Sep 04, 2025·8 min
How to Create a Web App for Enterprise Feature Requests
Learn how to plan, build, and launch a web app that captures enterprise feature requests, routes approvals, prioritizes roadmaps, and reports progress.
Learn how to plan, build, and launch a web app that captures enterprise feature requests, routes approvals, prioritizes roadmaps, and reports progress.
Before you sketch screens or pick a tech stack, get specific about the problem your feature request web app is supposed to solve. “Collect feedback” is too broad; enterprises already have email threads, spreadsheets, CRM notes, and support tickets doing that (usually poorly). Your job is to replace the chaos with a single, reliable system of record.
Most teams build an enterprise feature request management app to fix three pain points:
Write a one-sentence problem statement, such as:
We need a feature request web app that consolidates requests across teams, reduces duplicates, and supports a transparent feature triage workflow.
A common mistake is designing for “the product team” only. In B2B product management, multiple groups need to submit, enrich, and consume requests:
Decide early which of these are true “users” of the app versus “consumers” of reports.
Be explicit about the outcomes you’re optimizing for:
Then attach measurable success metrics, for example:
These goals will guide everything that follows: your data model, roles and permissions, voting and insights, and what you automate later (like release notes automation).
Your intake model determines who can submit requests, how much context you capture upfront, and how “safe” the system feels for enterprise customers. The best choice is usually a mix, not a single door.
A public portal works when your product is largely standardized and you want to encourage broad participation (e.g., SMB + enterprise). It’s great for discoverability and self-serve submission, but it requires careful moderation and clear expectations about what will (and won’t) be built.
A private portal is often better for enterprise. It lets customers submit requests without worrying that competitors will see their needs, and it supports account-specific visibility. Private portals also reduce noise: fewer “nice-to-have” ideas, more actionable requests tied to contracts, deployments, or compliance.
Even with a portal, many enterprise requests originate elsewhere: emails, quarterly business reviews, support tickets, sales calls, and CRM notes. Plan for an internal intake path where a PM, CSM, or Support lead can quickly create a request on behalf of a customer and attach the original source.
This is where you standardize messy inputs: summarize the ask, capture affected accounts, and tag urgency drivers (renewal, blocker, security requirement).
Enterprise feature requests can be sensitive. Design for per-customer visibility, so one account can’t see another account’s requests, comments, or votes. Also consider internal partitions (e.g., Sales can see status, but not internal prioritization notes).
Duplicates are inevitable. Make it easy to merge requests while preserving:
A good rule: one canonical request, many linked supporters. That keeps triage clean while still showing demand.
A good data model makes everything else easier: cleaner intake, faster triage, better reporting, and fewer “what did they mean?” follow-ups. Aim for a structure that captures business context without turning submission into a form marathon.
Start with the essentials you’ll need to evaluate and later explain decisions:
Tip: store attachments as references (URLs/IDs) rather than blobs in your primary database to keep performance predictable.
Enterprise requests often depend on who asked and what’s at stake. Add optional fields for:
Keep these fields optional and permissioned—some users shouldn’t see revenue or contract metadata.
Use tags for flexible labeling and categories for consistent reporting:
Make categories controlled lists (admin-managed), while tags can be user-generated with moderation.
Create templates for common request types (e.g., “New integration,” “Reporting change,” “Security/compliance”). Templates can prefill fields, suggest required details, and reduce back-and-forth—especially when requests are submitted through a product feedback portal.
Enterprise feature request management breaks down quickly when everyone can change everything. Before you build screens, define who’s allowed to submit, view, edit, merge, and decide—and make those rules enforceable in code.
Start with a simple set of roles that match how B2B accounts work:
A practical rule: customers can propose and discuss, but they shouldn’t be able to rewrite history (status, priority, or ownership).
Internal teams need finer control because feature requests touch product, support, and engineering:
Write permission rules like test cases. For example:
Enterprises will ask “who changed this and why?” Capture an immutable audit log for:
Include timestamps, actor identity, and source (UI vs API). This protects you during escalations, supports compliance reviews, and builds trust when multiple teams collaborate on the same request.
A feature request app succeeds when everyone can answer two questions quickly: “What happens next?” and “Who owns it?” Define a workflow that is consistent enough for reporting, but flexible enough for edge cases.
Use a small set of statuses that map to real decisions:
Keep statuses mutually exclusive, and make sure each one has clear exit criteria (what must be true to move forward).
Triage is where enterprise requests can get messy, so standardize it:
This checklist can be surfaced directly in the admin UI so reviewers don’t rely on tribal knowledge.
For certain categories (e.g., data exports, admin controls, identity, integrations), require an explicit security/compliance review before moving from Under review → Planned. Treat this as a gate with a recorded outcome (approved, rejected, approved with conditions) to avoid surprises late in delivery.
Enterprise queues rot without timeboxes. Set automatic reminders:
These guardrails keep your pipeline healthy and your stakeholders confident that requests won’t disappear.
Enterprise feature requests rarely fail because of a lack of ideas—they fail because teams can’t compare requests fairly across accounts, regions, and risk profiles. A good scoring system creates consistency without turning prioritization into a spreadsheet contest.
Start with voting because it captures demand quickly, then constrain it so popularity doesn’t replace strategy:
Alongside the request description, collect a few required fields that help you compare across teams:
Keep the options constrained (dropdowns or small numeric ranges). The goal is consistent signals, not perfect precision.
Urgency is “how soon must we act?” Importance is “how much does it matter?” Track them separately so the loudest or most panicked request doesn’t automatically win.
A practical approach: score importance from impact fields, score urgency from deadline/risk, then display both as a simple 2x2 view (high/low).
Every request should include a visible decision rationale:
This reduces repeat escalation and builds trust—especially when the answer is “not now.”
Great enterprise feature-request apps feel “obvious” because the key pages map to how customers ask, and how internal teams decide. Aim for a small set of pages that serve different audiences well: requesters, reviewers, and leaders.
The portal should help customers quickly answer two questions: “Has someone already asked for this?” and “What’s happening with it?”
Include:
Keep the language neutral. Status labels should inform without implying a commitment.
The request detail page is where conversations happen and where confusion is either resolved—or amplified.
Make room for:
If you support voting, show it here, but avoid turning it into a popularity contest—context should outrank counts.
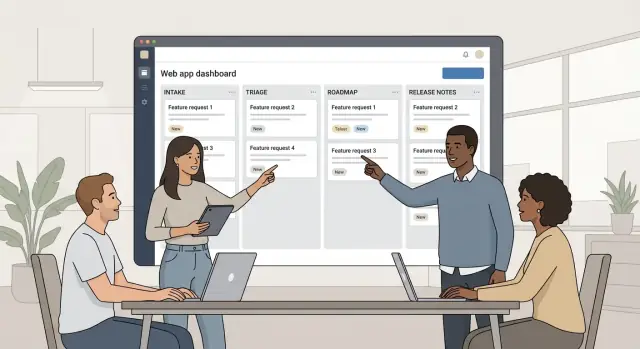
Internally, teams need a queue that reduces manual coordination.
The dashboard should show:
Enterprises expect a roadmap view, but it must be designed to avoid accidental commitments.
Use a theme-based view by quarter (or “Now / Next / Later”), with room for dependency notes and “subject to change” messaging. Link each theme back to the underlying requests to preserve traceability without overpromising delivery dates.
Enterprise customers will judge your feature request web app as much by its security posture as by its UX. The good news: you can cover most expectations with a small set of well-understood building blocks.
Support SSO via SAML (and/or OIDC) so customers can use their identity provider (Okta, Azure AD, Google Workspace). For smaller customers and internal stakeholders, keep email/password (or magic link) as a fallback.
If you offer SSO, also plan for:
At minimum, implement account-level isolation (a tenant model): users from Customer A must never see Customer B’s requests.
Many B2B products also need an optional workspace layer so large customers can separate teams, products, or regions. Keep permissions simple: Viewer → Contributor → Admin, plus an internal “Product Ops” role for triage.
Even if you’re not pursuing formal certifications yet, design for common requirements:
Security isn’t a single feature—it’s a set of defaults that make enterprise adoption easier and procurement faster.
Enterprise feature request management rarely lives in one tool. If your app can’t connect to the systems teams already use, requests will get copied into spreadsheets, context will be lost, and trust will drop.
Most teams will want a two-way link between a request and the work item that ships it:
A practical tip: avoid syncing every field. Sync the minimum needed to keep stakeholders informed, and show a deep link to the ticket for details.
Product decisions often hinge on account value and renewal risk. CRM sync helps you:
Be careful with permissions—sales data is sensitive. Consider a “CRM summary” view rather than full record mirroring.
Support teams need a one-click path from ticket → request.
Support integrations should capture conversation links, tags, and volume signals, and prevent duplicate requests by suggesting existing matches during creation.
Status changes are where adoption is won.
Send targeted updates (watchers, requesters, account owners) for key events: received, under review, planned, shipped. Let users control frequency, and include clear CTAs back to the portal (e.g., /portal/requests/123).
Your architecture should match how quickly you need to ship, how many internal teams will maintain the app, and how “enterprise” your customer expectations are (SSO, audit trails, integrations, reporting). The goal is to avoid building a complex platform before you’ve proven the workflow.
Start with a modular monolith if you want speed and simplicity. A single codebase (e.g., Rails, Django, Laravel, or Node/Nest) with server-rendered pages or light JS is often enough for intake, triage, and admin reporting. You can still structure it in modules (Intake, Workflow, Reporting, Integrations) so it evolves cleanly.
Choose API + SPA (e.g., FastAPI/Nest + React/Vue) when you expect multiple clients (portal + admin + future mobile), separate frontend/backend teams, or heavy UI interactivity (advanced filtering, bulk triage). The tradeoff is more moving parts: auth, CORS, versioning, and deployment complexity.
If you want to validate workflow and permissions quickly, consider using a vibe-coding platform like Koder.ai to generate an internal MVP from a structured spec (intake → triage → decision → portal). You describe roles, fields, and statuses in chat (or in Planning Mode), and iterate rapidly without hand-wiring every screen from scratch.
For teams that care about ownership and portability, Koder.ai supports source code export and end-to-end deployment/hosting options, which can be useful once your pilot proves what the system needs.
A relational database (PostgreSQL, MySQL) is usually the best fit because feature request systems are workflow-heavy: statuses, assignments, approval steps, audit logs, and analytics all benefit from strong consistency and SQL reporting.
If you later need event-based analytics, add a warehouse or event stream—but keep the operational system relational.
Early on, database search is fine: indexed text fields, basic ranking, and filters (product area, customer, status, tags). Add a dedicated search engine (Elasticsearch/OpenSearch/Meilisearch) when you hit real pain: thousands of requests, fuzzy matching, faceted search at speed, or cross-tenant performance constraints.
Requests often include screenshots, PDFs, and logs. Store uploads in object storage (S3/GCS/Azure Blob) rather than the app server. Add virus/malware scanning (e.g., scanning on upload via a queue worker) and enforce limits: file type allowlists, size caps, and retention policies.
If customers demand compliance features, plan for encryption at rest, signed URLs, and a clear download audit trail.
An enterprise feature request web app succeeds (or fails) based on whether busy people actually use it. The fastest way to get there is to ship a small MVP, put it in front of real stakeholders, then iterate based on observed behavior—not guesses.
Keep the first version focused on the shortest path from “request submitted” to “decision made.” A practical MVP scope usually includes:
Avoid “nice-to-haves” until you see consistent usage. Features like advanced scoring models, roadmaps, granular permissions, and SSO are valuable, but they also add complexity and can lock you into the wrong assumptions early.
Start with a pilot group—a handful of internal product stakeholders and a small set of customer accounts that represent different segments (enterprise, mid-market, high-touch, self-serve). Give them a clear way to participate and a lightweight success metric, such as:
Once the workflow feels natural for the pilot, expand gradually. This reduces the risk of forcing a half-baked process onto the whole organization.
Treat the app as a product. Add a “Feedback about this portal” entry point for customers, and run a short internal retro every couple of weeks:
Small improvements—clearer labels, better defaults, and smarter de-dupe—often drive adoption more than big new modules.
A feature request web app only works if people trust it and use it. Treat launch as an operational change, not just a software release: define owners, set expectations, and establish the rhythm for updates.
Decide who runs the system day-to-day and what “done” means at each step:
Document this in a lightweight governance page and keep it visible in the admin area.
Adoption rises when customers see a reliable feedback loop. Set a standard cadence for:
Avoid silent changes. If a request is declined, explain the reasoning and, when possible, suggest alternatives or workarounds.
Operational metrics keep the system from becoming a graveyard. Track:
Review these monthly with stakeholders to spot bottlenecks and improve your feature triage workflow.
If you’re evaluating an enterprise feature request management approach, book a demo or compare options on /pricing. For implementation questions (roles, integrations, or governance), reach out via /contact.
Start with a one-sentence problem statement that’s narrower than “collect feedback,” such as consolidating intake, reducing duplicates, and making triage decisions transparent.
Then define measurable outcomes (e.g., time-to-triage, % categorized, % with decision rationale) so your workflow, permissions, and reporting have a clear target.
Treat it as a system used by multiple groups:
Decide which groups are full “users” vs. report “consumers,” because that drives permissions and UI.
Most enterprise teams use a mix:
A hybrid approach reduces noise while still capturing everything in a single system of record.
Implement account-level isolation by default so Customer A can’t see Customer B’s requests, comments, or votes.
Add internal partitioning too (e.g., Sales can see status but not internal prioritization notes). Keep “public” requests as an explicit opt-in flag, not the default.
Use a canonical-request model:
This keeps triage clean while still showing demand and customer impact.
Capture enough to evaluate and explain decisions without turning submission into a form marathon:
Templates for common request types can improve quality without adding friction.
Define roles and write permissions like test cases. Common patterns:
Add an immutable audit log for status/priority changes, merges, permission edits, and comment deletion/redaction.
Use a small, mutually exclusive status set with clear exit criteria, for example:
Standardize triage with a checklist (validate, dedupe, categorize, assign owner) and add approval gates for high-risk areas like security/compliance. Add SLA reminders so queues don’t stagnate.
Combine demand signals with structured impact so popularity doesn’t override strategy:
Require a decision rationale field (“why planned/declined” and “what would change the decision”).
A practical MVP focuses on the shortest path from submission to decision:
Pilot with a few accounts and measure adoption (portal submission rate, time to first update, duplicate rate), then iterate based on real usage.