May 13, 2025·8 min
Build a Web App to Track Product Adoption by Account Tier
Learn how to design data, events, and dashboards to measure product adoption across account tiers, and act on insights with alerts and automation.
Goals, Users, and Account Tier Definitions
Before you build dashboards or instrument events, get crisp on what the app is for, who it serves, and how account tiers are defined. Most “adoption tracking” projects fail because they start with data and end up with disagreements.
A practical rule: if two teams can’t define “adoption” in the same sentence, they won’t trust the dashboard later.
Who will use this app?
Name the primary audiences and what each needs to do next after reading the data:
- Product: understand whether new features are being discovered, used repeatedly, and retained.
- Customer Success (CS): spot onboarding gaps, adoption risk, and accounts that need enablement.
- Sales / Account Management: identify expansion signals (high usage, breadth of features) and renewal risk.
- Executives: track overall adoption health and whether strategic initiatives are moving the needle.
A useful litmus test: each audience should be able to answer “so what?” in under a minute.
Define “adoption” for your product
Adoption is not one metric. Write a definition your team can agree on—usually as a sequence:
- Activation: the first meaningful success (e.g., invited teammates, created first project, completed setup).
- Feature use: repeated usage of key features that correlate with value (not vanity clicks).
- Retention: usage continues week over week/month over month.
Keep it grounded in customer value: what action signals they’re getting outcomes, not just exploring.
Account tiers and assignment rules
List your tiers and make assignment deterministic. Common tiers include SMB / Mid-Market / Enterprise, Free / Trial / Paid, or Bronze / Silver / Gold.
Document the rules in plain language (and later, in code):
- Which source of truth decides tier (billing system, CRM, internal table)?
- Is tier based on ARR, seats purchased, plan, industry, or support level?
- What happens when data conflicts (e.g., CRM says Enterprise, billing says Pro)?
- When does a tier change take effect, and do you need tier history for reporting?
Decisions you want to support
Write down the decisions the app must enable. For example:
- Onboarding: who hasn’t activated within 7 days?
- Risk: which high-value accounts are showing declining usage?
- Expansion: which accounts are hitting limits or adopting multiple advanced features?
3–5 key dashboard questions
Use these as acceptance criteria:
- Which tiers are improving or declining in adoption this month?
- For each tier, what percent of accounts are activated and what percent are retained?
- Which features drive the biggest difference between healthy and at-risk accounts by tier?
- Which top accounts in each tier need intervention, and why (activation gap, low breadth, drop in frequency)?
- After a release or onboarding change, did adoption lift for the target tier?
Adoption Metrics That Make Sense by Tier
Account tiers behave differently, so a single “adoption” metric will either punish small customers or hide risk in larger ones. Start by defining what success looks like per tier, then pick metrics that reflect that reality.
1) Choose north-star outcomes per tier
Pick one primary outcome that represents real value delivered:
- Starter/SMB: “Activated accounts” (reached first value fast)
- Mid-market: “Weekly active accounts with key feature usage”
- Enterprise: “Accounts with multi-team adoption” or “accounts meeting rollout milestones”
Your north star should be countable, tier-segmented, and hard to game.
2) Define funnel stages with clear qualification
Write your adoption funnel as stages with explicit rules—so a dashboard answer doesn’t depend on interpretation.
Example stages:
- Invited → Signed up: at least one user created
- Activated: setup checklist completed and first key action performed
- Integrated: at least one key integration connected
- Adopting: repeated key actions across multiple days/weeks
Tier differences matter: enterprise “Activated” may require an admin action and at least one end-user action.
3) Pick leading vs. lagging indicators
Use leading indicators to spot early momentum:
- Setup completed
- Key integration connected
- First workflow published/shared
Use lagging indicators to confirm durable adoption:
- Retention by tier (e.g., 4-week active rate)
- Depth of usage (actions per active user, projects created, seats active)
- Renewal proxies (contract health signals, expansion events)
4) Set realistic targets per tier
Targets should reflect expected time-to-value and organizational complexity. For example, SMB may target activation within 7 days; enterprise may target integration within 30–60 days.
Write targets down so alerts and scorecards stay consistent across teams.
Data Model for Accounts, Users, and Tier History
A clear data model prevents “mystery math” later. You want to answer simple questions—who used what, in which account, under which tier, at that point in time—without stitching ad-hoc logic into every dashboard.
Core entities to model
Start with a small set of entities that map to how customers actually buy and use your product:
- Account: the customer record you sell to (company or organization). Store identifiers (
account_id), name, status, and lifecycle fields (created_at,churned_at). - User: an individual person. Include
user_id, email domain (helpful for matching),created_at,last_seen_at. - Workspace / Project (optional): if your product has multiple spaces under one Account, model it explicitly with
workspace_idand a foreign key toaccount_id. - Subscription: the billing object. Store plan, billing period, seats, MRR, and timestamps.
- Tier: a normalized table (e.g., Free, Team, Business, Enterprise) so naming stays consistent.
Decide the tracking grain
Be explicit about the analytics “grain”:
- User-level events answer: Which personas adopted feature X?
- Account-level rollups answer: Is this customer healthy?
A practical default is to track events at the user level (with account_id attached), then aggregate to account-level metrics. Avoid account-only events unless no user exists (e.g., system imports).
Model time: events vs. snapshots
Events tell you what happened; snapshots tell you what was true.
- Keep an event table as the source of truth.
- Add daily account snapshots (one row per account per day) for fast dashboards: active users, key feature counts, adoption score, and the tier for that day.
Capture tier history (tiers change)
Don’t overwrite “current tier” and lose context. Create an account_tier_history table:
account_id,tier_idvalid_from,valid_to(nullable for current)source(billing, sales override)
This lets you compute adoption while the account was Team, even if it later upgraded.
Document metric definitions
Write definitions once and treat them as product requirements: what counts as an “active user,” how you attribute events to accounts, and how you handle tier changes mid-month. This prevents two dashboards showing two different truths.
Event Tracking Plan and Instrumentation Basics
Your adoption analytics will only be as good as the events you collect. Start by mapping a small set of “critical path” actions that indicate real progress for each account tier, then instrument them consistently across web, mobile, and backend.
Critical events to track
Focus on events that represent meaningful steps—not every click. A practical starter set:
signup_completed(account created)user_invitedandinvite_accepted(team growth)first_value_received(your “aha” moment; define it explicitly)key_feature_used(repeatable value action; may be multiple events per feature)integration_connected(if integrations drive stickiness)
Event properties (make them queryable)
Every event should carry enough context to slice by tier and by role:
account_id(required)user_id(required when a person is involved)tier(capture at event time)plan(billing plan/SKU if relevant)role(e.g., owner/admin/member)- Optional but useful:
workspace_id,feature_name,source(web/mobile/api),timestamp
Naming conventions you can enforce
Use a predictable scheme so dashboards don’t turn into a dictionary project:
- Events: lowercase
snake_caseverbs, past tense (report_exported,dashboard_shared) - Properties: consistent nouns (
account_id, notacctId) - Feature events: either dedicated events (
invoice_sent) or a single event withfeature_name; choose one approach and stick to it.
Identity: cross-device and multi-workspace
Support both anonymous and authenticated activity:
- Assign an
anonymous_idon first visit, then link touser_idon login. - In multi-workspace products, always include
workspace_idand map it toaccount_idserver-side to avoid client bugs.
Server-side events for reliability
Instrument system actions on the backend so key metrics don’t depend on browsers or ad blockers. Examples: subscription_started, payment_failed, seat_limit_reached, audit_log_exported.
These server-side events are also ideal triggers for alerts and workflows.
Ingestion, Storage, and Aggregation Pipeline
This is where tracking becomes a system: events arrive from your app, get cleaned up, stored safely, and turned into metrics your team can actually use.
Pick an ingestion path that fits your product
Most teams use a mix:
- SDK (client/server): best for consistent, structured product event tracking.
- HTTP API: good for backend services, partners, or importing events from other systems.
- Application logs: useful when you already have rich logs; you’ll need parsing and stricter schemas.
- Message queue (Kafka/SQS/PubSub): ideal when volume is high or you need resilience and replay.
Whatever you choose, treat ingestion as a contract: if an event can’t be interpreted, it should be quarantined—not silently accepted.
Normalize early: timestamps, IDs, and properties
At ingestion time, standardize the few fields that make downstream reporting reliable:
- Convert all timestamps to UTC and store the original source timestamp when relevant.
- Map identifiers to canonical forms:
account_id,user_id, and (if needed)workspace_id. - Validate required properties (e.g.,
event_name,tier,plan,feature_key) and add defaults only when explicit.
Store raw events separately from aggregates
Decide where raw events live based on cost and query patterns:
- Warehouse (Snowflake/BigQuery/Redshift): easiest for analytics and ad-hoc queries.
- Object storage (S3/GCS) + query engine: cheapest at scale, slightly more setup.
- Operational database: only for smaller volumes; watch performance carefully.
Rollups: scheduled jobs that match decisions
Build daily/hourly aggregation jobs that produce tables like:
- Daily active accounts by tier
- Feature adoption counts by tier
- Account-level adoption score inputs
Keep rollups deterministic so you can re-run them when tier definitions or backfills change.
Retention rules
Set clear retention for:
- Raw events: longer (e.g., 12–36 months) for auditability and reprocessing
- Aggregates: longer or indefinite, since they’re compact and power dashboards and alerts
Adoption Scoring and Tier-Level Rollups
Get an instrumentation plan
Draft a clear event taxonomy and properties your team can query without debate.
An adoption score gives busy teams a single number to monitor, but it only works if it stays simple and explainable. Aim for a 0–100 score that reflects meaningful behaviors (not vanity activity) and can be broken down into “why this moved.”
A simple, explainable 0–100 score
Start with a weighted checklist of behaviors, capped at 100 points. Keep weights stable for a quarter so trends remain comparable.
Example weighting (adjust to your product):
- Activation (40 pts): completed onboarding steps, created first project, invited a teammate.
- Core usage (40 pts): used the primary feature on 3+ distinct days in the last 14 days.
- Expansion (20 pts): adopted one secondary feature (e.g., integrations, exports, approvals).
Each behavior should map to a clear event rule (e.g., “used core feature” = core_action on 3 separate days). When the score changes, store contributing factors so you can show: “+15 because you invited 2 users” or “-10 because core usage dropped below 3 days.”
Rollups by account and by tier
Compute the score per account (daily or weekly snapshot), then aggregate by tier using distributions, not just averages:
- Median score by tier
- 25th/75th percentiles (and optionally 10th/90th)
- % of accounts above thresholds (e.g., 60+ = “healthy adoption”)
Trends without misleading comparisons
Track weekly change and 30-day change per tier, but avoid mixing tier sizes:
- Show counts (e.g., 38 accounts improved) alongside percentages (e.g., 12% improved).
This makes small tiers readable without letting large tiers dominate the narrative.
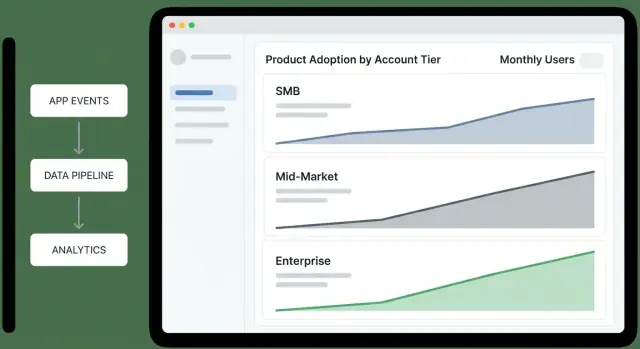
Dashboards: Tier Overview and Executive Summary
A tier overview dashboard should let an exec answer one question in under a minute: “Which tiers are improving, which are slipping, and why?” Treat it as a decision screen, not a reporting scrapbook.
What to show (and what each chart answers)
Tier funnel (Awareness → Activation → Habit): “Where are accounts getting stuck by tier?” Keep the steps consistent with your product (e.g., “Invited users” → “Completed first key action” → “Weekly active”).
Activation rate by tier: “Are new or reactivated accounts reaching first value?” Pair a rate with the denominator (accounts eligible) so leaders can tell signal from small-sample noise.
Retention by tier (e.g., 7/28/90-day): “Do accounts keep using after the first win?” Show a simple line per tier; avoid over-segmenting on the overview.
Depth of use (feature breadth): “Are they adopting multiple product areas or staying shallow?” A stacked bar per tier works well: % using 1 area, 2–3 areas, 4+ areas.
Comparisons that drive action
Add two comparisons everywhere:
- This week vs last week (or last 7 vs prior 7) for fast feedback.
- Tier vs tier to spot mismatch (e.g., SMB outperforming Enterprise on activation).
Use consistent deltas (absolute percentage-point change) so executives can scan quickly.
Filters that don’t break the story
Keep filters limited, global, and sticky:
- Time range (preset windows plus custom)
- Product area (for depth-of-use context)
- Region (to reveal rollout or market effects)
- Account owner (to support GTM accountability)
If a filter would change metric definitions, don’t offer it here—push it to drill-down views.
“Top drivers” per tier
Include a small panel for each tier: “What’s most associated with higher adoption this period?” Examples:
- Top 3 features/events correlated with high adoption score
- Biggest drop-off step in the funnel
- Accounts with largest week-over-week change (positive and negative)
Keep it explainable: prefer “Accounts that set up X in the first 3 days retain 18pp better” over opaque model outputs.
A useful layout
Put Tier KPI cards at the top (activation, retention, depth), one scroll of trend charts in the middle, and drivers + next actions at the bottom. Every widget should answer one question—or it doesn’t belong on the executive summary.
Drill-Down Views: From Tier to Individual Accounts
A tier dashboard is useful for prioritization, but the real work happens when you can click through to why a tier moved and who needs attention. Design drill-down views as a guided path: tier → segment → account → user.
Tier → Segment: narrow the question
Start with a tier overview table, then let users slice it into meaningful segments without building custom reports. Common segment filters:
- Onboarding status (not started / in progress / complete)
- Industry, plan, region, lifecycle stage
- “At risk” vs “healthy” based on your adoption score
Each segment page should answer: “Which accounts are driving this tier’s adoption score up or down?” Include a ranked list of accounts with score change over time and top contributing features.
Account profile view: timeline, score, milestones
Your account profile should feel like a case file:
- Usage timeline (last 30/90 days): key events, active days, major feature touchpoints
- Adoption score with a simple breakdown (e.g., activation, breadth, depth)
- Milestones: first key action, feature X adopted, invited teammates, reached threshold Y
Keep it scannable: show deltas (“+12 this week”) and annotate spikes with the feature/event that caused them.
User drill-down and cohort views
From the account page, list users by recent activity and role. Clicking a user shows their feature usage and last-seen context.
Add cohort views to explain patterns: signup month, onboarding program, and tier at signup. This helps CS compare like-with-like rather than mixing brand-new accounts with mature ones.
Feature adoption by tier + exporting for workflows
Include a “Who uses what” view per tier: adoption rate, frequency, and trending features, with a click-through list of accounts using (or not using) each feature.
For CS and Sales, add export/share options: CSV export, saved views, and shareable internal links (e.g., /accounts/{id}) that open with filters applied.
Alerts and Actionable Workflows by Tier
Make your build budget go further
Get credits by sharing what you build or referring teammates to Koder.ai.
Dashboards are great for understanding adoption, but teams act when they’re nudged at the right moment. Alerts should be tied to account tier so CS and Sales aren’t flooded with low-value noise—or worse, missing critical issues in your highest-value accounts.
Define tier-specific risk signals
Start with a small set of “something is wrong” signals:
- Usage drop: a meaningful decline in weekly active users, key events, or sessions versus the account’s own baseline.
- Stalled onboarding: no progress past activation milestones (e.g., no project created, no integration connected) within an expected window.
- Low activation: the account never reaches the minimum “aha” usage threshold after signup or purchase.
Make these signals tier-aware. For example, Enterprise might alert on a 15% week-over-week drop in a core workflow, while SMB might require a 40% drop to avoid churn-noise from sporadic usage.
Define tier-specific expansion signals
Expansion alerts should highlight accounts that are growing into more value:
- Power users emerging: multiple users repeatedly completing high-value workflows.
- Feature breadth: adoption across several key features (not just one).
- High growth: rising seat count, invitations sent, or steady increases in active users.
Again, thresholds differ by tier: a single power user may matter for SMB, while Enterprise expansion should require multi-team adoption.
Notifications that drive action
Route alerts to where work happens:
- Slack/email for real-time signals (e.g., onboarding stalled for a top-tier account).
- A weekly digest for lower-urgency insights (e.g., accounts trending up in feature breadth).
Keep the payload actionable: account name, tier, what changed, comparison window, and a link to the drill-down view (e.g., /accounts/{account_id}).
Playbooks: what to do when an alert fires
Every alert needs an owner and a short playbook: who responds, the first 2–3 checks (data freshness, recent releases, admin changes), and the recommended outreach or in-app guidance.
Document playbooks next to metric definitions so responses stay consistent and alerts remain trusted.
Data Quality, Monitoring, and Metric Governance
If adoption metrics drive tier-specific decisions (CS outreach, pricing conversations, roadmap bets), the data feeding them needs guardrails. A small set of checks and governance habits will prevent “mystery drops” in dashboards and keep stakeholders aligned on what numbers mean.
Validation at the edge
Validate events as early as possible (client SDK, API gateway, or ingestion worker). Reject or quarantine events that can’t be trusted.
Implement checks like:
- Missing
account_idoruser_id(or values that don’t exist in your accounts table) - Invalid tier values (anything outside your approved enum)
- Impossible timestamps (far future/past) and missing required properties for key events
Keep a quarantine table so you can inspect bad events without polluting analytics.
Monitoring volume and freshness
Adoption tracking is time-sensitive; late events distort weekly active usage and tier rollups. Monitor:
- Event volume by type and tier (sudden spikes/drops)
- Freshness and delay distributions (e.g., p95 ingestion lag)
- Pipeline health (failed jobs, backfills running, broken dependencies)
Route monitors to an on-call channel, not to everyone.
Duplicates, retries, and idempotency
Retries happen (mobile networks, webhook redelivery, batch replays). Make ingestion idempotent using an idempotency_key or a stable event_id, and dedupe within a time window.
Your aggregations should be safe to re-run without double counting.
Metric governance: one meaning, one owner
Create a glossary that defines each metric (inputs, filters, time window, tier attribution rules) and treat it as the single source of truth. Link dashboards and docs to that glossary (e.g., /docs/metrics).
Add audit logs for metric definitions and adoption scoring rule changes—who changed what, when, and why—so shifts in trends can be explained quickly.
Privacy, Security, and Access Control
Iterate without breaking trust
Experiment safely with snapshots and rollback when metric rules change.
Adoption analytics is only useful if people trust it. The safest approach is to design your tracking app to answer adoption questions while collecting the least sensitive data possible, and to make “who can see what” a first-class feature.
Minimize personal data (by design)
Start with identifiers sufficient for adoption insights: account_id, user_id (or a pseudonymous id), timestamp, feature, and a small set of behavior properties (plan, tier, platform). Avoid capturing names, email addresses, free-text inputs, or anything that could accidentally contain secrets.
If you need user-level analysis, store user identifiers separately from PII and join only when necessary. Treat IP addresses and device identifiers as sensitive; if you don’t need them for scoring, don’t keep them.
Roles, permissions, and safe defaults
Define clear access roles:
- Exec/Leadership: account- and tier-level rollups only
- CS/Sales: account-level details; limited user-level views if required
- Product/Analytics: deeper user-level exploration with audit trails
- Admin: configuration, retention, and deletion controls
Default to aggregated views. Make user-level drill-down an explicit permission, and hide sensitive fields (emails, full names, external ids) unless a role truly requires them.
Retention, deletion, and consent
Support deletion requests by being able to remove a user’s event history (or anonymize it) and to delete account data on contract end.
Implement retention rules (for example, keep raw events for N days, keep aggregates longer) and document them in your policy. Record consent and data processing responsibilities where applicable.
Architecture Choices and a Practical Build Roadmap
The fastest way to get value is to choose an architecture that matches where your data already lives. You can always evolve it later—what matters is getting trustworthy tier-level insights into people’s hands.
Two common build approaches
Warehouse-first analytics: events flow into a warehouse (e.g., BigQuery/Snowflake/Postgres), then you compute adoption metrics and serve them to a lightweight web app. This is ideal if you already rely on SQL, have analysts, or want one source of truth shared with other reporting.
App-first analytics: your web app writes events to its own database and calculates metrics inside the application. This can be quicker for a small product, but it’s easier to outgrow when event volume increases and historical reprocessing becomes necessary.
A practical default for most SaaS teams is warehouse-first with a small operational database for app configuration (tiers, metric definitions, alert rules).
Core components (keep it simple)
- Web UI: tier overview + account drill-down pages.
- API: serves pre-aggregated metrics, account lists, and filters.
- Warehouse / analytics DB: raw events + modeled tables for daily adoption metrics.
- Job runner: scheduled transformations (daily/hourly), backfills, and scoring.
Buy vs build decisions that save weeks
- Charts: start with a proven charting library (or embed a BI tool for early iterations) rather than building visualization primitives.
- Auth: use an established provider (SSO, roles) to avoid security pitfalls.
- Event collection: use an SDK or gateway you trust; only build a custom collector if you have strict requirements.
MVP roadmap (2–4 weeks)
Ship a first version with:
-
3–5 metrics (e.g., active accounts, key feature usage, adoption score, weekly retention, time-to-first-value).
-
One tier overview page: adoption score by tier + trend over time.
-
One account view: current tier, last activity, top features used, and a simple “why the score is what it is.”
Plan for iteration without breaking trust
Add feedback loops early: let Sales/CS flag “this looks wrong” directly from the dashboard. Version your metric definitions so you can change formulas without rewriting history silently.
Roll out gradually (one team → whole org) and keep a changelog of metric updates in the app (e.g., /docs/metrics) so stakeholders always know what they’re looking at.
Where Koder.ai Fits (Fast Prototyping Without Lock-In)
If you want to move from “spec” to a working internal app quickly, a vibe-coding approach can help—especially for the MVP phase where you’re validating definitions, not perfecting infrastructure.
With Koder.ai, teams can prototype an adoption analytics web app through a chat interface while still generating real, editable code. That’s a good fit for this kind of project because the scope is cross-cutting (React UI, an API layer, a Postgres data model, and scheduled rollups) and tends to evolve rapidly as stakeholders converge on definitions.
A common workflow:
- Use Planning Mode to map the tier model, event schema, and dashboard questions into an implementation plan.
- Generate a React dashboard UI plus a Go backend backed by PostgreSQL for configuration tables (tiers, metric definitions, alert rules).
- Export the source code when you’re ready to hand it to engineering, and use snapshots/rollback to safely iterate as metric definitions change.
Because Koder.ai supports deployment/hosting, custom domains, and code export, it can be a practical way to get to a credible internal MVP while keeping your long-term architecture choices (warehouse-first vs app-first) open.
FAQ
What does “product adoption” mean in a tiered B2B SaaS product?
Start with a shared definition of adoption as a sequence:
- Activation: first meaningful success that proves value.
- Feature use: repeated use of key value-driving features.
- Retention: continued usage week over week/month over month.
Then make it tier-aware (e.g., SMB activation in 7 days vs. Enterprise activation requiring admin + end-user actions).
Why should adoption tracking be segmented by account tier?
Because tiers behave differently. A single metric can:
- Penalize SMB for naturally lower frequency.
- Hide Enterprise risk when a few heavy users mask low rollout breadth.
Segmenting by tier lets you set realistic targets, choose the right north star per tier, and trigger the right alerts for high-value accounts.
How do I define account tiers so reporting stays consistent over time?
Use a deterministic, documented rule set:
- Choose a source of truth (billing, CRM, or an internal mapping table).
- Define tie-breakers for conflicts (e.g., billing overrides CRM unless a sales override flag exists).
- Set an effective date and keep an account_tier_history table with
valid_from/valid_to.
This prevents dashboards from changing meaning when accounts upgrade or downgrade.
What’s a good “north-star” metric for adoption by tier?
Pick one primary outcome per tier that reflects real value:
- Starter/SMB: activated accounts (fast time-to-first-value).
- Mid-market: weekly active accounts using key features.
- Enterprise: multi-team adoption or rollout milestones.
Make it countable, hard to game, and clearly tied to customer outcomes—not clicks.
How do I design an adoption funnel with unambiguous stage definitions?
Define explicit stages and qualification rules so interpretation doesn’t drift. Example:
- Invited → Signed up: at least one user created.
- Activated: setup checklist completed and first key action performed.
- Integrated: at least one integration connected.
- Adopting: repeated key actions on multiple days/weeks.
Which events should I instrument first for adoption tracking?
Track a small set of critical-path events:
signup_completeduser_invited,invite_acceptedfirst_value_received(define your “aha” precisely)
What event properties are essential for tier-level adoption analytics?
Include properties that make slicing and attribution reliable:
Should I model adoption with raw events, snapshots, or both?
Use both:
- Raw events as the source of truth.
- Daily account snapshots for fast dashboards (one row per account per day).
Snapshots typically store active users, key feature counts, adoption score components, and the tier for that day—so tier changes don’t rewrite historical reporting.
How can I build an adoption score that teams will actually trust?
Make it simple, explainable, and stable:
- Score 0–100 from a weighted checklist (e.g., Activation 40, Core usage 40, Expansion 20).
- Define each rule in terms of events (e.g., core usage =
core_actionon 3 distinct days in 14 days). - Store contributing factors so you can show why it changed.
Roll up by tier using distributions (median, percentiles, % above a threshold), not just averages.
How do I set up tier-aware alerts without spamming Customer Success and Sales?
Make alerts tier-specific and actionable:
- Risk signals: usage drop vs. baseline, stalled onboarding, low activation.
- Expansion signals: increasing seats, rising active users, broader feature adoption.
Route notifications to where work happens (Slack/email for urgent, weekly digests for low urgency), and include the essentials: what changed, comparison window, and a drill-down link like /accounts/{account_id}.