Oct 08, 2025·8 min
Distributed SQL Databases: When to Use Spanner, Cockroach, Yugabyte
Learn what distributed SQL is, how Spanner, CockroachDB, and YugabyteDB differ, and which real-world use cases justify multi-region, strongly consistent SQL.
Learn what distributed SQL is, how Spanner, CockroachDB, and YugabyteDB differ, and which real-world use cases justify multi-region, strongly consistent SQL.
“Distributed SQL” is a database that looks and feels like a traditional relational database—tables, rows, joins, transactions, and SQL—but it’s designed to run as a cluster across many machines (and often across regions) while still behaving like one logical database.
That combination matters because it tries to deliver three things at once:
A classic RDBMS (like PostgreSQL or MySQL) is typically easiest to operate when everything lives on one primary node. You can scale reads with replicas, but scaling writes and surviving regional outages usually requires additional architecture (sharding, manual failover, and careful application logic).
Many NoSQL systems took the opposite approach: scale and high availability first, sometimes by relaxing consistency guarantees or offering simpler query models.
Distributed SQL aims for a middle path: keep the relational model and ACID transactions, but distribute data automatically to handle growth and failures.
Distributed SQL databases are built for problems like:
This is why products like Google Spanner, CockroachDB, and YugabyteDB are often evaluated for multi-region deployment and always-on services.
Distributed SQL is not automatically “better.” You’re accepting more moving parts and different performance realities (network hops, consensus, cross-region latency) in exchange for resilience and scale.
If your workload fits on a single well-managed database with a straightforward replication setup, a conventional RDBMS can be simpler and cheaper. Distributed SQL earns its keep when the alternative is custom sharding, complex failover, or business requirements that demand multi-region consistency and uptime.
Distributed SQL aims to feel like a familiar SQL database while storing data across multiple machines (and often multiple regions). The hard part is coordinating many computers so they behave like one dependable system.
Each piece of data is typically copied to several nodes (replication). If one node fails, another copy can still serve reads and accept writes.
To prevent replicas from drifting apart, Distributed SQL systems use consensus protocols—most commonly Raft (CockroachDB, YugabyteDB) or Paxos (Spanner). At a high level, consensus means:
That “majority vote” is what gives you strong consistency: once a transaction commits, other clients won’t see an older version of the data.
No single machine can hold everything, so tables are split into smaller chunks called shards/partitions (Spanner calls them splits; CockroachDB calls them ranges; YugabyteDB calls them tablets).
Each partition is replicated (using consensus) and placed on specific nodes. Placement isn’t random: you can influence it through policies (for example, keep EU customer records in EU regions, or keep hot partitions on faster nodes). Good placement reduces cross-network trips and keeps performance more predictable.
With a single-node database, a transaction can often commit with local disk work. In Distributed SQL, a transaction may touch multiple partitions—potentially on different nodes.
Committing safely usually requires extra coordination:
Those steps introduce network round trips, which is why distributed transactions typically add latency—especially when data spans regions.
When deployments span regions, systems try to keep operations “close” to users:
This is the core multi-region balancing act: you can optimize for local responsiveness, but strong consistency across long distances will still pay a network cost.
Before you reach for distributed SQL, sanity-check your baseline needs. If you have a single primary region, predictable load, and a small ops footprint, a conventional relational database (or a managed Postgres/MySQL) is usually the simplest way to ship features quickly. You can often stretch a single-region setup a long way with read replicas, caching, and careful schema/index work.
Distributed SQL is worth serious consideration when one (or more) of these become true:
Distributed systems add complexity and cost. Be cautious if:
If you can answer “yes” to two or more, distributed SQL is likely worth evaluating:
Distributed SQL sounds like “get everything at once,” but real systems force choices—especially when regions can’t talk to each other reliably.
Think of a network partition as “the link between regions is flaky or down.” In that moment, a database can prioritize:
Distributed SQL systems are typically built to favor consistency for transactions. That’s often what teams want—until a partition means certain operations must wait or fail.
Strong consistency means once a transaction commits, any subsequent read returns that committed value—no “it worked in one region but not another.” This is critical for:
If your product promise is “when we confirm it, it’s real,” strong consistency is a feature, not a luxury.
Two practical behaviors matter:
Strong consistency across regions usually requires consensus (multiple replicas must agree before commit). If replicas span continents, the speed of light becomes a product constraint: every cross-region write can add tens to hundreds of milliseconds.
The tradeoff is simple: more geographic safety and correctness often means higher write latency unless you carefully choose where data lives and where transactions are allowed to commit.
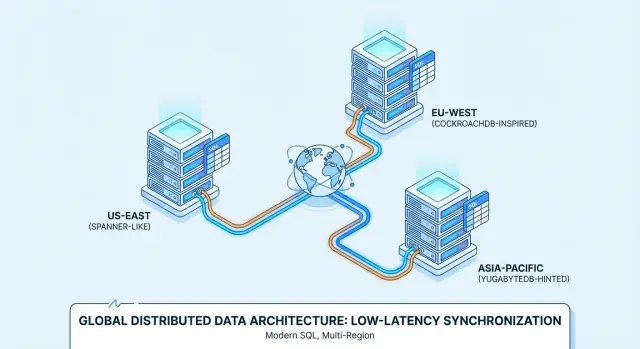
Google Spanner is a distributed SQL database offered primarily as a managed service on Google Cloud. It’s designed for multi-region deployments where you want a single logical database with data replicated across nodes and regions. Spanner supports two SQL dialect options—GoogleSQL (its native dialect) and a PostgreSQL-compatible dialect—so portability varies depending on which one you choose and which features your application relies on.
CockroachDB is a distributed SQL database that aims to feel familiar to teams used to PostgreSQL. It uses the PostgreSQL wire protocol and supports a large subset of PostgreSQL-style SQL, but it’s not a byte-for-byte replacement for Postgres (some extensions and edge-case behaviors differ). You can run it as a managed service (CockroachDB Cloud) or self-host it in your own infrastructure.
YugabyteDB is a distributed database with a PostgreSQL-compatible SQL API (YSQL) and an additional Cassandra-compatible API (YCQL). Like CockroachDB, it’s often evaluated by teams that want Postgres-like development ergonomics while scaling out across nodes and regions. It’s available both self-hosted and as a managed offering (YugabyteDB Managed), with common deployments spanning single-region HA through multi-region setups.
Managed services typically reduce operational work (upgrades, backups, monitoring integrations), while self-hosting gives more control over networking, instance types, and where data physically runs. Spanner is most commonly consumed as managed on GCP; CockroachDB and YugabyteDB are commonly seen in both managed and self-hosted models, including multi-cloud and on-prem options.
All three speak “SQL,” but day-to-day compatibility depends on dialect choice (Spanner), Postgres feature coverage (CockroachDB/YugabyteDB), and whether your app depends on specific Postgres extensions, functions, or transaction semantics.
Planning time here pays off: test your queries, migrations, and ORM behavior early rather than assuming drop-in equivalence.
A classic fit for distributed SQL is a B2B SaaS product with customers across North America, Europe, and APAC—think support tools, HR platforms, analytics dashboards, or marketplaces.
The business requirement is straightforward: users want “local app” responsiveness, while the company wants one logical database that’s always available.
Many SaaS teams end up with a mix of requirements:
Distributed SQL can model this cleanly with per-tenant locality: place each tenant’s primary data in a specific region (or set of regions) while keeping the schema and query model consistent across the whole system. That lets you avoid the “one database per region” sprawl while still meeting residency needs.
To keep the app fast, you typically aim for:
This matters because cross-region round trips dominate user-perceived latency. Even with strong consistency, good locality design ensures most requests don’t pay intercontinental network costs.
The technical wins only matter if operations stay manageable. For global SaaS, plan for:
Done well, distributed SQL gives you a single product experience that still feels local—without splitting your engineering team into “the EU stack” and “the APAC stack.”
Financial systems are where “eventually consistent” can turn into real money lost. If a customer places an order, a payment is authorized, and a balance is updated, those steps need to agree on a single truth—right now.
Strong consistency matters because it prevents two different regions (or two different services) from each making a “reasonable” decision that results in an incorrect ledger.
In a typical workflow—create order → reserve funds → capture payment → update balance/ledger—you want guarantees like:
Distributed SQL is a fit here because it gives you ACID transactions and constraints across nodes (and often across regions), so your ledger invariants hold even during failures.
Most payment integrations are retry-heavy: timeouts, webhook retries, and job reprocessing are normal. The database should help you make retries safe.
A practical approach is to pair application-level idempotency keys with database-enforced uniqueness:
idempotency_key per customer/payment attempt.(account_id, idempotency_key).That way, the second attempt becomes a harmless no-op rather than a double charge.
Sales events and payroll runs can create sudden write bursts (authorizations, captures, transfers). With distributed SQL, you can scale out by adding nodes to increase write throughput while keeping the same consistency model.
The key is planning for hot keys (e.g., one merchant account receiving all traffic) and using schema patterns that spread load.
Financial workflows typically require immutable audit trails, traceability (who/what/when), and predictable retention policies. Even without naming specific regulations, assume you’ll need: append-only ledger entries, time-stamped records, controlled access, and retention/archival rules that don’t compromise auditability.
Inventory and reservations look simple until you have multiple regions serving the same scarce resource: the last concert seat, a “limited drop” product, or a hotel room for a specific night.
The hard part isn’t reading availability—it’s preventing two people from successfully claiming the same item at nearly the same time.
In a multi-region setup without strong consistency, each region can temporarily believe it has inventory available based on slightly outdated data. If two users check out in different regions during that window, both transactions may be accepted locally and later conflict during reconciliation.
That’s how cross-region oversell happens: not because the system is “wrong,” but because it allowed divergent truths for a moment.
Distributed SQL databases are often chosen here because they can enforce a single, authoritative outcome for write-heavy allocation—so “the last seat” really is allocated once, even if requests arrive from different continents.
Hold + confirm: Place a temporary hold (a reservation record) in a transaction, then confirm payment in a second step.
Expirations: Holds should expire automatically (e.g., after 10 minutes) to prevent inventory from being stuck if a user abandons checkout.
Transactional outbox: When a reservation is confirmed, write an “event to send” row in the same transaction, then deliver it asynchronously to email, fulfillment, analytics, or a message bus—without risking a “booked but no confirmation sent” gap.
The takeaway: if your business can’t tolerate double-allocation across regions, strong transactional guarantees become a product feature, not a technical nice-to-have.
High availability (HA) is a good fit for Distributed SQL when downtime is expensive, unpredictable outages are unacceptable, and you need maintenance to be boring.
The goal isn’t “never fail”—it’s meeting clear SLOs (for example, 99.9% or 99.99% uptime) even when nodes die, zones go dark, or you’re applying upgrades.
Start by translating “always-on” into measurable expectations: maximum monthly downtime, recovery time objective (RTO), and recovery point objective (RPO).
Distributed SQL systems can keep serving reads/writes through many common failures, but only if your topology matches your SLO and your app handles transient errors (retries, idempotency) cleanly.
Planned maintenance matters too. Rolling upgrades and instance replacements are easier when the database can move leadership/replicas away from impacted nodes without taking the whole cluster offline.
Multi-zone deployments protect you from a single AZ/zone outage and many hardware failures, usually with lower latency and cost. They’re often enough if your compliance and user base are mostly in one region.
Multi-region deployments protect you from a full regional outage and support regional failover. The tradeoff is higher write latency for strongly consistent transactions that span regions, plus more complex capacity planning.
Don’t assume failover is instant or invisible. Define what “failover” means for your service: brief error spikes? read-only periods? a few seconds of elevated latency?
Run “game days” to prove it:
Even with synchronous replication, keep backups and rehearse restore. Backups protect against operator mistakes (bad migrations, accidental deletes), application bugs, and corruption that can replicate.
Validate point-in-time recovery (if available), restore speed, and the ability to recover to a clean environment without touching production.
Data residency requirements show up when regulations, contracts, or internal policies say that certain records must be stored (and sometimes processed) within a specific country or region.
This can apply to personal data, healthcare information, payment data, government workloads, or “customer-owned” datasets where the client contract dictates where their data lives.
Distributed SQL is often considered here because it can keep a single logical database while physically placing data in different regions—without forcing you to run a completely separate application stack per geography.
If a regulator or customer requires “data stays in region,” it’s not enough to just have low-latency replicas nearby. You may need to guarantee that:
This pushes teams toward architectures where location is a first-class concern, not an afterthought.
A common pattern in SaaS is per-tenant (per-customer) data placement. For example: EU customers’ rows or partitions are pinned to EU regions, US customers to US regions.
At a high level, you typically combine:
The goal is to make it hard to accidentally violate residency through operational access, backup restores, or cross-region replication.
Residency and compliance obligations differ widely by country, industry, and contract. They also change over time.
Treat database topology as part of your compliance program, and validate assumptions with qualified legal counsel (and, where relevant, your auditors).
Residency-friendly topologies can complicate “global views” of the business. If customer data is intentionally kept in separate regions, analytics and reporting may:
In practice, many teams separate operational workloads (strongly consistent, residency-aware) from analytics (region-scoped warehouses or carefully governed aggregate datasets) to keep compliance manageable without slowing everyday product reporting.
Distributed SQL can save you from painful outages and regional limitations, but it rarely saves money by default. Planning upfront helps you avoid paying for “insurance” you don’t actually need.
Most budgets break down into four buckets:
Distributed SQL systems add coordination—especially for strongly consistent writes that must be confirmed by a quorum.
A practical way to estimate impact:
This doesn’t mean “don’t do it,” but it does mean you should design journeys to reduce sequential writes (batching, idempotent retries, fewer chatty transactions).
If your users are mostly in one region, a single-region Postgres with read replicas, great backups, and a tested failover plan can be cheaper and simpler—and fast.
Distributed SQL earns its cost when you truly need multi-region writes, strict RPO/RTO, or residency-aware placement.
Treat the spend as a trade:
If the avoided loss (downtime + churn + compliance risk) is bigger than the ongoing premium, the multi-region design is justified. If not, start simpler—and keep a path to evolve later.
Adopting distributed SQL is less about “lifting and shifting” a database and more about proving that your specific workload behaves well when data and consensus are spread across nodes (and possibly regions). A lightweight plan helps you avoid surprises.
Pick one workload that represents real pain: e.g., checkout/booking, account provisioning, or ledger posting.
Define success metrics up front:
If you want to move faster in the PoC stage, it can help to build a small “realistic” app surface (API + UI) rather than only synthetic benchmarks. For example, teams sometimes use Koder.ai to spin up a lightweight React + Go + PostgreSQL baseline app via chat, then swap the database layer to CockroachDB/YugabyteDB (or connect to Spanner) to test transaction patterns, retries, and failure behavior end-to-end. The point isn’t the starter stack—it’s shortening the loop from “idea” to “workload you can measure.”
Monitoring and runbooks matter as much as SQL:
Start with a PoC sprint, then budget time for a production readiness review and a gradual cutover (dual writes or shadow reads when possible).
If you need help scoping costs or tiers, see /pricing. For more practical walkthroughs and migration patterns, browse /blog.
If you do end up documenting your PoC findings, architecture tradeoffs, or migration lessons learned, consider sharing them with your team (and publicly if possible): platforms like Koder.ai even offer ways to earn credits for creating educational content or referring other builders, which can offset experimentation costs while you evaluate options.
A distributed SQL database provides a relational, SQL interface (tables, joins, constraints, transactions) but runs as a cluster across multiple machines—often across regions—while acting like one logical database.
In practice, it’s trying to combine:
A single-node or primary/replica RDBMS is often simpler, cheaper, and faster for single-region OLTP.
Distributed SQL becomes compelling when the alternative is:
Most systems rely on two core ideas:
This is what enables strong consistency even when nodes fail—but it adds network coordination overhead.
They split tables into smaller chunks (often called partitions/shards, or vendor-specific names like ranges/tablets/splits). Each partition:
You usually influence placement with policies so “hot” data and primary writers stay close, reducing cross-network trips.
Distributed transactions often touch multiple partitions, potentially on different nodes (or different regions). A safe commit may require:
Those extra network round trips are the main reason write latency can increase—especially when consensus spans regions.
Consider distributed SQL when two or more are true:
If your workload fits in one region with replicas/caching, a conventional RDBMS is often the better default.
Strong consistency means once a transaction commits, reads won’t see older data.
In product terms, it helps prevent:
The tradeoff is that during network partitions, a strongly consistent system may block or fail some operations rather than accept divergent truths.
Rely on database constraints + transactions:
idempotency_key (or similar) per request/attempt(account_id, idempotency_key)This turns retries into no-ops instead of duplicates—critical for payments, provisioning, and background job reprocessing.
A practical separation:
Before choosing, test your actual ORM/migrations and any Postgres extensions you rely on—don’t assume drop-in replacement.
Start with a focused PoC around one critical workflow (checkout, booking, ledger posting). Validate:
If you need help scoping cost/tiers, see /pricing. For related implementation notes, browse /blog.