Jul 21, 2025·8 min
Building a Web App for Incident Impact Analysis, Step by Step
Learn how to design and build a web app that calculates incident impact using service dependencies, real-time signals, and clear dashboards for teams.
Learn how to design and build a web app that calculates incident impact using service dependencies, real-time signals, and clear dashboards for teams.
Before you build calculations or dashboards, decide what “impact” actually means in your organization. If you skip this step, you’ll end up with a score that looks scientific but doesn’t help anyone act.
Impact is the measurable consequence of an incident on something the business cares about. Common dimensions include:
Pick 2–4 primary dimensions and define them explicitly. For example: “Impact = affected paying customers + SLA minutes at risk,” not “Impact = anything that looks bad on graphs.”
Different roles make different decisions:
Design “impact” outputs so each audience can answer their top question without translating metrics.
Decide what latency is acceptable. “Real-time” is expensive and often unnecessary; near-real-time (e.g., 1–5 minutes) may be enough for decision-making.
Write this down as a product requirement because it influences ingestion, caching, and UI.
Your MVP should directly support actions such as:
If a metric doesn’t change a decision, it’s probably not “impact”—it’s just telemetry.
Before you design screens or pick a database, write down what “impact analysis” must answer during a real incident. The goal isn’t perfect precision on day one—it’s consistent, explainable results that responders can trust.
Start with the data you must ingest or reference to calculate impact:
Most teams don’t have perfect dependency or customer mapping on day one. Decide what you’ll allow people to enter manually so the app is still useful:
Design these as explicit fields (not ad-hoc notes) so they’re queryable later.
Your first release should reliably generate:
Impact analysis is a decision tool, so constraints matter:
Write these requirements as testable statements. If you can’t verify it, you can’t rely on it during an outage.
Your data model is the contract between ingestion, calculation, and the UI. If you get it right, you can swap tooling sources, refine scoring, and still answer the same questions: “What broke?”, “Who is affected?”, and “For how long?”
At minimum, model these as first-class records:
Keep IDs stable and consistent across sources. If you already have a service catalog, treat it as the source of truth and map external tool identifiers into it.
Store multiple timestamps on the incident to support reporting and analysis:
Also store calculated time windows for impact scoring (e.g., 5-minute buckets). This makes replay and comparisons straightforward.
Model two key graphs:
A simple pattern is customer_service_usage(customer_id, service_id, weight, last_seen_at) so you can rank impact by “how much the customer relies on it.”
Dependencies evolve, and impact calculations should reflect what was true at the time. Add effective dating to edges:
dependency(valid_from, valid_to)Do the same for customer subscriptions and usage snapshots. With historical versions, you can accurately re-run past incidents during post-incident review and produce consistent SLA reporting.
Your impact analysis is only as good as the inputs feeding it. The goal here is straightforward: pull signals from the tools you already use, then convert them into a consistent event stream your app can reason about.
Start with a short list of sources that reliably describe “something changed” during an incident:
Don’t try to ingest everything at once. Pick sources that cover detection, escalation, and confirmation.
Different tools support different integration patterns:
A practical approach is: webhooks for critical signals, plus batch imports to fill gaps.
Normalize every incoming item into a single “event” shape, even if the source calls it an alert, incident, or annotation. At minimum, standardize:
Expect messy data. Use idempotency keys (source + external_id) to deduplicate, tolerate out-of-order events by sorting on occurred_at (not arrival time), and apply safe defaults when fields are missing (while flagging them for review).
A small “unmatched service” queue in the UI prevents silent errors and keeps your impact results trustworthy.
If your dependency map is wrong, your blast radius will be wrong—even if your signals and scoring are perfect. The goal is to build a dependency graph you can trust during an incident and also afterward.
Before you map edges, define the nodes. Create a service catalog entry for every system you might reference in an incident: APIs, background workers, data stores, third-party vendors, and other critical shared components.
Each service should include at least: owner/team, tier/criticality (e.g., customer-facing vs. internal), SLA/SLO targets, and links to runbooks and on-call docs (for example, /runbooks/payments-timeouts).
Use two complementary sources:
Treat these as separate edge types so people can understand confidence: “declared by team” vs. “observed in last 7 days.”
Dependencies should be directional: Checkout → Payments is not the same as Payments → Checkout. Direction drives reasoning (“if Payments is degraded, which upstreams might fail?”).
Also model hard vs. soft dependencies:
This distinction prevents overstating impact and helps responders prioritize.
Your architecture changes weekly. If you don’t store snapshots, you can’t accurately analyze an incident from two months ago.
Persist dependency graph versions over time (daily, per deploy, or on change). When calculating blast radius, resolve the incident timestamp to the closest graph snapshot, so “who was affected” reflects reality at that moment—not today’s architecture.
Once you’re ingesting signals (alerts, SLO burn, synthetic checks, customer tickets), the app needs a consistent way to turn messy inputs into a clear statement: what is broken, how bad is it, and who is affected?
You can get to a usable MVP with any of these patterns:
Whichever approach you choose, store the intermediate values (threshold hit, weights, tier) so people can understand why the score happened.
Avoid collapsing everything into one number too early. Track a few dimensions separately, then derive an overall severity:
This helps responders communicate precisely (e.g., “available but slow” vs. “incorrect results”).
Impact isn’t only service health—it’s who felt it.
Use usage mapping (tenant → service, customer plan → features, user traffic → endpoint) and calculate affected customers within a time window aligned to the incident (start time, mitigation time, and any backfill period).
Be explicit about assumptions: sampled logs, estimated traffic, or partial telemetry.
Operators will need to override: a false-positive alert, a partial rollout, a known subset of tenants.
Allow manual edits to severity, dimensions, and affected customers, but require:
This audit trail protects trust in the dashboard and makes post-incident review faster.
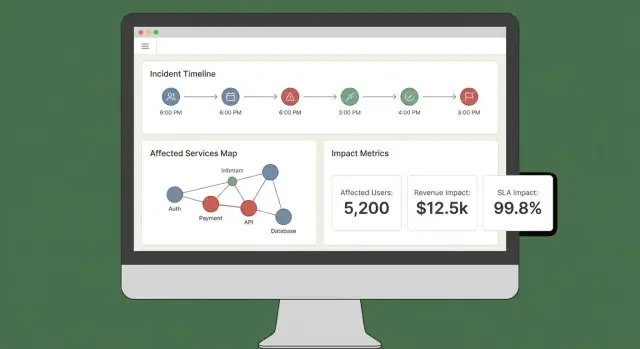
A good impact dashboard answers three questions quickly: What’s affected? Who’s affected? How sure are we? If users have to open five tabs to piece that together, they won’t trust the output—or act on it.
Start with a small set of “always-there” views that map to real incident workflows:
Impact scores without explanation feel arbitrary. Every score should be traceable back to inputs and rules:
A simple “Explain impact” drawer or panel can do this without cluttering the main view.
Make it easy to slice impact by service, region, customer tier, and time range. Let users click any chart point or row to drill into raw evidence (the exact monitors, logs, or events that drove the change).
During an active incident, people need portable updates. Include:
If you already have a status page, link to it via a relative route like /status so comms teams can cross-reference quickly.
Impact analysis is only useful if people trust it—which means controlling who can see what and keeping a clear record of changes.
Define a small set of roles that match how incidents run in real life:
Keep permissions aligned to actions, not job titles. For example, “can export customer impact report” is a permission you can grant to commanders and a small subset of admins.
Incident impact analysis often touches customer identifiers, contract tiers, and sometimes contact details. Apply least privilege by default:
Log key actions with enough context to support reviews:
Store audit logs append-only, with timestamps and actor identity. Make them searchable per incident so they’re usable during a post-incident review.
Document what you can support now—retention period, access controls, encryption, and audit coverage—and what’s on the roadmap.
A short “Security & Audit” page in your app (e.g., /security) helps set expectations and reduces ad-hoc questions during critical incidents.
Impact analysis only matters during an incident if it drives the next action. Your app should behave like a “co-pilot” for the incident channel: it turns incoming signals into clear updates, and it nudges people when the impact meaningfully changes.
Start by integrating with the place responders already work (often Slack, Microsoft Teams, or a dedicated incident tool). The goal isn’t to replace the channel—it’s to post context-aware updates and keep a shared record.
A practical pattern is to treat the incident channel as both an input and an output:
If you’re prototyping quickly, consider building the workflow end-to-end first (incident view → summarize → notify) before perfecting scoring. Platforms like Koder.ai can be useful here: you can iterate on a React dashboard and a Go/PostgreSQL backend through a chat-driven workflow, then export the source code once the incident team agrees the UX matches reality.
Avoid alert spam by triggering notifications only when impact crosses explicit thresholds. Common triggers include:
When a threshold is crossed, send a message that explains why (what changed), who should act, and what to do next.
Every notification should include “next-step” links so responders can move quickly:
Keep these links stable and relative so they work across environments.
Build two summary formats from the same data:
Support scheduled summaries (e.g., every 15–30 minutes) and on-demand “generate update” actions, with an approval step before sending externally.
Impact analysis is only useful if people trust it during an incident and after. Validation should prove two things: (1) the system produces stable, explainable results, and (2) those results match what your organization later agrees actually happened.
Start with automated tests that cover the two most failure-prone areas: scoring logic and data ingestion.
Keep test fixtures readable: when someone changes a rule, they should be able to understand why a score changed.
A replay mode is a fast path to confidence. Run historical incidents through the app and compare what the system would have shown “in the moment” versus what responders concluded later.
Practical tips:
Real incidents rarely look like clean outages. Your validation suite should include scenarios like:
For each, assert not only the score, but also the explanation: which signals and which dependencies/customers drove the result.
Define accuracy in operational terms, then track it.
Compare computed impact to post-incident review outcomes: affected services, duration, customer count, SLA breach, and severity. Log discrepancies as validation issues with a category (missing data, wrong dependency, bad threshold, delayed signal).
Over time, the goal isn’t perfection—it’s fewer surprises and faster agreement during incidents.
Shipping an MVP for incident impact analysis is mostly about reliability and feedback loops. Your first deployment choice should optimize for speed of change, not theoretical future scale.
Start with a modular monolith unless you already have a strong platform team and clear service boundaries. One deployable unit simplifies migrations, debugging, and end-to-end testing.
Split into services only when you feel real pain:
A pragmatic middle ground is one app + background workers (queues) + a separate ingestion edge if needed.
If you want to move fast without committing to a large bespoke platform build up front, Koder.ai can help accelerate the MVP: its chat-driven “vibe-coding” workflow is well-suited to building a React UI, a Go API, and a PostgreSQL data model, with snapshots/rollback when you’re iterating on scoring rules and workflow changes.
Use relational storage (Postgres/MySQL) for core entities: incidents, services, customers, ownership, and calculated impact snapshots. It’s easy to query, audit, and evolve.
For high-volume signals (metrics, logs-derived events), add a time-series store (or columnar store) when raw signal retention and rollups become expensive in SQL.
Consider a graph database only if dependency queries become a bottleneck or your dependency model becomes highly dynamic. Many teams can get far with adjacency tables plus caching.
Your impact analysis app becomes part of your incident toolchain, so instrument it like production software:
Expose a “health + freshness” view in the UI so responders can trust (or question) the numbers.
Define MVP scope tightly: a small set of tools to ingest, a clear impact score, and a dashboard that answers “who is affected and how much.” Then iterate:
Treat the model as a product: version it, migrate it safely, and document changes for post-incident review.
Impact is the measurable consequence of an incident on business-critical outcomes.
A practical definition names 2–4 primary dimensions (e.g., affected paying customers + SLA minutes at risk) and explicitly excludes “anything that looks bad on graphs.” That keeps the output tied to decisions, not just telemetry.
Pick dimensions that map to actions your teams take during the first 10 minutes.
Common MVP-friendly dimensions:
Limit it to 2–4 so the score stays explainable.
Design outputs so each role can answer their main question without translating metrics:
If one metric can’t be used by any of these audiences, it’s likely not “impact.”
“Real-time” is expensive; many teams do fine with near-real-time (1–5 minutes).
Write a latency target as a requirement because it affects:
Also set expectations in the UI (e.g., “data fresh as of 2 minutes ago”).
Start by listing the decisions responders must make, then ensure each output supports one:
If a metric doesn’t change a decision, keep it as telemetry, not impact.
Minimum required inputs typically include:
Allow explicit, queryable manual fields so the app remains useful when data is missing:
Require who/when/why for changes so trust doesn’t degrade over time.
A reliable MVP should produce:
Optionally add cost estimates (SLA credits, revenue risk) with confidence ranges.
Normalize every source into one event schema so calculations stay consistent.
At minimum standardize:
occurred_at, detected_at, Start simple and explainable:
Keep intermediate values (threshold hits, weights, tier, confidence) so users can see why the score changed. Track dimensions (availability/latency/errors/data correctness/security) before collapsing into one number.
This set is enough to compute “what broke,” “who is affected,” and “for how long.”
resolved_atservice_id (mapped from tool tags/names)source + original raw payload (for audit/debug)Handle messiness with idempotency keys (source + external_id) and out-of-order tolerance based on occurred_at.