2025년 10월 11일·6분
Kafka 이벤트 스트리밍: 큐가 적절할 때와 로그가 유리할 때
Kafka 이벤트 스트리밍은 이벤트를 순서화된 로그로 다루는 방식으로 시스템 설계를 바꿨습니다. 단순한 큐로 충분한 경우와 로그 기반 접근이 유리한 경우를 알아보세요.
Kafka 이벤트 스트리밍은 이벤트를 순서화된 로그로 다루는 방식으로 시스템 설계를 바꿨습니다. 단순한 큐로 충분한 경우와 로그 기반 접근이 유리한 경우를 알아보세요.
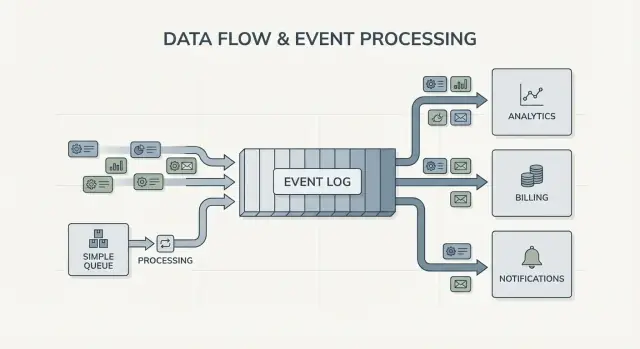
fraud_review_requested 같은 이벤트를 백필할 수 있습니다.\n\n이 접근이 요구하는 것을 주목하세요. 로그 기반 접근은 이벤트를 명확하게 이름 짓고 안정적으로 유지하며 여러 팀과 서비스가 그것에 의존할 것을 받아들이게 합니다. 또한 유용한 질문을 던지게 합니다: 진실의 출처는 무엇인가? 이 이벤트는 장기적으로 무엇을 의미하는가? 실수를 했을 때 우리는 무엇을 하는가?\n\n가치 있는 것은 사람의 성격이 아니라 공유 로그가 시스템의 기억이 될 수 있다는 깨달음입니다. 기억은 새로운 소비자를 추가해도 시스템이 깨지지 않고 성장할 수 있게 합니다.\n\n## 큐 vs 로그: 가장 단순한 머리속 모델\n\n메시지 큐는 소프트웨어의 할 일 줄과 같습니다. 프로듀서가 작업을 줄에 넣으면 소비자가 다음 항목을 가져가서 작업을 수행하고 항목은 사라집니다. 시스템은 주로 각 작업을 가능한 빨리 한 번 처리하는 데 초점이 있습니다.\n\n로그는 다릅니다. 로그는 발생한 사실의 순서화된 기록으로, 내구성 있게 보관됩니다. 소비자는 이벤트를 "가져가서" 사라지게 하지 않습니다. 각 소비자는 자신의 속도로 로그를 읽고 나중에 다시 읽을 수 있습니다. Kafka 이벤트 스트리밍에서 그 로그가 핵심 아이디어입니다.\n\n차이를 기억하기 쉬운 실용적 방식:\n\n- 큐 = 해야 할 일. 작업자가 확인하면 사라진다.\n- 로그 = 무슨 일이 일어났는지의 기록. 이벤트는 보존 기간 동안 남아 있다.\n\n보존(retention)은 설계를 바꿉니다. 큐에서는 나중에 과거 메시지에 의존하는 새 기능(분석, 부정행위 검사, 버그 이후 재실행)이 필요하면 별도의 데이터베이스를 추가하거나 메시지 복사본을 다른 곳에 캡처해야 합니다. 로그에서는 재생이 자연스럽습니다: 처음부터(또는 알려진 체크포인트부터) 읽어 파생 뷰를 재구성할 수 있습니다.\n\n팬아웃(fan-out)은 또 다른 큰 차이입니다. 체크아웃 서비스가 OrderPlaced를 발행한다고 상상해보세요. 큐에서는 보통 하나의 워커 그룹을 선택해 처리하거나 여러 큐에 작업을 복제해야 합니다. 로그에서는 청구, 이메일, 재고, 검색 인덱싱, 분석이 모두 동일한 이벤트 스트림을 독립적으로 읽을 수 있습니다. 각 팀은 자신의 속도로 이동할 수 있고, 새 소비자를 나중에 추가해도 프로듀서를 변경할 필요가 없습니다.\n\n따라서 머리속 모델은 간단합니다: 작업을 옮길 때는 큐를 사용하세요; 회사 여러 부분이 지금이나 나중에 읽을 수 있는 이벤트를 기록할 때는 로그를 사용하세요.\n\n## 이벤트 스트리밍이 시스템 설계에서 바꾸는 것\n\n이벤트 스트리밍은 기본 질문을 바꿉니다. "이 메시지를 누가 받아야 하나?" 대신에 "무슨 일이 방금 일어났나?"를 기록하는 것으로 시작합니다. 사소해 보이지만 시스템 모델링 방식을 바꿉니다.\n\n당신은 OrderPlaced나 PaymentFailed 같은 사실을 게시하고 시스템의 다른 부분은 언제, 어떻게 반응할지 스스로 결정합니다.\n\nKafka 이벤트 스트리밍을 사용하면 프로듀서는 직접 연결 목록을 가질 필요가 없습니다. 체크아웃 서비스는 하나의 이벤트를 게시하면, 그것이 분석, 이메일, 부정행위 검사, 또는 향후 추천 서비스 중 어느 쪽에서 사용될지 알 필요가 없습니다. 새 소비자는 나중에 나타날 수 있고, 오래된 소비자는 일시중지할 수 있으며, 프로듀서는 동일하게 동작합니다.\n\n이것은 또한 실수에서 회복하는 방식을 바꿉니다. 메시지 전용 세계에서는 소비자가 무언가를 놓치거나 버그가 생기면 데이터가 흔히 "사라진" 것으로 간주됩니다(특별한 백업을 구축하지 않았으면). 로그에서는 코드를 고치고 히스토리를 재생해 올바른 상태를 재구성할 수 있습니다. 이는 수동으로 데이터베이스를 수정하거나 신뢰하지 못하는 일회성 스크립트보다 나은 경우가 많습니다.\n\n실무에서 이 전환은 몇 가지 신뢰할 수 있는 방식으로 드러납니다: 이벤트를 내구성 있는 기록으로 취급하게 되고, 기능 추가는 프로듀서를 수정하는 대신 구독으로 이루어지며, 읽기 모델(검색 인덱스, 대시보드)을 처음부터 재구성할 수 있고, 서비스 간에 무슨 일이 있었는지에 대한 타임라인이 더 명확해집니다.\n\n관찰 가능성(observability)이 향상됩니다. 이벤트 로그가 공유 참조가 되면 문제가 생겼을 때 비즈니스 시퀀스를 따라갈 수 있습니다: 주문 생성, 재고 예약, 결제 재시도, 배송 일정. 비즈니스 사실에 초점이 맞춰진 이 타임라인은 흩어진 애플리케이션 로그보다 이해하기 쉬운 경우가 많습니다.\n\n구체적 예: 할인 버그로 두 시간 동안 주문 가격이 잘못되었다면, 수정 코드를 배포하고 영향을 받은 이벤트를 재생해 총액을 재계산하고 송장을 업데이트하며 분석을 갱신할 수 있습니다. 결과를 재도출해서 수정하는 것이 어떤 테이블을 수동으로 패치할지 추측하는 것보다 낫습니다.\n\n## 단순한 큐로 충분할 때\n\n단순 큐는 작업을 옮기는 것이 목적일 때 적절한 도구입니다. 목표는 작업을 워커에게 넘겨 실행한 뒤 잊는 것입니다. 아무도 과거를 재생하거나 오래된 이벤트를 검사하거나 나중에 새 소비자를 추가할 필요가 없다면 큐가 더 단순합니다.\n\n큐는 백그라운드 작업에 적합합니다: 가입 이메일 발송, 업로드 후 이미지 리사이즈, 야간 리포트 생성, 느린 외부 API 호출 등. 이러한 경우 메시지는 단지 작업 티켓입니다. 워커가 작업을 마치면 티켓의 역할도 끝납니다.\n\n큐는 또한 소유 모델에 잘 맞습니다: 하나의 소비자 그룹이 작업을 책임지고 다른 서비스가 동일한 메시지를 독립적으로 읽을 것으로 예상하지 않습니다.\n\n다음 중 대부분이 참이면 큐면 충분합니다:\n\n- 데이터의 가치가 단기간에 한정된다.\n- 하나의 팀이나 서비스가 작업을 끝까지 소유한다.\n- 재생과 장기 보존이 요구사항이 아니다.\n- 디버깅이 과거 히스토리 재실행에 의존하지 않는다.\n\n예: 제품이 사용자 사진을 업로드한다고 합시다. 앱은 "이미지 리사이즈" 작업을 큐에 씁니다. 워커 A가 가져가 썸네일을 만들고 저장한 뒤 작업을 완료로 표시합니다. 작업이 두 번 실행되어도 출력이 동일하면(멱등성) 적어도 한 번 전달이 허용됩니다. 다른 서비스가 그 작업을 나중에 읽을 필요도 없습니다.\n\n요구가 공유 사실(여러 소비자), 재생, 감사, 또는 "지난주 시스템이 무엇을 믿고 있었나?" 쪽으로 이동하면 Kafka 이벤트 스트리밍과 로그 기반 접근이 가치가 생깁니다.\n\n## 로그 기반 접근이 유리할 때\n\n이벤트가 일회성 메시지가 아니라 공유되는 히스토리가 될 때 로그 기반 시스템이 효과를 발휘합니다. "보내고 잊기" 대신 여러 팀이 자신의 속도로 읽고 나중에 재생할 수 있는 순서화된 기록을 유지합니다.\n\n가장 분명한 신호는 다수의 소비자입니다. OrderPlaced 같은 이벤트 하나가 청구, 이메일, 부정행위 검사, 검색 인덱싱, 분석을 모두 공급할 수 있습니다. 로그를 사용하면 각 소비자가 동일한 스트림을 독립적으로 읽습니다. 맞춤형 팬아웃 파이프라인을 만들거나 메시지를 누가 먼저 받는지 조정할 필요가 없습니다.\n\n또 다른 장점은 "당시 우리가 무엇을 알고 있었나?"에 답할 수 있다는 점입니다. 고객이 요금에 대해 이의를 제기하거나 추천이 잘못되었다고 하면, 추가된 히스토리를 재생하면 사건이 도착했을 때의 사실을 다시 볼 수 있습니다. 이러한 감사 추적을 단순 큐에 나중에 붙이는 것은 어렵습니다.\n\n또한 새 기능을 기존 시스템을 다시 쓰지 않고 추가할 수 있는 실용적인 방법을 얻게 됩니다. 몇 달 후 새 "배송 상태" 페이지를 추가하면 새 서비스가 구독하고 기존 히스토리를 백필해 상태를 구성할 수 있습니다. 업스트림 팀에게 매번 데이터 익스포트를 부탁할 필요가 없습니다.\n\n로그 기반 접근이 가치가 있는 상황은 다음과 같습니다:\n\n- 동일한 이벤트가 여러 시스템(분석, 검색, 청구, 지원 도구)에 공급되어야 할 때.\n- 재생, 감사, 과거 사실 기반 조사 기능이 필요할 때.\n- 새 서비스가 원할 때 백필(backfill)을 자체적으로 수행해야 할 때.\n\n- 엔터티별(order, user 등)로 정렬이 중요할 때.\n- 이벤트 포맷이 진화하고 버전 관리를 통제할 필요가 있을 때.\n\n일반적인 패턴은 주문과 이메일로 시작한 제품이 나중에 재무가 수익 리포트를 원하고, 제품팀이 퍼널을 원하며, 운영팀이 실시간 대시보드를 원하는 경우입니다. 각 새 요구가 데이터를 새로운 파이프라인으로 복사하게 만들면 비용이 금세 커집니다. 공유 이벤트 로그는 팀들이 같은 진실의 출처를 기반으로 구축하게 해줍니다.\n\n## 단계별로 결정하는 방법\n\n단순 큐와 로그 기반 접근 사이를 선택하는 것은 제품 결정처럼 취급하면 쉽습니다. 이번 주에 작동하는 것뿐 아니라 1년 후에도 성립해야 할 것을 기준으로 시작하세요.\n\n### 실용적인 5단계 결정\n\n1) 게시자와 읽는자를 맵으로 그리세요. 오늘 이벤트를 생성하는 주체와 읽는 주체를 적고, 분석·검색 인덱싱·부정행위 검사·고객 알림 같은 향후 소비자를 추가하세요. 같은 이벤트를 여러 팀이 독립적으로 읽을 것으로 예상되면 로그가 타당해집니다.\n\n2) 히스토리를 다시 읽어야 할지 질문하세요. 버그 이후 재생, 백필, 서로 다른 속도로 읽는 소비자 등 이유를 구체적으로 적으세요. 큐는 작업을 한 번 넘겨주는 데 좋고, 로그는 재생 가능한 기록을 원할 때 낫습니다.\n\n3) 무엇을 "완료"로 볼지 정의하세요. 일부 워크플로는 "작업이 실행되었다"면 완료입니다(이메일 전송, 이미지 리사이즈). 다른 워크플로는 "이벤트가 내구성 있는 사실이다"가 완료 기준입니다(주문 생성, 결제 승인). 내구성 있는 사실은 로그를 향하게 합니다.\n\n4) 전달 기대치와 중복 처리를 어떻게 할지 결정하세요. at-least-once 전달이 흔하므로 중복이 발생할 수 있습니다. 중복이 큰 피해를 줄 수 있다면 멱등성을 계획하세요: 처리된 이벤트 ID를 저장하거나 고유 제약을 사용하거나 업데이트를 반복해도 안전하게 만드세요.\n\n5) 얇은 슬라이스(one thin slice)로 시작하세요. 하나의 이벤트 스트림을 선택해 집중하고 거기서 확장하세요. Kafka 이벤트 스트리밍을 선택하면 첫 토픽을 집중시키고 이벤트 이름을 명확히 하며 관련 없는 이벤트 유형을 섞지 마세요.\n\n구체적 예: OrderPlaced가 나중에 배송, 청구, 지원, 분석을 공급할 것이라면 로그는 각 팀이 자신의 속도로 읽고 실수 후 재생할 수 있게 합니다. 단순 영수증 이메일 전송 같은 배경 작업만 필요하다면 큐면 보통 충분합니다.\n\n## 예: 성장하는 제품의 주문 이벤트\n\n작은 온라인 상점을 상상해보세요. 처음에는 주문을 받고 카드 결제를 하고 배송 요청을 만드는 것만 필요합니다. 가장 쉬운 버전은 체크아웃 후 단일 백그라운드 작업인 "주문 처리(process order)"입니다: 결제 API에 호출하고, 데이터베이스의 주문 행을 업데이트하고, 배송을 호출합니다.\n\n그 큐 스타일은 하나의 명확한 워크플로가 있고 하나의 소비자(워커)만 필요하며 재시도와 데드레터가 대부분 실패 사례를 커버할 때 잘 동작합니다.\n\n상점이 성장하면 문제가 생깁니다. 지원팀은 자동 "내 주문은 어디에 있나?" 업데이트를 원합니다. 재무팀은 일일 수익을 원합니다. 제품팀은 고객 이메일을 원합니다. 배송 전에 부정행위 검사가 필요합니다. 단일 "주문 처리" 작업으로는 같은 워커를 계속 편집하고 분기(branch)를 추가하게 되어 핵심 흐름에 새로운 버그를 도입할 위험이 커집니다.\n\n로그 기반 접근에서는 체크아웃이 작은 사실을 이벤트로 발행하고 각 팀이 그 위에 구축합니다. 전형적인 이벤트는 다음과 같습니다:\n\n- OrderPlaced\n- PaymentConfirmed\n- ItemShipped\n- RefundIssued\n\n핵심 변화는 소유권입니다. 체크아웃 서비스는 OrderPlaced를 소유합니다. 결제 서비스는 PaymentConfirmed를 소유합니다. 배송은 ItemShipped를 소유합니다. 이후 새 소비자가 나타나도 프로듀서를 변경할 필요가 없습니다: 부정행위 서비스는 OrderPlaced와 PaymentConfirmed를 읽어 위험 점수를 매기고, 이메일 서비스는 영수증을 보내고, 분석은 퍼널을 만들며, 지원 도구는 사건 타임라인을 유지합니다.\n\n이것이 Kafka 이벤트 스트리밍이 가치 있는 부분입니다: 로그가 히스토리를 보관하므로 새 소비자는 처음부터(또는 알려진 지점부터) 되감아 따라잡을 수 있습니다. 업스트림 팀에게 매번 웹훅을 추가해달라고 요청할 필요가 없습니다.\n\n로그가 데이터베이스를 대체하지는 않습니다. 최신 주문 상태, 고객 레코드, 재고 수량, 트랜잭션 규칙(예: 결제가 확인되지 않으면 발송 금지) 등 현재 상태를 위한 데이터베이스는 여전히 필요합니다. 로그는 변경의 기록이고 데이터베이스는 "지금 무엇이 사실인가"를 묻는 곳이라고 생각하세요.\n\n## 흔한 실수와 함정\n\n이벤트 스트리밍은 시스템을 더 깔끔하게 만들 수 있지만 몇 가지 흔한 실수는 이점을 빠르게 없애버립니다. 대부분은 이벤트 로그를 기록이 아니라 원격 제어(remote control)로 취급할 때 발생합니다.\n\n자주 발생하는 함정은 이벤트를 명령(command)처럼 쓰는 것입니다. 예: SendWelcomeEmail이나 ChargeCardNow 같은 이벤트는 소비자를 의도에 강하게 결합시킵니다. 이벤트는 사실로서 기록하는 것이 더 낫습니다: UserSignedUp이나 PaymentAuthorized처럼. 사실은 시간이 지나도 재사용되기 쉽습니다.\n\n중복과 재시도도 고통의 큰 원천입니다. 실제 시스템에서 프로듀서는 재시도하고 소비자는 재처리합니다. 준비하지 않으면 중복 청구, 이중 이메일, 불만이 발생합니다. 해결책은 특별한 것이 아니라 의도적이어야 합니다: 멱등한 핸들러, 안정적인 이벤트 ID, 그리고 이미 적용되었음을 감지하는 비즈니스 규칙입니다.\n\n흔한 함정:\n\n- 서비스에 무엇을 하라고 지시하는 명령형 이벤트를 쓰는 것 대신 발생한 일을 기록하는 사실형 이벤트를 사용하지 않는 것.\n- 동일한 이벤트를 두 번 보면 깨지는 소비자 작성.\n- 하나의 비즈니스 흐름을 너무 일찍 분리해 여러 토픽에 흩어지게 만드는 것.\n- 작은 변경이 오래된 소비자를 깨뜨릴 때까지 스키마 규칙을 무시하는 것.\n- 스트리밍을 좋은 데이터베이스 설계의 대체물로 보는 것.\n\n스키마와 버전 관리는 특별한 주의가 필요합니다. JSON으로 시작하더라도 명확한 계약이 필요합니다: 필수 필드, 선택적 필드, 변경 롤아웃 방식. 필드 이름 변경 같은 작은 변경이 분석, 청구, 모바일 앱을 조용히 깨뜨릴 수 있습니다.\n\n또 다른 함정은 과도한 분리입니다. 팀들이 기능마다 새 스트림을 만들면 한 달 뒤엔 "주문의 현재 상태가 무엇인가?"를 아무도 대답할 수 없게 됩니다.\n\n이벤트 스트리밍은 견고한 데이터 모델의 필요성을 없애지 않습니다. 여전히 현재 진실을 나타내는 데이터베이스가 필요합니다. 로그는 히스토리일 뿐 전체 애플리케이션을 대체하지 않습니다.\n\n## 빠른 체크리스트와 다음 단계\n\n큐와 Kafka 이벤트 스트리밍 사이에서 결정하기 어렵다면 몇 가지 빠른 점검으로 시작하세요. 이 질문들은 단순한 작업 전달이 필요한지, 아니면 여러 해 동안 재사용할 수 있는 로그가 필요한지를 알려줍니다.\n\n### 빠른 확인 항목\n\n- 재생이 필요한가(백필, 버그 수정, 새 기능) 그리고 얼마나 오래까지 필요한가?\n- 지금이나 곧 동일한 이벤트를 둘 이상의 소비자가 필요로 하는가(분석, 검색, 이메일, 부정행위, 청구)?\n- 프로듀서에게 다시 요청하지 않고 팀이 히스토리를 다시 읽을 수 있도록 보존이 필요한가?\n- 정렬(ordering)은 얼마나 중요한가, 어떤 수준에서: 엔터티별(주문별, 사용자별)인지 전역적인지?\n- 소비자를 멱등하게 만들 수 있는가(같은 이벤트를 재시도해도 이중 청구·이중 이메일·이중 업데이트가 일어나지 않음)?\n\n"재생 불필요", "소비자 1개만", "단기간 메시지"에 모두 해당하면 기본 큐로도 충분한 경우가 많습니다. "재생 필요", "다중 소비자", "장기 보존" 중 하나라도 해당하면 로그 기반 접근이 더 유리합니다.\n\n### 다음 단계\n\n답을 바탕으로 작고 테스트 가능한 계획을 만드세요.\n\n- 5orderId 같은 엔터티별)를 결정하고 "정확한 순서"가 무엇인지 문서화하세요.\n- 소비자별 멱등성 규칙을 정의하세요(예: 주문별 마지막 처리된 이벤트 ID 저장).\n- 필요에 맞는 보존 기간을 선택하세요(큐와 비슷한 워크플로우면 며칠, 재생이 중요하면 몇 주큐는 처리하고 잊어버리는 작업 티켓에 적합합니다(예: 이메일 전송, 이미지 리사이즈, 작업 실행). 로그는 보관하고 여러 시스템이 나중에 다시 읽고 재생할 수 있는 사실에 적합합니다(예: 주문 발생, 결제 승인, 환불 처리).
새 기능을 추가할 때마다 여러 통합 지점을 건드려야 하고, 디버깅 시 “이 값을 누가 썼지?” 같은 질문이 생기면 문제가 시작됩니다. 로그는 공유된 기록이 되어 과거를 검사하고 재생할 수 있기 때문에 이런 상황에서 큰 도움이 됩니다.
로그 기반 접근은 다음과 같은 경우에 가치가 큽니다: 버그를 고치기 위해 과거를 재처리해야 할 때, 새로운 기능을 과거 데이터로 백필해야 할 때, “당시 우리는 무엇을 알고 있었나?” 같은 조사가 필요할 때, 또는 청구·분석·지원·사기 탐지 등 여러 소비자가 동일한 이벤트를 필요로 할 때.
시스템이 커지면 재시도, 타임아웃, 부분 장애, 수동 수정 같은 복잡한 실패가 발생합니다. 서비스들이 서로 직접 업데이트하면 서로 다른 기록을 가지기 쉽습니다. 추가된 이벤트를 덧붙이는(append-only) 히스토리는 다운된 소비자가 복구 후 따라잡을 수 있게 해주어 '진실의 출처' 논쟁을 완화합니다.
이벤트를 과거형의 불변한 사실으로 모델링하세요. 예:\n\n- OrderPlaced (x ProcessOrder)\n- PaymentAuthorized (x ChargeCardNow)\n- UserEmailChanged (x UpdateEmail)\n\n무언가가 바뀌면 기존 항목을 편집하지 말고 새로운 이벤트로 그 변화를 게시하세요.
중복은 발생한다고 가정하세요(대부분 at-least-once 전달을 사용). 각 소비자를 재시도해도 안전하게 만들려면:\n\n- 안정적인 이벤트 ID를 사용하고 “이미 처리됨” 표시를 저장하세요.\n- 가능한 곳에는 고유 제약을 적용하세요.\n- 같은 이벤트를 두 번 적용해도 부작용이 생기지 않도록 설계하세요(예: 이중 과금 방지).\n\n기본 규칙: 정확성 우선, 속도는 그 다음입니다.
추가 필드를 허용하는 방식으로 변경을 진행하세요: 기존 필드는 유지하고 새 필드는 선택적으로 추가하며, 필드 이름 변경이나 제거는 피하세요. 깨지는 변경이 필요하면 이벤트(또는 토픽)를 버전 관리하고 소비자들을 의도적으로 마이그레이션하세요.
작고 끝에서 끝까지 동작하는 한 조각으로 시작하세요:\n\n1. 단일 비즈니스 흐름을 선택하세요(예: OrderPlaced → 영수증 이메일).\n2. 명확한 이벤트 이름과 필수 필드를 정의하세요.\n3. 정렬 키(보통 orderId 또는 userId)를 선택하세요.\n4. 소비자를 멱등하게 만드세요.\n5. 테스트 중 재생할 수 있도록 보존 기간을 충분히 설정하세요.\n\n루프가 작동하는 것을 증명한 후 확장하세요.
아니요. 현재 상태와 트랜잭션(“지금 무엇이 참인가”)을 위한 데이터베이스는 유지하세요. 이벤트 로그는 히스토리와 파생 뷰(분석 테이블, 검색 인덱스, 타임라인)를 재구성하는 데 사용하세요. 실무적으로는: 데이터베이스는 현재 상태, 로그는 변경의 기록입니다.
계획 모드는 게시자/소비자를 매핑하고 이벤트 이름, 멱등성, 보존 정책을 결정하는 데 유용합니다. 그런 다음 작고 안정된 producer-consumer 조각을 구현하고 스냅샷과 롤백으로 실험하세요. 안정되면 소스 코드를 내보내 배포할 수 있습니다.