Nov 13, 2025·8 min
How NoSQL Databases Emerged to Fix Scaling and Flexibility
Learn why NoSQL databases emerged: the web’s scale, flexible data needs, and the limits of relational systems—plus key models and tradeoffs.
Learn why NoSQL databases emerged: the web’s scale, flexible data needs, and the limits of relational systems—plus key models and tradeoffs.
NoSQL emerged when many teams ran into a mismatch between what their applications needed and what traditional relational databases (SQL databases) were optimized for. SQL didn’t “fail”—but at web scale, some teams began prioritizing different goals.
First, scale. Popular consumer apps started seeing traffic spikes, constant writes, and massive volumes of user-generated data. For these workloads, “just buy a bigger server” became expensive, slow to implement, and ultimately limited by the biggest machine you could reasonably operate.
Second, change. Product features evolved quickly, and the data behind them didn’t always fit neatly into a fixed set of tables. Adding new attributes to user profiles, storing multiple event types, or ingesting semi-structured JSON from different sources often meant repeated schema migrations and cross-team coordination.
Relational databases are excellent at enforcing structure and enabling complex queries across normalized tables. But some high-scale workloads made those strengths harder to capitalize on:
The result: some teams sought systems that traded certain guarantees and capabilities for simpler scaling and faster iteration.
NoSQL isn’t a single database or design. It’s an umbrella term for systems that emphasize some mix of:
NoSQL was never meant to be a universal replacement for SQL. It’s a set of tradeoffs: you may gain scalability or schema flexibility, but you might accept weaker consistency guarantees, fewer ad-hoc query options, or more responsibility in application-level data modeling.
For years, the standard answer to a slow database was straightforward: buy a bigger server. Add more CPU, more RAM, faster disks, and keep the same schema and operational model. This “scale up” approach worked—until it stopped being practical.
High-end machines get expensive quickly, and the price/performance curve eventually becomes unfriendly. Upgrades often require large, infrequent budget approvals and maintenance windows to move data and cut over. Even if you can afford bigger hardware, a single server still has a ceiling: one memory bus, one storage subsystem, and one primary node absorbing the write load.
As products grew, databases faced constant read/write pressure rather than occasional peaks. Traffic became truly 24/7, and certain features created uneven access patterns. A small number of heavily accessed rows or partitions could dominate traffic, producing hot tables (or hot keys) that dragged down everything else.
Operational bottlenecks became common:
Many applications also needed to be available across regions, not just fast in one data center. A single “main” database in one location increases latency for distant users and makes outages more catastrophic. The question shifted from “How do we buy a larger box?” to “How do we run the database across many machines and locations?”
Relational databases shine when your data shape is stable. But many modern products don’t sit still. A table schema is intentionally strict: every row follows the same set of columns, types, and constraints. That predictability is valuable—until you’re iterating quickly.
In practice, frequent schema changes can be expensive. A seemingly small update may require migrations, backfills, index updates, coordinated deployment timing, and compatibility planning so older code paths don’t break. On large tables, even adding a column or changing a type can become a time-consuming operation with real operational risk.
That friction pushes teams to delay changes, accumulate workarounds, or store messy blobs in text fields—none of which is ideal for rapid iteration.
A lot of application data is naturally semi-structured: nested objects, optional fields, and attributes that evolve over time.
For example, a “user profile” might start with name and email, then grow to include preferences, linked accounts, shipping addresses, notification settings, and experiment flags. Not every user has every field, and new fields arrive gradually. Document-style models can store nested and uneven shapes directly without forcing every record into the same rigid template.
Flexibility also reduces the need for complex joins for certain data shapes. When a single screen needs a composed object (an order with items, shipping info, and status history), relational designs may require multiple tables and joins—plus ORM layers that attempt to hide that complexity but often add friction.
NoSQL options made it easier to model data closer to how the application reads and writes it, helping teams ship changes faster.
Web applications didn’t just get bigger—they changed shape. Instead of serving a predictable number of internal users during business hours, products began serving millions of global users around the clock, with sudden spikes driven by launches, news, or social sharing.
Always-on expectations raised the bar: downtime became a headline, not an inconvenience. At the same time, teams were asked to ship features faster—often before anyone knew what the “final” data model should look like.
To keep up, scaling up a single database server stopped being enough. The more traffic you handled, the more you wanted capacity you could add incrementally—add another node, spread load, isolate failures.
This pushed architecture toward fleets of machines rather than one “main” box, and changed what teams expected from databases: not just correctness, but predictable performance under high concurrency and graceful behavior when parts of the system are unhealthy.
Before “NoSQL” was a mainstream category, many teams were already bending systems toward web-scale realities:
These techniques worked, but they shifted complexity into application code: cache invalidation, keeping duplicated data consistent, and building pipelines for “ready-to-serve” records.
As these patterns became standard, databases had to support distributing data across machines, tolerating partial failures, handling high write volumes, and representing evolving data cleanly. NoSQL databases emerged in part to make common web-scale strategies first-class rather than constant workarounds.
When data lives on one machine, the rules feel simple: there’s a single source of truth, and every read or write can be checked immediately. When you spread data across servers (often across regions), a new reality appears: messages can be delayed, nodes can fail, and parts of the system can temporarily stop communicating.
A distributed database must decide what to do when it can’t safely coordinate. Should it keep serving requests so the app stays “up,” even if results might be slightly out of date? Or should it refuse some operations until it can confirm replicas agree, which can look like downtime to users?
These situations occur during router failures, overloaded networks, rolling deployments, firewall misconfigurations, and cross-region replication delays.
The CAP theorem is a shorthand for three properties you’d like at the same time:
The key point isn’t “pick two forever.” It’s: when a network partition happens, you must choose between consistency and availability. In web-scale systems, partitions are treated as inevitable—especially in multi-region setups.
Imagine your app runs in two regions for resilience. A fiber cut or routing issue prevents synchronization.
Different NoSQL systems (and even different configurations of the same system) make different compromises depending on what matters most: user experience during failures, correctness guarantees, operational simplicity, or recovery behavior.
Scaling out (horizontal scaling) means increasing capacity by adding more machines (nodes) rather than buying a single bigger server. For many teams, this was a financial and operational shift: commodity nodes could be added incrementally, failures were expected, and growth didn’t require risky “big box” migrations.
To make many nodes useful, NoSQL systems leaned on sharding (also called partitioning). Instead of one database handling every request, data is split into partitions and distributed across nodes.
A simple example is partitioning by a key (like user_id):
Reads and writes spread out, reducing hotspots and letting throughput grow as you add nodes. The partition key becomes a design decision: pick a key aligned with query patterns, or you can accidentally funnel too much traffic into one shard.
Replication means keeping multiple copies of the same data on different nodes. This improves:
Replication also enables spreading data across racks or regions to survive localized outages.
Sharding and replication introduce ongoing operational work. As data grows or nodes change, the system must rebalance—moving partitions while staying online. If handled poorly, rebalancing can cause latency spikes, uneven load, or temporary capacity shortages.
This is a core tradeoff: cheaper scaling via more nodes, in exchange for more complex distribution, monitoring, and failure handling.
Once data is distributed, a database must define what “correct” means when updates happen concurrently, networks slow down, or nodes can’t communicate.
With strong consistency, once a write is acknowledged, every reader should see it immediately. This matches the “single source of truth” experience many people associate with relational databases.
The challenge is coordination: strict guarantees across nodes require multiple messages, waiting for enough responses, and handling failures mid-flight. The farther apart nodes are (or the busier they are), the more latency you may introduce—sometimes on every write.
Eventual consistency relaxes that guarantee: after a write, different nodes may briefly return different answers, but the system converges over time.
Examples:
For many user experiences, that temporary mismatch is acceptable if the system remains fast and available.
If two replicas accept updates at nearly the same time, the database needs a merge rule.
Common approaches include:
Strong consistency is usually worth the cost for money movement, inventory limits, unique usernames, permissions, and any workflow where “two truths for a moment” can cause real harm.
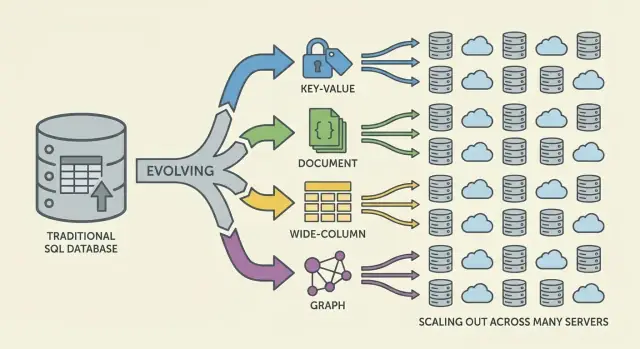
NoSQL is a set of models that make different tradeoffs around scale, latency, and data shape. Understanding the “family” helps you predict what will be fast, what will be painful, and why.
Key-value databases store a value behind a unique key, like a giant distributed hashmap. Because the access pattern is typically “get by key” / “set by key,” they can be extremely fast and horizontally scalable.
They’re great when you already know the lookup key (sessions, caching, feature flags), but they’re limited for ad-hoc querying: filtering across multiple fields is often not the point of the system.
Document databases store JSON-like documents (often grouped into collections). Each document can have a slightly different structure, which supports schema flexibility as products evolve.
They optimize for reading and writing whole documents and querying by fields inside them—without forcing rigid tables. The tradeoff: modeling relationships can get tricky, and joins (if supported) can be more limited than in relational systems.
Wide-column databases (inspired by Bigtable) organize data by row keys, with many columns that can vary per row. They shine at massive write rates and distributed storage, making them a strong fit for time-series, event, and log workloads.
They tend to reward careful design around access patterns: you query efficiently by primary key and clustering rules, not arbitrary filters.
Graph databases treat relationships as first-class data. Instead of repeatedly joining tables, they traverse edges between nodes, making “how are these things connected?” queries natural and fast (fraud rings, recommendations, dependency graphs).
Relational databases encourage normalization: split data into many tables and reassemble with joins at query time. Many NoSQL systems push you to design around the most important access patterns—sometimes at the cost of duplication—to keep latency predictable across nodes.
In distributed databases, a join can require pulling data from multiple partitions or machines. That adds network hops, coordination, and unpredictable latency. Denormalization (storing related data together) reduces round-trips and keeps a read “local” as often as possible.
A practical consequence: you might store the same customer name in an orders record even if it also exists in customers, because “show me the last 20 orders” is a core query.
Many NoSQL databases support limited joins (or none), so the application takes on more responsibility:
This is why NoSQL modeling often starts with: “What screens do we need to load?” and “What are the top queries we must make fast?”
Secondary indexes can enable new queries (“find users by email”), but they aren’t free. In distributed systems, each write may update multiple index structures, leading to:
NoSQL wasn’t adopted because it was “better” in every way. It was adopted because teams were willing to trade certain conveniences of relational databases for speed, scale, and flexibility under web-scale pressure.
Scale-out by design. Many NoSQL systems made it practical to add machines (horizontal scaling) instead of continuously upgrading a single server. Sharding and replication were core capabilities, not afterthoughts.
Flexible schemas. Document and key-value systems let applications evolve without routing every field change through a strict table definition, reducing friction when requirements changed weekly.
High availability patterns. Replication across nodes and regions made it easier to keep services running during hardware failures or maintenance.
Data duplication and denormalization. Avoiding joins often means duplicating data. That improves read performance but increases storage and introduces “update it everywhere” complexity.
Consistency surprises. Eventual consistency can be acceptable—until it isn’t. Users may see stale data or confusing edge cases unless the application is designed to tolerate or resolve conflicts.
Harder analytics (sometimes). Some NoSQL stores excel at operational reads/writes but make ad-hoc querying, reporting, or complex aggregations more cumbersome than SQL-first systems.
Early NoSQL adoption often shifted effort from database features to engineering discipline: monitoring replication, managing partitions, running compaction, planning backups/restores, and load-testing failure scenarios. Teams with strong operational maturity benefited most.
Choose based on workload realities: expected latency, peak throughput, dominant query patterns, tolerance for stale reads, and recovery requirements (RPO/RTO). The “right” NoSQL choice is usually the one that matches how your application fails, scales, and needs to be queried—not the one with the most impressive checklist.
Choosing NoSQL shouldn’t start with database brands or hype—it should start with what your application needs to do, how it will grow, and what “correct” means for your users.
Before picking a datastore, write down:
If you can’t describe your access patterns clearly, any choice will be guesswork—especially with NoSQL, where modeling is often shaped around how you read and write.
Use this as a quick filter:
A practical signal: if your “core truth” (orders, payments, inventory) must be correct at all times, keep that in SQL or another strongly consistent store. If you’re serving high-volume content, sessions, caching, activity feeds, or flexible user-generated data, NoSQL can fit well.
Many teams succeed with multiple stores: for example, SQL for transactions, a document database for profiles/content, and a key-value store for sessions. The goal isn’t complexity for its own sake—it’s matching each workload to a tool that handles it cleanly.
This is also where developer workflow matters. If you’re iterating on architecture (SQL vs NoSQL vs hybrid), being able to spin up a working prototype quickly—API, data model, and UI—can de-risk decisions. Platforms like Koder.ai help teams do that by generating full-stack apps from chat, typically with a React frontend and a Go + PostgreSQL backend, then letting you export the source code. Even if you later introduce a NoSQL store for specific workloads, having a strong SQL “system of record” plus rapid prototyping, snapshots, and rollback can make experiments safer and faster.
Whatever you choose, prove it:
If you can’t test these scenarios, your database decision stays theoretical—and production will end up doing the testing for you.
NoSQL addressed two common pressures:
It wasn’t about SQL being “bad,” but about different workloads prioritizing different tradeoffs.
Traditional “scale up” hits practical limits:
NoSQL systems leaned into scaling out by adding nodes instead of continually buying a larger box.
Relational schemas are strict by design, which is great for stability but painful under rapid iteration. On large tables, even “simple” changes can require:
Document-style models often reduce this friction by allowing optional and evolving fields.
Not necessarily. Many SQL databases can scale out, but it can be operationally complex (sharding strategies, cross-shard joins, distributed transactions).
NoSQL systems often made distribution (partitioning + replication) a first-class design, optimized for simpler, predictable access patterns at large scale.
Denormalization stores data in the shape you read it, often duplicating fields to avoid expensive joins across partitions.
Example: keeping customer name inside an orders record so “last 20 orders” is a single fast read.
The tradeoff is update complexity: you must keep duplicated data consistent via application logic or pipelines.
In distributed systems, the database must decide what happens during network partitions:
CAP is a reminder that under partition, you can’t guarantee both perfect consistency and full availability at the same time.
Strong consistency means once a write is acknowledged, all readers see it immediately; it often requires coordination across nodes.
Eventual consistency means replicas may temporarily disagree, but converge over time. It can work well for feeds, counters, and high-availability user experiences—if the application tolerates brief staleness.
A conflict happens when different replicas accept concurrent updates. Common strategies include:
Your choice depends on whether losing intermediate updates is acceptable for that data.
A quick fit guide:
Pick based on your dominant access patterns, not general popularity.
Start with requirements and prove them with tests:
Many real systems are hybrid: SQL for core truth (payments, inventory), NoSQL for high-volume or flexible data (feeds, sessions, profiles).