Jul 27, 2025·8 min
How Languages, Databases, and Frameworks Work as One System
Learn how languages, databases, and frameworks work as one system. Compare tradeoffs, integration points, and practical ways to choose a coherent stack.
Learn how languages, databases, and frameworks work as one system. Compare tradeoffs, integration points, and practical ways to choose a coherent stack.
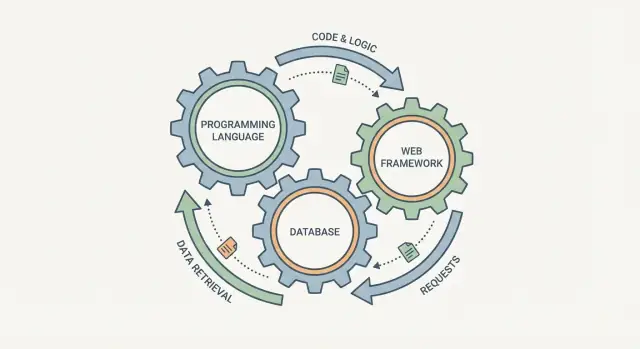
It’s tempting to pick a programming language, a database, and a web framework as three independent checkboxes. In practice, they behave more like connected gears: change one, and the others feel it.
A web framework shapes how requests are handled, how data is validated, and how errors are surfaced. The database shapes what “easy to store” looks like, how you query information, and what guarantees you get when multiple users act at once. The language sits in the middle: it determines how safely you can express rules, how you manage concurrency, and what libraries and tooling you can rely on.
Treating the stack as a single system means you don’t optimize each part in isolation. You choose a combination that:
This article stays practical and intentionally non-technical. You don’t need to memorize database theory or language internals—just see how choices ripple across the whole application.
A quick example: using a schema-less database for highly structured, report-heavy business data often leads to scattered “rules” in application code and confusing analytics later. A better fit is pairing that same domain with a relational database and a framework that encourages consistent validation and migrations, so your data stays coherent as the product evolves.
When you plan the stack together, you’re designing one set of tradeoffs—not three separate bets.
A helpful way to think about a “stack” is as a single pipeline: a user request enters your system, and a response (plus saved data) comes out. The programming language, web framework, and database aren’t independent picks—they’re three parts of the same journey.
Imagine a customer updates their shipping address.
/account/address). Validation checks the input is complete and sane.When these three align, a request flows cleanly. When they don’t, you get friction: awkward data access, leaky validation, and subtle consistency bugs.
Most “stack” debates start with language or database brand. A better starting point is your data model—because it quietly dictates what will feel natural (or painful) everywhere else: validation, queries, APIs, migrations, and even team workflow.
Applications usually juggle four shapes at once:
A good fit is when you don’t spend your days translating between shapes. If your core data is highly connected (users ↔ orders ↔ products), rows and joins can keep logic simple. If your data is mostly “one blob per entity” with variable fields, documents can reduce ceremony—until you need cross-entity reporting.
When the database has a strong schema, many rules can live close to the data: types, constraints, foreign keys, uniqueness. That often reduces duplicated checks across services.
With flexible structures, rules shift upward into the application: validation code, versioned payloads, backfills, and careful reading logic (“if field exists, then…”). This can work well when product requirements change weekly, but it increases the burden on your framework and testing.
Your model decides whether your code is mostly:
That, in turn, influences language and framework needs: strong typing can prevent subtle drift in JSON fields, while mature migration tooling matters more when schemas evolve frequently.
Pick the model first; the “right” framework and database choice often becomes clearer after that.
Transactions are the “all-or-nothing” guarantees your app quietly depends on. When a checkout succeeds, you expect the order record, the payment status, and the inventory update to either all happen—or none happen. Without that promise, you get the hardest kind of bugs: rare, expensive, and hard to reproduce.
A transaction groups multiple database operations into a single unit of work. If something fails midway (a validation error, a timeout, a crashed process), the database can roll back to the previous safe state.
This matters beyond money flows: account creation (user row + profile row), publishing content (post + tags + search index pointers), or any workflow that touches more than one table.
Consistency means “reads match reality.” Speed means “return something quickly.” Many systems make tradeoffs here:
The common failure pattern is choosing an eventually consistent setup, then coding as if it were strongly consistent.
Frameworks and ORMs don’t create transactions automatically just because you called multiple “save” methods. Some require explicit transaction blocks; others start a transaction per request, which can hide performance issues.
Retries are tricky too: ORMs may retry on deadlocks or transient failures, but your code must be safe to run twice.
Partial writes happen when you update A, then fail before updating B. Duplicate actions happen when a request is retried after a timeout—especially if you charge a card or send an email before the transaction commits.
A simple rule helps: make side effects (emails, webhooks) happen after the database commit, and make actions idempotent (safe to repeat) by using unique constraints or idempotency keys.
This is the “translation layer” between your application code and your database. The choices here often matter more day-to-day than the database brand itself.
An ORM (Object-Relational Mapper) lets you treat tables like objects: create a User, update a Post, and the ORM generates SQL behind the scenes. It can be productive because it standardizes common tasks and hides repetitive plumbing.
A query builder is more explicit: you build a SQL-like query using code (chains or functions). You still think in “joins, filters, groups,” but you get parameter safety and composability.
Raw SQL is writing the actual SQL yourself. It’s the most direct and often the clearest for complex reporting queries—at the cost of more manual work and conventions.
Languages with strong typing (TypeScript, Kotlin, Rust) tend to push you toward tools that can validate queries and result shapes early. That can reduce runtime surprises, but it also pressures teams to centralize data access so types don’t drift.
Languages with flexible metaprogramming (Ruby, Python) often make ORMs feel natural and fast to iterate with—until hidden queries or implicit behavior become hard to reason about.
Migrations are versioned change scripts for your schema: add a column, create an index, backfill data. The goal is simple: anyone can deploy the app and get the same database structure. Treat migrations as code you review, test, and roll back when needed.
ORMs can quietly generate N+1 queries, fetch huge rows you don’t need, or make joins awkward. Query builders can become unreadable “chains.” Raw SQL can get duplicated and inconsistent.
A good rule: use the simplest tool that keeps intent obvious—and for critical paths, inspect the SQL that actually runs.
People often blame “the database” when a page feels slow. But most user-visible latency is the sum of multiple small waits across the whole request path.
A single request typically pays for:
Even if your database can answer in 5 ms, an app that makes 20 queries per request, blocks on I/O, and spends 30 ms serializing a huge response will still feel sluggish.
Opening a new database connection is expensive and can overwhelm the database under load. A connection pool reuses existing connections so requests don’t pay that setup cost repeatedly.
The catch: the “right” pool size depends on your runtime model. A highly concurrent async server can create massive simultaneous demand; without pool limits, you’ll get queueing, timeouts, and noisy failures. With pool limits that are too strict, your app becomes the bottleneck.
Caching can sit in the browser, a CDN, an in-process cache, or a shared cache (like Redis). It helps when many requests need the same results.
But caching won’t rescue:
Your programming language runtime shapes throughput. Thread-per-request models can waste resources while waiting on I/O; async models can increase concurrency, but they also make backpressure (like pool limits) essential. That’s why performance tuning is a stack decision, not a database decision.
Security isn’t something you “add” with a framework plugin or a database setting. It’s the agreement between your language/runtime, your web framework, and your database about what must always be true—even when a developer makes a mistake or a new endpoint is added.
Authentication (who is this?) usually lives at the framework edge: sessions, JWTs, OAuth callbacks, middleware. Authorization (what are they allowed to do?) must be enforced consistently in both app logic and data rules.
A common pattern: the app decides intent (“user can edit this project”), and the database enforces boundaries (tenant IDs, ownership constraints, and—where it makes sense—row-level policies). If authorization exists only in controllers, background jobs and internal scripts can accidentally bypass it.
Framework validation gives fast feedback and good error messages. Database constraints provide a final safety net.
Use both when it matters:
This reduces “impossible states” that otherwise appear when two requests race or a new service writes data differently.
Secrets should be handled by the runtime and deployment workflow (env vars, secret managers), not hardcoded in code or migrations. Encryption can happen in the app (field-level encryption) and/or in the database (at-rest encryption, managed KMS), but you need clarity on who rotates keys and how recovery works.
Auditing is shared too: the app should emit meaningful events; the database should keep immutable logs where appropriate (e.g., append-only audit tables, restricted access).
Over-trusting app logic is the classic one: missing constraints, silent nulls, “admin” flags stored without checks. The fix is simple: assume bugs will happen, and design the stack so the database can refuse unsafe writes—even from your own code.
Scaling rarely fails because “the database can’t handle it.” It fails because the whole stack reacts poorly when load changes shape: one endpoint becomes popular, one query turns hot, one workflow starts retrying.
Most teams hit the same early bottlenecks:
Whether you can respond quickly depends on how well your framework and database tooling expose query plans, migrations, connection pooling, and safe caching patterns.
Common scaling moves tend to arrive in an order:
A scalable stack needs first-class support for background tasks, scheduling, and safe retries.
If your job system can’t enforce idempotency (the same job runs twice without double-charging or double-sending), you’ll “scale” into data corruption. Early choices—like relying on implicit transactions, weak uniqueness constraints, or opaque ORM behaviors—can block the clean introduction of queues, outbox patterns, or exactly-once-ish workflows later.
Early alignment pays off: pick a database that matches your consistency needs, and a framework ecosystem that makes the next scaling step (replicas, queues, partitioning) a supported path rather than a rewrite.
A stack feels “easy” when development and operations share the same assumptions: how you start the app, how data changes, how tests run, and how you know what happened when something breaks. If those pieces don’t line up, teams waste time on glue code, brittle scripts, and manual runbooks.
Fast local setup is a feature. Prefer a workflow where a new teammate can clone, install, run migrations, and have realistic test data in minutes—not hours.
That usually means:
If your framework’s migration tooling fights your database choice, every schema change becomes a small project.
Your stack should make it natural to write:
A common failure mode: teams lean on unit tests because integration tests are slow or painful to set up. That’s often a stack/ops mismatch—test database provisioning, migrations, and fixtures aren’t streamlined.
When latency spikes, you need to follow one request through the framework and into the database.
Look for consistent structured logs, basic metrics (request rate, errors, DB time), and traces that include query timing. Even a simple correlation ID that appears in app logs and database logs can turn “guessing” into “finding.”
Operations isn’t separate from development; it’s the continuation of it.
Choose tooling that supports:
If you can’t confidently rehearse a restore or a migration locally, you won’t do it well under pressure.
Choosing a stack is less about picking “best” tools and more about picking tools that fit together under your real constraints. Use this checklist to force alignment early.
Time-box to 2–5 days. Build one thin vertical slice: one core workflow, one background job, one report-like query, and basic auth. Measure developer friction, migration ergonomics, query clarity, and how easily you can test.
If you want to accelerate this step, a vibe-coding tool like Koder.ai can be useful for quickly generating a working vertical slice (UI, API, and database) from a chat-driven spec—then iterating with snapshots/rollback and exporting the source code when you’re ready to commit to a direction.
Title:
Date:
Context (what we’re building, constraints):
Options considered:
Decision (language/framework/database):
Why this fits (data model, consistency, ops, hiring):
Risks & mitigations:
When we’ll revisit:
Even strong teams end up with stack mismatches—choices that look fine in isolation but create friction once the system is built. The good news: most are predictable, and you can avoid them with a few checks.
A classic smell is choosing a database or framework because it’s trending while your actual data model is still fuzzy. Another is premature scaling: optimizing for millions of users before you can reliably handle hundreds, which often leads to extra infrastructure and more failure modes.
Also watch for stacks where the team can’t explain why each major piece exists. If the answer is mostly “everyone uses it,” you’re accumulating risk.
Many problems show up at the seams:
These aren’t “database issues” or “framework issues”—they’re system issues.
Prefer fewer moving parts and one clear path for common tasks: one migration approach, one query style for most features, and consistent conventions across services. If your framework encourages a pattern (request lifecycle, dependency injection, job pipeline), lean into it instead of mixing styles.
Revisit choices when you see recurring production incidents, persistent developer friction, or when new product requirements fundamentally change your data access patterns.
Change safely by isolating the seam: introduce an adapter layer, migrate incrementally (dual-write or backfill when needed), and prove parity with automated tests before flipping traffic.
Choosing a programming language, a web framework, and a database isn’t three independent decisions—it’s one system design decision expressed in three places. The “best” option is the combination that aligns with your data shape, your consistency needs, your team’s workflow, and the way you expect the product to grow.
Write down the reasons behind your choices: expected traffic patterns, acceptable latency, data retention rules, failure modes you can tolerate, and what you’re explicitly not optimizing for right now. This makes tradeoffs visible, helps future teammates understand “why,” and prevents accidental architecture drift when requirements change.
Run your current setup through the checklist section and note where decisions don’t line up (for example, a schema that fights the ORM, or a framework that makes background work awkward).
If you’re exploring a new direction, tools like Koder.ai can also help you compare stack assumptions quickly by generating a baseline app (commonly React on the web, Go services with PostgreSQL, and Flutter for mobile) that you can inspect, export, and evolve—without committing to a long build cycle upfront.
For deeper follow-up, browse related guides on /blog, look up implementation details in /docs, or compare support and deployment options on /pricing.
Treat them as a single pipeline for every request: framework → code (language) → database → response. If one piece encourages patterns the others fight (e.g., schema-less storage + heavy reporting), you’ll spend time on glue code, duplicated rules, and hard-to-debug consistency issues.
Start with your core data model and the operations you’ll do most often:
Once the model is clear, the natural database and framework features you need usually become obvious.
If the database enforces a strong schema, many rules can live close to the data:
NOT NULL, uniquenessCHECK constraints for valid ranges/statesWith flexible structures, more rules move into application code (validation, versioned payloads, backfills). That can speed early iteration, but increases testing burden and the chance of drift across services.
Use transactions whenever multiple writes must succeed or fail together (e.g., order + payment status + inventory change). Without transactions, you risk:
Also keep side effects (emails/webhooks) after commit and make operations idempotent (safe to retry).
Pick the simplest option that keeps intent obvious:
For critical endpoints, always inspect the SQL that actually runs.
Keep schema and code in sync with migrations you treat like production code:
If migrations are manual or flaky, environments drift and deploys become risky.
Profile the entire request path, not just the database:
A database that answers in 5 ms won’t help if the app makes 20 queries or blocks on I/O.
Use a connection pool to avoid paying connection setup costs per request and to protect the database under load.
Practical guidance:
Mis-sized pools often show up as timeouts and noisy failures during traffic spikes.
Use both layers:
NOT NULL, CHECK)This prevents “impossible states” when requests race, background jobs write data, or a new endpoint forgets a check.
Time-box a small proof of concept (2–5 days) that exercises the real seams:
Then write a one-page decision record so future changes are intentional (see related guides at /docs and /blog).