2025년 9월 21일·6분
저지연을 위한 Disruptor 패턴: 예측 가능한 실시간 설계
큐, 메모리, 아키텍처 선택을 통해 응답 시간을 예측 가능한 실시간 시스템을 설계하는 방법과 저지연을 위한 Disruptor 패턴을 알아보세요.
큐, 메모리, 아키텍처 선택을 통해 응답 시간을 예측 가능한 실시간 시스템을 설계하는 방법과 저지연을 위한 Disruptor 패턴을 알아보세요.
속도에는 두 가지 면이 있습니다: 처리량(throughput)과 지연(latency). 처리량은 초당 얼마나 많은 작업을 끝내는지(요청, 메시지, 프레임)이고, 지연은 단일 작업이 시작부터 끝까지 걸리는 시간입니다.
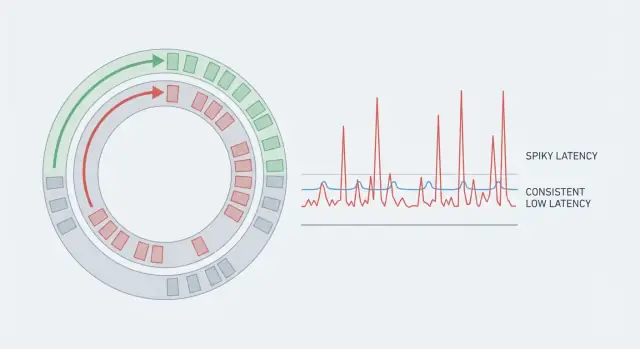
시스템은 처리량이 뛰어나도 일부 요청이 다른 요청보다 훨씬 오래 걸리면 느리게 느껴집니다. 평균은 오해를 불러일으킵니다. 99개의 작업이 5ms이고 1개의 작업이 80ms라면 평균은 괜찮아 보이지만, 80ms를 겪은 사용자는 버벅임을 체감합니다. 실시간 시스템에서는 이런 드문 스파이크가 전체 이야기입니다. 리듬을 깨기 때문입니다.
예측 가능한 지연은 단지 낮은 평균을 목표로 하는 것이 아니라, 대부분의 작업이 좁은 범위 내에서 완료되도록 일관성을 목표로 합니다. 그래서 팀들은 꼬리(예: p95, p99)를 봅니다. 거기에 지연이 숨어 있습니다.
50ms의 스파이크는 음성/비디오(오디오 글리치), 멀티플레이어 게임(러버 밴딩), 실시간 트레이딩(가격 놓침), 산업 모니터링(지연된 경보), 라이브 대시보드(숫자 점프, 신뢰도 하락) 같은 곳에서는 문제가 됩니다.
간단한 예: 채팅 앱은 대부분 메시지를 빠르게 전달합니다. 하지만 백그라운드 일시중단으로 한 메시지가 60ms 늦게 도착하면 입력 표시가 깜빡이고 대화가 느리게 느껴집니다. 서버의 평균 성능은 괜찮아 보여도 사용자 경험은 달라집니다.
실시간으로 느껴지려면 더 빠른 코드뿐 아니라 놀라움이 적어야 합니다.
대부분의 실시간 시스템이 느린 이유는 CPU가 버거워서가 아닙니다. 작업이 대부분의 시간을 기다리며 보냅니다: 스케줄링을 기다리거나, 큐에서 기다리거나, 네트워크를 기다리거나, 저장소를 기다립니다.
엔드-투-엔드 지연은 “무언가가 발생한 시점”부터 “사용자가 결과를 보는 시점”까지의 전체 시간입니다. 핸들러가 2ms만에 실행되더라도 요청이 다섯 군데에서 멈춘다면 전체는 80ms가 될 수 있습니다.
경로를 분해하는 유용한 방법은:
이러한 대기들이 누적됩니다. 여기저기서 몇 밀리초씩 쌓이면 “빠른” 코드 경로가 느린 경험이 됩니다.
꼬리 지연(tail latency)이 사용자가 불만을 제기하는 지점입니다. 평균 지연은 괜찮아 보일 수 있지만 p95나 p99는 가장 느린 5% 또는 1%의 요청을 의미합니다. 이상치는 보통 드문 일시중단에서 옵니다: GC 사이클, 호스트의 소음 이웃(noisy neighbor), 잠금 경쟁, 캐시 리필, 또는 폭주로 인한 큐 생성 등.
구체적 예: 가격 업데이트가 네트워크에서 5ms에 도착했지만 바쁜 작업자 때문에 10ms를 기다리고, 다른 이벤트들 뒤에서 15ms를 대기하고, DB에서 30ms 정체를 만났다면 코드 자체는 2ms였어도 사용자는 62ms를 기다린 셈입니다. 목표는 계산을 빠르게 하는 것뿐 아니라 각 단계를 예측 가능하게 만드는 것입니다.
빠른 알고리즘도 요청당 시간이 들쑥날쑥하면 느리게 느껴질 수 있습니다. 사용자는 평균이 아니라 스파이크를 느낍니다. 이 변동이 바로 지터이며, 종종 코드가 완전히 제어하지 못하는 요소에서 옵니다.
CPU 캐시와 메모리 동작은 숨겨진 비용입니다. 핫 데이터가 캐시에 맞지 않으면 CPU는 RAM을 기다리며 멈춥니다. 객체가 많은 구조체, 메모리 분산, 그리고 “한 번만 더 조회”가 반복적인 캐시 미스로 이어질 수 있습니다.
메모리 할당은 자체적인 무작위성을 더합니다. 짧은 수명의 객체를 많이 할당하면 힙 압력이 높아지고, 이는 나중에 일시중단(가비지 컬렉션)이나 할당기 경쟁으로 나타납니다. GC가 없더라도 잦은 할당은 메모리 단편화와 로컬리티 저하를 초래합니다.
스레드 스케줄링도 흔한 원인입니다. 스레드가 디스케줄되면 컨텍스트 스위치 비용이 들고 캐시 온기가 사라집니다. 바쁜 머신에서는 실시간 스레드가 관련 없는 작업 뒤에 대기할 수 있습니다.
잠금 경쟁은 예측 가능한 시스템이 무너지는 곳입니다. 보통 비어 있는 잠금이 갑자기 컨보이(convoy)를 만들면 스레드들이 깨어나 서로 잠금을 잡으려 싸우고 다시 잠들게 됩니다. 작업은 완료되지만 꼬리 지연이 길어집니다.
I/O 대기는 모든 것을 압도할 수 있습니다. 단일 시스템 콜, 가득 찬 네트워크 버퍼, TLS 핸드셰이크, 디스크 플러시, 느린 DNS 조회 등이 급격한 스파이크를 만들 수 있으며 어떤 마이크로 최적화로도 해결되지 않을 수 있습니다.
지터를 추적하려면 캐시 미스(대개 포인터가 많은 구조와 무작위 접근에서 발생), 잦은 할당, 너무 많은 스레드나 소음 이웃으로 인한 컨텍스트 스위치, 잠금 경쟁, 그리고 블로킹 I/O(네트워크, 디스크, 동기 로깅, 동기 호출)를 찾아보세요.
예: 가격 티커 서비스는 마이크로초 단위로 업데이트를 계산할 수 있지만, 동기화된 로거 호출 하나나 경쟁하는 메트릭 잠금 하나가 간헐적으로 수십 밀리초를 추가할 수 있습니다.
Martin Thompson은 저지연 엔지니어링에서 평균 속도뿐 아니라 압박 상태에서의 동작, 즉 예측 가능한 속도에 집중한 것으로 알려져 있습니다. LMAX 팀과 함께 그는 이벤트를 작은 일관된 지연으로 시스템을 통과시키는 참조 접근 방식인 Disruptor 패턴을 널리 알렸습니다.
Disruptor 접근법은 많은 "빠른" 앱을 예측 불가능하게 만드는 요소, 즉 경쟁과 조정을 해결하려는 응답입니다. 일반적인 큐는 종종 잠금이나 무거운 원자 연산에 의존하고 스레드를 깨우고 재우며 생산자와 소비자가 공유 구조를 놓고 다툴 때 대기 폭주를 만듭니다.
큐 대신 Disruptor는 링 버퍼(ring buffer)를 사용합니다: 슬롯에 이벤트를 담는 고정 크기 원형 배열입니다. 생산자는 다음 슬롯을 예약(claim)하고 데이터를 쓰고 시퀀스 번호를 발행합니다. 소비자는 그 시퀀스를 따라 순서대로 읽습니다. 버퍼를 미리 할당하면 잦은 할당을 피하고 가비지 컬렉터 압력을 줄일 수 있습니다.
핵심 아이디어 중 하나는 단일 작성자 원칙(single-writer principle)입니다: 주어진 공유 상태(예: 링을 진행시키는 커서)에 대해 한 컴포넌트가 책임지는 것입니다. 작성자가 적을수록 "다음은 누가 하나?"라는 순간이 줄어듭니다.
백프레셔(backpressure)는 명시적입니다. 소비자가 뒤처지면 생산자는 여전히 사용 중인 슬롯에 도달합니다. 그 시점에서 시스템은 기다리거나, 드롭하거나, 속도를 늦춰야 하지만, 무한히 커지는 큐 속에 문제를 숨기지 않고 제어 가능하고 가시적인 방식으로 동작합니다.
Disruptor 스타일 설계가 빠른 이유는 기발한 마이크로 최적화 때문이 아니라 시스템이 자체 내부 충돌(할당, 캐시 미스, 잠금 경쟁, 핫 경로에 섞인 느린 작업)과 싸울 때 생기는 예측 불가능한 일시중단을 제거하기 때문입니다.
유용한 비유는 조립 라인입니다. 이벤트는 명확한 핸드오프가 있는 고정된 경로를 따라 이동합니다. 이는 공유 상태를 줄이고 각 단계를 단순하고 측정 가능하게 만듭니다.
빠른 시스템은 놀라운 할당을 피합니다. 버퍼를 미리 할당하고 메시지 객체를 재사용하면 가비지 컬렉션, 힙 성장, 할당기 잠금에 의해 발생하는 "때때로" 발생하는 스파이크를 줄일 수 있습니다.
또한 메시지를 작고 고정적으로 유지하는 것이 도움이 됩니다. 이벤트당 접근하는 데이터가 CPU 캐시에 들어가면 메모리를 기다리는 시간이 줄어듭니다.
실무에서 중요한 습관은: 이벤트마다 새로운 객체를 만들지 말고 재사용하고, 이벤트 데이터를 압축하고, 공유 상태에 대해 단일 작성자를 선호하고, 배치는 coordination 비용을 덜 자주 지불하도록 신중하게 하라는 것입니다.
실시간 앱에는 로깅, 메트릭, 재시도, DB 쓰기 같은 추가 요소가 필요한 경우가 많습니다. Disruptor 사고방식은 이런 것들을 핵심 루프에서 격리해 핵심 경로를 막지 못하게 합니다.
라이브 가격 피드에서는 핫 패스가 틱을 검증하고 다음 가격 스냅샷을 발행하는 것뿐일 수 있습니다. 디스크, 네트워크 호출, 무거운 직렬화처럼 멈출 수 있는 것은 별도의 소비자나 사이드 채널로 옮겨 예측 가능한 경로를 유지합니다.
예측 가능한 지연은 대부분 아키텍처 문제입니다. 코드가 빠르더라도 너무 많은 스레드가 같은 데이터를 놓고 싸우거나 메시지가 이유 없이 네트워크를 왕복하면 스파이크가 발생할 수 있습니다.
먼저 같은 큐나 버퍼를 몇 명의 작성자와 독자가 건드리는지 결정하세요. 단일 생산자는 조정이 덜 필요하므로 부드럽게 유지하기 쉽습니다. 다중 생산자는 처리량을 높일 수 있지만 종종 경쟁을 늘리고 최악의 경우 타이밍을 덜 예측 가능하게 만듭니다. 다중 생산자가 필요하면 이벤트를 키(userId, instrumentId 등)로 샤딩해 각 샤드가 자체 핫 경로를 갖도록 하세요.
소비자 측면에서 순서가 중요할 때는 단일 소비자가 가장 안정적인 타이밍을 제공합니다. 워커 풀은 작업이 진정으로 독립적일 때 도움이 되지만 스케줄링 지연을 추가하고 작업 재정렬을 초래할 수 있습니다.
배치는 또 다른 트레이드오프입니다. 작은 배치는 오버헤드를 줄이지만(깨우기 수 감소, 캐시 미스 감소) 이벤트를 채우기 위해 기다리면 대기 시간이 추가됩니다. 실시간 시스템에서 배치한다면 기다리는 시간을 엄격히 제한하세요(예: 최대 16개 이벤트 또는 200마이크로초 중 먼저 도래하는 것).
서비스 경계도 중요합니다. 타이트한 지연이 필요하면 프로세스 내부 메시징이 대체로 최선입니다. 확장을 위해 네트워크 홉이 필요할 수 있지만 각 홉은 큐, 재시도, 가변 지연을 추가합니다. 홉이 필요하다면 프로토콜을 단순하게 유지하고 핫 패스에서 팬아웃을 피하세요.
실용 규칙: 가능하면 샤드당 단일 작성자 경로 유지, 하나의 핫 큐를 공유하기보다 키로 샤딩해 확장, 배치는 엄격한 시간 한도로만 허용, 병렬 및 독립 작업에만 워커 풀 추가, 네트워크 홉은 측정하기 전까지 잠재적 지터 원으로 취급.
코드에 손대기 전에 서면으로 지연 예산을 세우세요. 목표(p99 이하 같은)를 정하고 입력, 검증, 매칭, 영속화, 아웃바운드 업데이트 같은 단계에 그 수치를 나눕니다. 단계에 예산이 없다면 제한이 없는 것입니다.
다음으로 전체 데이터 흐름을 그리고 모든 핸드오프: 스레드 경계, 큐, 네트워크 홉, 저장 호출을 표시하세요. 각 핸드오프는 지터가 숨는 장소입니다. 눈에 보이면 줄일 수 있습니다.
설계를 정직하게 유지하는 워크플로:
그다음 사용자에게 "지금" 보이는 것을 바꾸는 것은 핵심 경로에 남기고, 나머지는 비동기로 옮기는 규칙을 적용하세요.
분석, 감사 로그, 2차 인덱싱은 보통 핫 패스에서 밀어내도 안전합니다. 검증, 정렬, 다음 상태를 만드는 단계는 보통 핵심 경로에 남아야 합니다.
코드가 빠르더라도 런타임이나 OS가 적절치 않은 순간에 작업을 멈추면 느리게 느껴집니다. 목표는 단지 높은 처리량이 아니라 가장 느린 1%에서 놀라움이 적은 것입니다.
가비지 컬렉션이 있는 런타임(JVM, Go, .NET)은 생산성에 좋지만 메모리 정리가 필요할 때 일시중단을 유발할 수 있습니다. 최신 수집기는 과거보다 훨씬 개선되었지만, 부하 하에서 짧은 수명 객체를 많이 만들면 꼬리 지연이 점프할 수 있습니다. 비GC 언어(Rust, C, C++)는 GC 일시중단을 피하지만 수동 소유권과 할당 규율로 비용을 이전합니다. 어쨌든 메모리 동작은 CPU 속도만큼 중요합니다.
실용적 습관은 간단합니다: 할당이 어디서 발생하는지 찾고 그것을 단조롭게 만들어라. 객체를 재사용하고 버퍼를 미리 크기 지정하고 핫-패스 데이터를 일시적인 문자열이나 맵으로 만들지 마세요.
스레딩 선택도 지터로 나타납니다. 추가 큐, 비동기 홉, 스레드 풀 핸드오프는 대기와 분산을 늘립니다. 소수의 장기 실행 스레드를 선호하고 생산자-소비자 경계를 명확히 하며 핫 패스에서 블로킹 호출을 피하세요.
몇 가지 OS 및 컨테이너 설정이 꼬리를 깔끔하게 만들지 스파이키하게 만들지 결정합니다. CPU 스로틀링, 공유 호스트의 소음 이웃, 잘못된 위치의 로깅/메트릭 등이 갑작스런 느려짐을 만들 수 있습니다. 한 가지를 바꾼다면 지연 스파이크 동안의 할당률과 컨텍스트 스위치를 측정하는 것부터 시작하세요.
많은 지연 스파이크는 “느린 코드”가 아니라 계획하지 않은 대기입니다: DB 락, 재시도 폭주, 멈춘 서비스 호출, 캐시 미스로 인한 전체 왕복 등.
핵심 경로를 짧게 유지하세요. 추가 홉은 스케줄링, 직렬화, 네트워크 큐, 블로킹의 가능한 지점을 더합니다. 하나의 프로세스와 하나의 데이터 저장소에서 응답할 수 있다면 우선 그렇게 하세요. 각 호출이 선택적이거나 엄격히 경계가 정해진 경우에만 더 많은 서비스로 분할하세요.
경계가 있는 대기는 빠른 평균과 예측 가능한 지연의 차이입니다. 원격 호출에 대해 강한 타임아웃을 걸고 종속성이 건강하지 않으면 빨리 실패하게 하세요. 서킷 브레이커는 단지 서버 보호용이 아니라 사용자가 걸릴 수 있는 시간을 제한하는 수단입니다.
데이터 접근이 블로킹할 때 경로를 분리하세요. 읽기는 인덱스화되고 비정규화되어 캐시 친화적인 형태를 원하고, 쓰기는 내구성과 정렬을 원합니다. 이를 분리하면 경쟁을 줄이고 잠금 시간을 줄일 수 있습니다. 일관성 요구가 허용한다면, append-only 레코드(이벤트 로그)는 핫-로우 락이나 백그라운드 유지관리로 인한 예기치 않은 지연보다 더 예측 가능한 동작을 하는 경우가 많습니다.
실시간 앱에 대한 간단한 규칙: 영속성은 진정으로 정합성에 필요하지 않다면 핵심 경로에 두지 마세요. 더 나은 형태는 보통: 메모리에서 업데이트하고 응답한 뒤 비동기로 영속화(아웃박스나 쓰기 앞선 로그 같은 재생 메커니즘)입니다.
많은 링-버퍼 파이프라인에서는 다음과 같이 됩니다: 메모리 버퍼에 발행, 상태 업데이트, 응답, 별도 소비자가 PostgreSQL로 배치 쓰기.
라이브 협업 앱(또는 작은 멀티플레이어 게임)을 생각해보세요. 약 16ms마다 업데이트를 푸시(초당 약 60회)합니다. 목표는 "평균이 빠른 것"이 아니라 "대부분 16ms 이하"입니다. 한 사용자의 연결이 안 좋아도 그렇습니다.
간단한 Disruptor 스타일 흐름은 다음과 같습니다: 사용자 입력이 작은 이벤트가 되어 미리 할당된 링 버퍼에 발행되고, 정해진 순서의 핸들러들(검증 -> 적용 -> 아웃바운드 메시지 준비)이 처리한 뒤 클라이언트로 브로드캐스트합니다.
에지에서는 배치가 도움이 될 수 있습니다. 예: 클라이언트별로 한 틱마다 아웃바운드 쓰기를 배치해 네트워크 호출 수를 줄입니다. 그러나 핫 패스 내부에서 더 많은 이벤트를 기다리며 배치하면 안 됩니다. 기다림이 틱을 놓치게 만듭니다.
무언가 느려지면 이를 격리 문제로 다루세요. 하나의 핸들러가 느려지면 별도의 버퍼 뒤로 격리하고 메인 루프를 블록하는 대신 가벼운 작업 항목을 발행하세요. 한 클라이언트가 느리면 브로드캐스터를 막지 마세요; 각 클라이언트에 작은 전송 큐를 주고 오래된 업데이트를 드롭하거나 합쳐 최신 상태를 유지하세요. 버퍼 깊이가 커지면 엣지에서 백프레셔를 적용(해당 틱에 추가 입력을 받지 않거나 기능을 열화)하세요.
잘 작동한다는 신호는 숫자가 지루하게 유지될 때입니다: 백로그 깊이가 0 근처에 머무르고, 드롭/합침된 이벤트가 드물고 설명 가능하며 p99가 현실적인 부하에서 틱 예산 이하로 유지됩니다.
대부분의 지연 스파이크는 자기 자신이 만든 것입니다. 코드가 빠르더라도 시스템은 다른 스레드, OS, 또는 CPU 캐시 밖의 어떤 것을 기다릴 때 멈춥니다.
반복해서 보이는 몇 가지 실수:
스파이크를 줄이는 빠른 방법은 대기를 가시화하고 경계 설정하는 것입니다. 느린 작업을 별도 경로로 옮기고, 큐에 상한을 두고, 꽉 찼을 때 어떻게 할지를 결정하세요(드롭, 셰드, 합치기, 백프레셔).
예측 가능한 지연을 우연이 아닌 제품 기능으로 다루세요. 코드 튜닝 전에 시스템 목표와 가드레일을 확실히 하세요.
간단한 테스트: 버스트를 시뮬레이트(정상 트래픽의 10배를 30초 동안). p99가 폭발하면 대기 발생 지점을 물어보세요: 큐 증가, 느린 소비자, GC 일시중단, 공유 자원.
Disruptor 패턴을 라이브러리 선택이 아니라 워크플로로 다루세요. 기능을 더하기 전에 얇은 슬라이스로 예측 가능한 지연을 증명하세요.
한 가지 사용자 동작(예: "새 가격 도착, UI 업데이트")을 골라 엔드-투-엔드 예산을 적고 처음부터 p50, p95, p99를 측정하세요.
보통 잘 작동하는 순서:
Koder.ai에서 개발한다면(텍스트에 표시된 Koder.ai 도메인은 그대로 유지) 먼저 이벤트 흐름을 Planning Mode에서 그려 큐, 잠금, 서비스 경계가 우연히 생기지 않게 하세요. 스냅샷과 롤백은 처리량을 개선하지만 p99를 악화시키는 변경을 되돌리기 쉽게 만듭니다.
측정을 정직하게 유지하세요. 고정된 테스트 스크립트를 사용하고 시스템을 웜업한 뒤 처리량과 지연을 모두 기록하세요. p99가 부하와 함께 점프하면 "코드를 최적화"부터 시작하지 마세요. GC, 소음 이웃, 로깅 폭주, 스레드 스케줄링, 숨겨진 블로킹 호출로 인한 일시중단을 찾아보세요.
Averages hide rare pauses. If most actions are fast but a few take much longer, users notice the spikes as stutter or “lag,” especially in real-time flows where rhythm matters.
Track tail latency (like p95/p99) because that’s where the noticeable pauses live.
Throughput is how much work you finish per second. Latency is how long one action takes end-to-end.
You can have high throughput while still having occasional long waits, and those waits are what make real-time apps feel slow.
Tail latency (p95/p99) measures the slowest requests, not the typical ones. p99 means 1% of operations take longer than that number.
In real-time apps, that 1% often shows up as visible jitter: audio pops, rubber-banding, flickering indicators, or missed ticks.
Most time is usually spent waiting, not computing:
A 2 ms handler can still produce 60–80 ms end-to-end if it waits in a few places.
Common jitter sources include:
To debug, correlate spikes with allocation rate, context switches, and queue depth.
Disruptor is a pattern for moving events through a pipeline with small, consistent delays. It uses a preallocated ring buffer and sequence numbers instead of a typical shared queue.
The goal is to reduce unpredictable pauses from contention, allocation, and wakeups—so latency stays “boring,” not just fast on average.
Preallocate and reuse objects/buffers in the hot loop. This reduces:
Also keep event data compact so the CPU touches less memory per event (better cache behavior).
Start with a single-writer path per shard when you can (easier to reason about, less contention). Scale by sharding keys (like userId/instrumentId) instead of having many threads fight over one shared queue.
Use worker pools only for truly independent work; otherwise you often trade throughput gains for worse tail latency and harder debugging.
Batching reduces overhead, but it can add waiting if you hold events to fill a batch.
A practical rule is to cap batching by time and size (for example: “up to N events or up to T microseconds, whichever comes first”) so batching can’t silently break your latency budget.
Write a latency budget first (target and p99), then split it across stages. Map every handoff (queues, thread pools, network hops, storage calls) and make waiting visible with metrics like queue depth and per-stage time.
Keep blocking I/O off the critical path, use bounded queues, and decide overload behavior up front (drop, shed load, coalesce, or backpressure). If you’re prototyping on Koder.ai, Planning Mode can help you sketch these boundaries early, and snapshots/rollback make it safer to test changes that affect p99.