Apr 29, 2025·8 min
How to Build a Web App for Product Pricing Experiments
Plan, design, and ship a web app to manage pricing experiments: variants, traffic splits, assignment, metrics, dashboards, and safe rollout guardrails.
Plan, design, and ship a web app to manage pricing experiments: variants, traffic splits, assignment, metrics, dashboards, and safe rollout guardrails.
Pricing experiments are structured tests where you show different prices (or packaging) to different groups of customers and measure what changes—conversion, upgrades, churn, revenue per visitor, and more. It’s the pricing version of an A/B test, but with extra risk: a mistake can confuse customers, create support tickets, or even violate internal policies.
A pricing experiment manager is the system that keeps these tests controlled, observable, and reversible.
Control: Teams need a single place to define what’s being tested, where, and for whom. “We changed the price” is not a plan—an experiment needs a clear hypothesis, dates, targeting rules, and a kill switch.
Tracking: Without consistent identifiers (experiment key, variant key, assignment timestamp), analysis becomes guesswork. The manager should ensure every exposure and purchase can be attributed to the right test.
Consistency: Customers shouldn’t see one price on the pricing page and a different one at checkout. The manager should coordinate how variants are applied across surfaces so the experience is coherent.
Safety: Pricing mistakes are expensive. You need guardrails like traffic limits, eligibility rules (e.g., new customers only), approval steps, and auditability.
This post focuses on an internal web app that manages experiments: creating them, assigning variants, collecting events, and reporting results.
It is not a full pricing engine (tax calculation, invoicing, multi-currency catalogs, proration, etc.). Instead, it’s the control panel and tracking layer that makes price testing safe enough to run regularly.
A pricing experiment manager is only useful if it’s clear what it will—and will not—do. Tight scope keeps the product easy to operate and safer to ship, especially when real revenue is on the line.
At a minimum, your web app should let a non-technical operator run an experiment end to end:
If you build nothing else, build these well—with clear defaults and guardrails.
Decide early which experiment formats you’ll support so the UI, data model, and assignment logic stay consistent:
Be explicit to prevent “scope creep” that turns an experiment tool into a fragile business-critical system:
Define success in operational terms, not just statistical ones:
A pricing experiment app lives or dies by its data model. If you can’t reliably answer “what price did this customer see, and when?”, your metrics will be noisy and your team will lose trust.
Start with a small set of core objects that map to how pricing actually works in your product:
Use stable identifiers across systems (product_id, plan_id, customer_id). Avoid “pretty names” as keys—they change.
Time fields are just as important:
Also consider effective_from / effective_to on Price records so you can reconstruct pricing at any point in time.
Define relationships explicitly:
Practically, this means an Event should carry (or be joinable to) customer_id, experiment_id, and variant_id. If you only store customer_id and “look up the assignment later,” you risk wrong joins when assignments change.
Pricing experiments need an audit-friendly history. Make key records append-only:
This approach keeps your reporting consistent and makes governance features like audit logs straightforward later on.
A pricing experiment manager needs a clear lifecycle so everyone understands what’s editable, what’s locked, and what happens to customers when the experiment changes state.
Draft → Scheduled → Running → Stopped → Analyzed → Archived
To reduce risky launches, enforce required fields as the experiment progresses:
For pricing, add optional gates for Finance and Legal/Compliance. Only approvers can move Scheduled → Running. If you support overrides (e.g., urgent rollback), record who overrode, why, and when in an audit log.
When an experiment is Stopped, define two explicit behaviors:
Make this a required choice at stop time so the team can’t stop an experiment without deciding customer impact.
Getting assignment right is the difference between a trustworthy pricing test and confusing noise. Your app should make it easy to define who gets a price, and ensure they keep seeing it consistently.
A customer should see the same variant across sessions, devices (when possible), and refreshes. That means assignment must be deterministic: given the same assignment key and experiment, the result is always the same.
Common approaches:
(experiment_id + assignment_key) and map it to a variant.Many teams use hash-based assignment by default and store assignments only when required (for support cases or governance).
Your app should support multiple keys, because pricing can be user-level or account-level:
user_id after signup/login.That upgrade path matters: if someone browses anonymously and later creates an account, you should decide whether to keep their original variant (continuity) or reassign them (cleaner identity rules). Make it a clear, explicit setting.
Support flexible allocation:
When ramping, keep assignments sticky: increasing traffic should add new users to the experiment, not reshuffle existing ones.
Concurrent tests can collide. Build guardrails for:
A clear “Assignment preview” screen (given a sample user/account) helps non-technical teams verify the rules before launch.
Pricing experiments fail most often at the integration layer—not because the experiment logic is wrong, but because the product shows one price and charges another. Your web app should make “what the price is” and “how the product uses it” very explicit.
Treat price definition as the source of truth (the variant’s price rules, effective dates, currency, tax handling, etc.). Treat price delivery as a simple mechanism to fetch the chosen variant’s price via an API endpoint or SDK.
This separation keeps the experiment management tool clean: non-technical teams edit definitions, while engineers integrate a stable delivery contract like GET /pricing?sku=....
There are two common patterns:
A practical approach is “display on client, verify and compute on server,” using the same experiment assignment.
Variants must follow the same rules for:
Store these rules alongside the price so every variant is comparable and finance-friendly.
If the experiment service is slow or down, your product should return a safe default price (usually the current baseline). Define timeouts, caching, and a clear “fail closed” policy so checkout doesn’t break—and log fallbacks so you can quantify impact.
Pricing experiments live or die by measurement. Your web app should make it hard to “ship and hope” by requiring clear success metrics, clean events, and a consistent attribution approach before an experiment can launch.
Start with one or two metrics you will use to decide the winner. Common pricing choices:
A helpful rule: if teams argue about the result after the test, you probably didn’t define the decision metric clearly enough.
Guardrails catch damage that a higher price might cause even if short-term revenue looks good:
Your app can enforce guardrails by requiring thresholds (e.g., “refund rate must not increase by more than 0.3%”) and by highlighting breaches on the experiment page.
At minimum, your tracking must include stable identifiers for the experiment and variant on every relevant event.
{
"event": "purchase_completed",
"timestamp": "2025-01-15T12:34:56Z",
"user_id": "u_123",
"experiment_id": "exp_earlybird_2025_01",
"variant_id": "v_price_29",
"currency": "USD",
"amount": 29.00
}
Make these properties required at ingestion time, not “best effort.” If an event arrives without experiment_id/variant_id, route it to an “unattributed” bucket and flag data quality issues.
Pricing outcomes are often delayed (renewals, upgrades, churn). Define:
This keeps teams aligned on when a result is trustworthy—and prevents premature calls.
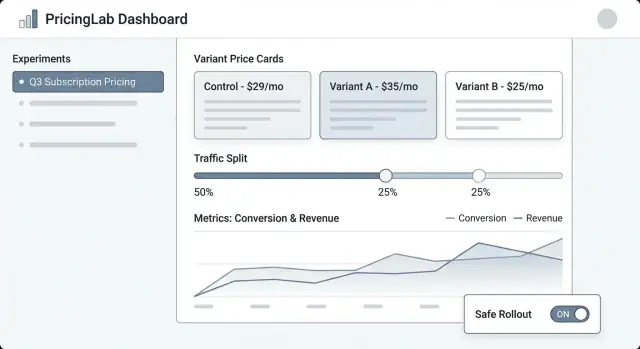
A pricing experiment tool only works if product managers, marketers, and finance can run it without needing an engineer for every click. The UI should answer three questions fast: What’s running? What will change for customers? What happened and why?
Experiment list should feel like an operations dashboard. Show: name, status (Draft/Scheduled/Running/Paused/Ended), start/end dates, traffic split, primary metric, and owner. Add a visible “last updated by” and timestamp so people trust what they’re seeing.
Experiment detail is the home base. Put a compact summary at the top (status, dates, audience, split, primary metric). Below that, use tabs like Variants, Targeting, Metrics, Change log, and Results.
Variant editor needs to be straightforward and opinionated. Each variant row should include price (or price rule), currency, billing period, and a plain-English description (“Annual plan: $120 → $108”). Keep it hard to accidentally edit a live variant by requiring confirmation.
Results view should lead with the decision, not just charts: “Variant B increased checkout conversion by 2.1% (95% CI …).” Then provide supporting drill-downs and filters.
Use consistent status badges and show a timeline of key dates. Display the traffic split as both a percentage and a small bar. Include a “Who changed what” panel (or tab) that lists edits to variants, targeting, and metrics.
Before allowing Start, require: at least one primary metric selected, at least two variants with valid prices, a defined ramp plan (optional but recommended), and a rollback plan or fallback price. If something’s missing, show actionable errors (“Add a primary metric to enable results”).
Provide safe, prominent actions: Pause, Stop, Ramp up (e.g., 10% → 25% → 50%), and Duplicate (copy settings into a new Draft). For risky actions, use confirmations that summarize impact (“Pausing freezes assignments and stops exposure”).
If you want to validate workflows (Draft → Scheduled → Running) before investing in a full build, a vibe-coding platform like Koder.ai can help you spin up an internal web app from a chat-based spec—then iterate quickly with role-based screens, audit logs, and simple dashboards. It’s especially useful for early prototypes where you want a working React UI and a Go/PostgreSQL backend you can later export and harden.
A pricing experiment dashboard should answer one question quickly: “Should we keep this price, roll it back, or keep learning?” The best reporting isn’t the fanciest—it’s the easiest to trust and explain.
Start with a small set of trend charts that update automatically:
Under the charts, include a variant comparison table: Variant name, traffic share, visitors, purchases, conversion rate, revenue per visitor, and the delta vs control.
For confidence indicators, avoid academic wording. Use plain labels like:
A short tooltip can explain that confidence increases with sample size and time.
Pricing often “wins” overall but fails for key groups. Make segment tabs easy to switch:
Keep the same metrics everywhere so comparisons feel consistent.
Add lightweight alerts directly on the dashboard:
When an alert appears, show the suspected window and a link to the raw event status.
Make reporting portable: a CSV download for the current view (including segments) and a shareable internal link to the experiment report. If helpful, link a short explainer like /blog/metric-guide so stakeholders understand what they’re seeing without scheduling another meeting.
Pricing experiments touch revenue, customer trust, and often regulated reporting. A simple permission model and a clear audit trail reduce accidental launches, quiet “who changed this?” arguments, and help you ship faster with fewer reversals.
Keep roles easy to explain and hard to misuse:
If you have multiple products or regions, scope roles by workspace (e.g., “EU Pricing”) so an editor in one area can’t impact another.
Your app should log every change with who, what, when, ideally with “before/after” diffs. Minimum events to capture:
Make logs searchable and exportable (CSV/JSON), and link them directly from the experiment page so reviewers don’t hunt. A dedicated /audit-log view helps compliance teams.
Treat customer identifiers and revenue as sensitive by default:
Add lightweight notes on each experiment: the hypothesis, expected impact, approval rationale, and a “why we stopped” summary. Six months later, these notes prevent rerunning failed ideas—and make reporting far more credible.
Pricing experiments fail in subtle ways: a 50/50 split drifts to 62/38, one cohort sees the wrong currency, or events never make it into reports. Before you let real customers see a new price, treat the experiment system like a payment feature—validate behavior, data, and failure modes.
Start with deterministic test cases so you can prove the assignment logic is stable across services and releases. Use fixed inputs (customer IDs, experiment keys, salt) and assert the same variant is returned every time.
customer_id=123, experiment=pro_annual_price_v2 -> variant=B
customer_id=124, experiment=pro_annual_price_v2 -> variant=A
Then test distribution at scale: generate, say, 1M synthetic customer IDs and check that the observed split stays within a tight tolerance (e.g., 50% ± 0.5%). Also verify edge cases like traffic caps (only 10% enrolled) and “holdout” groups.
Don’t stop at “the event fired.” Add an automated flow that creates a test assignment, triggers a purchase or checkout event, and verifies:
Run this in staging and in production with a test experiment limited to internal users.
Give QA and PMs a simple “preview” tool: enter a customer ID (or session ID) and see the assigned variant and the exact price that would render. This catches mismatched rounding, currency, tax display, and “wrong plan” issues before launch.
Consider a safe internal route like /experiments/preview that never alters real assignments.
Practice the ugly scenarios:
If you can’t confidently answer “what happens when X breaks?”, you’re not ready to ship.
Launching a pricing experiment manager is less about “shipping a screen” and more about ensuring you can control blast radius, observe behavior quickly, and recover safely.
Start with a launch path that matches your confidence and your product constraints:
Treat monitoring as a release requirement, not a “nice to have.” Set alerts for:
Create a written runbook for operations and on-call:
After the core workflow is stable, prioritize upgrades that unlock better decisions: targeting rules (geo, plan, customer type), stronger stats and guardrails, and integrations (data warehouse, billing, CRM). If you offer tiers or packaging, consider exposing experiment capabilities on /pricing so teams understand what’s supported.
It’s an internal control panel and tracking layer for pricing tests. It helps teams define experiments (hypothesis, audience, variants), serve a consistent price across surfaces, collect attribution-ready events, and safely start/pause/stop with auditability.
It’s intentionally not a full billing or tax engine; it orchestrates experiments around your existing pricing/billing stack.
A practical MVP includes:
If these are reliable, you can iterate on richer targeting and reporting later.
Model the core objects that let you answer: “What price did this customer see, and when?” Typically:
Avoid mutable edits to key history: version prices and append new assignment records instead of overwriting.
Define a lifecycle such as Draft → Scheduled → Running → Stopped → Analyzed → Archived.
Lock risky fields once Running (variants, targeting, split) and require validation before moving states (metrics selected, tracking confirmed, rollback plan). This prevents “mid-test edits” that make results untrustworthy and create customer inconsistency.
Use sticky assignment so the same customer gets the same variant across sessions/devices when possible.
Common patterns:
(experiment_id + assignment_key) into a variant bucketMany teams do hash-first and store assignments only when needed for governance or support workflows.
Pick a key that matches how customers experience pricing:
If you start anonymous, decide an explicit “identity upgrade” rule at signup/login (keep the original variant for continuity vs reassign for cleanliness).
Treat “Stop” as two separate decisions:
Make the serving policy a required choice when stopping so teams can’t stop a test without acknowledging customer impact.
Ensure the same variant drives both display and charging:
Also define a safe fallback if the service is slow/down (usually baseline pricing) and log every fallback for visibility.
Require a small, consistent event schema where every relevant event includes experiment_id and variant_id.
You’ll typically define:
If an event arrives without experiment/variant fields, route it to an “unattributed” bucket and flag data quality issues.
Use a simple role model and a complete audit trail:
This reduces accidental launches and makes finance/compliance reviews—and later retrospectives—much easier.