Nov 24, 2025·8 min
How to Build a Website for a Technical Comparison Matrix
Learn how to plan, design, and build a website that hosts a technical decision comparison matrix with clear criteria, scoring, filters, and SEO-friendly pages.
Learn how to plan, design, and build a website that hosts a technical decision comparison matrix with clear criteria, scoring, filters, and SEO-friendly pages.
A comparison matrix is only as useful as the decision it helps someone make. Before you design tables, filters, or scoring, get specific about who will use the site and what they’re trying to decide. This prevents a common failure mode: building a beautiful grid that answers questions nobody is asking.
Different audiences interpret the same “feature comparison” very differently:
Pick a primary audience for the first version. You can still support secondary users, but the site’s default views, terminology, and priorities should reflect the main user group.
Write down the concrete decisions the matrix must enable. Examples include:
These decisions inform which criteria become top-level filters, which become “details,” and which can be omitted.
Avoid vague goals like “increase engagement.” Choose metrics that reflect decision progress:
“Technical evaluation” can include many dimensions. Align on what matters most for your users, such as:
Document these priorities in plain language. This becomes your north star for later choices: data model, scoring rules, UX, and SEO.
Your data model determines whether the matrix stays consistent, searchable, and easy to update. Before you design screens, decide what “things” you’re comparing, what you’re measuring, and how you’ll store proof.
Most technical comparison sites need a small set of building blocks:
Model criteria as reusable objects and store each vendor/product’s value as a separate record (often called an “assessment” or “criterion result”). That lets you add new vendors without duplicating the criteria list.
Avoid forcing everything into plain text. Pick a type that matches how people will filter and compare:
Also decide how to represent “Unknown,” “Not applicable,” and “Planned,” so blanks don’t read as “No.”
Criteria evolve. Store:
Create fields (or even a separate table) for internal commentary, negotiation details, and reviewer confidence. Public pages should show the value and the evidence; internal views can include candid context and follow-up tasks.
A comparison matrix site succeeds when visitors can predict where things live and how to get there. Decide on an information architecture that mirrors how people evaluate options.
Start with a simple, stable taxonomy that won’t change every quarter. Think in “problem areas” rather than vendor names.
Examples:
Keep the tree shallow (usually 2 levels is enough). If you need more nuance, use tags or filters (e.g., “Open-source,” “SOC 2,” “Self-hosted”) rather than deep nesting. This helps users browse confidently and prevents duplicate content later.
Design your site around a few repeatable page templates:
Add supporting pages that reduce confusion and build credibility:
Pick URL rules early so you don’t create messy redirects later. Two common patterns:
/compare/a-vs-b (or /compare/a-vs-b-vs-c for multi-way)/category/ci-cdKeep URLs short, lowercase, and consistent. Use the product’s canonical name (or a stable slug) so the same tool doesn’t end up as both /product/okta and /product/okta-iam.
Finally, decide how filtering and sorting affects URLs. If you want shareable filtered views, plan a clean query-string approach (e.g., ?deployment=saas&compliance=soc2) and keep the base page usable without any parameters.
A comparison matrix only helps people decide if the rules are consistent. Before you add more vendors or criteria, lock down the “math” and the meaning behind every field. This avoids endless debates later (“What did we mean by SSO support?”) and makes your results defensible.
Start with a canonical list of criteria and treat it like a product spec. Each criterion should have:
Avoid near-duplicates such as “Compliance” vs “Certifications” unless the distinction is explicit. If you need variants (e.g., “Encryption at rest” and “Encryption in transit”), make them separate criteria with separate definitions.
Scores are only comparable if everyone uses the same scale. Write scoring rubrics that fit the criterion:
Define what each point means. For example, “3” might be “meets the requirement with limitations,” while “5” is “meets the requirement with advanced options and proven deployments.” Also specify whether “N/A” is allowed and when.
Weighting changes the story your matrix tells, so choose intentionally:
If you support custom weights, define guardrails (e.g., weights must sum to 100, or use low/medium/high presets).
Missing data is inevitable. Document your rule and apply it everywhere:
These policies keep your matrix fair, repeatable, and trustworthy as it grows.
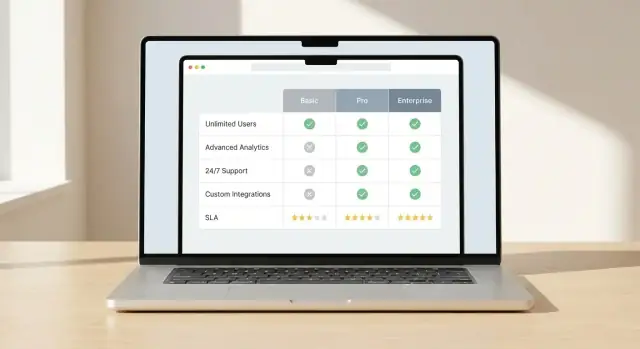
Your comparison UI succeeds or fails on one thing: whether a reader can quickly see what’s meaningfully different. Decide on a primary comparison view and a set of visual cues that make contrasts jump off the page.
Pick one main pattern and design everything around it:
Consistency matters. If users learn how differences are shown in one area, the same rules should apply everywhere.
Avoid forcing people to scan every cell. Use deliberate highlights:
Keep color meaning simple and accessible: one color for “better,” one for “worse,” and a neutral state. Don’t rely on color alone—include icons or short labels.
Long matrices are normal in technical evaluation. Make them usable:
Mobile users won’t tolerate tiny grids. Offer:
When differences are easy to spot, readers trust the matrix—and keep using it.
A comparison matrix only feels “fast” when people can narrow the list and see meaningful differences without scrolling for minutes. Filtering, sorting, and side-by-side views are the core interaction tools that make that possible.
Start with a small set of filters that reflect real evaluation questions, not just what’s easy to store. Commonly useful filters include:
Design filters so users can combine them. Show how many items match as they filter, and make it obvious how to clear filters. If some filters are mutually exclusive, prevent invalid combinations instead of showing “0 results” with no explanation.
Sorting should reflect both objective and audience-specific priorities. Provide a few clear options such as:
If you show a “best score,” display what that score represents (overall vs. category score) and allow users to switch the scoring view. Avoid hidden defaults.
Let users select a small set (typically 2–5) and compare them in a fixed column layout. Keep the most important criteria pinned near the top, and group the rest into collapsible sections to reduce overwhelm.
Make the comparison shareable with a link that preserves selections, filters, and sort order. That enables teams to review the same shortlist without recreating it.
Exports can be valuable for internal review, procurement, and offline discussion. If your audience needs it, offer CSV (for analysis) and PDF (for sharing). Keep exports focused: include selected items, chosen criteria, timestamps, and any notes about scoring so the file isn’t misleading when viewed later.
Readers will only use your matrix to make decisions if they trust it. If your pages make strong claims without showing where the data came from—or when it was checked—users will assume it’s biased or outdated.
Treat each cell as a statement that needs evidence. For anything factual (pricing tier limits, API availability, compliance certifications), store a “source” field alongside the value:
In the UI, make the source visible without clutter: a small “Source” label in a tooltip or an expandable row works well.
Add metadata that answers two questions: “How current is this?” and “Who stands behind it?”
Include a “Last verified” date for each product (and optionally for each criterion), plus an “Owner” (team or person) responsible for review. This is especially important for fast-changing items like feature flags, integrations, and SLA terms.
Not everything is binary. For subjective criteria (ease of setup, quality of support) or incomplete items (vendor hasn’t published details), show confidence levels such as:
This prevents false precision and encourages readers to dig into the notes.
On each product page, include a small change log when key fields change (pricing, major features, security posture). Readers can quickly see what’s new, and returning stakeholders can trust they’re not comparing stale information.
A comparison matrix is only as useful as it is current. Before you publish the first page, decide who can change data, how those changes get reviewed, and how you’ll keep scoring consistent across dozens (or thousands) of rows.
Start by picking the “source of truth” for your matrix data:
The key isn’t the technology—it’s whether your team can update it reliably without breaking the matrix.
Treat changes like product releases, not casual edits.
A practical workflow looks like this:
If you expect frequent updates, add lightweight conventions: change requests, a standard “reason for update” field, and scheduled review cycles (monthly/quarterly).
Validation prevents silent drift in your matrix:
Manual editing doesn’t scale. If you have many vendors or frequent data feeds, plan for:
When your workflow is clear and enforced, your comparison matrix stays trustworthy—and trust is what makes people act on it.
A comparison matrix feels simple on the surface, but the experience depends on how you fetch, render, and update lots of structured data without delays. The goal is to keep pages fast while making it easy for your team to publish changes.
Pick a model based on how often your data changes and how interactive the matrix is:
Matrix tables get heavy quickly (many vendors × many criteria). Plan for performance early:
Search should cover vendor names, alternative names, and key criteria labels. For relevance, index:
Return results that jump users directly to a vendor row or a criteria section, not just a generic results page.
Track events that show intent and friction:
Capture the active filters and compared vendor IDs in the event payload so you can learn which criteria drive decisions.
If you want to ship a comparison site quickly—without spending weeks on scaffolding, CRUD admin screens, and basic table UX—a vibe-coding platform like Koder.ai can be a practical shortcut. You can describe your entities (products, criteria, evidence), required workflows (review/approval), and key pages (category hub, product page, compare page) in chat, then iterate on the generated app.
Koder.ai is especially relevant if your target stack matches its defaults: React on the web, Go on the backend with PostgreSQL, and optional Flutter if you later want a mobile companion for “saved comparisons.” You can also export source code, use snapshots/rollback while you tune scoring logic, and deploy with custom domains when you’re ready to publish.
Comparison pages are often the first touchpoint for high-intent visitors (“X vs Y”, “best tools for…”, “feature comparison”). SEO works best when each page has a clear purpose, a stable URL, and content that’s genuinely distinct.
Give every comparison page its own page title and on-page H1 that matches the intent:
Open with a short summary that answers: who this comparison is for, what’s being compared, and what the headline differences are. Then include a compact verdict section (even if it’s “best for X, best for Y”) so the page doesn’t feel like a generic table.
Structured data can improve how your pages appear in search results when it reflects visible content.
Avoid stuffing every page with schema types or adding fields you can’t support with evidence. Consistency and accuracy matter more than volume.
Filtering and sorting can create many near-identical URLs. Decide what should be indexable and what should not:
Help search engines and people navigate the same way they evaluate:
Use descriptive anchor text (“compare pricing model”, “security features”) rather than repetitive “click here”.
For big matrices, your SEO success depends on what you don’t index.
Include only high-value pages in your sitemap (hubs, core products, curated comparisons). Keep thin, auto-generated combinations out of indexation, and monitor crawl stats so search engines spend time on pages that actually help users decide.
A comparison matrix only works if it stays accurate, easy to use, and trustworthy. Treat launch as the start of an ongoing cycle: test, release, learn, and update.
Run usability tests that focus on the real outcome: can users decide faster and with more confidence? Give participants a realistic scenario (for example, “pick the best option for a 50-person team with strict security needs”) and measure:
Comparison UIs often fail basic accessibility checks. Before launch, verify:
Spot-check the most-viewed vendors/products and the most important criteria first. Then test edge cases:
Set expectations internally and publicly: data changes.
Define how users can report issues or suggest updates. Offer a simple form with category options (data error, missing feature, UX issue) and commit to response targets (for example, acknowledge within 2 business days). Over time, this becomes your best source of “what to fix next.”
Start by defining the primary audience and the concrete decision they’re trying to make (shortlist, replacement, RFP, validation of requirements). Then choose criteria and UX defaults that match that audience’s constraints.
A good internal check: can a user go from landing page to a defensible shortlist quickly, without learning your whole scoring system?
Treat each cell as a claim that needs support. Store evidence alongside the value (docs section, release note, internal test) and show it in the UI via tooltips or expandable notes.
Also display:
Use core entities that keep comparisons consistent:
Model criteria as reusable objects, and store each product’s value separately so you can add vendors without duplicating the criteria list.
Use data types that match how people will filter and compare:
Define explicit states for Unknown, Not applicable, and Planned so blank cells don’t get interpreted as “No.”
Use a small set of repeatable templates:
Support credibility and clarity with methodology, glossary, and contact/corrections pages.
Pick URL patterns that scale and stay consistent:
/compare/a-vs-b (and -vs-c for multi-way)/category/ci-cdIf you support shareable filtered views, keep the base page stable and use query strings (e.g., ?deployment=saas&compliance=soc2). Also plan canonical URLs to avoid duplicate SEO pages from filters and sorts.
Write a rubric per criterion and choose a scoring style that fits:
Document how unknowns affect totals (0 vs neutral vs excluded) and apply the rule consistently across the site.
Weighting changes the story, so decide intentionally:
If you allow custom weights, add guardrails (e.g., weights sum to 100, presets like low/medium/high).
Design around speed to shortlist:
Consider CSV/PDF export if your audience needs procurement/offline review, and include timestamps and scoring notes so exports aren’t misleading later.
Common performance levers for large matrices:
A practical approach is hybrid rendering: prebuild stable pages, then load interactive matrix data via an API so the UI stays fast while data remains updateable.