Nov 09, 2025·8 min
Build a Web App to Manage Marketplace Disputes End-to-End
Learn how to plan, design, and build a web app to handle marketplace disputes: case intake, evidence, workflows, roles, audit trails, integrations, and reporting.
Learn how to plan, design, and build a web app to handle marketplace disputes: case intake, evidence, workflows, roles, audit trails, integrations, and reporting.
A dispute app isn’t just a “support form with a status.” It’s the system that decides how money, items, and trust move through your marketplace when something goes wrong. Before you draw screens or tables, define the problem space clearly—otherwise you’ll build a tool that’s easy to use but hard to enforce.
Start by listing the dispute types you actually need to handle and how they differ. Common categories include:
Each type tends to require different evidence, time windows, and outcomes (refund, replacement, partial refund, seller payout reversal). Treat the dispute type as a workflow driver—not just a label.
Dispute handling usually competes on speed, consistency, and loss prevention. Write down what success looks like in your context:
These goals influence everything from what data you collect to which actions you automate.
Most marketplaces have more than “customer support.” Typical users include buyers, sellers, support agents, admins, and finance/risk. Each group needs a different view:
A strong v1 usually focuses on: creating a case, collecting evidence, messaging, tracking deadlines, and recording a decision with an audit trail.
Later releases can add: automated refund rules, fraud signals, advanced analytics, and deeper integrations. Keeping scope tight early prevents a “do everything” system that no one trusts.
If you’re moving fast, it can help to prototype the workflow end-to-end before committing to a full build. For example, teams sometimes use Koder.ai (a vibe-coding platform) to spin up an internal React admin dashboard + Go/PostgreSQL backend from a chat-driven spec, then export the source code once the core case states and permissions feel right.
A dispute app succeeds or fails based on whether it mirrors how disputes actually move through your marketplace. Start by mapping the current journey end-to-end, then turn that map into a small set of states and rules the system can enforce.
Write the “happy path” as a timeline: intake → evidence collection → review → decision → payout/refund. For each step, note:
This becomes the backbone for automation, reminders, and reporting.
Keep states mutually exclusive and easy to understand. A practical baseline:
For every state, define entry criteria, allowed transitions, and required fields before moving forward. This prevents stuck cases and inconsistent outcomes.
Attach deadlines to states (e.g., seller has 72 hours to provide tracking). Add automatic reminders, and decide what happens when time runs out: auto-close, default decision, or escalation to manual review.
Model outcomes separately from states so you can track what happened: refund, partial refund, replacement, release funds, account restriction/ban, or goodwill credit.
Disputes get messy. Include paths for missing tracking, split shipments, digital goods delivery proofs, and orders with multiple items (item-level decisions vs full-order decisions). Designing these branches early avoids one-off handling that breaks consistency later.
A dispute app succeeds or fails on whether the data model matches real-world questions: “What happened?”, “What’s the proof?”, “What did we decide?”, and “Can we show an audit trail later?” Start by naming a small set of core entities and being strict about what can change.
At minimum, model:
Keep “Dispute” focused: it should reference the order/payment, store status, deadlines, and pointers to evidence and decisions.
Treat anything that must be defensible later as append-only:
Allow edits only for operational convenience:
This split is easiest with an audit trail table (event log) plus current “snapshot” fields on the case.
Define strict validation early:
Plan for evidence storage: allowed file types, size limits, virus scanning, and retention rules (e.g., auto-delete after X months if policy allows). Store file metadata (hash, uploader, timestamp) and keep the blob in object storage.
Use a consistent, human-readable case ID scheme (e.g., DSP-2025-000123). Index searchable fields like order ID, buyer/seller IDs, status, reason, amount range, and key dates so agents can find cases fast from the queue.
Disputes involve multiple parties and high-risk data. A clear role model reduces mistakes, speeds decisions, and helps you meet compliance expectations.
Start with a small, explicit set of roles and map them to actions—not just screens:
Use least-privilege defaults and add “break glass” access only for audited emergencies.
For staff, support SSO (SAML/OIDC) when available so access follows HR lifecycle. Require MFA for privileged roles (supervisor, finance, admin) and for any action that changes money or a final decision.
Session controls matter: short-lived tokens for staff tools, device-bound refresh where possible, and automatic logout for shared workstations.
Separate “case facts” from sensitive fields. Apply field-level permissions for:
Redact by default in the UI and logs. If someone needs access, record why.
Maintain an immutable audit log for sensitive actions: decision changes, refunds, payout holds, evidence deletion, permission changes. Include timestamp, actor, old/new values, and source (API/UI).
For evidence, define consent and sharing rules: what the other party can see, what remains internal (e.g., fraud signals), and what must be partially redacted before sharing.
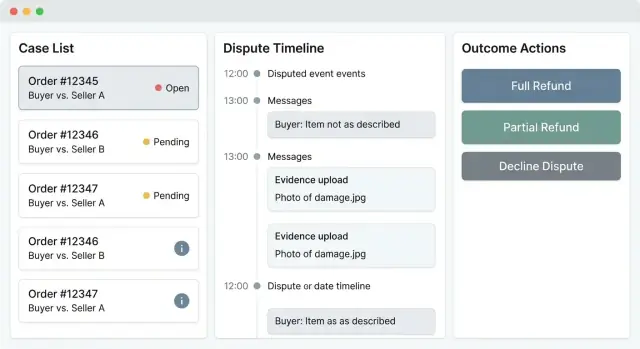
A dispute tool lives or dies on speed: how quickly an agent can triage a case, understand what happened, and take a safe action. The UI should make “what needs attention now” obvious, while keeping sensitive data and irreversible decisions hard to click by accident.
Your case list should behave like an operations console, not a generic table. Include filters that mirror how teams actually work: status, reason, amount, age/SLA, seller, and risk score. Add saved views (e.g., “New high-value”, “Overdue”, “Awaiting buyer response”) so agents don’t rebuild filters every day.
Make the rows scannable: case ID, status chip, days open, amount, party (buyer/seller), risk indicator, and the next deadline. Keep sorting predictable (default by urgency/SLA). Bulk actions are useful, but limit them to safe operations like assign/unassign or add internal tags.
The case detail page should answer three questions within seconds:
A practical layout is a timeline down the center (events, status changes, payments/shipping signals), with a right-side snapshot panel for order/payment context (order total, payment method, shipment status, refunds/chargebacks, key IDs). Keep deep links to related objects (order, payment, shipment) as relative routes like /orders/123 and /payments/abc.
Add a messages area and an evidence gallery that supports quick preview (images, PDFs) plus metadata (who submitted, when, type, verification state). Agents should never have to hunt through attachments to understand the latest update.
Decisioning actions (refund, deny, request more info, escalate) must be unambiguous. Use confirmations for irreversible steps and require structured inputs: a required note, reason code, and optional decision templates for consistent wording.
Separate collaboration channels: internal notes (agent-only, for handoffs) versus external messages (buyer/seller visible). Include assignment controls and a visible “current owner” to prevent duplicate work.
Design for keyboard navigation, readable status contrast, and screen reader labels—especially on action buttons and form fields. Mobile views should prioritize the snapshot, last message, next deadline, and a one-tap route to the evidence gallery for quick reviews during on-call shifts.
Disputes are mostly communication problems with a timer attached. Your app should make it obvious who needs to do what next, by when, and through which channel—without forcing people to dig through email threads.
Use in-app messaging as the source of truth: every request, reply, and attachment should live on the case timeline. Then mirror key updates via email notifications (new message, evidence requested, deadline approaching, decision issued). If you add SMS, keep it for time-sensitive nudges (e.g., “Deadline in 24 hours”) and avoid putting sensitive details in the text.
Create message templates for common requests so agents stay consistent and users know what “good evidence” looks like:
Allow placeholders like order ID, dates, and amounts, plus a short “human edit” area so replies don’t feel robotic.
Every request should generate a deadline (e.g., seller has 3 business days to respond). Show it prominently on the case, send automated reminders (48h and 24h), and define clear outcomes for non-response (e.g., auto-close, auto-refund, or escalate).
If you serve multiple regions, store message content with a language tag and provide localized templates. To prevent abuse, add rate limits per case/user, attachment size/type limits, virus scanning, and safe rendering (no inline HTML, sanitize filenames). Keep an audit trail of who sent what and when.
Evidence is where most disputes are won or lost, so your app should treat it like a first-class workflow—not a pile of attachments.
Start by defining evidence types you expect to see across common marketplace disputes: tracking links and delivery scans, photos of packaging or damage, invoices/receipts, chat logs, return labels, and internal notes. Making these types explicit helps you validate inputs, standardize review, and improve reporting later.
Avoid generic “upload anything” prompts. Instead, generate structured evidence requests from the dispute reason (e.g., “Item not received” → carrier tracking + proof of delivery; “Not as described” → product listing snapshot + buyer photos). Each request should include:
This reduces back-and-forth and makes cases comparable across reviewers.
Treat evidence like sensitive records. For each upload, store:
These controls won’t “prove” the content is truthful, but they do prove whether the file was altered after submission and who handled it.
Disputes often end up in external review (payment processor, carrier, arbitration). Provide a one-click export that bundles key files plus a summary: case facts, timeline, order metadata, and evidence index. Keep it consistent so teams can trust it under time pressure.
Evidence can contain personal data. Implement retention rules by dispute type and region, plus a tracked deletion process (with approvals and audit logs) when legally required.
Decisioning is where a dispute app either builds trust or creates more work. The goal is consistency: similar cases should get similar outcomes, and both parties should understand why.
Start by defining policies as readable rules, not legal prose. For each dispute reason (item not received, damaged, not as described, unauthorized payment, etc.), document:
Keep these policies versioned so you can explain decisions made under older rules and reduce “policy drift” over time.
A good decision screen nudges reviewers toward complete, defensible outcomes.
Use checklists per reason that automatically appear in the case view (for example: “carrier scan present,” “photo shows damage,” “listing promised X”). Each checklist item can:
This creates a consistent audit trail without forcing everyone to write from scratch.
Decisioning should compute financial impact, not leave it to spreadsheets. Store and display:
Make it clear whether the system will auto-issue the refund or generate a task for finance/support (especially when payments are split or partially captured).
Appeals reduce frustration when new information appears—but they can also become infinite loops.
Define: when appeals are allowed, what “new” evidence means, who reviews (different queue/reviewer if possible), and how many attempts are permitted. On appeal, freeze the original decision and create a linked appeal record so reporting can distinguish initial vs. final outcomes.
Every decision should generate two messages: one for the buyer and one for the seller. Use clear language, list the key evidence considered, and state next steps (including appeal eligibility and deadlines). Avoid jargon and avoid blaming either party—focus on facts and policy.
Integrations turn a dispute tool from a “notes app” into a system that can verify facts and safely execute outcomes. Start by listing the external systems that must agree on reality: order management (what was purchased), payments (what was captured/refunded), shipping carriers (what was delivered), and your email/SMS provider (what was communicated, and when).
For time-sensitive changes—like chargeback alerts, refund status, or ticket updates—prefer webhooks. They reduce delay and keep case timelines accurate.
Use scheduled sync when webhooks are unavailable or unreliable (common with carriers). A practical hybrid is:
Whichever you choose, store the “last known external status” on the case and keep the raw payload for audit and debugging.
Financial actions must be repeat-safe. Network retries, double-clicks, and webhook re-deliveries can otherwise trigger duplicate refunds.
Make every money-affecting call idempotent by:
case_id + decision_id + action_type)This same pattern applies to partial refunds, voids, and fee reversals.
When something doesn’t match (a refund says “pending” or a delivery scan is missing), your team needs visibility. Log every integration event with:
Expose a lightweight “Integration” tab in the case detail screen so support can self-serve.
Plan safe environments from day one: payment processor sandbox, carrier test tracking numbers (or mocked responses), and email/SMS “test recipients.” Add a visible “test mode” banner in non-production so QA never accidentally triggers real refunds.
If you’re building admin tooling, document required credentials and scopes on an internal page like /docs/integrations so setup is repeatable.
A dispute management system quickly grows beyond “just a few screens.” You’ll add evidence uploads, payment lookups, deadline reminders, and reporting—so the architecture should stay boring and modular.
For v1, prioritize what your team already knows. A conventional setup (React/Vue + a REST/GraphQL API + Postgres) is usually faster to deliver than experimenting with new frameworks. The goal is predictable delivery, not novelty.
If you want to accelerate the first iteration without locking yourself into a black box, a platform like Koder.ai can be useful for generating a working React + Go + PostgreSQL foundation from a written workflow spec, while still keeping the option to export the source code and take full ownership.
Keep clear boundaries between:
This separation makes it easier to scale specific parts (like background processing) without rewriting the whole case management web app.
Evidence collection and verification often involves virus scanning, OCR, file conversions, and calling external services. Exports and scheduled reminders can also be heavy. Put these tasks behind a queue so your UI stays fast and users don’t re-submit actions. Track job status on the case so operators understand what’s pending.
Case queues live and die by search. Design for filtering by status, SLA/deadlines, payment method, risk flags, and assigned agent. Add indexes early, and consider full-text search only if basic indexing can’t meet your needs. Also design pagination and “saved views” for common workflows.
Define staging and production from the start, with seed data that mirrors real dispute scenarios (chargeback workflow, refund automation, appeals). Use versioned migrations, feature flags for risky changes, and a rollback plan so you can deploy often without breaking active cases.
If your team values fast iteration, features like snapshots and rollback (available in platforms like Koder.ai) can be a practical complement to traditional release controls—especially while your workflows and permissions are still evolving.
A dispute management system gets better when you can see what’s happening across cases—fast. Reporting isn’t just for executives; it helps agents prioritize work, helps managers spot operational risk, and helps the business adjust policies before costs creep up.
Track a small set of actionable KPIs and make them visible everywhere:
Agents need an operational view: “What should I work next?” Build a queue-style dashboard that highlights SLA breaches, impending deadlines, and “missing evidence” cases.
Managers need pattern detection: spikes in specific reason codes, high-risk sellers, unusual refund totals, and win-rate drops after policy changes. A simple week-over-week view often beats an overbuilt chart page.
Support CSV exports and scheduled reports, but put guardrails around them:
Analytics only works if cases are labeled consistently. Use controlled reason codes, optional tags (free-form but normalized), and validation prompts when agents try to close a case with “Other.”
Treat reporting as a feedback loop: review top loss reasons monthly, adjust evidence checklists, refine auto-refund thresholds, and document changes so improvements show up in future cohorts.
Shipping a dispute management system is less about perfect UI polish and more about knowing it behaves correctly under stress: missing evidence, late responses, payment edge cases, and strict access control.
Write test cases that follow real flows end-to-end: open → evidence requested/received → decision → payout/refund/hold. Include negative paths and time-based transitions:
Automate these with integration tests around your APIs and background jobs; keep a small set of manual exploratory scripts for UI regression.
Role-based access control failures are high-impact. Build a permission test matrix for each role (buyer, seller, agent, supervisor, finance, admin) and verify:
Dispute apps depend on jobs and integrations (orders, payments, shipping). Add monitoring for:
Prepare an internal runbook covering common issues, escalation paths, and manual overrides (re-open case, extend deadline, reverse/refund correction, evidence re-request). Then roll out in phases:
When you’re iterating quickly, a structured “planning mode” (for example, the kind offered in Koder.ai) can help you align stakeholders on states, roles, and integrations before you ship changes into production.
Start by defining dispute types (item not received, not as described/damaged, fraud/unauthorized, chargebacks) and mapping each to different evidence requirements, time windows, and outcomes. Treat the dispute type as a workflow driver so the system can enforce consistent steps and deadlines.
A practical v1 usually includes: case creation, structured evidence collection, in-app messaging mirrored to email, SLA deadlines with reminders, a basic agent queue, and recording decisions with an immutable audit trail. Defer advanced automation (fraud scoring, auto-refund rules, complex analytics) until the core workflow is trusted.
Use a small, mutually exclusive set such as:
For each state, define entry criteria, allowed transitions, and required fields before moving forward (e.g., you can’t enter “Under review” without required evidence for that reason code).
Set deadlines per state/action (e.g., “seller has 72 hours to provide tracking”), then automate reminders (48h/24h) and define default outcomes when time expires (auto-close, auto-refund, or escalate). Make deadlines visible in both the queue (for prioritization) and the case detail (for clarity).
Separate state (where the case is in the workflow) from outcome (what happened). Outcomes often include refund, partial refund, replacement, release funds, payout reversal, account restriction, or goodwill credit. This lets you report accurately even when the same state (“Resolved”) can mean very different financial actions.
At minimum model: Order, Payment, User, Case/Dispute, Claim reason (controlled codes), Evidence, Messages, and Decision. Keep defensible information append-only via an event log (status changes, evidence uploads, decisions, money moves), while allowing limited edits for operational fields like internal notes, tags, and assignment.
Treat sensitive and defensible artifacts as append-only:
Pair that with a “current snapshot” on the case for fast UI queries. This makes investigations, appeals, and chargeback packets much easier to defend later.
Define explicit roles (buyer, seller, agent, supervisor, finance, admin) and grant permissions by action, not just by screen. Add least-privilege defaults, SSO + MFA for privileged staff, and field-level masking for PII/payment details. Keep internal notes and risk signals hidden from external parties, with audited “break glass” access for exceptions.
Build an operations-style queue with filters that match real triage: status, reason, amount, age/SLA, seller, and risk score. Make rows scannable (case ID, status, days open, amount, party, risk, next deadline) and add saved views like “Overdue” or “New high-value.” Limit bulk actions to safe operations such as assignment or tagging.
Use in-app messaging as the source of truth, mirror key events to email, and use SMS only for time-sensitive nudges without sensitive content. Drive evidence requests from the reason code with templates (proof of delivery, photos, return instructions) and always attach a due date so users know exactly what to do next.