Jul 15, 2025·8 min
How to Build a Technical Blog Website With Programmatic Pages
Step-by-step guide to building a technical blog with programmatic pages: content model, routing, SEO, templates, tooling, and a maintainable workflow.
Step-by-step guide to building a technical blog with programmatic pages: content model, routing, SEO, templates, tooling, and a maintainable workflow.
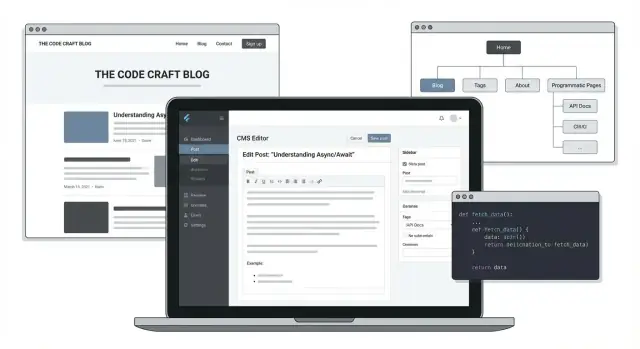
A technical blog with programmatic pages is more than a stream of individual posts. It’s a site where your content is also organized and republished into helpful index pages—generated automatically from a consistent content model.
Programmatic pages are pages created from structured data rather than written one-by-one. Common examples include:
/tags/react/) that list related posts and surface key subtopics./authors/sam-lee/) with bios, social links, and all articles by that writer./series/building-an-api/) that present a curated learning path./guides/, “Start here” hubs, or topic directories that aggregate content by intent.Done well, programmatic pages create consistency and scale:
“Programmatic” doesn’t mean “auto-generated fluff.” These pages still need a job to do: a clear intro, sensible ordering, and enough context to help readers choose what to read next. Otherwise, they risk becoming thin lists that don’t earn trust (or search visibility).
By the end of this guide, you’ll have a practical blueprint: a site structure with programmatic routes, a content model that feeds them, reusable templates, and an editorial workflow for publishing and maintaining a content-heavy technical blog.
Before you design a content model or generate thousands of pages, decide what the blog is for and who it serves. Programmatic pages amplify whatever strategy you choose—good or bad—so this is the moment to be specific.
Most technical blogs serve multiple groups. That’s fine, as long as you recognize that they search differently and need different levels of explanation:
A useful exercise: pick 5–10 representative queries for each group and write down what a good answer looks like (length, examples, prerequisites, and whether a code snippet is needed).
Programmatic pages work best when each page has a clear job. Common building blocks:
Pick a frequency you can sustain, then define the minimum review steps for each content type: quick editorial pass, code review for tutorials, and SME review for claims about security, compliance, or performance.
Tie the blog to measurable outcomes without promising miracles:
These choices will directly shape what pages you generate later—and how you prioritize updates.
A programmatic blog succeeds when readers (and crawlers) can predict where things live. Before you build templates, sketch the top-level navigation and the URL rules together—changing either later is how you end up with redirects, duplicate pages, and confusing internal links.
Keep the primary structure simple and durable:
This structure makes it easy to add programmatic pages under clearly named sections (e.g., a topic hub that lists all posts, related series, and FAQs).
Pick a small set of readable patterns and stick to them:
/blog/{slug}/topics/{topic}/series/{series}A few practical rules:
internal-linking, not InternalLinking).Decide what each classification means:
If you want long-term consistency, lead with topics and use tags sparingly (or not at all).
Overlaps happen: a post might belong to a topic and also match a tag, or a series might look similar to a topic hub. Decide the “source of truth”:
noindex and/or canonicalize to the relevant topic page.Document these decisions early so every generated page follows the same canonical pattern.
A programmatic blog succeeds or fails on its content model. If your data is consistent, you can generate topic hubs, series pages, author archives, “related posts,” and tool pages automatically—without hand-curating every route.
Define a small set of models that match how readers browse:
For Post, decide what is mandatory so templates never guess:
title, description, slugpublishDate, updatedDatereadingTime (stored or computed)codeLanguage (single or list, used for filters and snippets)Then add fields that unlock programmatic pages:
topics[] and tools[] relationships (many-to-many)seriesId and seriesOrder (or seriesPosition) for correct sequencingrelatedPosts[] (optional manual override) plus autoRelatedRules (tag/tool overlap)Programmatic pages depend on stable naming. Set clear rules:
slug (no synonyms).If you want a concrete spec, write it down in your repo wiki or an internal page like /content-model so everyone publishes the same way.
Your stack choice affects two things more than anything else: how pages are rendered (speed, hosting, complexity) and how content is stored (authoring experience, preview, governance).
Static Site Generator (SSG) tools like Next.js (static export) or Astro build HTML ahead of time. This is usually the simplest and fastest approach for a technical blog with lots of evergreen content, because it’s cheap to host and easy to cache.
Server-rendered sites generate pages on request. This is helpful when content changes constantly, you need per-user personalization, or you can’t afford long build times. The tradeoff is higher hosting complexity and more things that can break at runtime.
Hybrid (a mix of static + server) is often the sweet spot: keep blog posts and most programmatic pages static, while rendering a few dynamic routes (search, dashboards, gated content). Next.js and many other frameworks support this pattern.
Markdown/MDX in Git is great for developer-led teams: clean versioning, easy code review, and local editing. Preview is typically “run the site locally” or via preview deployments.
Headless CMS (e.g., Contentful, Sanity, Strapi) improves authoring UX, permissions, and editorial workflows (drafts, scheduled publishing). The cost is subscription fees and a more complex preview setup.
Database-backed content fits fully dynamic systems or when content is generated from product data. It adds engineering overhead and usually isn’t necessary for a blog-first site.
If you’re unsure, start with SSG + Git content, and leave room to swap in a CMS later by keeping your content model and templates clean (see /blog/content-model).
If your goal is to move fast without reinventing a full pipeline, consider prototyping the blog platform in a vibe-coding environment like Koder.ai. You can sketch your information architecture and templates via chat, generate a React frontend with a Go + PostgreSQL backend when needed, and export the source code once your model (posts, topics, authors, series) stabilizes.
Programmatic pages are built from a simple idea: one template + many data entries. Instead of hand-writing every page, you define a layout once (headline, intro, cards, sidebar, metadata), then feed it a list of records—posts, topics, authors, or series—and the site produces a page for each.
Most technical blogs end up with a small set of page “families” that multiply automatically:
You can extend this pattern to tags, tools, “guides,” or even API references—as long as you have structured data behind it.
At build time (or on-demand in a hybrid setup), your site does two jobs:
Many stacks call this a “build hook” or “content collection” step: whenever content changes, the generator reruns the mapping and re-renders affected pages.
Programmatic lists need clear defaults so pages don’t feel random:
/topics/python/page/2.These rules make your pages easier to browse, easier to cache, and easier for search engines to understand.
Programmatic pages work best when you design a small set of templates that can serve hundreds (or thousands) of URLs without feeling repetitive. The goal is consistency for readers and speed for your team.
Start with a post template that’s flexible but predictable. A good baseline includes a clear title area, an optional table of contents for longer posts, and opinionated typography for both prose and code.
Make sure your template supports:
Most programmatic value comes from index-like pages. Create templates for:
/topics/static-site-generator)/authors/jordan-lee)/series/building-a-blog)Each listing should show a short description, sorting (newest, most popular), and consistent snippets (title, date, reading time, tags).
Reusable components keep pages useful without custom work:
Bake accessibility into your UI primitives: sufficient contrast, visible focus states for keyboard navigation, and code blocks that remain readable on mobile. If a TOC is clickable, ensure it’s reachable and usable without a mouse.
Programmatic pages can rank extremely well—if each URL has a clear purpose and enough unique value. The goal is to make Google confident that every generated page is useful, not a near-duplicate created just because you had data.
Give every page type a predictable SEO contract:
A simple rule: if you wouldn’t proudly link to the page from your homepage, it probably shouldn’t be indexed.
Add structured data only when it matches the content:
This is easiest when baked into templates shared across all programmatic routes.
Programmatic sites win when pages reinforce each other:
/blog/topics).Define minimum content rules for generated indexes:
Once you start generating pages (tag hubs, category listings, author pages, comparison tables), search engines need a clear “map” of what matters—and what doesn’t. Good crawl hygiene keeps bots focused on pages you actually want ranked.
Create sitemaps for both editorial posts and programmatic pages. If you have many URLs, split them by type so they stay manageable and easier to debug.
Include lastmod dates (based on real content updates) and avoid listing URLs you plan to block.
Use robots.txt to prevent crawlers from wasting time on pages that can explode into near-duplicates.
Block:
/search?q=)?sort=, ?page= when those pages don’t add unique value)If you still need these pages for users, keep them accessible but consider adding noindex at the page level (and keep internal linking pointed at the canonical version).
Publish an RSS or Atom feed for the main blog (e.g., /feed.xml). If topics are a core navigation element, consider per-topic feeds too. Feeds help power email digests, Slack bots, and reader apps—and they’re a simple way to expose new content quickly.
Add breadcrumbs that match your URL strategy (Home → Topic → Post). Keep navigation labels consistent across the site so crawlers—and readers—understand your hierarchy. If you want an extra SEO boost, add breadcrumb schema markup alongside the UI.
A technical blog with programmatic pages can grow from 50 to 50,000 URLs quickly—so performance has to be a product requirement, not an afterthought. The good news: most wins come from a handful of clear budgets and a build pipeline that enforces them.
Start with targets you can measure on every release:
Budgets are useful because they turn debates into checks: “This change adds 60 KB of JS—does it earn its keep?”
Syntax highlighting is a common performance trap. Prefer server-side highlighting (at build time) so the browser receives plain HTML with precomputed styles. If you must highlight on the client, limit it to pages that actually contain code blocks and load the highlighter only when needed.
Also consider reducing theme complexity: fewer token styles usually means smaller CSS.
Treat images as part of your content system:
srcset variants and serve modern formats (AVIF/WebP) with fallbacks.A CDN caches your pages close to readers, making most requests fast without extra servers. Pair that with sensible cache headers and purge rules so updates propagate quickly.
If you publish often or have many programmatic pages, incremental builds become important: rebuild only the pages that changed (and the ones that depend on them) instead of regenerating the entire site every time. This keeps deploys reliable and prevents “site is stale because the build took two hours” problems.
Programmatic pages scale your site; your workflow is what keeps quality scaling with them. A lightweight, repeatable process also prevents “almost correct” content from quietly shipping.
Define a small set of statuses and stick to them: Draft, In Review, Ready, Scheduled, Published. Even if you’re a one-person team, this structure helps you batch work and avoid context switching.
Use preview builds for every change—especially template or content-model updates—so editors can validate formatting, internal links, and generated lists before anything goes live. If your platform supports it, add publish scheduling so posts can be reviewed early and released at a predictable cadence.
If you’re iterating on templates quickly, features like snapshots and rollback (available in platforms such as Koder.ai) can reduce the fear of “one template change broke 2,000 pages,” because you can preview, compare, and revert safely.
Code blocks are often the reason readers trust (or abandon) a technical blog. Set house rules such as:
If you maintain a repo for examples, link to it with a relative path (e.g., /blog/example-repo) and pin tags or commits so examples don’t drift.
Add a visible “Last updated” field and store it as structured data in your content model. For evergreen posts, maintain a short changelog (“Updated steps for Node 22”, “Replaced deprecated API”) so returning readers can see what changed.
Before publishing, run a quick checklist: broken links, headings in order, metadata present (title/description), code blocks formatted, and any generated page-specific fields populated (like tags or product names). This takes minutes and saves support emails later.
A programmatic blog isn’t “done” at launch. The main risk is quiet drift: templates change, data changes, and suddenly you have pages that don’t convert, don’t rank, or shouldn’t exist.
Before you announce anything, do a quick production sweep: key templates render correctly, canonical URLs are consistent, and every programmatic page has a clear purpose (answer, comparison, glossary, integration, etc.). Then submit your sitemap in Search Console and verify your analytics tags are firing.
Focus on signals that guide content decisions:
If you can, segment by template type (e.g., /glossary/ vs /comparisons/) so you can improve a whole class of pages at once.
Add site search and filters, but be careful with filter-generated URLs. If a filtered view doesn’t deserve to rank, keep it usable for humans while preventing crawl waste (e.g., noindex for parameter-heavy combinations, and avoid generating infinite tag intersections).
Programmatic sites evolve. Plan for:
Create obvious navigation paths so readers don’t hit dead ends: a curated /blog hub, a “start here” collection, and—if relevant—commercial paths like /pricing tied to high-intent pages.
If you want to accelerate implementation, build the first version of your programmatic routes and templates, then refine the content model in place. Tools like Koder.ai can be useful here: you can prototype the React UI, generate the backend pieces (Go + PostgreSQL) when you outgrow flat files, and still keep the option to export the source code once your architecture is set.
Programmatic pages are pages generated from structured data and templates rather than written one-by-one. In a technical blog, common examples are topic hubs (e.g., /topics/{topic}), author archives (e.g., /authors/{author}), and series landing pages (e.g., /series/{series}).
They give you consistency and scale:
They’re especially valuable when you publish many posts across repeatable topics, tools, or series.
Start with intent-based segments and map content to how people search:
Write down a handful of representative queries per segment and define what a “good answer” needs (examples, prerequisites, code).
Use a small set of stable, readable patterns and treat them as permanent:
/blog/{slug}/topics/{topic}/series/{series}Keep slugs lowercase and hyphenated, avoid dates unless you’re news-heavy, and don’t change URLs for minor title edits.
Use topics/categories as your controlled, primary taxonomy (a limited set you maintain intentionally). Add tags only if you can enforce rules; otherwise, you’ll create duplicates like seo vs SEO.
A practical approach is “topics-first, tags-sparingly,” with clear ownership over creating new topics.
At minimum, model these entities so templates can generate pages reliably:
Then add relationships like topics[], , and so hubs and “next in series” navigation can be built automatically.
Most blogs do best with a hybrid approach:
For storage, Markdown/MDX in Git fits dev-led teams; a headless CMS is better when you need drafts, permissions, and scheduled publishing.
Define stable defaults so lists don’t feel random:
Keep URLs predictable (e.g., /topics/python/page/2) and decide early which filtered views are indexable.
Give every generated page unique value and control what gets indexed:
noindex near-duplicate filter combinationsA good heuristic: if you wouldn’t link to the page from a main hub, it probably shouldn’t be indexed.
Use crawl controls and maintenance routines:
lastmodrobots.txtTrack performance by template type (posts vs topic hubs vs comparisons) so improvements apply across whole page families.
tools[]seriesOrder