Reliable webhook integrations: signing, idempotency, debugging
Learn reliable webhook integrations with signing, idempotency keys, replay protection, and a fast debugging workflow for customer-reported failures.
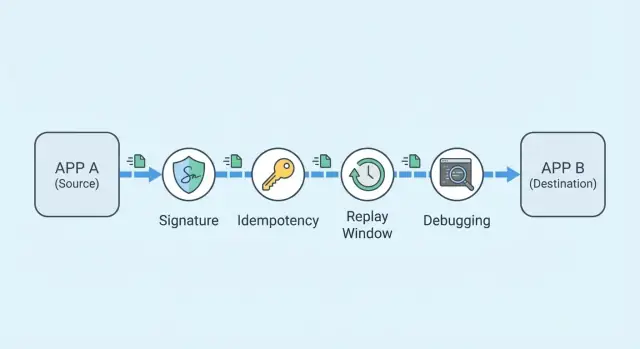
Why webhooks fail in real life
When someone says “webhooks are broken,” they usually mean one of three things: events never arrived, events arrived twice, or events arrived in a confusing order. From their point of view, the system “missed” something. From your point of view, the provider did send it, but your endpoint didn’t accept it, didn’t process it, or didn’t record it the way you expected.
Webhooks live on the public internet. Requests get delayed, retried, and sometimes delivered out of order. Most providers retry aggressively when they see timeouts or non-2xx responses. That turns a small hiccup (a slow database, a deploy, a brief outage) into duplicates and race conditions.
Bad logs make this feel random. If you can’t prove whether a request was authentic, you can’t safely act on it. If you can’t tie a customer complaint to a specific delivery attempt, you end up guessing.
Most real-world failures fall into a few buckets:
- “Missing” events (you timed out, returned an error, or failed after acknowledging)
- Duplicates (retries plus a handler that isn’t idempotent)
- Wrong order (you assumed delivery order equals event order)
- Mystery requests (no signature verification, so you can’t separate real from fake)
The practical goal is simple: accept real events once, reject fakes, and leave a clear trail so you can debug a customer report in minutes.
How webhooks actually behave
A webhook is just an HTTP request that a provider sends to an endpoint you expose. You don’t pull it like an API call. The sender pushes it when something happens, and your job is to receive it, respond quickly, and process it safely.
A typical delivery includes a request body (often JSON) plus headers that help you validate and track what you received. Many providers include a timestamp, an event type (like invoice.paid), and a unique event ID you can store to detect duplicates.
The part that surprises teams: delivery is almost never “exactly once.” Most providers aim for “at least once,” which means the same event can arrive multiple times, sometimes minutes or hours apart.
Retries happen for boring reasons: your server is slow or times out, you return a 500, their network doesn’t see your 200, or your endpoint is briefly unavailable during deploys or traffic spikes.
A timeout is especially tricky. Your server might receive the request and even finish processing it, but the response doesn’t reach the sender in time. From the provider’s view it failed, so they retry. Without protection, you process the same event twice.
A good mental model is to treat the HTTP request as a “delivery attempt,” not “the event.” The event is identified by its ID. Your processing should be based on that ID, not on how many times the provider calls you.
Webhook signing in plain terms
Webhook signing is how the sender proves a request really came from them and wasn’t changed on the way. Without signing, anyone who guesses your webhook URL can post fake “payment succeeded” or “user upgraded” events. Even worse, a real event could be altered in transit (amount, customer ID, event type) and still look valid to your app.
The most common pattern is HMAC with a shared secret. Both sides know the same secret value. The sender takes the exact webhook payload (usually the raw request body), computes an HMAC using that secret, and sends the signature alongside the payload. Your job is to recompute the HMAC over the same bytes and check that the signatures match.
Signature data is usually placed in an HTTP header. Some providers also include a timestamp there so you can add replay protection. Less commonly, the signature is embedded in the JSON body, which is riskier because parsers or re-serialization can change formatting and break verification.
When comparing signatures, don’t use a normal string equality check. Basic comparisons can leak timing differences that help an attacker guess the correct signature over many attempts. Use a constant-time comparison function from your language or crypto library, and reject on any mismatch.
If a customer reports “your system accepted an event we never sent,” start with signature checks. If signature verification fails, you likely have a secret mismatch or you’re hashing the wrong bytes (for example, parsed JSON instead of the raw body). If it passes, you can trust the sender identity and move on to deduping, ordering, and retries.
Step by step: verify a webhook signature
Reliable webhook handling starts with one boring rule: verify what you received, not what you wish you received.
The safe way to verify
Capture the raw request body exactly as it arrived. Don’t parse and re-serialize JSON before checking the signature. Tiny differences (whitespace, key order, unicode) change the bytes and can make valid signatures look invalid.
Then build the exact payload your provider expects you to sign. Many systems sign a string like timestamp + "." + raw_body. The timestamp isn’t decoration. It’s there so you can reject old requests.
Compute the HMAC using the shared secret and the required hash (often SHA-256). Keep the secret in a secure store and treat it like a password.
Finally, compare your computed value to the signature header using a constant-time comparison. If it doesn’t match, return a 4xx and stop. Don’t “accept anyway.”
A quick implementation checklist:
- Read the body as bytes once, store it, and use those same bytes for verification.
- Recreate the signed string exactly, including separators and timestamp formatting.
- Compute HMAC with the correct secret and algorithm.
- Compare signature values safely and reject mismatches.
- Log why verification failed (missing header, bad timestamp, mismatch) without logging the secret or full signature.
A quick example
A customer reports “webhooks stopped working” after you added JSON parsing middleware. You see signature mismatches, mostly on larger payloads. The fix is usually to verify using the raw body before any parsing, and to log which step failed (for example, “signature header missing” vs “timestamp outside allowed window”). That one detail often cuts debugging time from hours to minutes.
Idempotency keys: accept once, safely
Providers retry because delivery isn’t guaranteed. Your server might be down for a minute, a network hop may drop the request, or your handler may time out. The provider assumes “maybe it worked” and sends the same event again.
An idempotency key is the receipt number you use to recognize an event you’ve already processed. It’s not a security feature, and it’s not a substitute for signature verification. It also won’t fix race conditions unless you store and check it safely under concurrency.
Choosing the key depends on what the provider gives you. Prefer a value that stays stable across retries:
- Event ID (best when one event maps to one business change)
- Delivery ID or message ID (best when retries keep the same delivery identifier)
- A hash of stable fields (last resort if no ID exists)
When you receive a webhook, write the key to storage first using a uniqueness rule so only one request “wins.” Then process the event. If you see the same key again, return success without doing the work twice.
Keep your stored “receipt” small but useful: the key, processing status (received/processed/failed), timestamps (first seen/last seen), and a minimal summary (event type and related object ID). Many teams retain keys for 7 to 30 days so late retries and most customer reports are covered.
Replay protection without blocking real traffic
Replay protection stops a simple but nasty problem: someone captures a real webhook request (with a valid signature) and sends it again later. If your handler treats every delivery as new, that replay can trigger duplicate refunds, duplicated user invites, or repeated status changes.
A common approach is to sign not only the payload but also a timestamp. Your webhook includes headers like X-Signature and X-Timestamp. On receipt, verify the signature and also verify the timestamp is fresh inside a short window.
Clock drift is what usually causes false rejections. Your servers and the sender’s servers can disagree by a minute or two, and networks can delay delivery. Keep a buffer and log why you rejected a request.
Practical rules that work well:
- Accept only if
abs(now - timestamp) <= window(for example, 5 minutes plus a small grace). - Rely on idempotency as the real safety net. Even inside the window, retries shouldn’t double-apply.
- If you reject for time, return a clear 4xx and log the received timestamp and your server time.
If timestamps are missing, you can’t do true replay protection based on time alone. In that case, lean harder on idempotency (store and reject duplicate event IDs) and consider requiring timestamps in the next webhook version.
Secret rotation matters too. If you rotate signing secrets, keep multiple active secrets for a short overlap period. Verify against the newest secret first, then fall back to older ones. This avoids customer breakage during rollout. If your team ships endpoints quickly (for example, generating code with Koder.ai and using snapshots and rollback during deploys), that overlap window helps because older versions may still be live briefly.
Design the handler so retries don’t hurt you
Retries are normal. Assume every delivery might be duplicated, delayed, or out of order. Your handler should behave the same way whether it sees an event once or five times.
Keep the request path short. Do only what you must to accept the event, then move heavier work to a background job.
A simple pattern that holds up in production:
- Validate basics (method, content type, required headers).
- Verify authenticity (signature) and reject anything that fails.
- Parse and validate the payload.
- Dedupe using the event ID (or idempotency key) in a table with a unique constraint.
- Enqueue work with the event ID, then respond.
Return 2xx only after you’ve verified the signature and recorded the event (or queued it). If you respond 200 before saving anything, you can lose events during a crash. If you do heavy work before responding, timeouts trigger retries and you may repeat side effects.
Slow downstream systems are the main reason retries become painful. If your email provider, CRM, or database is slow, let a queue absorb the delay. The worker can retry with backoff, and you can alert on stuck jobs without blocking the sender.
Out-of-order events happen too. For example, a "subscription.updated" might arrive before "subscription.created". Build tolerance by checking current state before applying changes, allowing upserts, and treating “not found” as a reason to retry later (when that makes sense) rather than as a permanent failure.
Common mistakes that cause hard-to-trace bugs
Many “random” webhook issues are self-inflicted. They look like flaky networks, but they repeat in patterns, usually after a deploy, secret rotation, or a small change in parsing.
The most common signature bug is hashing the wrong bytes. If you parse JSON first, your server may reformat it (whitespace, key order, number formatting). Then you verify the signature against a different body than the sender signed, and verification fails even though the payload is genuine. Always verify against the raw request body bytes exactly as received.
The next big source of confusion is secrets. Teams test in staging but accidentally verify with the production secret, or keep an old secret after rotation. When a customer reports failures “only in one environment,” assume wrong secret or wrong config first.
A few mistakes that lead to long investigations:
- Logging the full body to debug, then leaking tokens, emails, or payment details into logs.
- Returning 500 while also performing side effects (sending emails, updating orders). Retries will repeat the side effects.
- Using an idempotency key that isn’t truly unique (for example, event type + minute). Real events get dropped as “duplicates.”
- Treating a 2xx response as “processed,” when your code only queued work that later failed.
Example: a customer says “order.paid never arrived.” You see signature failures started after a refactor that switched request parsing middleware. The middleware reads and re-encodes JSON, so your signature check is now using a modified body. The fix is simple, but only if you know to look for it.
Debug customer-reported failures quickly
When a customer says “your webhook didn’t fire,” treat it like a trace problem, not a guessing problem. Anchor on one exact delivery attempt from the provider and follow it through your system.
Start by getting the provider’s delivery identifier, request ID, or event ID for the failed attempt. With that single value, you should be able to find the matching log entry quickly.
From there, check three things in order:
- Did signature verification pass?
- Did your timestamp or replay window check pass (if you use one)?
- Did idempotency treat it as new or as a duplicate?
Then confirm what you returned to the provider. A slow 200 can be as bad as a 500 if the provider times out and retries. Look at status code, response time, and whether your handler acknowledged before doing heavy work.
If you need to reproduce, do it safely: store a redacted raw request sample (key headers plus raw body) and replay it in a test environment using the same secret and verification code.
Quick checklist you can run in 10 minutes
When a webhook integration starts failing “randomly,” speed matters more than perfection. This runbook catches the usual causes.
Pull one concrete example first: provider name, event type, approximate timestamp (with timezone), and any event ID the customer can see.
Then verify:
- Signature verification uses the raw request body bytes (before JSON parsing) and the correct secret for that environment.
- Replay checks make sense for real retry behavior (and your server clock is sane).
- Idempotency really dedupes (unique constraint, written before processing, sensible retention).
- Your handler acknowledges only after validation and durable recording/queueing.
- Logs include a minimal, searchable receipt: provider, event_id, signature_ok, replay_ok, idempotency_status, response_code, latency_ms.
If the provider says “we retried 20 times,” check common patterns first: wrong secret (signature fails), clock drift (replay window), payload size limits (413), timeouts (no response), and bursts of 5xx from downstream dependencies.
Example: tracing a “missing event” report end to end
A customer emails: “We missed an invoice.paid event yesterday. Our system never updated.” Here’s a fast way to trace it.
First, confirm whether the provider attempted delivery. Pull the event ID, timestamp, destination URL, and the exact response code your endpoint returned. If there were retries, note the first failure reason and whether a later retry succeeded.
Next, validate what your code saw at the edge: confirm the signing secret configured for that endpoint, recompute signature verification using the raw request body, and check the request timestamp against your allowed window.
Be careful with replay windows during retries. If your window is 5 minutes and the provider retries 30 minutes later, you might reject a legitimate retry. If that’s your policy, make sure it’s intentional and documented. If it’s not, widen the window or change the logic so idempotency remains the primary defense against duplicates.
If signature and timestamp look good, follow the event ID through your system and answer: did you process it, dedupe it, or drop it?
Common outcomes:
- Deduped: the idempotency key already exists, so you returned 200 without re-running business logic.
- Rejected: validation failed (signature mismatch, timestamp too old, missing headers).
- Timed out: the handler took too long, the provider marked it failed, then retried.
When you reply to the customer, keep it crisp and specific: “We received delivery attempts at 10:03 and 10:33 UTC. The first timed out after 10s; the retry was rejected because the timestamp was outside our 5-minute window. We increased the window and added faster acknowledgement. Please resend event ID X if needed.”
Next steps: make it repeatable
The fastest way to stop webhook fires is to make every integration follow the same playbook. Write down the contract you and the sender agree on: required headers, the exact signing method, which timestamp is used, and which IDs you treat as unique.
Then standardize what you record for each delivery attempt. A small receipt log is usually enough: received_at, event_id, delivery_id, signature_valid, idempotency_result (new/duplicate), handler_version, and response status.
A workflow that stays useful as you grow:
- Keep a dedicated test endpoint that validates signatures and returns 2xx without running business actions.
- Store the raw request body and key headers for a short time, just long enough to debug and replay.
- Build a replay-safe reprocess job that re-runs stored events through the same handler code path.
- Keep one internal checklist that support, QA, and engineering all follow.
If you build apps on Koder.ai (koder.ai), Planning Mode is a nice way to define the webhook contract first (headers, signing, IDs, retry behavior) and then generate a consistent endpoint and receipt record across projects. That consistency is what makes debugging fast instead of heroic.
FAQ
Why do webhooks seem to “randomly” fail or duplicate in production?
Because webhook delivery is usually at-least-once, not exactly once. Providers retry on timeouts, 5xx responses, and sometimes when they don’t see your 2xx in time, so you can get duplicates, delays, and out-of-order deliveries even when everything is “working.”
What’s the safest basic flow for handling a webhook request?
Default to this rule: verify the signature first, then store/dedupe the event, then respond 2xx, then do heavy work asynchronously.
If you do heavy work before replying, you’ll hit timeouts and trigger retries; if you reply before recording anything, you can lose events on crashes.
How do I avoid signature mismatches when verifying webhooks?
Use the raw request body bytes exactly as received. Don’t parse JSON and re-serialize before verification—whitespace, key order, and number formatting changes can break signatures.
Also make sure you’re recreating the provider’s signed payload precisely (often timestamp + "." + raw_body).
What should my endpoint do when signature verification fails?
Return a 4xx (commonly 400 or 401) and do not process the payload.
Log a minimal reason (missing signature header, mismatch, bad timestamp window), but don’t log secrets or full sensitive payloads.
What is an idempotency key for webhooks, and which value should I use?
An idempotency key is a stable unique identifier you store so retries don’t re-apply side effects.
Best options:
- Event ID (ideal when one event maps to one business change)
- Delivery/message ID (if it stays constant across retries)
- Hash of stable fields (last resort)
Enforce it with a unique constraint so only one request wins under concurrency.
How do I dedupe webhooks without race conditions?
Write the idempotency key before doing side effects, with a uniqueness rule. Then either:
- Mark it processed after success, or
- Record a failure status so you can retry safely
If the insert fails because the key already exists, return 2xx and skip the business action.
How do I add replay protection without rejecting legitimate retries?
Use a timestamp in the signed data and reject requests outside a short window (for example, a few minutes).
To avoid blocking legitimate retries:
- Allow some clock drift
- Log your server time and received timestamp on rejection
- Treat idempotency as the main protection against duplicates; the time window is mainly to stop late replays
How should I handle out-of-order webhook events?
Don’t assume delivery order equals event order. Make handlers tolerant:
- Use upserts where possible
- Check current state before applying changes
- If an object isn’t found, consider retrying later (via a queue) instead of permanently failing
Store the event ID and type so you can reason about what happened even when order is weird.
What should I log so webhook debugging doesn’t turn into guessing?
Log a small “receipt” per delivery attempt so you can trace one event end-to-end:
- provider, event_id, delivery_id
- signature_ok, replay_ok
- idempotency result (new/duplicate)
- response_code, latency_ms
- timestamps (received/first_seen/last_seen)
Keep logs searchable by event ID so support can answer customer reports quickly.
What’s a fast way to investigate a customer report that “a webhook never arrived”?
Start by asking for a single concrete identifier: event ID or delivery ID, plus an approximate timestamp.
Then check in this order:
- Signature verification result
- Timestamp/replay window result (if used)
- Idempotency outcome (new vs duplicate)
- What you returned (status code + latency)
If you build endpoints using Koder.ai, keep the handler pattern consistent across projects (verify → record/dedupe → queue → respond). Consistency makes these checks fast when incidents happen.