2025년 8월 07일·6분
노암 샤지어와 LLM 뒤의 트랜스포머 아키텍처
노암 샤지어가 트랜스포머 설계에 어떤 기여를 했는지, 셀프 어텐션·멀티헤드 어텐션·포지셔널 인코딩 등 핵심 요소가 왜 현대 LLM의 기반이 되었는지 알아보세요.
노암 샤지어가 트랜스포머 설계에 어떤 기여를 했는지, 셀프 어텐션·멀티헤드 어텐션·포지셔널 인코딩 등 핵심 요소가 왜 현대 LLM의 기반이 되었는지 알아보세요.
트랜스포머는 문장, 코드, 검색 쿼리처럼 순서와 문맥이 중요한 시퀀스를 컴퓨터가 이해하도록 돕는 방식입니다. 약한 메모리를 단계별로 이어가는 대신, 트랜스포머는 전체 시퀀스를 살펴보고 각 부분을 해석할 때 무엇에 주목할지 결정합니다.
이 단순한 변화가 큰 차이를 만들었습니다. 현대의 대형 언어 모델(LLM)이 문맥을 유지하고, 지침을 따르며, 일관된 단락을 쓰고, 이전의 함수나 변수를 참조하는 코드를 생성할 수 있는 주된 이유 중 하나가 바로 이것입니다.
챗봇, "요약하기" 기능, 의미 기반 검색, 코딩 어시스턴트를 사용해본 적이 있다면 트랜스포머 기반 시스템과 상호작용한 것입니다. 동일한 핵심 설계가 다음을 뒷받침합니다:
셀프 어텐션, 멀티헤드 어텐션, 포지셔널 인코딩, 기본 트랜스포머 블록의 구성 요소를 분해하고, 왜 이 설계가 모델 규모가 커질수록 잘 확장되는지 설명합니다.
또한 같은 핵심 아이디어를 유지하면서 속도, 비용, 더 긴 컨텍스트 창을 위해 변형된 최신 기법들도 간단히 다룹니다.
이 글은 수식을 최소화한 직관적 설명의 하이레벨 투어입니다. 목표는 각 구성요소가 무엇을 하는지, 왜 함께 작동하는지, 그리고 그것이 실제 제품 기능으로 어떻게 이어지는지에 대한 감을 잡게 하는 것입니다.
노암 샤지어는 2017년 논문 *"Attention Is All You Need"*의 공저자로 가장 잘 알려진 AI 연구자 겸 엔지니어입니다. 그 논문은 트랜스포머 아키텍처를 소개했고, 이후 많은 현대 LLM의 기반이 되었습니다. 샤지어의 작업은 팀 노력 속에 자리한다는 점을 기억하는 것이 중요합니다: 트랜스포머는 구글의 연구자 그룹이 만든 산물입니다.
트랜스포머 이전에는 많은 NLP 시스템이 텍스트를 한 단계씩 처리하는 순환 모델에 의존했습니다. 트랜스포머 제안은 어텐션을 주된 메커니즘으로 사용해, 순환 없이도 시퀀스를 효과적으로 모델링할 수 있음을 보여주었습니다.
이 변화는 병렬화된 학습을 쉽게 해주었고(여러 토큰을 한꺼번에 처리할 수 있음), 모델과 데이터셋을 확장하는 길을 열어 실용적인 제품으로 빠르게 이어질 수 있게 했습니다.
샤지어의 기여는 다른 저자들의 기여와 함께 학술 벤치마크에 머무르지 않았습니다. 트랜스포머는 재사용 가능한 모듈이 되어 팀들이 구성요소를 교체하고, 크기를 조정하고, 과업에 맞게 튜닝하고, 나중에 대규모로 사전학습할 수 있게 되었습니다.
많은 돌파구가 이렇게 확산됩니다: 논문은 명확하고 일반적인 레시피를 제시하고, 엔지니어들이 이를 다듬고, 기업들이 운영화하며, 결국 언어 기능을 구축하는 기본 선택지가 됩니다.
샤지어가 트랜스포머 논문의 핵심 공저자였다고 말하는 것은 정확합니다. 그러나 그를 단독 발명자로 표현하는 것은 부정확합니다. 영향력은 집단적 설계와 그 원래 청사진 위에 커뮤니티가 쌓아 올린 수많은 개선에서 나왔습니다.
트랜스포머 이전에는 번역, 음성, 텍스트 생성 같은 시퀀스 문제를 주로 RNN(순환 신경망)과 이후의 LSTM(장단기 메모리 네트워크)이 지배했습니다. 기본 아이디어는 단순했습니다: 텍스트를 한 토큰씩 읽고, 누적되는 "메모리"(히든 상태)를 유지하며 다음을 예측하는 방식입니다.
RNN은 문장을 체인처럼 처리합니다. 각 단계는 현재 단어와 이전 히든 상태를 기반으로 히든 상태를 업데이트합니다. LSTM은 유지, 잊음, 출력 게이트를 추가해 유용한 신호를 더 오래 보유할 수 있게 개선했습니다.
실제에서는 순차적 메모리에 병목이 생깁니다: 문장이 길어질수록 많은 정보가 단일 상태에 압축되어야 합니다. LSTM을 써도 멀리 떨어진 단어의 신호는 희미해지거나 덮어써질 수 있습니다.
이로 인해 대명사를 멀리 앞선 명사와 연결하거나, 여러 절에 걸친 주제를 추적하는 것 같은 관계를 안정적으로 학습하기 어려웠습니다.
RNN과 LSTM은 시간 축으로 완전 병렬화할 수 없어 학습이 느립니다. 문장 내부에서는 단계 50이 단계 49에 의존하고, 49는 48에 의존하는 식입니다. 이 단계별 계산은 더 큰 모델, 더 많은 데이터, 더 빠른 실험을 원할 때 심각한 제약이 됩니다.
연구자들은 단지 좌→우로 엄격히 진행하지 않고도 단어들끼리 관계를 맺을 수 있는 설계가 필요했습니다—장거리 관계를 직접 모델링하고 현대 하드웨어를 더 잘 활용할 방법이 필요했습니다. 이런 압력이 Attention Is All You Need에서 소개된 어텐션 우선 접근을 탄생시켰습니다.
어텐션은 모델이 묻는 방식입니다: "지금 이 단어를 이해하려면 어떤 다른 단어들을 봐야 할까?"
순차적으로 문장을 읽으며 메모리가 버티기를 바라는 대신, 어텐션은 모델이 필요한 순간에 문장에서 가장 관련 있는 부분을 훑어볼 수 있게 합니다.
유용한 비유는 문장 내부에 작은 검색 엔진이 돌아가는 것입니다.
모델은 현재 위치의 쿼리를 만들고, 모든 위치의 키와 비교한 뒤 값의 혼합을 가져옵니다.
이 비교는 관련도 점수를 만듭니다: "얼마나 관련 있는가"의 신호입니다. 그런 다음 모델은 이를 어텐션 가중치로 변환하는데, 이 가중치들은 합이 1이 되는 비율들입니다.
어떤 단어가 매우 관련 있다면 더 큰 비중을 얻고, 여러 단어가 중요하면 어텐션이 그들 사이에 분산됩니다.
문장: "Maria told Jenna that she would call later."에서 she를 해석하기 위해 모델은 "Maria"와 "Jenna" 같은 후보를 돌아봐야 합니다. 어텐션은 문맥에 더 적절한 이름에 더 높은 가중치를 할당합니다.
또는 "The keys to the cabinet are missing." 같은 문장에서 어텐션은 "are"를 더 먼 단어인 "keys"(실제 주어)와 연결시키는 데 도움을 줍니다. 핵심 이점은 거리에 상관없이 의미를 연결할 수 있다는 점입니다.
셀프 어텐션은 시퀀스의 각 토큰이 같은 시퀀스 내의 다른 토큰들을 보며 지금 무엇이 중요한지 결정한다는 아이디어입니다. 옛 순환 모델처럼 엄격히 좌→우로 처리하는 대신, 트랜스포머는 모든 토큰이 입력 어디에서든 단서를 모을 수 있게 합니다.
예를 들어: "I poured the water into the cup because it was empty."에서 "it"은 "cup"과 연결되어야 합니다. 셀프 어텐션으로 "it" 토큰은 "cup"과 "empty" 같은 토큰에 더 높은 중요도를 부여하고 관련 없는 토큰에는 낮은 중요도를 줍니다.
셀프 어텐션 후, 각 토큰은 더 이상 그 자체만의 표현이 아닙니다. 그것은 다른 토큰들로부터 가중 혼합된 문맥 인지형 표현이 됩니다. 각 토큰이 필요로 하는 것에 맞춰 전체 문장의 개인화된 요약을 만든다고 생각할 수 있습니다.
실제로는 "cup"의 표현이 "poured", "water", "empty"로부터 신호를 담을 수 있고, "empty"는 그것이 설명하는 대상의 단서를 끌어올 수 있습니다.
각 토큰이 전체 시퀀스에 대한 어텐션을 동시에 계산할 수 있기 때문에 학습은 이전 토큰의 처리를 기다릴 필요가 없습니다. 이 병렬 처리 덕분에 트랜스포머는 대규모 데이터셋에서 효율적으로 학습하고 거대한 모델로 확장할 수 있습니다.
셀프 어텐션은 멀리 떨어진 텍스트 부분을 직접 연결하기 쉽게 합니다. 토큰은 중간 단계를 거치지 않고도 멀리 있는 관련 단어에 직접 초점을 맞출 수 있습니다.
이 직접 경로는 대명사 해소, 여러 단락에 걸친 주제 추적, 이전 세부사항에 의존하는 지침 처리 같은 작업에 특히 도움이 됩니다.
단일 어텐션 메커니즘도 강력하지만, 하나의 카메라 앵글만으로 대화를 이해하려는 것과 비슷한 한계가 있습니다. 문장에는 동시에 여러 관계가 존재할 수 있습니다: 누가 무엇을 했는지, "it"이 무엇을 가리키는지, 어조를 정하는 단어들, 전체 주제 등입니다.
"The trophy didn’t fit in the suitcase because it was too small"을 읽을 때 문법, 의미, 현실 세계 지식 등 여러 실마리를 동시에 추적해야 할 수 있습니다. 한 헤드는 가장 가까운 명사에 집중할 수 있고, 다른 헤드는 동사구를 사용해 "it"이 무엇을 가리키는지 결정할 수 있습니다.
멀티헤드 어텐션은 여러 어텐션 계산을 병렬로 실행합니다. 각 "헤드"는 다른 하위 공간(subspace)을 통해 문장을 보도록 유도되어 보통 다음과 같은 패턴에 특화됩니다:
각 헤드가 자체적인 통찰을 생산한 후, 모델은 그 중 하나만 선택하지 않습니다. 헤드 출력들을 **연결(concatenate)**하고 학습된 선형층으로 다시 **사영(project)**합니다.
여러 부분 노트를 하나의 깔끔한 요약으로 합치는 과정이라 생각하면 됩니다. 결과는 여러 관계를 동시에 담을 수 있는 표현으로, 트랜스포머가 대규모에서 잘 작동하는 이유 중 하나입니다.
셀프 어텐션은 관계를 잘 포착하지만 그 자체만으로는 누가 먼저 왔는지 알지 못합니다. 단어를 섞으면 단순 셀프 어텐션 레이어는 섞인 버전을 동일하게 처리할 수 있습니다. 포지셔널 인코딩은 "내가 시퀀스에서 어디에 있나?" 정보를 토큰 표현에 주입해 이 문제를 해결합니다.
핵심 아이디어는 간단합니다: 각 토큰 임베딩에 트랜스포머 블록에 들어가기 전에 위치 신호를 더합니다. 이 위치 신호는 토큰이 입력에서 1번째, 2번째, 3번째...라는 것을 태그하는 추가 특징 셋으로 생각할 수 있습니다.
일반적인 접근법:
포지셔널 선택은 긴 컨텍스트 모델링—긴 보고서 요약, 여러 단락에 걸친 엔터티 추적, 수천 토큰 이전에 언급된 세부사항 검색—에 눈에 띄는 영향을 줄 수 있습니다.
긴 입력에서는 모델이 단지 언어를 배우는 것이 아니라 어디를 볼지도 배우는 것입니다. 상대·로터리 스타일 기법은 먼 토큰들을 비교하고 컨텍스트가 커져도 패턴을 보존하기 쉬운 경향이 있으며, 일부 절대 방식은 학습 창을 넘어설 때 성능이 더 빨리 저하될 수 있습니다.
실무에서는 포지셔널 인코딩이 2,000토큰에서 날카롭고 일관된 LLM을 만들 수 있는지, 100,000토큰에서도 일관성을 유지하는지에 영향을 주는 조용한 설계 결정 중 하나입니다.
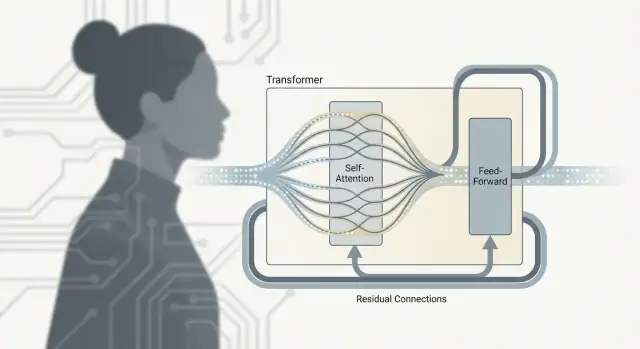
트랜스포머는 단순히 "어텐션"만 있는 것이 아닙니다. 실제 작업은 반복 단위(보통 트랜스포머 블록) 안에서 일어나며, 이 블록은 토큰들 간 정보를 섞고 그것을 정교화합니다. 이 블록을 여러 개 쌓으면 대형 언어 모델이 강력해지는 깊이를 얻습니다.
셀프 어텐션은 소통 단계입니다: 각 토큰이 다른 토큰들로부터 문맥을 수집합니다.
피드포워드 네트워크(FFN, 또는 MLP)는 사고 단계입니다: 업데이트된 각 토큰 표현에 동일한 작은 신경망을 독립적으로 적용합니다.
간단히 말해, FFN은 각 토큰이 수집한 문맥을 변환·재형성하여 구문 패턴, 사실, 스타일 단서 같은 더 풍부한 특징을 만들도록 돕습니다.
두 부분은 서로 다른 일을 하기 때문에 번갈아 가며 배치하는 것이 중요합니다:
이 패턴을 반복하면 모델이 점진적으로 더 높은 수준의 의미를 구성합니다: 소통, 계산, 다시 소통, 다시 계산.
각 서브레이어(어텐션 또는 FFN)는 잔차 연결로 감싸져 있습니다: 입력을 출력에 더합니다. 이는 깊은 모델이 학습될 때 그라디언트가 "스킵 레인"을 통해 흐르도록 도와주어 학습을 쉽게 하고, 레이어가 모든 것을 재학습하지 않고도 작은 수정만 하도록 합니다.
레이어 정규화는 활성화가 여러 층을 통과하면서 너무 크거나 작아지지 않도록 해줍니다. 이를 통해 후속 층이 신호에 질식당하거나 신호 부족에 시달리지 않게 해 학습을 더 부드럽고 안정적으로 만듭니다—특히 LLM 규모에서 중요합니다.
원래의 트랜스포머는 기계번역을 위해 만들어졌고, 한 시퀀스(예: 프랑스어)를 다른 시퀀스(예: 영어)로 변환하는 작업이어서 자연스럽게 두 역할로 나뉘었습니다: **읽기(encoding)**와 쓰기(decoding).
인코더–디코더 트랜스포머에서 인코더는 전체 입력 문장을 한 번에 처리해 풍부한 표현 집합을 만듭니다. 디코더는 출력을 한 토큰씩 생성하면서 인코더 출력에 대한 크로스 어텐션을 사용해 소스 텍스트에 기반을 둡니다.
이 구성은 번역, 요약, 특정 문단에 기반한 질의응답처럼 입력에 강하게 조건화해야 하는 작업에 여전히 탁월합니다.
현대 대부분의 대형 언어 모델은 디코더 전용입니다. 단순하지만 강력한 과제인 다음 토큰 예측을 학습합니다.
이를 위해 마스킹된(self-attention, causal) 셀프 어텐션을 사용해 각 위치가 오직 이전 토큰들만 볼 수 있게 하고, 생성 시에는 왼쪽에서 오른쪽으로 계속 확장해 나가도록 보장합니다.
이 방식은 대규모 텍스트 말뭉치로 학습하기 쉽고, 생성 사용 사례와 직접적으로 일치하며, 데이터와 연산 측면에서 효율적으로 확장됩니다.
인코더 전용(BERT 스타일) 트랜스포머는 텍스트를 양방향으로 읽고, 길게 생성하지는 않습니다. 분류, 검색, 임베딩 생성처럼 텍스트 이해가 생성보다 중요한 작업에 적합합니다.
트랜스포머는 놀랍도록 확장 친화적이라는 점이 드러났습니다: 더 많은 텍스트, 더 많은 연산, 더 큰 모델을 주면 예측 가능한 방식으로 성능이 꾸준히 좋아지는 경향이 있습니다.
큰 이유 중 하나는 구조적 단순성입니다. 트랜스포머는 반복되는 블록(셀프 어텐션 + 작은 FFN + 정규화)으로 구성되며, 이 블록들은 백만 단어로 학습하든 조 단위 단어로 학습하든 유사하게 동작합니다.
이전의 시퀀스 모델(RNN 등)은 토큰을 하나씩 처리해야 했습니다. 반면 트랜스포머는 학습 중에 시퀀스의 모든 토큰을 병렬로 처리할 수 있습니다.
이 점이 GPU/TPU와 분산 학습 환경에 매우 적합하게 만들어 현대 LLM을 학습할 때 결정적인 이점을 제공합니다.
컨텍스트 창은 모델이 한 번에 "볼" 수 있는 텍스트 덩어리입니다—프롬프트와 최근 대화나 문서 텍스트를 포함합니다. 더 큰 창은 모델이 더 많은 문장이나 페이지에 걸쳐 아이디어를 연결하고 제약을 유지하며, 이전 세부사항에 의존하는 질문에 답할 수 있게 합니다.
하지만 컨텍스트는 무료가 아닙니다.
셀프 어텐션은 토큰들을 서로 비교합니다. 시퀀스가 길어질수록 비교 횟수가 급격히 증가(대략 길이의 제곱)합니다.
그래서 아주 긴 컨텍스트 창은 메모리와 연산 면에서 부담스럽고, 많은 최신 연구는 어텐션을 더 효율적으로 만드는 데 집중합니다.
트랜스포머를 대규모로 학습하면 특정 과제 하나만 잘하는 것이 아니라 요약, 번역, 글쓰기, 코딩, 추론 등 폭넓고 유연한 능력이 등장하는 경우가 많습니다. 이는 같은 일반적 학습 기제가 방대한 다양하고 방대한 데이터에 적용되기 때문입니다.
원래 트랜스포머 설계는 여전히 기준점이지만, 대부분의 생산용 LLM은 "트랜스포머 플러스": 핵심 블록(어텐션 + MLP)은 유지하면서 속도, 안정성, 컨텍스트 길이를 개선하는 작은 실용적 수정들을 더한 형태입니다.
많은 업그레이드는 모델의 "정체성"을 바꾸기보다 학습과 실행을 더 좋게 만드는 데 초점이 맞춰져 있습니다:
이 변화들은 보통 모델의 근본적 "트랜스포머성"을 바꾸지 않고 정교하게 다듬는 역할을 합니다.
수천 토큰에서 수만~수십만 토큰으로 컨텍스트를 확장하려면 보통 희소 어텐션(선택된 토큰만 주목)이나 효율적 어텐션 변형(연산을 근사 또는 재구조화) 같은 기법이 필요합니다.
트레이드오프는 정확성, 메모리, 엔지니어링 복잡성 사이의 균형입니다.
MoE 모델은 여러 개의 "전문가" 서브네트워크를 추가하고 각 토큰은 그 중 일부만 통과시키는 방식입니다. 개념적으로는 더 큰 두뇌를 얻되 매번 전부를 활성화하지 않는 것입니다.
이 방식은 파라미터 수에 비해 토큰당 연산을 낮출 수 있지만 라우팅, 전문가 균형, 서빙 복잡성이 증가합니다.
새로운 트랜스포머 변형을 내세우는 모델을 볼 때는 다음을 요구하세요:
대부분의 개선은 실재하지만, 대개 공짜는 아닙니다.
셀프 어텐션과 스케일링 같은 트랜스포머 아이디어는 흥미롭지만, 제품팀은 주로 그것을 토큰으로 얼마나 넣을 수 있는지, 답을 얼마나 빨리 받는지, 요청당 비용은 얼마인지 같은 트레이드오프로 체감합니다.
컨텍스트 길이: 더 긴 컨텍스트는 더 많은 문서, 대화 기록, 지침을 포함할 수 있게 합니다. 그러나 토큰 지출이 늘고 응답이 느려집니다. "30페이지를 읽고 답변" 같은 기능이 필요하면 컨텍스트 길이를 최우선으로 고려하세요.
지연성(Latency): 사용자 대상 채팅과 코파일럿 경험은 응답 시간에 좌우됩니다. 스트리밍 출력이 도움이 되지만 모델 선택, 리전, 배치 처리도 중요합니다.
비용: 보통 입력+출력 토큰 단위로 과금됩니다. 10% 더 "나은" 모델이 비용은 2~5배일 수 있습니다. 어떤 품질 수준에 비용을 지불할지 가격 비교로 결정하세요.
품질: 귀하의 사용 사례에 맞게 정의하세요: 사실성, 지침 준수, 톤, 도구 사용 능력, 코드 품질 등. 일반 벤치마크가 아니라 도메인 샘플로 평가하세요.
검색, 중복 제거, 클러스터링, 추천, "유사한 것 찾기" 등이 주 목적이라면 임베딩(대개 인코더 스타일 모델)이 보통 더 저렴하고 빠르며 안정적입니다. 검색 후 최종 단계에서(요약, 설명 작성, 초안 작성 등)만 생성 모델을 사용하세요.
더 깊은 분석을 위해 팀에 기술 해설 글을 연결하려면 /blog/embeddings-vs-generation 을 참고하세요.
트랜스포머 능력을 제품으로 전환할 때 어려운 부분은 아키텍처 자체보다 그 주변 워크플로우인 경우가 많습니다: 프롬프트 반복, 근거(grounding), 평가, 안전한 배포 등입니다.
실용적인 경로의 하나는 Koder.ai 같은 vibe-coding 플랫폼을 사용해 LLM 기반 기능을 빠르게 프로토타이핑하고 배포하는 것입니다: 웹앱, 백엔드 엔드포인트, 데이터 모델을 채팅으로 설명하고 계획 모드에서 반복한 뒤 소스 코드를 내보내거나 호스팅, 맞춤 도메인, 스냅샷을 통한 롤백으로 배포할 수 있습니다. 검색, 임베딩, 도구 호출 루프를 실험할 때 동일한 스캐폴딩을 다시 만들지 않고도 빠르게 반복하기 좋습니다.
트랜스포머는 같은 입력 안의 모든 토큰이 서로를 참조할 수 있게 하는 신경망 아키텍처로, 셀프 어텐션을 사용해 각 토큰이 다른 토큰과 어떻게 관련되는지 학습합니다.
RNN/LSTM처럼 정보를 한 단계씩 전달하는 대신, 전체 시퀀스에서 "무엇에 주목할지" 결정해 문맥을 구성하므로 장거리 의존성을 더 잘 처리하고 병렬 학습이 가능합니다.
RNN과 LSTM은 텍스트를 한 토큰씩 처리하므로 시퀀스 내에서 단계별로 계산이 이어져야 하고, 장거리 의존성 정보가 단일 상태에 압축되는 병목이 생깁니다.
트랜스포머는 어텐션으로 먼 토큰들끼리 직접 연결하고 학습 시 많은 토큰 상호작용을 병렬로 계산할 수 있어, 더 빠르게 확장하고 대규모 데이터와 연산에서 성능을 끌어낼 수 있었습니다.
어텐션은 **“이 토큰을 이해하기 위해 지금 어떤 다른 토큰들을 봐야 할까?”**라는 질문에 답하는 메커니즘입니다.
작동 방식은 내부 검색과 비슷합니다:
결과는 관련 토큰을 가중합한 출력으로, 각 위치는 문맥을 반영한 표현을 얻습니다.
셀프 어텐션은 같은 시퀀스 안의 토큰들이 서로를 참조하는 것을 의미합니다.
이를 통해 모델은 대명사 해소(예: "it"가 무엇을 가리키는지), 절을 넘는 주어–동사 관계 등, 텍스트 내 먼 거리의 의존성을 직접 해결할 수 있습니다. 이전처럼 모든 정보를 단일 순환 상태에 의존할 필요가 없습니다.
멀티헤드 어텐션은 여러 개의 어텐션 연산을 병렬로 수행하는 구조로, 각 헤드는 다른 유형의 패턴을 포착하도록 특화될 수 있습니다.
실전에서는 서로 다른 헤드들이 구문적 연결, 장거리 링크, 대명사 해소, 주제 신호 등 다양한 관계에 집중하고, 최종적으로 이들을 합쳐 더 풍부한 표현을 만듭니다.
셀프 어텐션만으로는 토큰의 순서를 알 수 없습니다—단어 순서를 섞어도 토큰 간 관계만으로는 같은 입력처럼 보일 수 있습니다.
그래서 포지셔널 인코딩(위치 정보)을 토큰 임베딩에 더해 순서를 알려줍니다. 대표적인 방식으로는 사인·코사인 기반의 고정 인코딩, 학습 가능한 절대 위치 벡터, 그리고 상대적/로터리(rotary) 스타일 방법 등이 있습니다.
트랜스포머 블록은 보통 다음을 조합합니다:
이들을 쌓아 깊이를 만들면 더 높은 수준의 의미와 기능을 학습하게 됩니다.
원래 논문의 트랜스포머는 인코더–디코더 구조로, 인코더가 입력을 읽고 디코더가 출력(번역문 등)을 생성하며 인코더 출력에 대해 크로스 어텐션을 사용합니다.
그러나 오늘날 대부분의 LLM은 디코더 전용(decoder-only) 모델로, 다음 토큰 예측을 학습합니다. 이 경우 마스킹된(인과적, causal) 셀프 어텐션을 사용해 왼쪽부터 오른쪽으로 생성하도록 보장합니다.
노암 샤지어(Noam Shazeer)는 2017년 논문 *"Attention Is All You Need"*의 공저자 중 한 명으로, 트랜스포머의 개발에 중요한 기여를 했습니다.
하지만 트랜스포머 아키텍처는 구글 내 연구팀의 공동 작업 결과이며, 이후 커뮤니티와 산업계의 다양한 개선들이 합쳐져 지금의 영향력을 만들어 냈습니다. 따라서 그를 주요 기여자로 인정하되 단독 발명자로 단정하는 것은 정확하지 않습니다.
표준 셀프 어텐션은 시퀀스 길이에 대해 연산 비용이 대략 제곱적으로 증가하므로 긴 입력은 메모리와 계산 측면에서 비쌉니다.
실무적 대응법으로는:
이런 절충을 통해 긴 문서 처리의 비용을 관리합니다.