2025년 12월 10일·4분
Claude Code로 행동에서 OpenAPI 생성하기, 솔직히 말하면
Claude Code를 사용해 행동(behavior)에서 OpenAPI를 생성하고, 이를 API 구현과 비교한 뒤 간단한 클라이언트·서버 검증 예제를 만드는 방법을 배우세요.
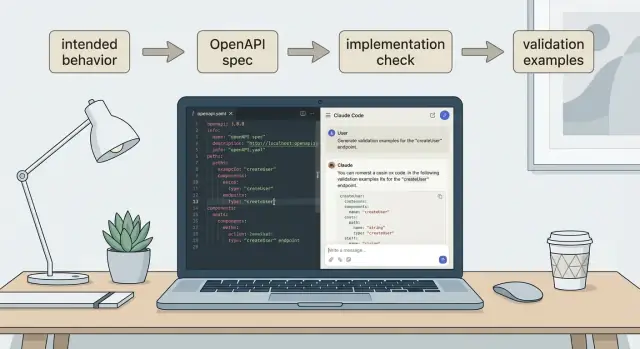
Claude Code를 사용해 행동(behavior)에서 OpenAPI를 생성하고, 이를 API 구현과 비교한 뒤 간단한 클라이언트·서버 검증 예제를 만드는 방법을 배우세요.
OpenAPI 계약은 API의 공통된 설명입니다: 어떤 엔드포인트가 있는지, 무엇을 보내고 무엇을 받는지, 오류는 어떻게 생겼는지. 서버와 그 호출 주체(웹 앱, 모바일 앱 또는 다른 서비스) 사이의 합의입니다.
문제는 드리프트입니다. 실행 중인 API는 변하는데 스펙은 그대로이거나, 스펙은 보기 좋게 정리되지만 구현은 이상한 필드를 계속 반환하거나 상태 코드가 빠지거나 오류 형태가 일관되지 않을 수 있습니다. 시간이 지나면 사람들은 OpenAPI 파일을 신뢰하지 않게 되고, 그냥 무시되는 문서가 됩니다.
드리프트는 보통 정상적인 압력에서 옵니다: 빠른 수정이 스펙 업데이트 없이 배포된다거나, 새로운 선택적 필드가 "임시로" 추가된다거나, 페이지네이션이 진화하거나, 팀들이 서로 다른 "진실의 출처"(백엔드 코드, Postman 컬렉션, OpenAPI 파일)를 업데이트할 때입니다.
정직하게 유지한다는 것은 스펙이 실제 동작과 일치한다는 뜻입니다. API가 때때로 충돌로 409를 반환한다면 그건 계약에 있어야 합니다. 필드가 nullable이면 그렇게 명시하세요. 인증이 필요하면 모호하게 두지 마세요.
좋은 워크플로우는 다음을 제공합니다:
마지막 포인트가 중요한 이유는 계약이 실제로 강제될 때만 도움이 되기 때문입니다. 정직한 스펙과 반복 가능한 검사는 “API 문서”를 팀들이 신뢰할 수 있는 것으로 바꿉니다.
코드를 읽거나 라우트를 그대로 복사해서 시작하면 OpenAPI는 오늘 존재하는 것을 기술하게 됩니다. 거기에는 약속하고 싶지 않은 특이사항도 포함됩니다. 대신 호출자 관점에서 API가 무엇을 해야 하는지 설명하고, 그 다음 구현이 스펙과 일치하는지 검증하세요.
YAML이나 JSON을 작성하기 전에 엔드포인트마다 작은 사실 집합을 수집하세요:
그 다음 동작을 예제로 작성하세요. 예제는 구체적으로 하도록 강제하고 일관된 계약 초안 작성이 쉬워집니다.
Tasks API의 경우 해피 패스 예시는: “title로 작업을 생성하고 id, title, status, createdAt를 받는다.” 흔한 실패도 추가하세요: “title이 없으면 {\"error\":\"title is required\"}로 400을 반환한다.” 그리고 “인증 없이는 401” 같은 예시도요. 이미 엣지 케이스를 알고 있다면 포함하세요: 중복 제목 허용 여부, 존재하지 않는 작업 ID 처리 방식 등.
규칙을 코드 세부사항에 의존하지 않는 간단한 문장으로 캡처하세요:
title은 필수이며 1-120자입니다.”limit이 설정되지 않으면 최대 50개를 반환합니다(최대 200).”dueDate는 ISO 8601 날짜-시간 형식입니다.”마지막으로 v1 범위를 결정하세요. 확실하지 않다면 v1을 작게 명확하게 유지하세요(생성, 조회, 목록, 상태 업데이트). 검색, 대량 업데이트, 복잡한 필터는 나중으로 미뤄서 계약이 믿을 만하게 만드세요.
Claude Code에게 스펙을 작성해 달라고 하기 전에 행동 노트를 작고 반복 가능한 형식으로 작성하세요. 목표는 모델이 실수로 공백을 추측으로 채우기 어렵게 만드는 것입니다.
좋은 템플릿은 실제로 사용할 만큼 짧고, 두 사람이 같은 엔드포인트를 비슷하게 설명할 만큼 일관적이어야 합니다. 구현 방식이 아니라 API가 무엇을 하는지에 집중하세요.
Use one block per endpoint:
METHOD + PATH:
Purpose (1 sentence):
Auth:
Request:
- Query:
- Headers:
- Body example (JSON):
Responses:
- 200 OK example (JSON):
- 4xx example (status + JSON):
Edge cases:
Data types (human terms):
요청과 두 개 이상의 응답을 적어 두세요. 상태 코드와 실제 필드 이름을 가진 현실적인 JSON 바디를 포함하세요. 필드가 선택적이라면 한 예제에서 누락된 형태를 보여 주세요.
엣지 케이스를 명시적으로 지적하세요. 엣지 케이스는 스펙이 나중에 조용히 틀어지는 지점입니다: 빈 결과, 잘못된 ID(400 vs 404), 중복(409 vs 멱등 동작), 검증 실패, 페이지네이션 한도 등.
또한 스키마를 생각하기 전에 사람 말로 데이터 타입을 적어 두세요: 문자열 vs 숫자, 날짜-시간 형식, 불리언, 열거형(허용 값 목록). 그러면 보기 좋은 스키마가 실제 페이로드와 맞지 않는 일을 막을 수 있습니다.
Claude Code는 주의 깊은 필경사처럼 다루면 가장 잘 작동합니다. 행동 노트와 스펙이 어떤 형태여야 하는지에 대한 엄격한 규칙을 제공하세요. 단순히 “OpenAPI 스펙을 작성해줘”라고만 하면 보통 추측, 일관성 없는 명명, 누락된 오류 케이스가 생깁니다.
행동 노트를 먼저 붙여 넣고, 그다음 엄격한 지시 블록을 추가하세요. 실용적 프롬프트 예시는 다음과 같습니다:
You are generating an OpenAPI 3.1 YAML spec.
Source of truth: the behavior notes below. Do not invent endpoints or fields.
If anything is unclear, list it under ASSUMPTIONS and leave TODO markers in the spec.
Requirements:
- Include: info, servers (placeholder), tags, paths, components/schemas, components/securitySchemes.
- For each operation: operationId, tags, summary, description, parameters, requestBody (when needed), responses.
- Model errors consistently with a reusable Error schema and reference it in 4xx/5xx responses.
- Keep naming consistent: PascalCase schema names, lowerCamelCase fields, stable operationId pattern.
Behavior notes:
[PASTE YOUR NOTES HERE]
Output only the OpenAPI YAML, then a short ASSUMPTIONS list.
초안을 받으면 먼저 ASSUMPTIONS를 살펴보세요. 바로잡음의 핵심은 거기에서 시작됩니다. 올바른 것은 승인하고, 잘못된 것은 고쳐서 노트를 업데이트한 뒤 다시 실행하세요.
명명 일관성을 유지하려면 규칙을 미리 정하고 지키세요. 예를 들어: 안정적인 operationId 패턴, 명사형 태그 이름, 단수 스키마 이름, 하나의 공용 Error 스키마, 모든 곳에서 같은 인증 스킴 이름 사용 등입니다.
Koder.ai 같은 바이브-코딩 워크스페이스에서 작업한다면 YAML 파일을 일찍 실제 파일로 저장하고 작은 diff로 반복하는 것이 도움이 됩니다. 어떤 변경이 승인된 행동 결정에서 왔고, 어떤 것이 모델의 추측에서 왔는지 볼 수 있습니다.
실행 중인 API와 비교하기 전에 OpenAPI 파일이 내부적으로 일관된지 확인하세요. 희망사항과 모호한 표현을 가장 빨리 잡을 수 있는 장소입니다.
각 엔드포인트를 클라이언트 개발자라고 생각하고 읽어보세요. 호출자가 반드시 보내야 하는 것과 받을 것인지를 중심으로 보세요.
실용적인 리뷰 패스:
오류 응답은 추가 주의가 필요합니다. 하나의 공통된 형태를 골라 모든 곳에서 재사용하세요. 어떤 팀은 { error: string }처럼 매우 단순하게 유지하고, 다른 팀은 { error: { code, message, details } } 같은 객체를 씁니다. 어느 쪽이든 섞어 쓰지 마세요. 섞이면 클라이언트 코드에 특수 처리가 늘어납니다.
간단한 시나리오로 점검해 보세요. POST /tasks가 title을 요구한다면 스키마는 필수로 표시돼야 하고, 실패 응답은 실제로 반환하는 오류 바디를 보여야 하며, 해당 연산이 인증을 요구하는지 명확히 해야 합니다.
스펙이 의도된 동작처럼 읽히면, 실행 중인 API를 클라이언트가 오늘 경험하는 진실로 취급하세요. 목표는 스펙과 코드 사이에서 “이겨내기”가 아니라 차이를 조기에 표면화하고 각 항목에 대해 명확한 결정을 내리는 것입니다.
첫 번째 패스에서는 실제 요청/응답 샘플이 가장 단순한 옵션입니다. 로그나 자동화된 테스트도 신뢰할 수 있으면 좋습니다.
일반적인 불일치 항목을 주의하세요: 한 쪽에만 존재하는 엔드포인트, 필드명 또는 형태 차이, 상태 코드 차이(200 vs 201, 400 vs 422), 문서화되지 않은 동작(페이지네이션, 정렬, 필터링), 인증 차이(스펙은 공개인데 코드가 토큰을 요구함).
예: OpenAPI에 POST /tasks가 201과 {id,title}을 반환한다고 적혀 있는데, 실제 호출 결과는 200과 {id,title,createdAt}을 받는다면 생성된 클라이언트에는 "충분히 비슷함"이 아닙니다.
바로 편집하기 전에 각 차이를 어떻게 해결할지 결정하세요:
모든 변경은 작고 검토 가능하게 유지하세요: 한 엔드포인트, 한 응답, 한 스키마 수정이 이상적입니다. 리뷰와 재테스트가 쉬워집니다.
신뢰하는 스펙이 생기면 그것을 작은 검증 예제로 바꾸세요. 이것이 드리프트가 다시 생기는 것을 막는 도구입니다.
서버에서 검증은 계약과 일치하지 않는 요청을 빠르게 거부하고 명확한 오류를 반환하는 것을 의미합니다. 이는 데이터 보호와 버그 탐지에 유리합니다.
서버 검증 예제는 보통 세 부분으로 된 케이스로 표현됩니다: 입력, 기대 출력, 기대 오류(정확한 텍스트가 아닌 오류 코드나 메시지 패턴).
예(계약에 title이 필수이며 1~120자일 때):
{
"name": "Create task without title returns 400",
"request": {"method": "POST", "path": "/tasks", "body": {"title": ""}},
"expect": {"status": 400, "body": {"error": {"code": "VALIDATION_ERROR"}}}
}
클라이언트에서의 검증은 서버가 달라지기 전에 드리프트를 탐지하는 것입니다. 서버가 다른 형태를 반환하거나 필수 필드가 사라지면 테스트가 이를 알려야 합니다.
클라이언트 검사는 실제로 의존하는 것에 집중하세요. 예: “작업에는 id, title, status가 있다” 정도입니다. 모든 선택적 필드나 정확한 정렬까지 단언하면 사소한 변경에도 실패합니다.
몇 가지 가이드라인:
Koder.ai로 빌드하면 이러한 예제 케이스를 OpenAPI 파일 옆에 보관하고 동작이 바뀔 때 함께 업데이트할 수 있습니다.
작업 생성 POST /tasks, 목록 GET /tasks, 단건 조회 GET /tasks/{id} 세 개의 엔드포인트가 있는 작은 API를 상상해 보세요.
한 엔드포인트에 대해 테스트 담당자에게 설명하듯 몇 가지 구체적 예제를 먼저 작성하세요.
POST /tasks의 의도된 동작 예시:
{ "title": "Buy milk" }를 보내면 새 작업 객체와 함께 201을 받고, id, title, done:false가 포함된다.{}를 보내면 { "error": "title is required" } 같은 오류로 400을 반환한다.{ "title": "x" }(너무 짧음)를 보내면 { "error": "title must be at least 3 characters" } 같은 오류로 422를 반환한다.Claude Code가 OpenAPI 초안을 만들면 이 엔드포인트 스니펫에는 스키마, 상태 코드, 현실적인 예제가 담겨야 합니다:
paths:
/tasks:
post:
summary: Create a task
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/CreateTaskRequest'
examples:
ok:
value: { "title": "Buy milk" }
responses:
'201':
description: Created
content:
application/json:
schema:
$ref: '#/components/schemas/Task'
examples:
created:
value: { "id": "t_123", "title": "Buy milk", "done": false }
'400':
description: Bad Request
content:
application/json:
schema:
$ref: '#/components/schemas/Error'
examples:
missingTitle:
value: { "error": "title is required" }
'422':
description: Unprocessable Entity
content:
application/json:
schema:
$ref: '#/components/schemas/Error'
examples:
tooShort:
value: { "error": "title must be at least 3 characters" }
흔한 불일치는 미묘합니다: 실행 중인 API가 201 대신 200을 반환하거나 { "taskId": 123 }처럼 다른 필드명을 반환하는 경우입니다. 생성된 클라이언트는 이런 차이에 의해 깨집니다.
해결 방법은 한 가지 진실의 출처를 선택하는 것입니다. 의도된 동작이 맞다면 구현을 변경해 201과 합의된 Task 형태를 반환하게 하세요. 이미 프로덕션 동작이 의존되고 있다면 스펙(및 행동 노트)을 현실에 맞게 업데이트하고 누락된 검증과 오류 응답을 추가해 클라이언트가 놀라지 않도록 하세요.
계약이 규칙을 설명하는 대신 어느 날 API가 반환한 것을 기술하게 되면 부정직해집니다. 간단한 테스트: 새 구현이 오늘의 특이사항을 복사하지 않고도 이 스펙을 통과할 수 있는가?
과적합의 함정이 있습니다. 한 번의 응답을 캡처해서 그것을 법으로 만드는 일입니다. 예: 현재 API가 모든 작업에서 dueDate: null을 반환하니까 스펙에 항상 nullable이라고 적는 경우, 실제 규칙은 “status가 scheduled일 때 필요”일 수 있습니다. 계약은 규칙을 표현해야지 현재 데이터셋을 옮겨 적으면 안 됩니다.
오류는 정직성이 깨지는 지점입니다. 성공 응답만 스펙에 적어두기 쉽지만, 클라이언트는 기본적인 오류 정보를 필요로 합니다: 토큰이 없으면 401, 권한 부족이면 403, 알려지지 않은 ID면 404, 그리고 일관된 검증 오류(400 또는 422) 등.
다른 문제 패턴:
taskId vs id, priority가 문자열/숫자 등)string, 모두 선택적 등)좋은 계약은 테스트 가능해야 합니다. 스펙에서 실패하는 테스트를 쓸 수 없다면 아직 정직하지 않은 것입니다.
OpenAPI 파일을 다른 팀에 넘기기 전에 “이 사람은 머리를 읽지 않고도 이걸 쓸 수 있는가?”를 빠르게 점검하세요.
먼저 예제를 확인하세요. 스펙이 유효하더라도 모든 요청/응답이 추상적이면 쓸모가 없습니다. 각 연산마다 현실적인 요청 예제와 성공 응답 예제를 최소 하나씩 포함하세요. 오류는 인증/검증 등 흔한 실패 케이스당 하나의 예제가 보통 충분합니다.
그다음 일관성을 확인하세요. 한 엔드포인트는 { "error": "..." }, 다른 엔드포인트는 { "message": "..." }를 반환하면 클라이언트는 분기 로직이 늘어납니다. 단일 오류 형태와 예제를 재사용하고 일관된 상태 코드를 선택하세요.
짧은 체크리스트:
실용적 트릭: 한 엔드포인트를 골라서 당신이 API를 전혀 본 적이 없다고 치고 “무엇을 보내고 무엇을 받으며 무엇이 깨지는가?”에 답해 보세요. OpenAPI가 그 질문에 명확히 답하지 못하면 준비가 된 것이 아닙니다.
이 워크플로우는 릴리즈 당일에만 하는 것이 아니라 정기적으로 돌릴 때 효과가 납니다. 간단한 규칙을 정하고 지키세요: 엔드포인트가 변경될 때마다 실행하고, 스펙을 공개하기 전 다시 실행하세요.
소유권을 단순하게 유지하세요. 엔드포인트를 변경한 사람이 행동 노트와 스펙 초안을 업데이트합니다. 두 번째 사람이 스펙 대 구현의 diff를 코드 리뷰처럼 검토하세요. QA나 서포트 팀원들은 불명확한 응답과 엣지 케이스를 잘 발견합니다.
계약 편집을 코드 편집처럼 취급하세요. 채팅 기반 빌더인 Koder.ai를 쓴다면 위험한 변경 전 스냅샷을 찍고, 롤백을 사용하면 반복이 안전합니다. Koder.ai는 소스 코드 내보내기를 지원해 스펙과 구현을 리포지토리에서 나란히 유지하기 쉽습니다.
보통 느리지 않게 일하는 루틴:
다음 행동: 이미 존재하는 한 엔드포인트를 하나 골라 보세요. 행동 노트 5-10줄(입력, 출력, 오류 케이스)을 작성하고, 그 노트로부터 OpenAPI 초안을 생성하고 검증한 다음 실행 중인 구현과 비교하세요. 하나의 불일치를 수정하고 재테스트한 뒤 반복하세요. 한 엔드포인트만으로도 이 습관이 자리잡기 쉽습니다.
OpenAPI drift는 실제로 운영되는 API가 사람들이 공유하는 OpenAPI 파일과 더 이상 일치하지 않을 때를 뜻합니다. 스펙에 새 필드나 상태 코드, 인증 규칙이 빠져 있을 수 있고, 스펙은 “이상적”인 동작을 기술하지만 서버는 따르지 않을 수 있습니다.
이게 중요한 이유는 클라이언트(앱, 다른 서비스, 생성된 SDK, 테스트 등)가 계약을 기준으로 동작하기 때문입니다. 서버가 실제로 어떻게 동작하는지와 스펙이 달라지면 예기치 못한 고장이 생깁니다.
클라이언트 쪽에서 드리프트가 나타나는 대표적인 방식은 다음과 같습니다: 모바일 앱은 201을 기대하는데 200을 받고, SDK가 응답을 역직렬화하지 못하거나 필드명이 바뀌어 오류가 발생하고, 오류 처리 로직이 서로 다른 오류 형태 때문에 실패합니다.
심각한 충돌이 없더라도 팀들이 스펙을 믿지 않게 되어 스펙 사용을 중단하면 조기 경고 시스템이 사라집니다.
백엔드 코드를 그대로 복사해 스펙을 시작하면 안 되는 이유는 코드가 현재 동작(및 우연한 결함)을 그대로 반영하기 때문입니다. 장기적으로 약속하고 싶지 않은 특이사항까지 계약에 포함될 수 있습니다.
대신 더 나은 기본 방식은: 의도한 동작(입력, 출력, 오류)을 먼저 쓰고, 구현이 그와 일치하는지 검증하는 것입니다. 그래야 강제할 수 있는 계약이 됩니다. 단순히 오늘의 라우트 스냅샷을 만드는 것이 아닙니다.
각 엔드포인트마다 최소한 다음을 작성하세요:
구체적인 요청과 두 개의 응답을 쓸 수 있다면, 대체로 진실한 스펙 초안 작성에 충분합니다.
오류 응답을 일관되게 유지하려면 한 가지 오류 바디 형태를 정하고 모든 곳에서 재사용하세요.
간단한 기본 형태는 다음 중 하나입니다:
{ "error": "message" }, 또는{ "error": { "code": "...", "message": "...", "details": ... } }그리고 엔드포인트와 예제 전반에서 일관되게 사용하세요. 복잡성보다 일관성이 더 중요합니다. 클라이언트는 이 형태를 하드코딩할 가능성이 큽니다.
Claude Code에 임의로 엔드포인트나 필드를 만들지 않도록 하려면 행동 노트를 주고 엄격한 규칙을 함께 제공하세요. 실용적인 지침 예시는 다음과 같습니다:
Error)를 포함하고 참조하세요.”생성 후에는 먼저 ASSUMPTIONS를 검토하세요. 모델이 추측을 받아들이면 그게 드리프트의 시작점입니다.
스펙을 비교하기 전에 먼저 스펙 자체의 내부 일관성을 확인하세요:
201)이렇게 하면 실제 프로덕션과 비교하기 전에 '희망사항'에 기반한 스펙을 걸러낼 수 있습니다.
스펙과 실행 중인 API가 일치하지 않을 때는 항목별로 다음 원칙에 따라 결정하세요:
변경은 작게 유지하세요(한 엔드포인트, 한 응답, 한 스키마 수정). 그래야 재테스트와 리뷰가 쉬워집니다.
서버 측 검증은 요청이 계약을 위반하면 빠르게 실패시키고 명확한 오류를 반환하는 것입니다(상태 코드 + 오류 코드/형식). 클라이언트 측 검증은 서버가 다른 형태를 반환하기 전에 드리프트를 감지하는 테스트를 말합니다.
일반적인 가이드라인:
옵션 필드 전체를 단언하지 마세요. 그렇지 않으면 사소한 추가에도 테스트가 깨집니다.
작은 규칙을 정하고 꾸준히 지키는 것이 중요합니다. 보통 다음 루틴이 느려지지 않으면서도 효과적입니다:
Koder.ai를 사용한다면 OpenAPI 파일을 코드 옆에 두고 스냅샷과 롤백을 활용해 안전하게 반복할 수 있습니다.