Sep 21, 2025·8 min
Meilisearch for Instant Server-Side Search in Your Apps
Learn how to add Meilisearch to your backend for fast, typo-tolerant search: setup, indexing, ranking, filters, security, and scaling basics.
Learn how to add Meilisearch to your backend for fast, typo-tolerant search: setup, indexing, ranking, filters, security, and scaling basics.
Server-side search means the query is processed on your server (or a dedicated search service), not inside the browser. Your app sends a search request, the server runs it against an index, and returns ranked results.
This matters when your dataset is too large to ship to the client, when you need consistent relevancy across platforms, or when access control is non-negotiable (for example, internal tools where users should only see what they’re allowed to see). It’s also the default choice when you want analytics, logging, and predictable performance.
People don’t think about search engines—they judge the experience. A good “instant” search flow usually means:
If any of these are missing, users compensate by trying different queries, scrolling more, or abandoning search entirely.
This article is a practical walkthrough for building that experience with Meilisearch. We’ll cover how to set it up safely, how to structure and sync your indexed data, how to tune relevancy and ranking rules, how to add filters/sorting/facets, and how to think about security and scaling so search stays fast as your app grows.
Meilisearch is a strong fit for:
The goal throughout: results that feel immediate, accurate, and trustworthy—without turning search into a major engineering project.
Meilisearch is a search engine you run alongside your app. You send it documents (like products, articles, users, or support tickets), and it builds an index optimized for fast searching. Your backend (or frontend) then queries Meilisearch through a simple HTTP API and gets back ranked results in milliseconds.
Meilisearch focuses on the features people expect from modern search:
It’s designed to feel responsive and forgiving, even when a query is short, slightly wrong, or ambiguous.
Meilisearch is not a replacement for your primary database. Your database remains the source of truth for writes, transactions, and constraints. Meilisearch stores a copy of the fields you choose to make searchable, filterable, or displayable.
A good mental model is: database for storing and updating data, Meilisearch for finding it quickly.
Meilisearch can be extremely fast, but results depend on a few practical factors:
For small-to-medium datasets, you can often run it on a single machine. As your index grows, you’ll want to be more deliberate about what you index and how you keep it updated—topics we’ll cover in later sections.
Before you install anything, decide what you’re actually going to search. Meilisearch will feel “instant” only if your indexes and documents match how people browse your app.
Start by listing your searchable entities—typically products, articles, users, help docs, locations, etc. In many apps, the cleanest approach is one index per entity type (e.g., products, articles). That keeps ranking rules and filters predictable.
If your UX searches across multiple types in one box (“search everything”), you can still keep separate indexes and merge results in your backend, or create a dedicated “global” index later. Don’t force everything into one index unless the fields and filters are truly aligned.
Each document needs a stable identifier (primary key). Pick something that:
id, sku, slug)For the document shape, prefer flat fields when you can. Flat structures are easier to filter and sort on. Nested fields are fine when they represent a tight, unchanging bundle (e.g., an author object), but avoid deep nesting that mirrors your whole relational schema—search documents should be read-optimized, not database-shaped.
A practical way to design documents is to tag each field with one role:
This prevents a common mistake: indexing a field “just in case” and later wondering why results are noisy or filters are slow.
“Language” can mean different things in your data:
lang: "en")Decide early whether you’ll use separate indexes per language (simple and predictable) or a single index with language fields (fewer indexes, more logic). The right answer depends on whether users search within one language at a time and how you store translations.
Running Meilisearch is straightforward, but “safe by default” takes a few deliberate choices: where you deploy it, how you persist data, and how you handle the master key.
Storage: Meilisearch writes its index to disk. Put the data directory on reliable, persistent storage (not ephemeral container storage). Plan capacity for growth: indexes can expand quickly with large text fields and many attributes.
Memory: allocate enough RAM to keep search responsive under load. If you notice swapping, performance will suffer.
Backups: back up the Meilisearch data directory (or use snapshots at the storage layer). Test restore at least once; a backup you can’t restore is just a file.
Monitoring: track CPU, RAM, disk usage, and disk I/O. Also monitor process health and log errors. At minimum, alert if the service stops or disk space runs low.
Always run Meilisearch with a master key in anything beyond local development. Store it in a secret manager or encrypted environment variable store (not in Git, not in a plain-text .env committed to your repo).
Example (Docker):
docker run -d --name meilisearch \
-p 7700:7700 \
-v meili_data:/meili_data \
-e MEILI_MASTER_KEY="$(openssl rand -hex 32)" \
getmeili/meilisearch:latest
Also consider network rules: bind to a private interface or restrict inbound access so only your backend can reach Meilisearch.
curl -s http://localhost:7700/version
Meilisearch indexing is asynchronous: you send documents, Meilisearch queues a task, and only after that task succeeds will those documents become searchable. Treat indexing like a job system, not a single request.
id).curl -X POST 'http://localhost:7700/indexes/products/documents?primaryKey=id' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_WRITE_KEY' \
--data-binary @products.json
taskUid. Poll until it’s succeeded (or failed).curl -X GET 'http://localhost:7700/tasks/123' \
-H 'Authorization: Bearer YOUR_WRITE_KEY'
curl -X GET 'http://localhost:7700/indexes/products/stats' \
-H 'Authorization: Bearer YOUR_WRITE_KEY'
If counts don’t match, don’t guess—check the task error details first.
Batching is about keeping tasks predictable and recoverable.
addDocuments acts like an upsert: documents with the same primary key are updated, new ones are inserted. Use this for normal updates.
Do a full reindex when:
For removals, explicitly call deleteDocument(s); otherwise old records can linger.
Indexing should be retryable. The key is stable document ids.
taskUid alongside your batch/job id, and retry based on task status.Before production data, index a small dataset (200–500 items) that matches your real fields. Example: a products set with id, name, description, category, brand, price, inStock, createdAt. This is enough to validate task flow, counts, and update/delete behavior—without waiting on a massive import.
Search “relevancy” is simply: what shows up first, and why. Meilisearch makes this adjustable without forcing you to build your own scoring system.
Two settings shape what Meilisearch can do with your content:
searchableAttributes: the fields Meilisearch looks into when a user types a query (for example: title, summary, tags). Order matters: earlier fields are treated as more important.displayedAttributes: the fields returned in the response. This matters for privacy and payload size—if a field isn’t displayed, it won’t be sent back.A practical baseline is to make a few high-signal fields searchable (title, key text), and keep displayed fields to what the UI needs.
Meilisearch sorts matching documents using ranking rules—a pipeline of “tie-breakers.” Conceptually, it prefers:
You don’t have to memorize the internals to tune it effectively; you mainly choose which fields matter most and when to apply custom sorting.
Goal: “Title matches should win.” Put title first:
{
"searchableAttributes": ["title", "subtitle", "description", "tags"]
}
Goal: “Newer content should appear first.” Add a sort rule and sort at query time (or set a custom ranking):
{
"sortableAttributes": ["publishedAt"],
"rankingRules": ["sort", "typo", "words", "proximity", "attribute", "exactness"]
}
Then request:
{ "q": "release notes", "sort": ["publishedAt:desc"] }
Goal: “Promote popular items.” Make popularity sortable and sort by it when appropriate.
Pick 5–10 real queries users type. Save the top results before changes, then compare after.
Example:
"apple" → Apple Watch band, Pineapple slicer, Apple iPhone case"apple" → Apple iPhone case, Apple Watch band, Pineapple slicerIf the “after” list better matches user intent, keep the settings. If it hurts edge cases, adjust one thing at a time (attribute order, then sorting rules) so you know what caused the improvement.
A good search box isn’t just “type words, get matches.” People also want to narrow results (“only available items”) and order them (“cheapest first”). In Meilisearch, you do this with filters, sorting, and facets.
A filter is a rule you apply to the result set. A facet is what you show in the UI to help users build those rules (often as checkboxes or counts).
Non-technical examples:
So a user might search “running” and then filter to category = Shoes and status = in_stock. Facets can show counts like “Shoes (128)” and “Jackets (42)” so users understand what’s available.
Meilisearch needs you to explicitly allow fields used for filtering and sorting.
category, status, brand, price, created_at (if you filter by time), tenant_id (if you isolate customers).price, rating, created_at, popularity.Keep this list tight. Making everything filterable/sortable can increase index size and slow updates.
Even if you have 50,000 matches, users only see the first page. Use small pages (often 20–50 results), set sensible limit, and paginate with offset (or the newer pagination features if you prefer). Also cap maximum page depth in your app to prevent expensive “page 400” requests.
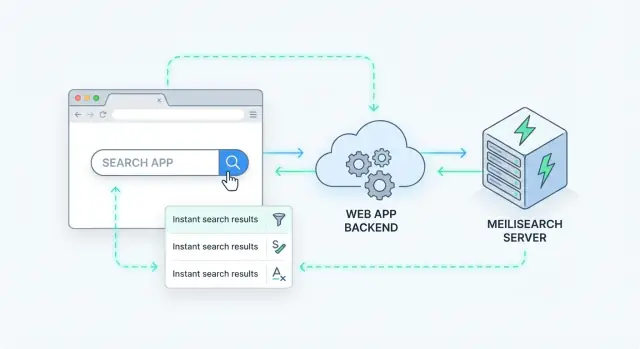
A clean way to add server-side search is to treat Meilisearch like a specialized data service behind your API. Your app receives a search request, calls Meilisearch, then returns a curated response to the client.
Most teams end up with a flow like this:
GET /api/search?q=wireless+headphones&limit=20).This pattern keeps Meilisearch replaceable and prevents frontend code from depending on index internals.
If you’re building a new app (or rebuilding an internal tool) and want this pattern implemented quickly, a vibe-coding platform like Koder.ai can help scaffold the full flow—React UI, a Go backend, and PostgreSQL—then integrate Meilisearch behind a single /api/search endpoint so the client stays simple and your permissions stay server-side.
Meilisearch supports client-side querying, but backend querying is usually safer because:
Frontend querying can still work for public data with restricted keys, but if you have any user-specific visibility rules, route search through your server.
Search traffic often has repeats (“iphone case”, “return policy”). Add caching at your API layer:
Treat search as a public-facing endpoint:
limit and a maximum query length.Meilisearch is often placed “behind” your app because it can return sensitive business data fast. Treat it like a database: lock it down, and expose only what each caller should see.
Meilisearch has a master key that can do everything: create/delete indexes, update settings, and read/write documents. Keep it server-only.
For applications, generate API keys with limited actions and limited indexes. A common pattern:
Least privilege means a leaked key can’t delete data or read from unrelated indexes.
If you serve multiple customers (tenants), you have two main options:
1) One index per tenant.
Simple to reason about and reduces risk of cross-tenant access. Downsides: more indexes to manage, and settings updates must be applied consistently.
2) Shared index + tenant filter.
Store a tenantId field on every document and require a filter like tenantId = "t_123" for all searches. This can scale well, but only if you ensure every request always applies the filter (ideally via a scoped key so callers can’t remove it).
Even if search is correct, results can leak fields you didn’t intend to show (emails, internal notes, cost prices). Configure what’s retrievable:
Do a quick “worst-case” test: search for a common term and confirm no private fields appear.
If you’re unsure whether a key should be client-side, assume “no” and keep search server-side.
Meilisearch is fast when you keep two workloads in mind: indexing (writing) and search queries (reading). Most “mystery slowness” is simply one of these competing for CPU, RAM, or disk.
Indexing load can spike when you import large batches, run frequent updates, or add many searchable fields. Indexing is a background task, but it still consumes CPU and disk bandwidth. If your task queue grows, searches may start to feel slower even if query volume hasn’t changed.
Query load grows with traffic, but also with features: more filters, more facets, larger result sets, and more typo tolerance can increase work per request.
Disk I/O is the quiet culprit. Slow disks (or noisy neighbors on shared volumes) can turn “instant” into “eventually.” NVMe/SSD storage is the typical baseline for production.
Start with simple sizing: give Meilisearch enough RAM to keep indexes hot and enough CPU to handle peak QPS. Then separate concerns:
Track a small set of signals:
Backups should be routine, not heroic. Use Meilisearch’s snapshot feature on a schedule, store snapshots off-box, and periodically test restores. For upgrades, read release notes, stage the upgrade in a non-prod environment, and plan for reindexing time if a version change affects indexing behavior.
If you already use environment snapshots and rollback in your app platform (for example, via Koder.ai’s snapshots/rollback workflow), align your search rollout with the same discipline: snapshot before changes, verify health checks, and keep a quick path back to a known-good state.
Even with a clean integration, search problems tend to fall into a few repeatable buckets. The good news: Meilisearch gives you enough visibility (tasks, logs, deterministic settings) to debug quickly—if you approach it systematically.
filterableAttributes, or the documents store it in an unexpected shape (string vs array vs nested object).sortableAttributes/rankingRules tweak is pushing the “wrong” items up.Start by checking whether Meilisearch successfully applied your last change.
filter, then sort, then facets.If you can’t explain a result, temporarily strip your configuration back: remove synonyms, reduce ranking rule tweaks, and test with a tiny dataset. Complex relevance issues are much easier to spot on 50 documents than on 5 million.
your_index_v2 in parallel, apply settings, and replay a sample of production queries.filterableAttributes and sortableAttributes match your UI requirements.Related guides: /blog (search reliability, indexing patterns, and production rollout tips).
Server-side search means the query runs on your backend (or a dedicated search service), not in the browser. It’s the right choice when:
Users notice four things immediately:
If one is missing, people retype queries, over-scroll, or abandon search.
Treat it as a search index, not your source of truth. Your database handles writes, transactions, and constraints; Meilisearch stores a copy of selected fields optimized for retrieval.
A useful mental model is:
A common default is one index per entity type (e.g., products, articles). This keeps:
If you need “search everything,” you can query multiple indexes and merge results in your backend, or add a dedicated global index later.
Pick a primary key that is:
id, sku, slug)Stable IDs make indexing idempotent: if you retry an upload, you won’t create duplicates because updates become safe upserts.
Classify each field by purpose so you don’t over-index:
Keeping these roles explicit reduces noisy results and prevents slow or bloated indexes.
Indexing is asynchronous: document uploads create a task, and documents become searchable only after that task succeeds.
A reliable flow is:
succeeded or failedIf results look stale, check task status before debugging anything else.
Use many smaller batches instead of one huge upload. Practical starting points:
Smaller batches are easier to retry, easier to debug (find bad records), and less likely to time out.
Two high-impact levers are:
searchableAttributes: which fields are searched, and in what priority orderpublishedAt, price, or popularityA practical approach is to take 5–10 real user queries, record top results “before,” change one setting, then compare “after.”
Most filter/sort issues come from missing configuration:
filterableAttributes to filter on itsortableAttributes to sort by itAlso verify field shape and types in documents (string vs array vs nested object). If a filter fails, inspect the last settings/task status and confirm the indexed documents actually contain the expected field values.