Oct 29, 2025·8 min
One AI-Generated Codebase for Web, Mobile, and APIs
See how a single AI-generated codebase can power web apps, mobile apps, and APIs with shared logic, consistent data models, and safer releases.
See how a single AI-generated codebase can power web apps, mobile apps, and APIs with shared logic, consistent data models, and safer releases.
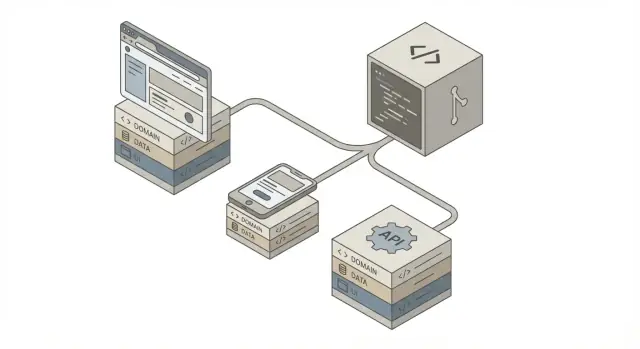
“One codebase” rarely means one UI that runs everywhere. In practice, it usually means one repository and one set of shared rules—with separate delivery surfaces (web app, mobile app, API) that all depend on the same underlying business decisions.
A useful mental model is to share the parts that should never disagree:
Meanwhile, you typically don’t share the UI layer wholesale. Web and mobile have different navigation patterns, accessibility expectations, performance constraints, and platform capabilities. Sharing UI can be a win in some cases, but it’s not the definition of “one codebase.”
AI-generated code can dramatically speed up:
But AI doesn’t automatically produce a coherent architecture. Without clear boundaries, it tends to duplicate logic across apps, mix concerns (UI calling database code directly), and create “almost the same” validations in multiple places. The leverage comes from defining the structure first—then using AI to fill in repetitive parts.
A single AI-assisted codebase is successful when it delivers:
A single codebase only works when you’re clear about what it must achieve—and what it must not try to standardize. Web, mobile, and APIs serve different audiences and usage patterns, even when they share the same business rules.
Most products have at least three “front doors”:
The goal is consistency in behavior (rules, permissions, calculations)—not identical experiences.
A common failure mode is treating “single codebase” as “single UI.” That usually produces a web-like mobile app or a mobile-like web app—both frustrating.
Instead, aim for:
Offline mode: Mobile often needs read access (and sometimes writes) without a network. That implies local storage, sync strategies, conflict handling, and clear “source of truth” rules.
Performance: Web cares about bundle size and time-to-interactive; mobile cares about startup time and network efficiency; APIs care about latency and throughput. Sharing code should not mean shipping unnecessary modules to every client.
Security and compliance: Authentication, authorization, audit trails, encryption, and data retention must be consistent across all surfaces. If you operate in regulated spaces, bake in requirements like logging, consent, and least-privilege access from the start—not as patches.
A single codebase works best when it’s organized into clear layers with strict responsibilities. That structure also makes AI-generated code easier to review, test, and replace without breaking unrelated parts.
Here’s the basic shape most teams converge on:
Clients (Web / Mobile / Partners)
↓
API Layer
↓
Domain Layer
↓
Data Sources (DB / Cache / External APIs)
The key idea: user interfaces and transport details sit at the edges, while business rules stay in the center.
The “shareable core” is everything that should behave the same everywhere:
When AI generates new features, the best outcome is: it updates the domain rules once, and every client benefits automatically.
Some code is expensive (or risky) to force into a shared abstraction:
A practical rule: if the user can see it or the OS can break it, keep it app-specific. If it’s a business decision, keep it in the domain.
The shared domain layer is the part of the codebase that should feel “boring” in the best way: predictable, testable, and reusable everywhere. If AI is helping generate your system, this layer is where you anchor the project’s meaning—so web screens, mobile flows, and API endpoints all reflect the same rules.
Define the core concepts of your product as entities (things with identity over time, like Account, Order, Subscription) and value objects (things defined by their value, like Money, EmailAddress, DateRange). Then capture behavior as use cases (sometimes called application services): “Create order,” “Cancel subscription,” “Change email.”
This structure keeps the domain understandable to non-specialists: nouns describe what exists, verbs describe what the system does.
Business logic should not know whether it’s being triggered by a button tap, a web form submit, or an API request. Practically, that means:
When AI generates code, this separation is easy to lose—models get stuffed with UI concerns. Treat that as a refactor trigger, not a preference.
Validation is where products often drift: the web allows something the API rejects, or mobile validates differently. Put consistent validation into the domain layer (or a shared validation module) so all surfaces enforce the same rules.
Examples:
EmailAddress validates format once, reused across web/mobile/APIMoney prevents negative totals, regardless of where the value originatedIf you do this well, the API layer becomes a translator, and web/mobile become presenters—while the domain layer stays the single source of truth.
The API layer is the “public face” of your system—and in a single AI-generated codebase, it should be the part that anchors everything else. If the contract is clear, the web app, mobile app, and even internal services can be generated and validated against the same source of truth.
Define the contract before you generate handlers or UI wiring:
/users, /orders/{id}), predictable filtering and sorting./v1/... or header-based) and document deprecation rules.Use OpenAPI (or a schema-first tool like GraphQL SDL) as the canonical artifact. From that, generate:
This matters for AI-generated code: the model can create lots of code quickly, but the schema keeps it aligned.
Set a few non-negotiables:
snake_case or camelCase, not both; match between JSON and generated types.Idempotency-Key for risky operations (payments, order creation), and define retry behavior.Treat the API contract as a product. When it’s stable, everything else becomes easier to generate, test, and ship.
A web app benefits greatly from shared business logic—and suffers when that logic gets tangled with UI concerns. The key is to treat the shared domain layer as a “headless” engine: it knows the rules, validations, and workflows, but nothing about components, routes, or browser APIs.
If you use SSR (server-side rendering), shared code must be safe to run on the server: no direct window, document, or browser storage calls. That’s a good forcing function: keep browser-dependent behavior in a thin web adapter layer.
With CSR (client-side rendering), you have more freedom, but the same discipline still pays off. CSR-only projects often “accidentally” import UI code into domain modules because everything runs in the browser—until you later add SSR, edge rendering, or tests that run in Node.
A practical rule: shared modules should be deterministic and environment-agnostic; anything that touches cookies, localStorage, or the URL belongs in the web app layer.
Shared logic can expose domain state (e.g., order totals, eligibility, derived flags) through plain objects and pure functions. The web app should own UI state: loading spinners, form focus, optimistic animations, modal visibility.
This keeps React/Vue state management flexible: you can change libraries without rewriting business rules.
The web layer should handle:
localStorage, caching)Think of the web app as an adapter that translates user interactions into domain commands—and translates domain outcomes into accessible screens.
A mobile app benefits most from a shared domain layer: the rules for pricing, eligibility, validation, and workflows should behave the same as the web app and the API. The mobile UI then becomes a “shell” around that shared logic—optimized for touch, intermittent connectivity, and device features.
Even with shared business logic, mobile has patterns that rarely map 1:1 to web:
If you expect real mobile usage, assume offline:
A “single codebase” breaks down quickly if your web app, mobile app, and API each invent their own data shapes and security rules. The fix is to treat models, authentication, and authorization as shared product decisions, then encode them once.
Pick one place where models live, and make everything else derive from it. Common options are:
The key isn’t the tool—it’s consistency. If “OrderStatus” has five values in one client and six in another, AI-generated code will happily compile and still ship bugs.
Authentication should feel the same to the user, but the mechanics differ by surface:
Design a single flow: login → short-lived access → refresh when needed → logout that invalidates server-side state. On mobile, store secrets in secure storage (Keychain/Keystore), not plain preferences. On web, prefer httpOnly cookies so tokens aren’t exposed to JavaScript.
Permissions should be defined once—ideally close to business rules—then applied everywhere.
This prevents “works on mobile but not on web” drift and gives AI code generation a clear, testable contract for who can do what.
A unified codebase only stays unified if builds and releases are predictable. The goal is to let teams ship the API, web app, and mobile apps independently—without forking logic or “special casing” environments.
A monorepo (one repo, multiple packages/apps) tends to work best for a single codebase because shared domain logic, API contracts, and UI clients evolve together. You get atomic changes (one PR updates a contract and all consumers) and simpler refactors.
A multi-repo setup can still be unified, but you’ll pay in coordination: versioning shared packages, publishing artifacts, and synchronizing breaking changes. Choose multi-repo only if org boundaries, security rules, or scale make a monorepo impractical.
Treat each surface as a separate build target that consumes shared packages:
Keep build outputs explicit and reproducible (lockfiles, pinned toolchains, deterministic builds).
A typical pipeline is: lint → typecheck → unit tests → contract tests → build → security scan → deploy.
Separate config from code: environment variables and secrets live in your CI/CD and secret manager, not in the repo. Use environment-specific overlays (dev/stage/prod) so the same artifact can be promoted across environments without rebuilding—especially for the API and web runtime.
When web, mobile, and API ship from the same codebase, testing stops being “one more checkbox” and becomes the mechanism that prevents a small change from breaking three products at once. The goal is simple: detect problems where they’re cheapest to fix, and block risky changes before they reach users.
Start with the shared domain (your business logic) because it’s the most reused and the easiest place to test without slow infrastructure.
This structure keeps most confidence in the shared logic, while still catching “wiring” issues where layers meet.
Even in a monorepo, it’s easy for the API to change in a way that compiles but breaks user experience. Contract tests prevent silent drift.
Good tests matter, but so do the rules around them.
With these gates in place, AI-assisted changes can be frequent without being fragile.
AI can accelerate a single codebase, but only if it’s treated like a fast junior engineer: great at producing drafts, unsafe to merge without review. The goal is to use AI for speed while keeping humans responsible for architecture, contracts, and long-term coherence.
Use AI to generate “first versions” you would otherwise write mechanically:
A good rule: let AI produce code that is easy to verify by reading or by running tests, not code that silently changes business meaning.
AI output should be constrained by explicit rules, not vibes. Put these rules where the code is:
If AI suggests a shortcut that violates boundaries, the answer is “no,” even if it compiles.
The risk isn’t only bad code—it’s untracked decisions. Keep an audit trail:
AI is most valuable when it’s repeatable: the team can see why something was generated, verify it, and regenerate safely when requirements evolve.
If you’re adopting AI-assisted development at the system level (web + API + mobile), the most important “feature” isn’t raw generation speed—it’s the ability to keep outputs aligned with your contracts and layering.
For example, Koder.ai is a vibe-coding platform that helps teams build web, server, and mobile applications through a chat interface—while still producing real, exportable source code. In practice, that’s useful for the workflow described in this article: you can define an API contract and domain rules, then iterate quickly on React-based web surfaces, Go + PostgreSQL backends, and Flutter mobile apps without losing the ability to review, test, and enforce architecture boundaries. Features like planning mode, snapshots, and rollback also map well to “generate → verify → promote” release discipline in a unified codebase.
A single codebase can reduce duplication, but it’s not a default “best” choice. The moment shared code starts forcing awkward UX, slowing releases, or hiding platform differences, you’ll spend more time negotiating architecture than shipping value.
Separate codebases (or at least separate UI layers) are often justified when:
Ask these before committing to a single codebase:
If you’re seeing warning signs, a practical alternative is shared domain + API contracts, with separate web and mobile apps. Keep shared code focused on business rules and validation, and let each client own UX and platform integrations.
If you want help choosing a path, compare options on /pricing or browse related architecture patterns on /blog.
It usually means one repository and one set of shared rules, not one identical app.
In practice, web, mobile, and the API share a domain layer (business rules, validation, use cases) and often a single API contract, while each platform keeps its own UI and platform integrations.
Share what must never disagree:
Keep UI components, navigation, and device/browser integrations platform-specific.
AI accelerates scaffolding and repetitive work (CRUD, clients, tests), but it won’t automatically create good boundaries.
Without an intentional architecture, AI-generated code often:
Use AI to fill in well-defined layers, not to invent the layering.
A simple, reliable flow is:
This keeps business rules centralized and makes both testing and AI-generated additions easier to review.
Put validation in one place (domain or a shared validation module), then reuse it everywhere.
Practical patterns:
EmailAddress and Money onceThis prevents “web accepts it, API rejects it” drift.
Use a canonical schema like OpenAPI (or GraphQL SDL) and generate from it:
Then add contract tests so schema-breaking changes fail in CI before they ship.
Design offline intentionally rather than “hoping caching works”:
Keep offline storage and sync in the mobile app layer; keep business rules in shared domain code.
Use one conceptual flow, implemented appropriately per surface:
Authorization rules should be defined centrally (e.g., canApproveInvoice) and enforced at the API; UI mirrors checks only to hide/disable actions.
Treat each surface as a separate build target that consumes shared packages:
In CI/CD, run: lint → typecheck → unit tests → contract tests → build → security scan → deploy, and keep secrets/config outside the repo.
Use AI like a fast junior engineer: great for drafts, unsafe without guardrails.
Good guardrails:
If AI output violates architecture rules, reject it even if it compiles.