Oct 07, 2025·8 min
How to Build a Web App for Logistics Tracking: Drivers & Routes
Plan and build a logistics web app to track deliveries, drivers, and routes. Learn core features, data flow, maps, notifications, security, and rollout steps.
Plan and build a logistics web app to track deliveries, drivers, and routes. Learn core features, data flow, maps, notifications, security, and rollout steps.
Before you sketch screens or pick a tech stack, decide what success looks like for your logistics web app. “Tracking” can mean many things, and vague goals usually lead to a cluttered product that no one loves.
Pick one primary business goal and a couple of supporting goals. Examples:
A good goal is specific enough to guide decisions. For instance, “reduce late deliveries” will push you toward accurate ETAs and exception handling—not just a prettier map.
Most delivery tracking software has multiple audiences. Define them early so you don’t build everything for one role.
Keep it to three so your MVP stays focused. Common metrics:
Write down the exact signals your system will capture:
This definition becomes your shared contract for product decisions and team expectations.
Before you design screens or pick tools, agree on a single “truth” for how a delivery moves through your operation. A clear workflow prevents confusion like “Is this stop still open?” or “Why can’t I reassign this job?”—and it makes reporting reliable.
Most logistics teams can align on a simple backbone:
Create jobs → assign driver → navigate → deliver → close out.
Even if your business has special cases (returns, multi-drop routes, cash on delivery), keep the backbone consistent and add variations as exceptions rather than inventing a new flow for every customer.
Define statuses in plain language and make them mutually exclusive. A practical set is:
Agree on what causes each status change. For example, “En route” might be automatic when the driver taps “Start navigation,” while “Delivered” should always be explicit.
Driver actions to support:
Dispatcher actions to support:
To reduce disputes later, log every change with who, when, and why (especially for Failed and reassignment).
A clear data model is what turns a “map with dots” into dependable delivery tracking software. If you define the core objects well, your dispatch dashboard becomes easier to build, reports are accurate, and operations don’t rely on workarounds.
Model each delivery as a job that moves through statuses (planned, assigned, en route, delivered, failed, etc.). Include fields that support real dispatch decisions, not just addresses:
Tip: treat pickup and drop-off as “stops” so a job can later expand to multi-stop without redesigning.
Drivers are more than a name on a route. Capture operational constraints so route optimization and dispatching stay realistic:
A route should store the ordered list of stops, plus what the system expected versus what happened:
Add an immutable event log: who changed what and when (status updates, edits, reassignments). This supports customer disputes, compliance, and “why was this late?” analysis—especially when paired with proof of delivery and exceptions.
Great logistics tracking software is mostly a UX problem: the right information, at the right moment, with the fewest clicks. Before building features, sketch the core screens and decide what each user must be able to do in under 10 seconds.
This is where work gets assigned and problems get handled. Make it “glanceable” and action-first:
Keep the list view fast, searchable, and optimized for keyboard use.
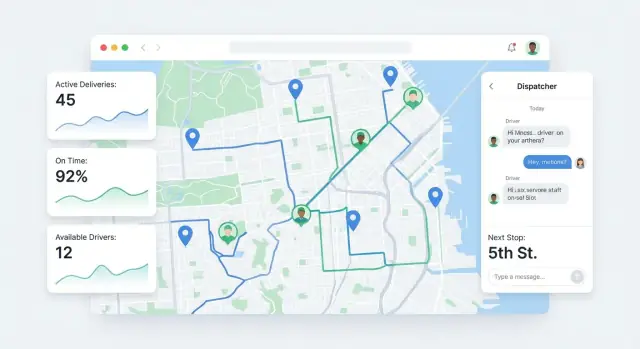
Dispatchers need a map that explains the day, not just points on a map.
Show live driver positions, stop pins, and color-coded statuses (Planned, En route, Arrived, Delivered, Failed). Add simple toggles: “show only late risk,” “show only unassigned,” and “follow driver.” Clicking a pin should open a compact stop card with ETA, notes, and next actions.
The driver screen should focus on the next stop, not the whole plan.
Include: next stop address, instructions (gate code, drop-off notes), contact buttons (call/text dispatcher or customer), and a quick status update with minimal typing. If you support proof of delivery, keep it in the same flow (photo/signature + short note).
Managers need trends, not raw events: on-time performance, delivery time by zone, and top failure reasons. Make reports easy to export and easy to compare week over week.
Design tip: define a consistent status vocabulary and color system across every screen—this reduces training time and avoids costly misunderstandings.
Maps are where your tracking app turns “a list of stops” into something dispatchers and drivers can act on. The goal isn’t fancy cartography—it’s fewer wrong turns, clearer ETAs, and faster decisions.
Most logistics web apps need the same core set of map features:
Decide early whether you’ll rely on a single provider (simpler) or abstract providers behind an internal service (more work now, flexibility later).
Bad addresses are a top cause of failed deliveries. Build guardrails:
Store the original text address and the resolved coordinates separately so you can audit and fix recurring issues.
Start with manual ordering (drag-and-drop stops) plus practical helpers: “cluster nearby stops,” “move failed delivery to end,” or “prioritize urgent stops.” Then add basic optimization rules (nearest-next, minimize drive time, avoid backtracking) as you learn real dispatch behavior.
Even MVP route planning should understand constraints such as:
If you document these constraints clearly in the UI, dispatchers will trust the plan—and know when to override it.
Real-time driver tracking is only useful if it’s reliable, understandable, and respectful of battery life. Before you write code, decide what “real-time” means for your operations: do dispatchers need second-by-second movement, or is “every 30–60 seconds” enough to answer customer questions and react to delays?
Higher update frequency gives smoother movement on the dispatch dashboard, but it drains battery and uses more mobile data.
A practical starting point:
You can also trigger updates on meaningful events (arrived at stop, leaving stop) rather than constant pings.
For the dispatcher view, you have two common patterns:
Many teams start with periodic refresh and add WebSockets later when dispatch volume grows.
Don’t only keep the latest coordinate. Save track points (timestamp + lat/long + optional speed/accuracy) so you can:
Mobile networks drop. The driver app should queue location events locally when the signal is lost and sync automatically when it returns. On the dashboard, mark the driver as “Last update: 7 min ago” instead of pretending the dot is current.
Done well, real-time GPS tracking builds trust: dispatch sees what’s happening, and drivers aren’t punished by unreliable connectivity.
Notifications and exception handling are what turn a basic logistics web app into dependable delivery tracking software. They help your team act early, and they give customers fewer reasons to call.
Start with a small set of events that matter to operations and customers: dispatched, arriving soon, delivered, and failed delivery. Let users choose the channel—push, SMS, or email—and who receives what (dispatcher only, customer only, or both).
A practical rule: send customer-facing messages only when something changes, and keep operational messages more detailed (stop reason, contact attempts, notes).
Exceptions should be triggered by clear conditions, not gut feel. Common ones in last-mile delivery:
When an exception fires, show a suggested next step in the dispatch dashboard: “call recipient,” “reassign,” or “mark as delayed.” This keeps fleet management decisions consistent.
Proof of delivery should be easy for drivers and verifiable for disputes. Typical options:
Store POD as part of the delivery record, and make it downloadable for customer support.
Different clients want different wording. Add message templates and per-customer settings (time windows, escalation rules, and quiet hours). This makes your logistics web app adaptable without needing code changes as your delivery volume grows.
Accounts and access control are easy to overlook until the first dispute, the first new depot, or the first customer asks, “Who changed this delivery?” A clear permissions model prevents accidental edits, protects sensitive data, and makes the dispatch team faster.
Start with a simple email/password flow, but make it production-ready:
If your customers or larger clients use identity providers (Google Workspace, Microsoft Entra ID/AD), plan for SSO as an upgrade path. Even if you don’t build it in the MVP, design user records so they can later link to an SSO identity without creating duplicate accounts.
Avoid creating dozens of micro-permissions at the start. Define a small set of roles that map to real jobs, then refine based on feedback.
Common roles for a logistics web app:
Then decide who can do sensitive actions:
If you have more than one depot, you’ll want tenant-like separation early:
This keeps teams focused and reduces accidental changes to another depot’s work.
For disputes, chargebacks, and “why was this rerouted?” questions, build an append-only event log for key actions:
Make audit entries immutable and queryable by delivery ID and user. It’s also helpful to show a human-friendly “Activity” timeline on the delivery detail screen (see /blog/proof-of-delivery-basics if you cover POD elsewhere), so ops can resolve issues without digging into raw data.
Integrations are what turn a tracking tool into a day-to-day operations hub. Before you write code, list the systems you already rely on and decide which one is the “source of truth” for orders, customer data, and billing.
Most logistics teams touch several platforms: an order management system, WMS, TMS, CRM, and accounting. Decide what data you pull in (orders, addresses, time windows, item counts) and what data you push back (status updates, proof of delivery, exceptions, charges).
A simple rule: avoid double-entry. If dispatchers create jobs in an OMS, don’t force them to recreate deliveries in your logistics web app.
Keep your API centered on the objects your team understands:
REST endpoints work well for most cases, and webhooks handle real-time updates to external systems (e.g., “delivered,” “failed delivery,” “ETA changed”). Make idempotency a requirement for status updates so retries don’t duplicate events.
Even with APIs, operations teams will ask for CSV:
Add scheduled syncs (hourly/nightly) where needed, plus clear error reporting: what failed, why, and how to fix it.
If your workflow uses barcode scanners or label printers, define how they interact with your app (scan to confirm stop, scan to verify package, print labels at depot). Start with a small supported set, document it, and expand once the MVP proves value.
Tracking deliveries and drivers means handling highly sensitive operational data: customer addresses, phone numbers, signatures, and real-time GPS. A few upfront decisions here can prevent costly incidents later.
At minimum, encrypt data in transit with HTTPS/TLS. For data at rest, enable encryption where your hosting provider supports it (databases, object storage for photos, backups). Store API keys and access tokens in a secure secrets manager—not in source code or shared spreadsheets.
Real-time GPS is powerful, but it shouldn’t be more detailed than necessary. Many teams only need:
Define clear retention periods. For example: keep high-frequency location pings for 7–30 days, then downsample (hourly/daily points) for performance reporting.
Add rate limiting to login, tracking, and public proof-of-delivery links to reduce abuse. Centralize logging (app events, admin actions, and API requests) so you can answer “who changed this status?” quickly.
Also plan backup and restore from day one: automated daily backups, tested restore steps, and an incident checklist your team can follow under pressure.
Collect only what you need and document why. Provide consent and notice for driver tracking, and define how you handle data access or deletion requests. A short, plain-language policy—shared internally and with customers—helps align expectations and reduces surprises later.
A logistics tracking app succeeds or fails in real life: messy addresses, late drivers, poor connectivity, and dispatchers under pressure. A solid testing plan, a careful pilot, and practical training are what turn “working software” into “software people actually use.”
Go beyond happy-path tests and recreate day-to-day chaos:
Include both web (dispatch) and mobile (driver) flows, plus exception flows like failed delivery, return-to-depot, or customer not home.
Tracking and maps can feel slow before they actually crash. Test:
Measure load times and responsiveness, then set performance targets your team can monitor.
Start with one depot or one region, not the whole company. Define success criteria upfront (e.g., % of deliveries with proof of delivery, fewer “where is my driver?” calls, improved on-time rate). Collect feedback weekly, fix issues fast, then expand.
Create a short quick-start guide, add in-app tips for first-time users, and set a clear support process: who drivers contact on the road, and how dispatch reports bugs. Adoption improves when people know exactly what to do when something goes wrong.
If you’re building a logistics web app for the first time, the fastest way to ship is to define a narrow MVP that proves value for dispatch and drivers, then add automation and analytics once the workflow is stable.
Must-haves for a first release usually include: a dispatch dashboard to create deliveries and assign drivers, a driver-friendly mobile web view (or simple app) to see the stop list, basic status updates (e.g., Picked up, Arrived, Delivered), and a map view for route visibility.
Nice-to-haves that often slow teams down early: complex route optimization rules, multi-depot planning, automated customer ETAs, custom reports, and extensive integrations. Keep these out of the MVP unless you already know they drive revenue.
A practical stack for logistics app development is:
If your main challenge is speed-to-first-version, a vibe-coding approach can help you validate the workflow before investing heavily in a custom build. With Koder.ai, teams can describe the dispatcher dashboard, driver flow, statuses, and data model in chat, then generate a working web app (React) with a Go + PostgreSQL backend.
This can be especially useful for piloting:
When the MVP proves value, you can export the source code and continue with a traditional engineering pipeline, or keep deploying and hosting through the platform.
The biggest cost drivers in delivery tracking software are often usage-based:
If you need help estimating these line items, it’s worth requesting a quick quote on /pricing or discussing your workflow on /contact.
Once the MVP is stable, common upgrades are: customer tracking links, stronger route optimization, delivery analytics (on-time %, dwell time), and SLA reports for key accounts.
Start with one primary goal (e.g., reduce late deliveries or cut “where is my driver?” calls), then define 3 measurable outcomes like on-time rate, failed stop rate, and idle time. These metrics keep your MVP focused and prevent “tracking” from turning into an unfocused map-and-features project.
Write a clear, shared definition of what your system captures:
This becomes the contract that guides product decisions and avoids mismatched expectations across teams.
Keep statuses mutually exclusive and define exactly what triggers each change. A practical baseline is:
Decide which transitions are automatic (e.g., “En route” when navigation starts) vs. always explicit (e.g., “Delivered”).
Treat the delivery as a job that contains stops, so you can grow into multi-stop routing later without redesigning. Core entities to model:
An append-only event log is your source of truth for disputes and analysis. Log:
Include who, when, and why so support and ops can answer “what happened?” without guessing or relying on memory.
Prioritize the screens that enable action in under 10 seconds:
Build guardrails around address quality:
Also store original text and resolved coordinates separately so you can audit recurring problems and fix upstream data.
Use a practical starting policy that balances usefulness and battery/data:
Combine periodic updates with event-triggered pings (arrive/leave a stop). Always show “Last update: X min ago” to avoid false confidence.
Plan for unreliable connectivity:
Keep roles small and tied to real jobs:
Add depot/branch scoping early if you have multiple teams, and protect sensitive actions (exports, post-dispatch edits) with stricter permissions plus audit logs.