Mar 11, 2025·8 min
Practical Security Lessons from Bruce Schneier
Learn the practical security mindset Bruce Schneier advocates: threat models, human behavior, and incentives that shape real risk beyond crypto buzzwords.
Learn the practical security mindset Bruce Schneier advocates: threat models, human behavior, and incentives that shape real risk beyond crypto buzzwords.
Security marketing is full of shiny promises: “military‑grade encryption,” “AI‑powered protection,” “zero trust everywhere.” Day to day, most breaches still happen through mundane paths—an exposed admin panel, a reused password, a rushed employee approving a fake invoice, a misconfigured cloud bucket, an unpatched system that everyone assumed was “someone else’s problem.”
Bruce Schneier’s enduring lesson is that security isn’t a product feature you sprinkle on top. It’s a practical discipline of making decisions under constraints: limited budget, limited time, limited attention, and imperfect information. The goal isn’t to “be secure.” The goal is to reduce the risks that actually matter to your organization.
Practical security asks a different set of questions than vendor brochures:
That mindset scales from small teams to large enterprises. It works whether you’re buying tools, designing a new feature, or responding to an incident. And it forces trade‑offs into the open: security vs. convenience, prevention vs. detection, speed vs. assurance.
This isn’t a tour of buzzwords. It’s a way to choose security work that produces measurable risk reduction.
We’ll keep coming back to three pillars:
If you can reason about those three, you can cut through hype and focus on the security decisions that pay off.
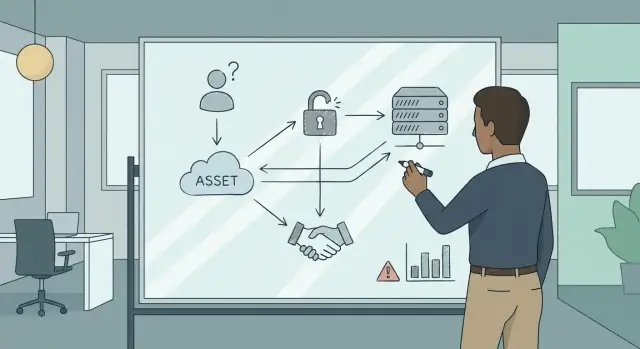
Security work goes off the rails when it starts with tools and checklists instead of purpose. A threat model is simply a shared, written explanation of what could go wrong for your system—and what you’re going to do about it.
Think of it as planning a trip: you don’t pack for every possible climate on Earth. You pack for the places you’ll actually visit, based on what would hurt if it went wrong. A threat model makes that “where we’re going” explicit.
A useful threat model can be built by answering a few basic questions:
These questions keep the conversation grounded in assets, adversaries, and impact—rather than in security buzzwords.
Every threat model needs boundaries:
Writing down what’s out of scope is healthy because it prevents endless debates and clarifies ownership.
Without a threat model, teams tend to “do security” by grabbing a standard list and hoping it fits. With a threat model, controls become decisions: you can explain why you need rate limits, MFA, logging, or approvals—and just as importantly, why some expensive hardening doesn’t meaningfully reduce your real risk.
A threat model stays practical when it starts with three plain questions: what you’re protecting, who might go after it, and what happens if they succeed. This keeps security work tied to real outcomes instead of vague fear.
Assets aren’t just “data.” List the things your organization truly depends on:
Be specific. “Customer database” is better than “PII.” “Ability to issue refunds” is better than “financial systems.”
Different attackers have different capabilities and motivations. Common buckets:
Describe what they’re trying to do: steal, disrupt, extort, impersonate, spy. Then translate that into business impact:
When impact is clear, you can prioritize defenses that reduce real risk—not just add security-looking features.
It’s natural to focus on the most frightening outcome: “If this fails, everything burns.” Schneier’s point is that severity alone doesn’t tell you what to work on next. Risk is about expected harm, which depends on both impact and likelihood. A catastrophic event that’s extremely unlikely can be a worse use of time than a modest issue that happens every week.
You don’t need perfect numbers. Start with a rough likelihood × impact matrix (Low/Medium/High) and force trade‑offs.
Example for a small SaaS team:
This framing helps you justify unglamorous work—rate limiting, MFA, anomaly alerts—over “movie-plot” threats.
Teams often defend against rare, headline-worthy attacks while ignoring the boring stuff: password reuse, misconfigured access, insecure defaults, unpatched dependencies, or fragile recovery processes. That’s adjacent to security theater: it feels serious, but it doesn’t reduce the risk you’re most likely to face.
Likelihood and impact shift as your product and attackers change. A feature launch, new integration, or growth spurt can raise impact; a new fraud trend can raise likelihood.
Make risk a living input:
Security failures often get summarized as “humans are the attack surface.” That line can be useful, but it’s also frequently shorthand for we shipped a system that assumes perfect attention, perfect memory, and perfect judgment. People aren’t weak; the design is.
A few common examples show up in almost every organization:
These are not moral failures. They’re outcomes of incentives, time pressure, and interfaces that make the risky action the easiest action.
Practical security leans on reducing the number of risky decisions people must make:
Training helps when it’s framed as tooling and teamwork: how to verify requests, where to report, what “normal” looks like. If training is used to punish individuals, people hide mistakes—and the organization loses the early signals that prevent bigger incidents.
Security decisions are rarely just technical. They’re economic: people respond to costs, deadlines, and who gets blamed when something goes wrong. Schneier’s point is that many security failures are “rational” outcomes of misaligned incentives—even when engineers know what the right fix is.
A simple question cuts through a lot of debate: who pays the cost of security, and who receives the benefit? When those are different parties, security work gets postponed, minimized, or externalized.
Shipping deadlines are a classic example. A team may understand that better access controls or logging would reduce risk, but the immediate cost is missed delivery dates and higher short-term spend. The benefit—fewer incidents—arrives later, often after the team has moved on. The result is security debt that accumulates until it’s paid with interest.
Users versus platforms is another. Users bear the time cost of strong passwords, MFA prompts, or security training. The platform captures much of the benefit (fewer account takeovers, lower support costs), so the platform has an incentive to make security easy—but not always an incentive to make it transparent or privacy-preserving.
Vendors versus buyers shows up in procurement. If buyers can’t evaluate security well, vendors are rewarded for features and marketing rather than safer defaults. Even good technology doesn’t fix that market signal.
Some security issues survive “best practices” because the cheaper option wins: insecure defaults reduce friction, liability is limited, and incident costs can be pushed onto customers or the public.
You can shift outcomes by changing what gets rewarded:
When incentives line up, security stops being a heroic afterthought and becomes the obvious business choice.
Security theater is any security measure that looks protective but doesn’t meaningfully reduce risk. It feels comforting because it’s visible: you can point at it, report it, and say “we did something.” The problem is that attackers don’t care what’s comforting—only what blocks them.
Theater is easy to buy, easy to mandate, and easy to audit. It also produces tidy metrics (“100% completion!”) even when the outcome is unchanged. That visibility makes it attractive to executives, auditors, and teams under pressure to “show progress.”
Checkbox compliance: passing an audit can become the goal, even if the controls don’t match your real threats.
Noisy tools: alerts everywhere, little signal. If your team can’t respond, more alerts don’t equal more security.
Vanity dashboards: lots of graphs that measure activity (scans run, tickets closed) instead of risk reduced.
“Military-grade” claims: marketing language that substitutes for a clear threat model and evidence.
To tell theater from real risk reduction, ask:
If you can’t name a plausible attacker action that becomes harder, you may be funding reassurance rather than security.
Look for proof in practice:
When a control earns its keep, it should show up in fewer successful attacks—or at least in smaller blast radius and quicker recovery.
Cryptography is one of the few areas in security with crisp, math-backed guarantees. Used correctly, it’s excellent at protecting data in transit and at rest, and at proving certain properties about messages.
At a practical level, crypto shines in three core jobs:
That’s a big deal—but it’s also only part of the system.
Crypto can’t fix problems that live outside the math:
A company can use HTTPS everywhere and store passwords with strong hashing—then still lose money through a simple business email compromise. An attacker phishes an employee, gains access to the mailbox, and convinces finance to change bank details for an invoice. Every message is “protected” by TLS, but the process for changing payment instructions is the real control—and it failed.
Start with threats, not algorithms: define what you’re protecting, who might attack, and how. Then choose the crypto that fits (and budget time for the non-crypto controls—verification steps, monitoring, recovery) that actually make it work.
A threat model is only useful if it changes what you build and how you operate. Once you’ve named your assets, likely adversaries, and realistic failure modes, you can translate that into controls that reduce risk without turning your product into a fortress nobody can use.
A practical way to move from “what could go wrong?” to “what do we do?” is to ensure you cover four buckets:
If your plan only has prevention, you’re betting everything on being perfect.
Layered defenses don’t mean adding every control you’ve heard of. They mean choosing a few complementary measures so one failure doesn’t become a catastrophe. A good litmus test: each layer should address a different point of failure (credential theft, software bugs, misconfigurations, insider mistakes), and each should be cheap enough to maintain.
Threat models often point to the same “boring” controls because they work across many scenarios:
These aren’t glamorous, but they directly reduce likelihood and limit blast radius.
Treat incident response as a feature of your security program, not an afterthought. Define who is on point, how to escalate, what “stop the bleeding” looks like, and what logs/alerts you rely on. Run a lightweight tabletop exercise before you need it.
This matters even more when teams ship fast. For example, if you’re using a vibe‑coding platform like Koder.ai to build a React web app with a Go + PostgreSQL backend from a chat-driven workflow, you can move from idea to deployment quickly—but the same threat-model-to-controls mapping still applies. Using features like planning mode, snapshots, and rollback can turn “we made a bad change” from a crisis into a routine recovery step.
The goal is simple: when the threat model says “this is the way we’ll probably fail,” your controls should ensure that failure is detected fast, contained safely, and recoverable with minimal drama.
Prevention is important, but it’s rarely perfect. Systems are complex, people make mistakes, and attackers only need one gap. That’s why good security programs treat detection and response as first-class defenses—not an afterthought. The practical goal is to reduce harm and recovery time, even when something slips through.
Trying to block every possible attack often leads to high friction for legitimate users, while still missing novel techniques. Detection and response scale better: you can spot suspicious behavior across many attack types and act quickly. This also aligns with reality: if your threat model includes motivated adversaries, assume some controls will fail.
Focus on a small set of signals that indicate meaningful risk:
A lightweight loop keeps teams from improvising under pressure:
Run short, scenario-based tabletop exercises (60–90 minutes): “stolen admin token,” “insider data pull,” “ransomware on a file server.” Validate who decides what, how fast you can find key logs, and whether containment steps are realistic. Then turn findings into concrete fixes—not more paperwork.
You don’t need a big “security program” to get real value from threat modeling. You need a repeatable habit, clear owners, and a short list of decisions it will drive.
Day 1 — Kickoff (30–45 min): Product leads the session, leadership sets scope (“we’re modeling the checkout flow” or “the admin portal”), and engineering confirms what’s actually shipping. Customer support brings the top customer pain points and abuse patterns they see.
Day 2 — Draw the system (60 min): Engineering and IT sketch a simple diagram: users, apps, data stores, third-party services, and trust boundaries (where data crosses a meaningful line). Keep it “whiteboard simple.”
Day 3 — List assets and top threats (60–90 min): As a group, identify what matters most (customer data, money movement, account access, uptime) and the most plausible threats. Support contributes “how people get stuck” and “how attackers try to social-engineer us.”
Day 4 — Choose top controls (60 min): Engineering and IT propose a small set of controls that reduce risk the most. Product checks impact on usability; leadership checks cost and timing.
Day 5 — Decide and write it down (30–60 min): Pick owners and deadlines for the top actions; log what you’re not fixing yet and why.
System diagram: (link or image reference)
Key assets:
Top threats (3–5):
Top controls (3–5):
Open questions / assumptions:
Decisions made + owners + dates:
Review quarterly or after major changes (new payment provider, new auth flow, new admin features, big infrastructure migration). Store the template where teams already work (ticketing/wiki), and link it from your release checklist (e.g., /blog/release-checklist). The goal is not perfection—it’s catching the most likely, most damaging problems before customers do.
Security teams rarely suffer from a lack of ideas. They suffer from too many plausible-sounding ones. Schneier’s practical lens is a useful filter: prioritize work that reduces real risk for your real system, under real constraints.
When someone says a product or feature will “solve security,” translate the promise into specifics. Useful security work has a clear threat, a credible deployment path, and measurable impact.
Ask:
Before adding new tools, make sure the basics are handled: asset inventory, least privilege, patching, secure defaults, backups, logging you can use, and an incident process that doesn’t rely on heroics. These aren’t glamorous, but they consistently reduce risk across many threat types.
A practical approach is to favor controls that:
If you can’t explain what you’re protecting, from whom, and why this control is the best use of time and money, it’s probably security theater. If you can, you’re doing work that matters.
For more practical guidance and examples, browse /blog.
If you’re building or modernizing software and want to ship faster without skipping the fundamentals, Koder.ai can help teams go from requirements to deployed web, backend, and mobile apps with a chat-driven workflow—while still supporting practices like planning, audit-friendly change history via snapshots, and fast rollback when reality disagrees with assumptions. See /pricing for details.
Start by writing down:
Keep it to one system or workflow (e.g., “admin portal” or “checkout”) so it stays actionable.
Because boundaries prevent endless debate and unclear ownership. Explicitly note:
This makes trade-offs visible and creates a concrete list of risks to revisit later.
Use a rough likelihood × impact grid (Low/Medium/High) and force ranking.
Practical steps:
This keeps you focused on expected harm, not just scary scenarios.
Design so the safest behavior is the easiest behavior:
Treat “user error” as a design signal—interfaces and processes should assume fatigue and time pressure.
Ask: who pays the cost, and who gets the benefit? If they’re different, security work tends to slip.
Ways to realign:
When incentives align, secure defaults become the path of least resistance.
Use the “attacker outcomes” test:
If you can’t connect a control to a plausible attacker action and measurable effect, it’s likely reassurance rather than risk reduction.
Crypto is excellent for:
But it won’t fix:
Aim for balance across four buckets:
If you only invest in prevention, you’re betting everything on perfection.
Start with a small set of high-signal indicators:
Keep alerts few and actionable; too many low-quality alerts train people to ignore them.
A lightweight cadence works well:
Treat the threat model as a living decision record, not a one-time document.
Choose crypto after you define threats and the non-crypto controls needed around it.