2025년 6월 05일·7분
고객 채택 헬스 점수 모니터링 웹앱 구축 방법
제품 사용을 추적하고 채택 헬스 점수를 계산해 팀에게 리스크를 알리는 웹앱 구축 방법 — 대시보드, 데이터 모델, 구현 팁 포함
목표와 채택 신호 정의하기
고객 채택 헬스 점수를 만들기 전에, 이 점수가 비즈니스에서 무엇을 할 것인지 결정하세요. 이탈 리스크 알림을 트리거하기 위한 점수는 온보딩, 고객 교육, 제품 개선을 안내하기 위한 점수와 다르게 설계되어야 합니다.
제품에서 “채택”이 의미하는 바를 정의하세요
채택은 단순히 “최근에 로그인했다”가 아닙니다. 고객이 가치를 얻고 있음을 진짜로 보여주는 몇 가지 행동을 적으세요:
- 활성화(Activation): 사용자가 의미 있는 결과에 처음 도달한 순간(예: “팀원 초대”, “데이터 소스 연결”, “리포트 게시”).
- 핵심 동작(Core actions): 성공 계정과 상관관계가 있는 반복 가능한 고신호 행동(예: 주간 내보내기, 자동화 실행, 여러 사용자가 조회한 대시보드).
- 유지(Retention): 제품에 맞는 주기(일간/주간/월간)로 지속 사용되며, 이상적으론 계정 내 여러 사용자에 걸쳐 발생하는 것.
이것들이 기능 사용 분석과 이후 코호트 분석을 위한 초기 채택 신호가 됩니다.
앱이 허용해야 할 결정을 나열하세요
점수가 바뀔 때 어떤 일이 일어나는지 명확히 하세요:
- 계정이 임계값 아래로 떨어지면 누가 알림을 받나요?
- 어떤 플레이북을 실행하나요(아웃리치, 교육, 지원 체크인)?
- 제품 채택 모니터링에 어떤 인사이트가 필요한가요(마찰 지점, 저활용 기능, TTV)?
결정을 명확히 못하면 해당 메트릭은 아직 추적하지 마세요.
사용자, 역할, 시간 윈도우를 식별하세요
고객 성공 대시보드를 누가 사용할지 명확히 하세요:
- CS 매니저는 우선순위와 계정 컨텍스트가 필요합니다.
- 제품팀은 패턴, 코호트, 기능 수준의 변화를 봐야 합니다.
- 지원팀은 티켓과 사건 주위의 최근 활동이 필요합니다.
- 리더십은 이해하기 쉬운 롤업과 추세를 원합니다.
표준 윈도우(예: 지난 7/30/90일)를 선택하고 수명주기 단계(체험, 온보딩, 안정화, 갱신)를 고려하세요. 이렇게 하면 신규 계정과 성숙 계정을 비교하는 실수를 피할 수 있습니다.
성공 기준 설정
헬스 스코어 모델의 “완료”를 정의하세요:
- 정확성: 현재 접근보다 리스크 및 확장 신호를 더 잘 예측하는가?
- 설명 가능성: CSM이 1분 안에 점수가 높은/낮은 이유를 설명할 수 있는가?
- 사용 편의성: 시간을 절약하고 일관된 행동을 유도하는가?
이 목표들이 이벤트 트래킹, 스코어링 로직, 점수 주변에 구축할 워크플로우를 결정합니다.
헬스 점수에 포함할 메트릭 선택
메트릭 선택은 헬스 점수가 유용한 신호가 될지 아니면 노이즈가 될지를 가릅니다. 실제 채택을 반영하는 소수의 지표에 집중하세요—단순 활동이 아닙니다.
제품 채택 신호로 시작하세요
사용자가 반복적으로 가치를 얻고 있는지를 보여주는 메트릭을 고르세요:
- 로그인 / 활성 사용자: 예: 주간 활성 사용자(WAU)와 지난 4–8주 추세
- 활동일수: 한 주/한 달 동안 계정이 활동한 서로 다른 일수(한 번의 긴 세션으로 인한 오탐을 줄임)
- 기능 깊이: 성공과 상관관계가 높은 “가치 기능”의 사용(모든 버튼 클릭이 아님)
- 연동 연결: 통합이 전환 비용을 높이거나 핵심 워크플로를 여는 경우
- 좌석 활용도: 구매한 좌석 중 초대된/활성화된/실제로 활동하는 비율
리스트를 간결하게 유지하세요. 메트릭이 왜 중요한지 한 문장으로 설명할 수 없다면 핵심 입력이 아닙니다.
비즈니스 컨텍스트 추가(점수가 불공정해지지 않도록)
채택은 컨텍스트와 함께 해석되어야 합니다. 3좌석 팀은 500좌석 롤아웃과 다르게 행동합니다.
일반적인 컨텍스트 신호:
- 요금제 티어 및 기능 권한
- 계약 규모 / ARR 밴드
- 수명주기 단계: 체험 vs 신규 유료 vs 갱신 기간
이들은 점수에 직접 점수를 더할 필요는 없지만 세그먼트별로 현실적인 기대치와 임계값을 설정하는 데 도움을 줍니다.
선행 지표 vs 후행 지표 결정
유용한 점수는 다음을 섞습니다:
- 선행 지표(미래 성공 예측): 활성일수 증가, 온보딩 완료, 첫 통합 연결
- 후행 지표(결과 확인): 갱신, 확장, 장기 유지
후행 지표에 과도한 가중치를 주지 마세요; 이미 일어난 일을 말해줄 뿐입니다.
선택적: 정성적 입력(주의해서 사용)
가능하다면 NPS/CSAT, 지원 티켓 양, CSM 노트는 뉘앙스를 더해줄 수 있습니다. 이들은 수정자나 플래그로 사용하세요—정성 데이터는 드물고 주관적일 수 있기 때문에 기반으로 사용하면 안 됩니다.
간단한 데이터 딕셔너리 만들기
차트를 만들기 전에 이름과 정의를 정렬하세요. 경량 데이터 딕셔너리는 다음을 포함해야 합니다:
- 메트릭 이름(예:
active_days_28d) - 명확한 정의(무엇이 포함되고 제외되는지)
- 시간 윈도우와 갱신 빈도
- 소스 시스템(제품 이벤트, CRM, 지원)
이것은 대시보드와 알림을 구현할 때 발생하는 “같은 메트릭, 다른 의미” 혼란을 막습니다.
설명 가능한 헬스 점수 모델 설계
팀이 점수를 신뢰하려면 모델이 설명 가능해야 합니다. CSM에게 1분, 고객에게 5분 안에 설명할 수 있는 모델을 목표로 하세요.
먼저 단순하게: 가중치 포인트(ML 이전)
투명한 규칙 기반 점수로 시작하세요. 소수의 채택 신호(예: 활성 사용자, 핵심 기능 사용, 연결된 통합)를 선택하고 제품의 "aha" 모멘트를 반영하는 가중치를 부여하세요.
예시 가중치:
- 좌석당 주간 활성 사용자: 0–40 포인트
- 핵심 기능 사용 빈도: 0–35 포인트
- 사용된 기능의 폭: 0–15 포인트
- 마지막 의미 있는 활동 이후 시간: 0–10 포인트
가중치는 방어하기 쉬운 수준으로 유지하세요. 완벽한 모델을 기다리지 말고 나중에 재검토할 수 있습니다.
편향을 줄이기 위한 정규화
원시 카운트는 작은 계정을 벌주고 큰 계정은 납작하게 보이게 합니다. 필요한 곳에서 메트릭을 정규화하세요:
- 좌석당(사용량 / 라이선스 좌석)
- 계정 연령별(신규 vs 성숙)
- 요금제 티어별(기능 가용성)
이렇게 하면 고객 채택 헬스 점수가 크기가 아닌 행동을 반영합니다.
Green/Yellow/Red 정의와 근거 문서화
임계값을 설정하세요(예: Green ≥ 75, Yellow 50–74, Red < 50) 그리고 각 컷오프가 존재하는 이유를 문서화하세요. 임계값을 기대 결과(갱신 리스크, 온보딩 완료, 확장 준비 상태)에 연결하고 내부 문서나 /blog/health-score-playbook에 메모를 보관하세요.
설명 가능하게 만들기: 기여자와 추세
각 점수는 다음을 보여줘야 합니다:
- 상위 3개 기여자(도움이 된/해가 된 항목)
- 기간별 변화(지난 7/30일)
- 평이한 언어 요약(예: “기능 X 사용이 주간 대비 35% 감소”)
반복을 위한 계획: 모델 버전 관리
스코어링을 제품처럼 다루세요. 버전 관리(v1, v2)를 하고 영향(이탈 리스크 알림의 정확도 향상 여부, CSM의 반응 속도 등)을 추적하세요. 각 계산에 모델 버전을 저장해 시간이 지나도 비교가 가능하게 하세요.
제품 이벤트 및 데이터 소스 계측
헬스 점수는 그 뒤에 있는 활동 데이터만큼 신뢰할 수 있습니다. 스코어링 로직을 만들기 전에 올바른 신호가 시스템 전반에 걸쳐 일관되게 캡처되는지 확인하세요.
이벤트 소스 선택
대부분의 채택 프로그램은 다음을 혼합해 사용합니다:
- 프런트엔드 이벤트(페이지 뷰, 클릭, 기능 상호작용)
- 백엔드 액션(API 호출, 완료된 작업, 생성된 레코드)
- 청구(요금제, 갱신, 결제 상태, 좌석 수)
- 지원 및 성공 도구(티켓, CSAT, 온보딩 마일스톤)
실용적인 규칙: 중요한 액션은 서버사이드에서 추적하세요(스푸핑하기 어렵고 애드블로커 영향을 덜 받음). 프런트엔드 이벤트는 UI 참여와 발견 용도로 사용하세요.
명확한 이벤트 스키마 정의
일관된 계약을 유지해 이벤트를 쉽게 조인하고 쿼리하며 설명할 수 있게 하세요. 공통 베이스라인 예:
event_nameuser_idaccount_idtimestamp(UTC)properties(feature, plan, device, workspace_id 등)
event_name에 대해 통제된 어휘를 사용하고(예: project_created, report_exported) 간단한 트래킹 플랜에 문서화하세요.
SDK vs 서버사이드(또는 둘 다) 결정
- SDK 트래킹은 빠르게 출시할 수 있고 UI 이벤트에 적합합니다.
- 서버사이드 트래킹은 시스템 오브레코드 액션에 더 좋습니다.
많은 팀이 둘 다 사용하지만, 동일한 실세계 행동을 이중 집계하지 않도록 하세요.
아이덴티티 처리
헬스 점수는 보통 계정 수준으로 롤업되므로 사용자→계정 매핑이 신뢰할 수 있어야 합니다. 다음을 계획하세요:
- 여러 계정에 속한 사용자
- 계정 병합(인수, 워크스페이스 통합)
- 가입 전 익명화된 ID(가입 후 안전한 병합)
데이터 품질 검사 내장
최소한 누락 이벤트, 중복 급증, 타임존 일관성(UTC 저장; 표시 시 변환)을 모니터링하세요. 이상을 조기에 플래그해 트래킹 오류 때문에 이탈 리스크 알림이 발동하지 않도록 합니다.
데이터 모델링과 저장
고객 채택 헬스 점수 앱은 “누가 언제 무엇을 했는가”를 얼마나 잘 모델링하느냐에 따라 성공 여부가 갈립니다. 목표는 자주 묻는 질문을 빠르게 답변할 수 있게 하는 것입니다: 이 계정은 이번 주 어떻게 지내나? 어떤 기능이 오르내리나? 좋은 데이터 모델링은 스코어링, 대시보드, 알림을 단순하게 만듭니다.
모델링할 핵심 엔터티
소스 오브 트루스 표 몇 개로 시작하세요:
- Accounts: account_id, plan, segment, lifecycle_stage, CSM owner
- Users: user_id, account_id, role/persona, created_at, status
- Subscriptions(또는 Contracts): account_id, start/end, seats, MRR, renewal_date
- Features: feature_id, name, category(activation, collaboration, admin 등)
- Events: event_id, account_id, user_id, feature_id(nullable), event_name, timestamp, properties
- Scores: account_id, score_date(또는 computed_at), overall_score, component_scores, explanation_fields
이 엔터티들에 안정적인 ID(account_id, user_id)를 everywhere 사용해 일관성을 유지하세요.
저장 분리: 관계형 + 애널리틱스
관계형 DB(예: Postgres)는 계정/사용자/구독/스코어 같은 자주 업데이트하고 조인하는 항목에 사용하세요.
고볼륨 이벤트는 웨어하우스(예: BigQuery/Snowflake/ClickHouse)에 저장해 대시보드와 코호트 분석이 반응형으로 동작하게 하세요.
성능을 위한 집계 저장
원시 이벤트에서 매번 재계산하는 대신 다음을 유지하세요:
- 일별 계정 요약(계정당 일별 한 행): 활성 사용자, 핵심 이벤트 카운트, 마지막 활동, 채택 마일스톤
- 기능 카운터: 계정/일/기능별 사용 횟수, 고유 사용자 수, 가능하면 사용 시간
이 테이블들은 추세 차트, “무엇이 변했나” 인사이트, 헬스 점수 구성요소를 지원합니다.
보존, 파티셔닝, 쿼리 성능
대규모 이벤트 테이블은 보존 정책(예: 원시 13개월, 집계는 더 오래)을 계획하고 날짜로 파티셔닝하세요. account_id와 timestamp/date로 클러스터/인덱스 해 계정별 시간 쿼리를 가속하세요.
관계형 테이블에서는 자주 사용하는 필터와 조인에 대해 인덱스하세요: account_id, 요약 테이블의 (account_id, date) 등과 외래키로 데이터 무결성을 유지하세요.
웹앱 아키텍처 계획
대시보드 배포
인프라를 직접 설정하지 않고도 채택 모니터링 앱을 배포하고 호스팅하세요.
아키텍처는 v1을 빠르게 출시하고 리팩토링 없이 성장할 수 있게 해야 합니다. 실질적으로 필요한 이동 부품의 수를 먼저 결정하세요.
모놀리스 vs 서비스(초기에는 단순하게)
대부분 팀은 모듈형 모놀리스를 선택하는 것이 빠릅니다: 인게스천, 스코어링, API, UI 같은 경계는 분명하되 단일 코드베이스와 배포로 운영상의 복잡함을 줄입니다.
독립적 확장 필요성, 데이터 격리, 별도 팀이 있는 경우에만 서비스를 도입하세요. 조기 분리는 실패 지점을 늘리고 반복 속도를 늦춥니다.
핵심 컴포넌트 정의
최소한 다음 책임을 계획하세요(초기에는 하나의 앱에 같이 있어도 됨):
- Ingestion: 제품 이벤트 수신(SDK, Segment, webhook, 배치 임포트)
- Aggregation: 원시 이벤트를 계정/사용자 일별/주별 사실로 전환
- Scoring: 고객 채택 헬스 점수와 설명을 계산
- API: UI와 통합을 위한 스코어, 추세, “이유” 인사이트 제공
- UI: 계정 뷰, 코호트, 드릴다운을 포함한 고객 성공 대시보드
빠른 프로토타입을 원하면 과도한 인프라 없이 작업할 수 있는 'vibe-coding' 접근이 유용합니다. 예를 들어 Koder.ai는 엔터티(accounts, events, scores), 엔드포인트, 화면 설명으로 React 기반 UI와 Go + PostgreSQL 백엔드를 생성해 v1을 빠르게 세팅할 수 있게 도와줍니다.
스케줄 잡 vs 스트리밍
대부분의 채택 모니터링에는 배치 스코어링(예: 시간별/일별)이 충분하며 운영이 훨씬 단순합니다. 스트리밍은 실시간 알림(갑작스런 사용량 급감)이나 매우 높은 이벤트 볼륨이 필요할 때 타당합니다.
실용적인 하이브리드: 이벤트는 연속적으로 수집하되 집계/스코어링은 스케줄로 수행하고, 소수의 긴급 신호에만 스트리밍을 예약하세요.
환경, 시크릿, 비기능 요구사항
초기에 dev/stage/prod를 설정하고 stage에는 샘플 계정을 시딩해 대시보드를 검증하세요. 관리형 시크릿 스토어를 사용하고 자격증명 회전을 설정하세요.
사전 문서화할 요구사항: 예상 이벤트 볼륨, 점수 신선도(SLA), API 지연 목표, 가용성, 데이터 보존, 개인정보 제약(PII 처리 및 접근 제어).
데이터 파이프라인과 스코어링 잡 구축
헬스 점수는 이를 생산하는 파이프라인만큼 신뢰할 수 있습니다. 스코어링을 재현 가능하고 관측 가능하게, 그리고 “왜 이 계정이 오늘 떨어졌나?”라는 질문에 답할 수 있게 만드세요.
간단한 파이프라인: raw → validated → aggregates
다음과 같은 단계로 좁혀가세요:
- Raw events: 앱, 모바일, 통합, 청구/CRM 익스포트에서의 추가 전용 수집
- Validated events: 스키마 체크(필수 필드, 타입), 아이덴티티 체크(사용자→계정 매핑), 중복 제거를 통과한 이벤트
- Daily aggregates: 계정(및 선택적으로 워크스페이스/팀)별 요약: 활성 사용자, 핵심 이벤트 카운트, TTV 마일스톤, 추세 델타
이 구조는 스코어링 작업이 깨끗하고 컴팩트한 테이블에서 동작하게 해 빠르고 안정적으로 만듭니다.
재계산 스케줄과 백필
점수가 얼마나 신선해야 하는지 결정하세요:
- 시간 단위 스코어링은 CSM이 빠르게 행동해야 하는 경우
- 일 단위 스코어링은 SMB/셀프서비스에 보통 충분하며 비용을 낮춤
스케줄러는 백필(예: 지난 30/90일 재처리)을 지원해야 합니다. 트래킹 수정, 가중치 변경, 새 신호 추가 시 필수입니다. 백필은 응급 스크립트가 아니라 일등 시민 기능이어야 합니다.
멱등성: 중복 집계를 피하세요
스코어링 작업은 재시도됩니다. 임포트는 다시 실행됩니다. 웹훅은 두 번 전달될 수 있습니다. 이를 염두에 두세요.
- 이벤트에는 idempotency key(event_id 또는 timestamp+user_id+event_name+properties의 안정적 해시)를 사용하고 검증 레이어에서 유니크하게 하세요.
- 애그리게이트는
(account_id, date)로 업서트해 재계산이 이전 결과를 대체하도록 하세요.
모니터링 및 이상치 검사
운영 모니터링을 추가하세요:
- 잡 성공/실패 및 재시도 횟수
- 데이터 지연(최신 집계가 얼마나 뒤처졌는지)
- 볼륨 이상치(이벤트, 활성 사용자, 핵심 액션의 급감/급증)
간단한 임계값(예: “이벤트가 7일 평균 대비 40% 감소”)도 트래킹 실패로 인한 침묵 실패를 막습니다.
모든 점수에 대한 감사 로그
계정별 스코어링 실행마다 입력 메트릭, 파생 특성(예: 주간 대비 변화), 모델 버전, 최종 스코어를 저장하세요. CSM이 “왜?” 버튼을 클릭하면 로그 뒤져 역추적하는 대신 정확히 무엇이 언제 바뀌었는지 보여줄 수 있어야 합니다.
헬스 및 인사이트를 위한 안전한 API 만들기
빌드 비용 절감
빌드 과정을 공유하거나 팀원을 Koder.ai에 추천하면 크레딧을 받으세요.
웹앱은 API에 의해 좌우됩니다. 스코어링 작업, UI, 하류 도구(CS 플랫폼, BI, 데이터 익스포트) 간의 계약입니다. 빠르고 예측 가능하며 기본적으로 안전한 API를 목표로 하세요.
실제 워크플로우를 지원하는 핵심 엔드포인트
고객 성공이 채택을 탐색하는 방식을 중심으로 엔드포인트를 설계하세요:
- Account health:
GET /api/accounts/{id}/health는 최신 스코어, 상태 밴드(예: Green/Yellow/Red), 마지막 계산 시각을 반환 - Trends:
GET /api/accounts/{id}/health/trends?from=&to=는 기간별 스코어와 주요 메트릭 델타 반환 - Drivers(“왜”):
GET /api/accounts/{id}/health/drivers는 상위 긍정/부정 요인을 표시(예: “좌석당 주간 활성 사용자 35% 하락”) - Cohorts:
GET /api/cohorts/health?definition=는 코호트 분석 및 동료 벤치마크 - Exports:
POST /api/exports/health는 일관된 스키마의 CSV/Parquet 생성
필터링, 페이징, 캐싱
리스트 엔드포인트를 쉽게 슬라이싱하세요:
- 필터:
plan,segment,csm_owner,lifecycle_stage,date_range - 페이징: 데이터 변경 시 안정적인 커서 기반 페이징(
cursor,limit) 사용 - 캐싱: 코호트 롤업, 추세 시리즈처럼 비용이 큰 쿼리는 캐시하고
ETag/If-None-Match반환으로 반복 로드를 줄이세요. 캐시 키는 필터와 권한을 인지해야 합니다.
역할 기반 접근 제어로 보안
데이터를 계정 수준에서 보호하세요. RBAC(예: Admin, CSM, Read-only)를 구현하고 모든 엔드포인트에서 서버 측으로 강제하세요. CSM은 자신이 담당한 계정만 볼 수 있어야 합니다; 재무 관련 역할은 요금제 수준의 롤업을 보되 사용자 수준의 세부정보는 보지 못하게 할 수 있습니다.
항상 설명 가능성 반환
수치적 헬스 점수 외에 “왜” 필드(상위 기여자, 영향을 받은 메트릭, 비교 기준(이전 기간, 코호트 중앙값))를 함께 반환하세요. 이렇게 하면 제품 채택 모니터링이 단순 리포팅이 아니라 행동 유도로 바뀌고 고객 성공 대시보드가 신뢰받습니다.
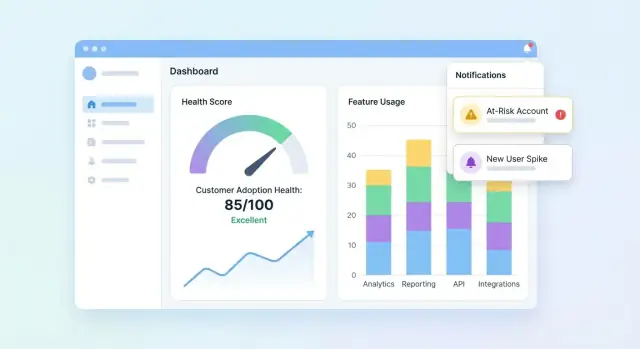
대시보드 및 계정 뷰 디자인
UI는 세 가지 질문에 빨리 답해야 합니다: 누가 건강한가? 누가 미끄러지는가? 왜 그런가? 포트폴리오를 요약하는 대시보드로 시작해 사용자가 계정을 드릴다운해 점수 뒤 이야기를 이해하게 하세요.
포트폴리오 대시보드 필수 요소
CS 팀이 몇 초 안에 훑어볼 수 있는 타일과 차트를 포함하세요:
- 스코어 분포(히스토그램 또는 Healthy / Watch / At-risk 버킷)
- 위험 계정 리스트(계정, 담당자, 스코어, 마지막 활동, 상위 드라이버)
- 스코어 추세(라인 차트) 및 세그먼트 필터 옵션
위험 계정 리스트는 클릭 가능하게 해 바로 계정의 변화 원인을 볼 수 있게 하세요.
계정 뷰: 점수를 설명하세요
계정 페이지는 채택의 타임라인처럼 읽히게 하세요:
- 타임라인(온보딩 단계 완료, 통합 연결, 관리자 변경, 주요 기능 첫 사용 등)
- 핵심 메트릭(활성 사용자, 핵심 기능 액션, 마지막 의미 있는 활동 이후 시간)
- 기능 채택 분해(어떤 기능이 채택되었고, 무시되었고, 퇴행하는지)
“왜 이 점수인가?” 패널을 추가하세요: 점수 클릭 시 긍정/부정 신호와 평이한 언어 설명을 표시합니다.
코호트 및 세그먼트 뷰
팀이 계정을 관리하는 방식과 일치하는 코호트 필터를 제공하세요: 온보딩 코호트, 요금제 티어, 업종. 각 코호트에 추세선과 주요 움직임 계정의 작은 표를 함께 보여 비교와 패턴 발견을 돕습니다.
접근성 있고 신뢰할 수 있는 시각화
명확한 레이블과 단위를 사용하고 애매한 아이콘을 피하세요. 색상에 민감한 표시기(예: 텍스트 라벨 + 모양)를 제공하고 차트를 의사결정 도구로 취급해 스파이크에 주석을 달고 날짜 범위를 표시하며 드릴다운 동작을 일관되게 만드세요.
알림, 작업, 워크플로 추가
헬스 점수는 행동으로 이어질 때만 유용합니다. 알림과 워크플로는 “흥미로운 데이터”를 시기적절한 아웃리치, 온보딩 수정, 제품 넛지로 바꿉니다—팀이 대시보드를 계속 지켜보지 않아도 됩니다.
실제 리스크에 맞춘 알림 규칙 정의
고신호 트리거 소수로 시작하세요:
- 스코어 하락(예: 주간 대비 15포인트 하락)
- Red 상태 진입(중요 임계값 통과)
- 갑작스런 사용량 감소(핵심 기능 사용이 기준선 아래로 떨어짐)
- 온보딩 단계 실패(체크리스트 항목 정체, 통합 미완료)
모든 규칙을 명시적이고 설명 가능하게 만드세요. “나쁜 헬스” 대신 “기능 X에서 7일간 활동 없음 + 온보딩 미완료”처럼 구체적으로 알리세요.
채널 선택과 설정 가능하게 하기
팀마다 일하는 방식이 다르므로 채널 지원과 선호 설정을 제공하세요:
- 이메일: 계정 담당자 및 매니저용
- Slack: 팀 가시성과 빠른 대응용
- 인앱 작업: 고객 성공 대시보드 내부에서 작업이 누락되지 않도록
각 팀이 누가 알림을 받는지, 어떤 규칙이 활성화되는지, 어떤 임계값이 "긴급"인지를 구성할 수 있게 하세요.
잡음을 줄이기 위한 가드레일
알림 피로는 채택 모니터링을 망칩니다. 다음과 같은 제어를 추가하세요:
- 쿨다운 윈도우(같은 계정에 대해 N시간/일 동안 재알림 금지)
- 최소 데이터 임계값(계정에 최근 데이터가 너무 적으면 알림 건너뛰기)
- 배치/다이제스트(긴급하지 않은 신호는 일일/주간 요약으로 묶기)
컨텍스트와 다음 단계 제공
각 알림은 무엇이 바뀌었는지, 왜 중요한지, 다음에 무엇을 할지를 답해야 합니다. 최근 점수 드라이버, 짧은 타임라인(예: 지난 14일), 추천 작업(“온보딩 콜 예약”, “통합 가이드 전송”)을 포함하세요. 계정 뷰(/accounts/{id})로 링크하세요.
결과 추적으로 루프 종료
알림을 작업 항목으로 취급해 상태를 추적하세요: acknowledged, contacted, recovered, churned. 결과 보고는 규칙 정제, 플레이북 개선, 헬스 점수가 측정 가능한 유지효과를 내는지 증명하는 데 도움이 됩니다.
데이터 품질, 개인정보, 거버넌스 보장
헬스 스코어 v1 출시
스캐폴딩 대신 채팅으로 헬스 스코어 아이디어를 실제 대시보드로 전환하세요.
신뢰할 수 없는 데이터 위에 세운 헬스 점수는 팀의 신뢰를 잃고 행동을 멈추게 합니다. 품질, 개인정보, 거버넌스를 제품 기능처럼 다루세요.
자동화된 데이터 검사 도입
각 핸드오프(ingest → warehouse → scoring output)에서 경량 검증을 시작하세요. 몇 가지 고신호 테스트가 대부분 문제를 조기에 포착합니다:
- 스키마 체크: 예상 컬럼 존재 여부, 타입 변화, 열거형 값 유효성
- 범위 체크: 불가능한 값(음수 세션, 미래 타임스탬프) 즉시 실패
- 널 체크: 필수 필드(
account_id,event_name,occurred_at)는 비어있으면 안 됨
테스트 실패 시 스코어링 잡을 차단하거나 결과를 “stale”로 표시해 파이프라인 장애로 인해 오도된 이탈 리스크 알림이 발생하지 않게 하세요.
일반적인 엣지 케이스를 명시적으로 처리하세요
헬스 스코어는 “이상하지만 정상”인 시나리오에서 흔히 흔들립니다. 다음에 대한 규칙을 정의하세요:
- 데이터가 적은 신규 계정: “데이터 부족” 표시 혹은 램프업 기준선을 사용(낮은 점수로 처벌하지 않음)
- 계절성 사용: 범용 임계값 대신 계정의 이전 기간이나 코호트 벤치마크와 비교
- 아웃리지 및 트래킹 갭: 영향을 받은 윈도우를 플래그하고 시스템 다운타임으로 고객을 불이익 주지 않기
권한 및 개인정보 보호 제어 추가
기본적으로 PII를 제한하세요: 제품 채택 모니터링에 필요한 최소한만 저장하세요. 웹앱에서 역할 기반 접근을 적용하고 누가 데이터를 조회/내보냈는지 로깅하며, 필드가 필요하지 않으면(예: CSV 다운로드에서 이메일) 익스포트 시 마스킹하세요.
런북과 거버넌스 습관 만들기
사건 대응 런북을 짧게 작성하세요: 스코어링 일시중지, 데이터 백필, 히스토리 재실행 방법. 고객 성공 메트릭과 점수 가중치를 정기적으로(월간/분기별) 검토해 제품 진화에 따른 드리프트를 방지하세요. 프로세스 정렬을 위해 내부 체크리스트를 /blog/health-score-governance에 링크하세요.
검증, 반복, 확장
검증은 헬스 점수가 단순한 “예쁜 차트”에서 실제 행동을 이끄는 신뢰 가능한 도구로 전환되는 단계입니다. 첫 버전을 가설로 취급하고 반복하세요.
파일럿 실행 및 사람의 판단과 보정
20–50개 계정(세그먼트별로)을 파일럿 그룹으로 시작하세요. 각 계정에 대해 점수와 리스크 이유를 CSM의 평가와 비교하세요.
패턴을 찾으세요:
- 점수가 CSM 판단보다 지속적으로 높거나 낮은지(보정)
- 오탐(리스크 표시는 많지만 계정이 괜찮음) vs 미스(건강해 보이지만 이탈하는 경우)
- 설명이 현실과 맞지 않는 이유(설명 가능성의 격차)
실제로 유용한지 측정하세요
정확성도 중요하지만, 유용성이 실질적 이익을 만듭니다. 다음 운영 결과를 추적하세요:
- 리스크 감지 시간(문제를 얼마나 빨리 포착하나)
- 아웃리치 성공률(리스크 계정 중 개입 후 개선 비율)
- 이탈 감소의 프록시(갱신 가능성 변화, 확장 신호, 지원 부담 변화)
변경사항을 안전하게 테스트(버전 관리)
임계값, 가중치 또는 신호를 변경할 때는 새 모델 버전으로 취급하세요. A/B 테스트로 버전을 비교하거나 유사 코호트에서 테스트하고, 점수가 시간에 따라 왜 바뀌었는지 설명할 수 있도록 과거 버전을 보관하세요.
UI 내에서 피드백 수집
“점수가 잘못된 것 같습니다”와 이유(예: “최근 온보딩 완료 반영 안 됨”, “사용량이 계절적임”, “잘못된 계정 매핑”) 같은 간단한 피드백 컨트롤을 추가하세요. 이 피드백을 백로그로 보내고 계정 및 점수 버전 태그를 달아 빠르게 디버깅하세요.
로드맵과 함께 확장
파일럿이 안정되면 확장 작업을 계획하세요: 더 깊은 통합(CRM, 청구, 지원), 세분화(요금제, 업종, 수명주기), 자동화(작업 및 플레이북), 팀이 엔지니어링 없이 뷰를 커스터마이즈할 수 있는 셀프서비스 설정.
확장 시에도 빌드/반복 주기를 짧게 유지하세요. 팀들은 종종 Koder.ai를 사용해 새로운 대시보드 페이지를 빠르게 생성하고 API 형태를 다듬거나 작업/익스포트/롤백 준비된 릴리스를 챗으로 바로 만들며 헬스 스코어 모델 버전 관리와 UI+백엔드 변경을 병행합니다.
자주 묻는 질문
고객 채택 헬스 점수는 비즈니스에 무엇을 해야 하나요?
먼저 점수가 어떤 용도인지 정의하세요:
- 이탈 리스크 알림(슬립하는 계정 식별)
- 온보딩 가이드(설정 단계 우선순위 지정)
- 제품 개선(마찰 지점 및 저활용 기능 발견)
점수가 변했을 때 실제로 바뀌는 결정을 말할 수 없다면, 그 메트릭은 아직 포함하지 마세요.
우리 제품에서 “채택(adoption)”을 어떻게 정의하나요?
고객이 가치를 얻고 있음을 증명하는 소수의 행동을 적으세요:
- 활성화(Activation): 첫 번째 의미 있는 결과(예: 팀원 초대, 데이터 소스 연결)
- 핵심 동작(Core actions): 성공 계정과 상관관계가 있는 반복 가능한 행동
- 유지 페이스(Retention cadence): 주간/월간 단위의 지속적인 사용(가능하면 여러 사용자에 걸쳐)
로그인 여부만으로 채택을 정의하지 마세요(로그인이 곧 가치인 경우를 제외).
헬스 점수에 어떤 메트릭을 포함해야 하나요?
높은 신호의 소수 지표로 시작하세요:
- 주간 활성 사용자(WAU)와 추세
- 활성일수(한 번의 긴 세션이 아닌 서로 다른 활동 일수)
- 핵심 기능 사용 빈도(가치 있는 기능)
- 연결된 통합(워크플로를 열거나 전환 비용을 높이는 경우)
- 좌석 활용도(초대된/활성화된/실제로 활동하는 좌석 비율)
한 문장으로 이유를 설명할 수 없는 메트릭은 핵심 입력이 아닐 가능성이 큽니다.
작은 계정과 큰 계정을 공정하게 유지하려면?
작고 큰 계정을 공정하게 평가하려면 정규화와 세분화가 필요합니다:
- 좌석으로 정규화(사용량/라이선스 좌석)
- 계정 연령으로 기대치 조정(신규 vs 성숙)
- 요금제/권한 및 ARR 밴드로 임계값 분리
원시 카운트가 작은 계정을 벌하거나 큰 계정에 과대평가되지 않도록 합니다.
헬스 스코어에서 선행 지표와 후행 지표의 차이는?
리딩(선행) 지표는 조기에 행동하게 하고, 래깅(후행) 지표는 결과를 확인합니다:
- 선행: 활성일수 증가, 온보딩 완료, 첫 통합 연결
- 후행: 갱신, 확장, 장기 유지
목표가 조기 경고라면 후행 지표에 과도한 가중치를 주지 마세요.
머신러닝 없이 설명 가능한 스코어 모델을 어떻게 만들 수 있나요?
머신러닝 없이 설명 가능한 모델을 만들려면 투명한 가중치 기반 포인트 모델을 사용하세요. 예시 구성요소:
- WAU/좌석(0–40)
- 핵심 기능 빈도(0–35)
- 기능 사용 범위(0–15)
- 마지막 의미 있는 활동 이후 시간(0–10)
그런 다음 명확한 상태 구간(예: Green ≥ 75, Yellow 50–74, Red < 50)을 정의하고 이유를 문서화하세요.
스코어를 위해 어떤 제품 이벤트를 계측해야 하나요?
최소한 각 이벤트에 다음 필드를 포함하세요:
event_name,user_id,account_id,timestamp(UTC)- 선택적
properties(feature, plan, workspace_id 등)
중요한 액션은 가능하면 서버사이드에서 추적하고, 을 통제된 어휘로 유지하세요. SDK와 서버사이드 둘 다 사용할 때는 이중 집계가 일어나지 않도록 주의하세요.
헬스 점수 웹앱을 위해 데이터를 어떻게 모델링하고 저장해야 하나요?
몇 가지 핵심 엔터티 중심으로 모델링하고 워크로드에 따라 저장소를 분리하세요:
- 관계형 DB(예: Postgres): accounts, users, subscriptions, scores
- 웨어하우스/애널리틱스: 고볼륨 원시 이벤트
- 애그리게이트: 일별 계정 요약, 기능별 카운터
대규모 이벤트 테이블은 날짜로 파티셔닝하고 account_id로 인덱스/클러스터링하세요.
신뢰할 수 있고 디버깅 가능한 스코어링 잡은 어떻게 구축하나요?
스코어링을 운영 시스템처럼 다루세요:
- raw → validated → daily aggregates → score
- 작업은 멱등성을 보장(이벤트 중복 제거;
(account_id, date)로 애그리게이트 업서트) - 트래킹이나 가중치가 바뀌었을 때를 대비한 백필(backfill) 지원
- 각 실행마다 입력, 파생지표, 모델 버전, 최종 스코어를 저장하는 감사 기록 보관
이렇게 하면 “왜 점수가 떨어졌나?”를 로그 뒤져가며 추론할 필요가 없습니다.
먼저 어떤 API 엔드포인트와 알림 규칙을 만들어야 하나요?
초기에는 업무 흐름 중심의 몇 개 엔드포인트부터 만드세요:
GET /api/accounts/{id}/health(최신 스코어 + 상태)GET /api/accounts/{id}/health/trends?from=&to=(시계열 + 델타)GET /api/accounts/{id}/health/drivers(상·하위 기여요인)
서버 측에서 RBAC를 강제하고, 리스트에는 커서 기반 페이징을 사용하며, 알림은 쿨다운과 최소 데이터 임계값으로 잡음을 줄이세요. 알림은 계정 뷰(/accounts/{id})로 링크하세요.