지만 백엔드가 동의하지 않는 상황을 방지할 수 있습니다.
간과하기 쉬운 엣지 케이스: 사용자가 이전 단계를 편집하면 이후 단계들이 잘못될 수 있습니다. 예: “국가” 변경으로 인해 “세금 정보”나 “사용 가능한 요금제”가 무효화될 수 있습니다.
해결 방법은 종속성을 추적하고 제출 후 다운스트림 단계를 재평가하는 것입니다. 일반적인 결과:
needs_review로 표시하거나 in_progress로 되돌림뒤로 가기는 지원하되 안전해야 합니다:
이렇게 하면 유연성을 유지하면서 세션 상태의 일관성과 강제성을 보장할 수 있습니다.
백엔드는 사용자가 온보딩에서 어디에 있는지, 지금까지 무엇을 입력했는지, 다음에 무엇을 할 수 있는지에 대한 “진실의 근원”입니다. 좋은 API는 프론트엔드를 단순하게 유지합니다: 현재 단계를 렌더링하고, 데이터를 안전하게 제출하며, 새로고침이나 네트워크 오류 후 복구할 수 있게 합니다.
최소한 다음 동작을 설계하세요:
GET /api/onboarding → 현재 단계 키, 완료 %, 렌더링에 필요한 저장된 초안 값을 반환PUT /api/onboarding/steps/{stepKey} with { "data": {…}, "mode": "draft" | "submit" }POST /api/onboarding/steps/{stepKey}/nextPOST /api/onboarding/steps/{stepKey}/previousPOST /api/onboarding/complete (서버가 모든 필수 단계를 검증)저장 후에는 업데이트된 진행률과 서버가 결정한 다음 단계를 함께 반환하세요:
{ "currentStep": "profile", "nextStep": "team", "progress": 0.4 }
사용자는 더블클릭 하거나 연결이 불안해 재시도하는 일이 있습니다. “저장”을 안전하게 만들려면:
PUT/POST 요청에 대해 Idempotency-Key 헤더를 받아 (userId, endpoint, key)로 중복 제거PUT /steps/{stepKey}를 해당 단계의 저장된 페이로드를 완전 덮어쓰기 형태로 처리(또는 부분 병합 규칙 문서화)version(또는 etag)를 추가해 오래된 재시도가 최신 데이터를 덮어쓰지 않도록 함UI가 필드 옆에 표시할 수 있도록 실행 가능한 메시지를 반환하세요:
{
"error": "VALIDATION_ERROR",
"message": "Please fix the highlighted fields.",
"fields": {
"companyName": "Company name is required",
"teamSize": "Must be a number"
}
}
또한 403(허용되지 않음), 409(충돌/잘못된 단계), **422(검증 실패)**를 구분해서 반환해 프론트엔드가 적절히 대응할 수 있게 하세요.
사용자와 관리자 기능을 분리하세요:
GET /api/admin/onboarding/users/{userId} 또는 오버라이드)는 역할 기반 접근 제어와 감사 로깅 필요이 경계는 권한 누수 방지와 지원·운영이 문제 있는 사용자를 도울 수 있게 합니다.
프론트엔드의 목표는 네트워크가 불안정해도 온보딩을 부드럽게 느끼게 하는 것입니다. 이는 예측 가능한 라우팅, 신뢰할 수 있는 재개 동작, 데이터 저장 시 명확한 피드백을 의미합니다.
단계별 하나의 URL(예: /onboarding/profile, /onboarding/billing)은 보통 가장 이해하기 쉽습니다. 브라우저 뒤/앞, 딥링크, 새로고침 안전성을 지원합니다.
아주 짧은 흐름에는 단일 페이지 내부 상태가 괜찮지만, 새로고침과 크래시, “계속하려면 링크 복사” 같은 시나리오에서 위험이 커집니다. 이 방식을 쓴다면 강력한 영속성(서버 저장 등)과 히스토리 관리를 신중히 설계하세요.
단계 완료와 최신 저장 데이터를 서버에 보관하세요. 페이지 로드 시 현재 온보딩 상태(현재 단계, 완료된 단계, 초안 값)를 가져와 그 상태로 렌더링하세요.
이렇게 하면:
낙관적 UI는 마찰을 줄여주지만 안전 장치가 필요합니다:
사용자가 돌아왔을 때 무조건 1단계로 보내지 마세요. 예: “60% 완료 — 이전 위치에서 계속하시겠어요?”와 같은 프롬프트를 제공하고 두 가지 액션 제시:
/onboarding으로 돌아가는 배너 유지)이 작은 터치는 포기율을 낮추면서도 즉시 모든 걸 끝내기 원치 않는 사용자를 존중합니다.
검증은 온보딩 흐름의 매끄러움을 결정합니다. 목표는 실수를 조기에 잡아 사용자의 흐름을 멈추지 않게 하고, 불완전하거나 의심스러운 데이터로부터 시스템을 보호하는 것입니다.
클라이언트 측 검증으로 명백한 오류를 네트워크 요청 전에 차단하세요. 이는 이탈을 줄이고 각 단계를 반응형으로 느끼게 합니다.
일반적인 체크는 필수 필드, 길이 제한, 기본 형식(이메일/전화), 간단한 교차 필드 규칙(비밀번호 확인) 등입니다. 메시지는 구체적으로(예: “유효한 업무용 이메일을 입력하세요”) 필드 옆에 배치하세요.
서버 측 검증을 진실의 근원으로 취급하세요. UI가 완벽히 검증하더라도 우회될 수 있습니다.
서버 검증은 다음을 강제해야 합니다:
필드별 구조화된 오류를 반환해 프론트엔드가 정확히 고칠 부분을 하이라이트할 수 있게 하세요.
이메일 중복, 초대 코드, 사기 신호, 문서 검증 같은 일부 검증은 외부 또는 지연 신호에 의존합니다.
이 경우 pending, verified, rejected 같은 명시적 상태와 명확한 UI 상태를 사용하세요. 검사가 보류 중이면 가능한 경우 사용자가 계속 진행할 수 있게 하고, 언제 통보될지 혹은 어떤 단계가 잠금 해제될지 알려주세요.
다단계 온보딩에서는 부분 데이터가 정상인 경우가 많습니다. 단계별로 다음 중 하나를 결정하세요:
in_progress로 표시현실적인 접근은 “항상 초안 저장, 완료 시에만 차단”입니다. 이는 재개를 지원하면서도 데이터 품질 기준을 유지합니다.
온보딩 분석은 두 가지 질문에 답해야 합니다: “사용자들이 어디서 막히는가?” 그리고 “완료를 개선하려면 어떤 변경이 필요할까?” 핵심은 모든 단계에서 작고 일관된 이벤트 집합을 추적해 흐름 변경 시에도 비교 가능하게 만드는 것입니다.
각 단계에 대해 동일한 핵심 이벤트를 추적하세요:
step_viewed (사용자가 단계를 봄)step_completed (사용자가 제출하고 검증을 통과)step_failed (사용자가 제출 시 검증 또는 서버 검사 실패)flow_completed (최종 성공 상태에 도달)각 이벤트에는 최소한의 안정적 컨텍스트를 포함하세요: user_id, flow_id, flow_version, step_id, step_index, session_id(한 번의 연속 세션과 여러 날에 걸친 세션을 구분하기 위해). 재개 지원 시 step_viewed에 resume=true/false를 포함하세요.
단계별 이탈을 측정하려면 동일한 flow_version에 대해 step_viewed 대 step_completed 수를 비교하세요. 소요 시간은 타임스탬프를 캡처해 계산:
step_viewed → step_completed까지의 시간step_viewed → 다음 step_viewed까지의 시간(사용자가 건너뛸 때 유용)시간 지표는 버전별로 그룹화하세요. 버전을 섞으면 개선 효과가 묻힐 수 있습니다.
카피나 단계 재배열을 A/B 테스트할 경우 분석 식별에 실험 정보를 포함하세요:
experiment_id와 variant_id 추가step_id는 안정적으로 유지step_id는 동일하게 유지하고 위치는 step_index로 표현완료율, 단계별 이탈, 단계별 중위수 소요 시간, 그리고 step_failed 메타데이터에서 추출한 “상위 실패 필드”를 보여주는 간단한 대시보드를 만드세요. CSV 내보내기 기능을 추가해 팀들이 분석 도구 접근 없이 스프레드시트로 공유할 수 있게 하세요.
다단계 온보딩 시스템은 결국 제품 변경, 지원 예외 처리, 안전한 실험을 위한 일상적 운영 제어가 필요합니다. 내부 관리자 영역을 작게라도 만들면 엔지니어링이 병목이 되는 걸 막을 수 있습니다.
권한 있는 직원이 온보딩 흐름과 단계를 생성·편집할 수 있는 간단한 “플로우 빌더”로 시작하세요.
각 단계는 다음을 편집 가능해야 합니다:
미리보기 모드를 추가해 최종 사용자가 보는 방식으로 렌더링해 혼란스러운 카피나 빠진 필드, 깨진 분기를 사전에 잡을 수 있게 하세요.
라이브 흐름을 바로 편집하지 마세요. 대신 버전으로 게시하세요:
롤아웃 방식:
이 방식은 위험을 줄이고 버전별 비교를 깨끗하게 합니다.
지원팀이 데이터베이스 수작업 없이 사용자를 도울 수 있게 하세요:
모든 관리자 행동은 누가 언제 무엇을 변경했는지(전후 값 포함)를 기록하세요. 권한은 보기 전용, 편집자, 게시자, 지원 오버라이드 같은 역할로 제한해 민감한 행동(예: 진행 리셋)이 통제되고 추적 가능하게 하세요.
다단계 온보딩을 배포하기 전에 두 가지를 가정하세요: 사용자는 예상치 못한 경로를 택할 것이고(예: 중간 이탈, 비정상 입력), 중간에 무언가가 실패할 것입니다(네트워크, 검증, 권한 등). 좋은 출시 체크리스트는 흐름이 올바른지 증명하고 사용자 데이터를 보호하며 현실이 계획과 어긋날 때 조기 경고를 줍니다.
워크플로 로직(상태와 전이)에 대한 단위 테스트로 시작하세요. 이 테스트는 각 단계가 다음과 같은지를 검증해야 합니다:
그다음 API 통합 테스트를 추가해 단계 페이로드 저장, 진행 재개, 잘못된 전이 거부 등을 검사하세요. 통합 테스트는 “로컬에서는 작동했지만 실제에선 안 되는” 인덱스 누락, 직렬화 버그, 프론트·백 버전 불일치 등을 잡아줍니다.
E2E 테스트는 최소한 다음을 포함하세요:
E2E 시나리오는 작고 의미 있게 유지하세요—대부분 사용자와 매출/활성화에 영향을 주는 몇 가지 경로에 집중하세요.
최소 권한 원칙을 적용하세요: 온보딩 관리자라고 해서 자동으로 전체 사용자 레코드에 접근할 필요는 없습니다. 서비스 계정은 필요한 테이블과 엔드포인트만 접근하게 제한하세요.
민감 토큰, 규제 대상 필드 등은 암호화하고 로그는 데이터 유출 위험으로 간주하세요. 원시 폼 페이로드를 로그에 남기지 말고, 디버깅을 위해 일부를 로깅해야 한다면 필드를 일관되게 마스킹하세요.
온보딩을 제품 퍼널과 API 관점에서 계측하세요.
단계별 오류, 저장 지연(p95/p99), 재개 실패 등을 추적하고, 배포 후 완료율 급락, 특정 단계의 검증 실패 급증, API 오류율 상승 같은 알림을 설정하세요. 이렇게 하면 지원 티켓이 쌓이기 전에 문제를 고칠 수 있습니다.
단계 기반 온보딩 시스템을 처음부터 구현하면 많은 시간이 동일한 빌딩 블록(단계 라우팅, 영속성, 검증, 진행/상태 로직, 버전·롤아웃을 위한 관리자 인터페이스)에 쓰입니다. Koder.ai는 채팅 기반 스펙으로 전체 스택 웹 앱을 생성해 이러한 부분을 더 빠르게 프로토타입하고 배포하는 데 도움을 줄 수 있습니다—일반적으로 React 프런트엔드, Go 백엔드, PostgreSQL 데이터 모델로 흐름·단계·응답을 깔끔하게 매핑합니다.
Koder.ai는 소스 코드 내보내기, 호스팅/배포, 스냅샷과 롤백을 지원하므로 온보딩 버전을 안전하게 반복하고(롤아웃이 완료율에 악영향을 미치면 빠르게 복구) 실험할 때 유용합니다.
설치가 한 번의 폼으로 끝나지 않을 때—특히 워크스페이스 생성 같은 전제 조건, 이메일/전화/KYC 같은 검증, 청구/통합 같은 구성, 또는 역할·플랜·지역에 따른 분기 로직이 필요할 때 다단계 흐름을 사용하세요.
사용자가 맥락을 알아야 올바르게 입력할 수 있다면 단계를 나누면 오류와 이탈을 줄일 수 있습니다.
성공의 정의는 화면을 끝까지 본 것이 아니라 사용자가 가치를 얻는 것입니다. 일반적인 지표:
또한 사용자가 떠났다가 돌아와도 진행이 유지되는지(재개 성공)를 추적하세요.
사용자 유형(예: 셀프서비스 신규가입, 초대받은 사용자, 관리자에 의해 생성된 계정)을 먼저 목록화하고 각 유형에 대해 다음을 정의하세요:
그다음 각 페르소나가 올바른 다음 단계로 가도록 스킵 규칙을 인코딩하면 복잡한 미로를 만들지 않으면서 맞춤형 흐름을 제공할 수 있습니다.
“완료”를 UI의 화면 완료 여부가 아니라 백엔드에서 검사 가능한 기준으로 작성하세요. 예시:
이렇게 하면 UI가 바뀌어도 서버가 온보딩 완료 여부를 신뢰성 있게 판단할 수 있습니다.
대부분의 경우는 선형 백본을 두고, 경험이 실제로 달라질 때만 조건부 분기를 추가하세요(역할, 플랜, 지역, 사용 사례 등).
분기는 if/then 규칙으로 문서화하세요(예: “If region = EU → show VAT step”). 단계 이름은 동사 중심의 행동 지향으로 유지합니다(예: “Confirm email”, “Invite teammates”).
대부분의 경우 단계마다 하나의 URL(예: /onboarding/profile)을 사용하는 것이 더 낫습니다. 새로고침 안전성, 이메일의 딥링크, 브라우저 뒤로/앞으로 기능을 자연스럽게 지원합니다.
페이지 한 장으로 내부 상태만 관리하는 방식은 화면이 아주 짧은 흐름에만 적합합니다. 그럴 경우 강한 영속성(서버 저장 등)이 필요합니다.
서버를 **진실의 근원(source of truth)**으로 취급하세요:
이렇게 하면 새로고침 안전성, 기기 간 재개, 흐름 업데이트 시 안정성이 보장됩니다.
실용적인 최소 데이터 모델:
흐름 정의는 버전 관리하세요. 진행 중인 사용자가 새로 추가/재배열된 단계 때문에 깨지지 않도록 flow_version_id 같은 식별자를 Progress가 참조하게 만듭니다.
온보딩을 상태 머신처럼 다루어 허용된 전이만 허용하세요(예: start_step, save_draft, submit_step, go_back).
단계는 다음 두 조건을 모두 만족해야 “완료”로 간주합니다:
이전 단계의 답변이 바뀌면 다운스트림 단계들을 재평가해 로 표시하거나 로 되돌리세요.
기본적인 필수 엔드포인트 예시:
GET /api/onboarding (현재 단계 + 진행률 + 렌더링에 필요한 초안값)PUT /api/onboarding/steps/{stepKey} with mode: draft|submitPOST /api/onboarding/complete (서버가 모든 필수 조건을 검증)신뢰성 기능으로는 재전송/더블서브밋을 막기 위한 처리, 를 통한 단계 페이로드의 전체 덮어쓰기(또는 병합 규칙 문서화), 그리고 /버전 검사를 통한 낡은 데이터 덮어쓰기 방지 등을 추가하세요.
needs_reviewin_progressIdempotency-KeyPUT /steps/{stepKey}etag응답은 필드 단위의 구조화된 오류와 HTTP 상태 코드(403/409/422 등)를 적절히 나눠서 반환해 프론트엔드가 정확히 대응할 수 있게 하세요.